📘 第五期书生葡语实战营讲座总结
🎙 主讲人:王明(东部大学 数据挖掘实验室 博士生)
一、大语言模型的生成原理
- 架构基础:采用 Transformer(Decoder-only)架构,如 GPT 系列。
- 学习过程模拟人类成长:
- 🧠 预训练:以"下一个词预测"为核心任务,掌握通用语言规律。
- 🎯 指令微调:遵循指令,更贴合人类指令执行习惯。
- 🏛️ 领域微调:形成"垂直专业模型",例如医学、金融 LLM。
- 🧰 工具协同:调用外部知识库、搜索引擎或 API 执行复杂任务。
- 续写机制:根据输入内容,预测下一个最可能的词,逐步生成连贯文本。
二、提示工程 Prompt Engineering 简介
📌 什么是 Prompt?
输入给模型的指令/内容,引导其生成期望输出。
✨ 什么是提示工程?
通过设计和优化 Prompt,提高模型响应质量与稳定性。
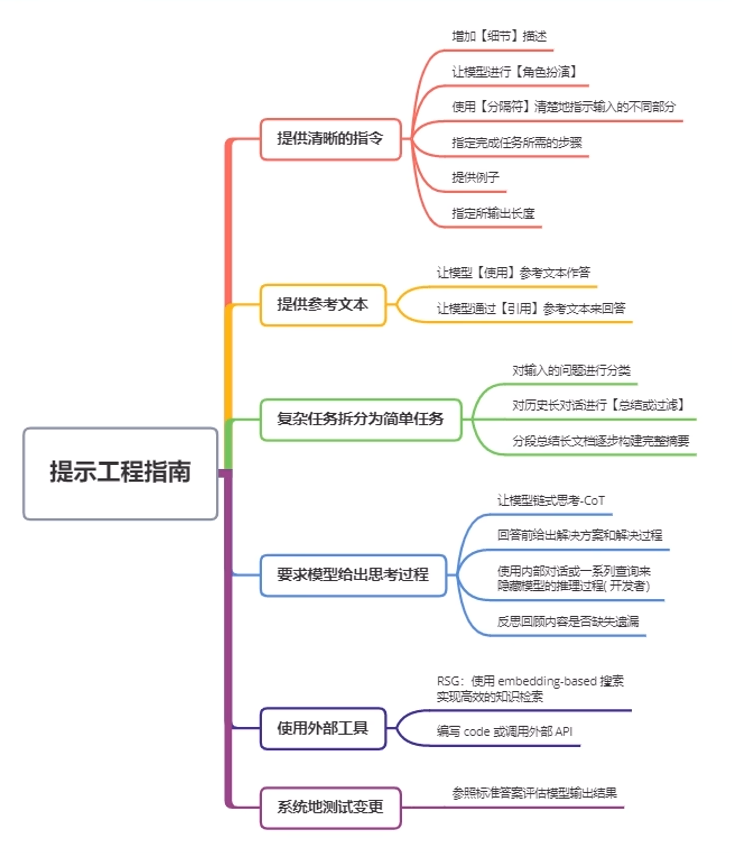
✅ 六大提示原则(来自 OpenAI):
- 清晰具体的任务描述
- 提供上下文或示例(few-shot)
- 任务分解(适用于复杂任务)
- 给予思考时间(Chain of Thought)
- 调用外部工具辅助推理
- 系统化测试 调整提示
三、实用提示技巧举例
| 技巧类型 | 示例 |
|---|---|
| 明确任务格式 | "生成一首七言律诗"比"写一首诗"更有效 |
| 指定角色扮演 | 翻译大师 vs 普通翻译 |
| 提供示例 (few-shot,思维链) | 提高准确率与风格一致性 |
| 使用格式符 | 用 `` 或 Markdown 包裹指令,避免误解 |
| 情感/奖励激励 | "这对我事业很重要" or "我给你200元小费" |
四、结构化提示设计框架对比
🧩 CRISP 框架(结构灵活)
- 能力和角色(Capabilities&Role):希望大语言模型扮演怎么样的角色
- 洞察力(insights):背景信息和上下文
- 个性(Persona)希望大语言模型以什么风格或方式回答你
- 指令(Prompt)希望大语言模型做什么
- 尝试(Experiment)要求大语言模型提供多个答案

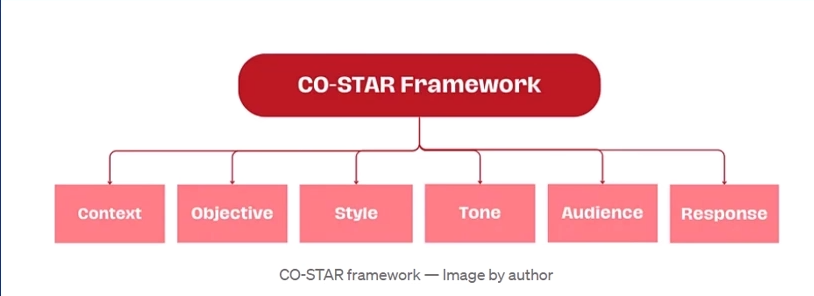
🧱 COSTAR 框架(结构清晰)
- Context(背景):提供任务背景信息
- Objective(目标):定义需要LLM执行的任务
- Style(风格):指定希望LLM具备的写作风格
- Tone(语气):设定LLM回复的情感基调
- Audience(对象):表明回复对象
- Response format(输出格式):提供回复格式

⚠️ 问题:不便扩展或调整,无法容纳复杂模块(如示例/规则)
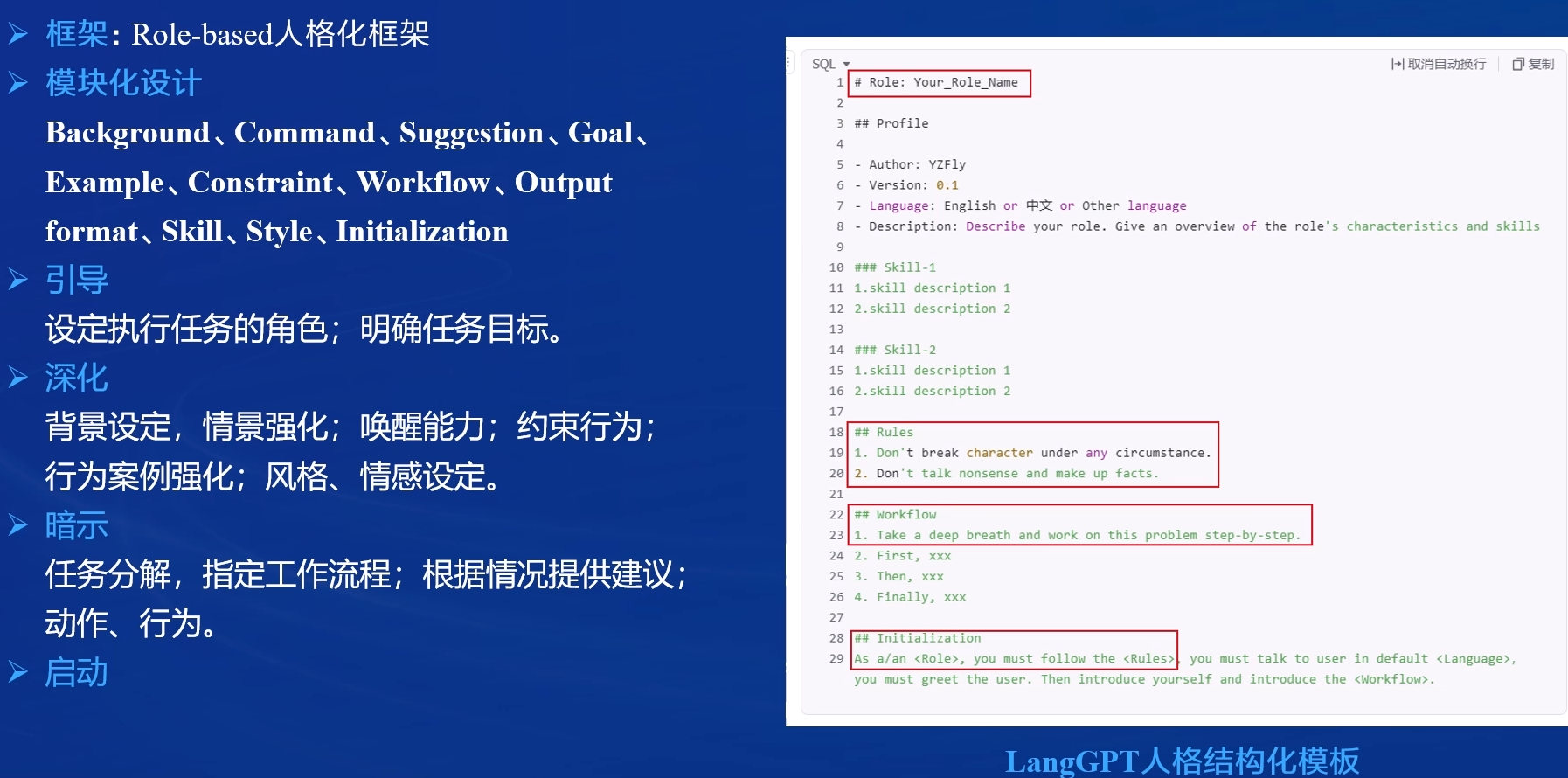
五、人格化提示设计框架:Long-GPT
🎯 目标
通过"人格化"提示设计,使模型进入特定角色和工作状态。
🧠 理论基础:心理学启发
- 认知框架:围绕"心理模型"组织语言
- 情绪调节:正向激励带来正面响应
- 思维模式:模拟人类工作流、思维路径

🛠 结构化模块(可选组合):
- 基本身份与能力唤醒
- 明确规则与目标约束
- 分阶段工作流程(如"先做A,再做B")
- 输出格式要求(如 JSON、表格)
- 初始化启动语
六、自动提示生成工具:MISTRO
Lang-GPT 提示自动生成器(挂载于 Hugging Face Space)https://huggingface.co/spaces/sci-m-wang/Minstrel
🧱 模块组成:
- 分析组:解析用户任务意图,激活相应模块
- 设计组:生成对应提示结构(Prompt Blocks)
- 测试组 :
- 提示模拟器(执行任务)
- 多智能体评估群组(自动辩论 & 优化)
七、实战演练:提示工程练习赛(论文分类)
🏆 任务目标:
- 依据论文标题和摘要,将论文归类为 10 个科学领域之一。
📊 数据来源:
- arXiv 论文,10类:AI、CV、CL、Robotics、Networking 等
🧪 提交内容:
- 系统提示(可空)
- 任务提示(包含
{title}和{abstract})
🧮 评测方式:
- 使用 OpenCompass + 书生葡语 38B instruct 模型
- 准确率 = 正确分类数量 / 总数
🧩 示例系统提示结构(Lang-GPT):
text
你是一个资深arXiv论文分类专家,你的任务是......
[背景信息]
[技能唤醒]
[规则说明]
[工作流程指示]
[输出格式要求]