一、InnoDB记录的存储结构和索引页结构
1、InnoDB的三大特性
双写机制、Buffer Pool、自适应Hash索引。
自适应Hash索引:
- 针对热点数据创建hash索引,下一次查询的sql命中这些数据时,可以直接返回
- 是innoDB底层自动维护的索引,无法手动干预
2、引入需求
客户端、表存储在哪里?
表中数据是什么格式?
以什么方式去访问这些数据?
事务和锁的原理?
3、如何从磁盘中读取数据
数据分成页(磁盘 -> 内存),每页16KB;
4、行格式
对于开发人员来说,以条数为单位,磁盘中存放一条数据叫行格式,有以下几类
- COMPACT;
- Redundant;
- Dynamic; // 默认
- Compressed;
查询行格式
java
show variables like 'innodb_default_row_format';5、行格式结构 & 说明
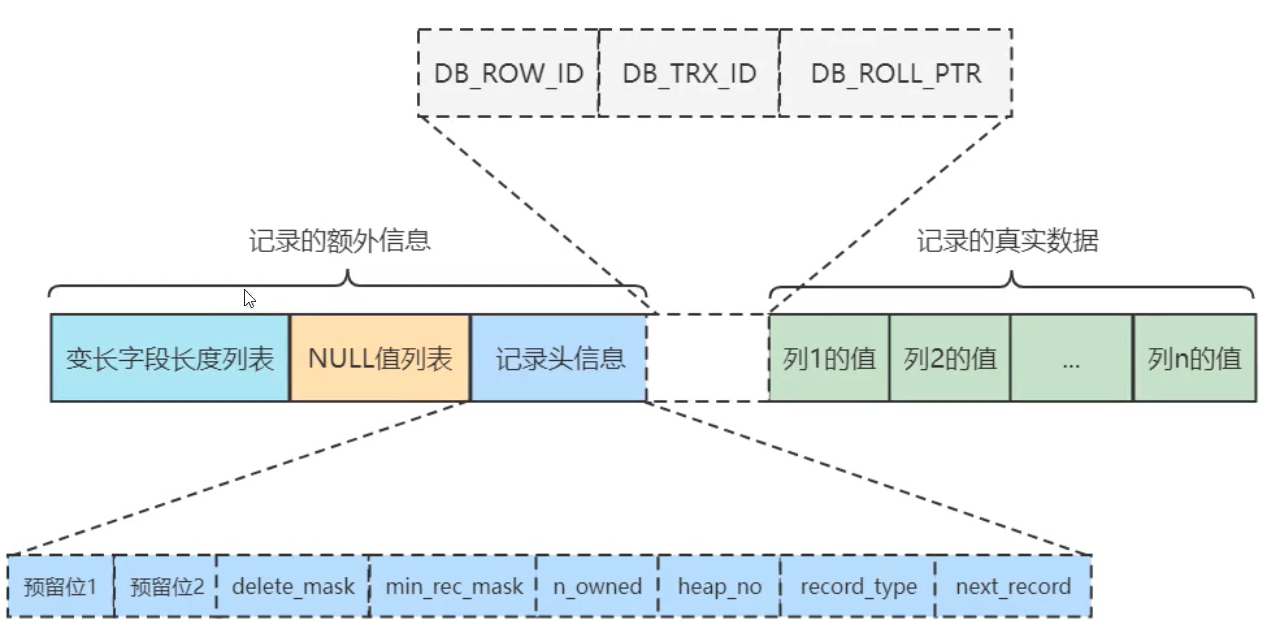
以COMPACT展示:
|-----------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 部分 | 说明 |
| 变长字段长度列表 | 所有【变长的字段】的长度组成的列表; varchar数据类型; 最大的数据长度 <= 255字节,就用1个字节记录,大于就用2个字节记录 |
| NULL值列表 | 存储当前行【所有字段】是否为null,用0和1表示; * 1 - null * 0 - 非null |
| 记录头信息 | 5个字节构成,按二进制的位数存储,40位; _____________________________________________________________________ | 头信息 | 二进制位数 | 解释 | 预留位1 1 没有使用; 预留位2 1 没有使用; delete_mask 1 标记是否被删除; min_rec_mask 1 B+树的每层非叶子节点中的最小记录都会添加该标记; n_owned 4 表示当前记录拥有的记录数; heap_no 13 表示当前记录的类型:0-普通记录,1-B+树非叶子节点记录,2-表示最小记录,3- 表示最大记录; next_record 16 表示下一条记录的相对位置; |
| 隐藏信息--DB_ROW_ID | 如果没设置表的主键列,那就自动创建这一列做主键; |
| 隐藏信息--DB_TRX_ID | 事务的id |
| 隐藏信息--DB_ROLL_PTR | 回滚指针 |
6、数据溢出
定义:一个字段的大小(varchar 60000字节)就大于一页(16KB = 16384字节)
处理方法:
|------------------------------|-----------------------------------------------------------|
| 行格式 | 处理方法 |
| COMPACT; Redundant; | 化整为零法; 当前页只保存【所有字段】的前768个字节的数据; 剩余的数据存到其他页中,留出20个字节指向其他页; |
| Dynamic; Compressed; | 别处寄存法; 如果数据长度超过768个字节,那么当前页什么都不保存; 只利用20字节指向其他页; |
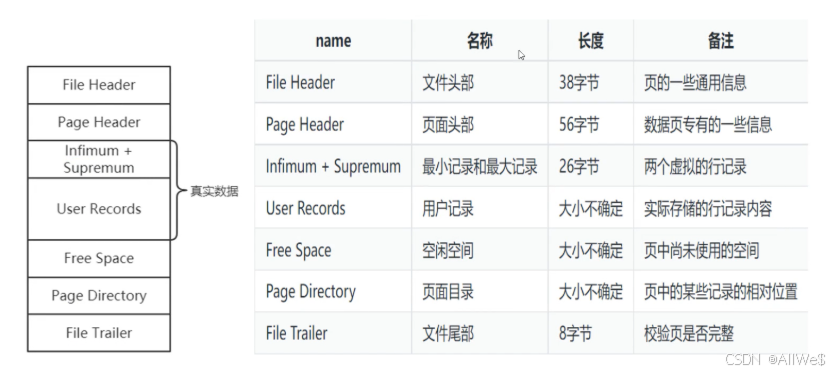
7、索引页格式
聚簇索引:关联了数据,可以理解成数据页。
二、表空间
表空间是抽象概念,是数据目录下的一个文件(ibdata1)。
系统表空间
MySQL只有一个 系统表空间,用来保存额外的数据 ,和系统数据;
InnoDB数据字典: 以B+树保存表信息;
独立表空间:行在页中,有若干条; //可能一个页放多条数据,可能多个页才放得下一条数据;
页在区中,有64页,每个页是物理连续的,消除大量随机 I/O
区在组中,有256个区;
组在段中,有若干个组,是个逻辑的分组;// 应对范围查询
段在表空间中,有页节点段,非页节点段,回滚段;
三、InnoDB的双写缓冲区/双写机制(doublewrite buffer)
|--------|-------------------------------------------------------------------------------------------------------------------------------------------|
| | 说明 |
| 目的 | innodb按页(16KB)做单位,操作系统按4KB做单位; 防止一个页写入了4KB后断电,出现页缺失情况; |
| 作用 | 保证数据写入的可靠性,用来防止丢失数据; |
| 组成 | 双写缓冲区在系统表空间中; 包含两个区,分别是:extent1区(1MB)和extent2区(1MB); 这两个区的物理地址是连续的,写入的快; 共128个页,页的编号 64 ~ 192,第一个区和第二个区; |
| 机制 | 把数据页写入数据文件前,先向双写缓冲区的两个区写入数据,两个区都写入完成后,才会再将数据页写入数据文件的合适位置; 写2次磁盘,第一次写双写缓冲区(磁盘),第二次真正写入数据文件(磁盘); 如果在写页的时候出现意外,可以在双写缓冲区找到备份完成恢复; |
| 理解 | 先把要写入的数据快速的保存到一个磁盘,再慢慢分发到正确的位置; 相当于一个事务,一个页中的数据要么都插入,要么都失败; |
四、InnoDB的Buffer Pool
1、定义
MySQL服务启动时,申请一块连续内存用来快速操作数据,这块连续内存叫缓冲池(buffer pool);
访问MySQL数据时,如果在磁盘直接访问,会很慢。所以把数据以页为单位 从磁盘加载到内存中;
访问磁盘中的数据页A时,A从磁盘加载到buffer Pool,再做操作;如果已经加载了,直接操作;
2、结构
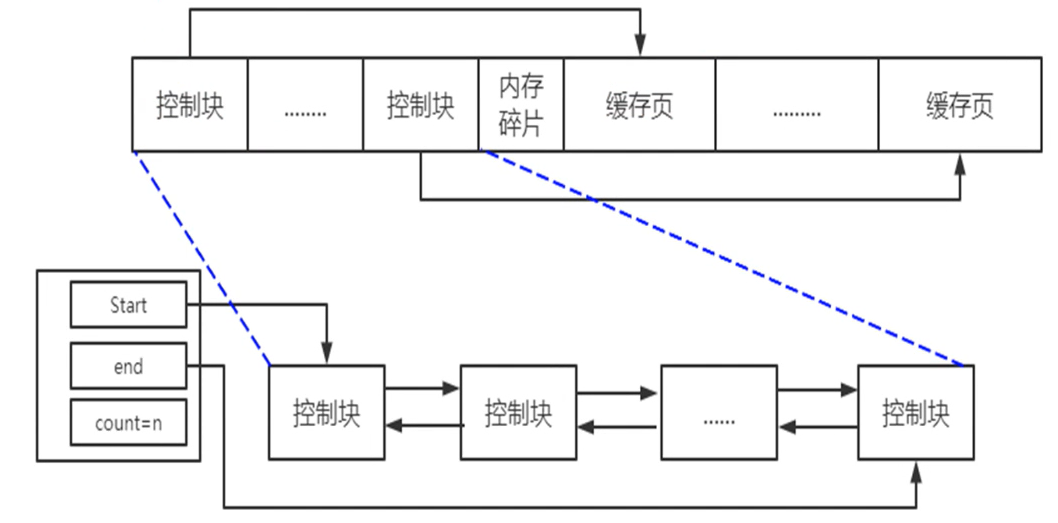
缓存页存放的是某个操作命中 的MySQL在磁盘中的数据;
每个缓存页都有一个它自己的控制块;
控制块:占用5%左右的空间,存放控制相关信息;指示当前数据页的区号、页号、在缓冲池中的位置等信息;
数据页的编号 = A的表空间号 + A的页号;
3、free链表
空闲链表,一个双向列表。
|----------|----------------------------------------------------------------------------------------------------------------------|
| 作用 | 管理缓存页的分配; 控制buffer pool的时候可以从这个列表入手; 只要拿到一个控制块,那么它指向的缓冲页就拿到了; |
| 结构 | 由许多控制块组成,可以理解成一个List; List包括:start,end,count = n,控制块; start -> 控制块1 <-> 控制块2 <-> end; |
| 初始化 | 在初始化缓冲池的时候创建free List,里面的每个节点都是空的; |
| 使用过程 | 在数据页进入buffer pool的时候,找到其中的一个控制块,拿到这个控制块指向的缓存页; * 向控制块写入控制信息; * 向缓存页存储读取的数据; List中的控制块被写入了数据,就认为该缓存空间被使用,把控制块移除出空闲链表; |
4、脏页
背景: 数据在做修改时,要先修改内存buffer pool,后写磁盘;
问题: 如果只来得及修改内存,还没有写磁盘,这时称buffer pool中的页为"脏页";
5、flush链表(刷新链表)
|--------|---------------------------------------------|
| 作用 | 针对数据修改,存储脏页,批量地把脏页写入磁盘; |
| 背景 | 数据在做修改时,会出现脏页; |
| 机制 | 内存中buffer pool的数据页被修改后,不立即写入到磁盘,而是攒一波后批量提交; |
6**、LRU链表(最少使用淘汰链表)**
|----------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 结构 | 与free链表结构相似; free链表移除出来的控制块,放到LRU链表的第一格; |
| 作用 | 针对缓存淘汰控制,最少使用原则; 只保留最近的数据页,移除最早的数据页; |
| 机制 -- 淘汰步骤: | 1、buffer pool中没有数据页时,把数据页A保存到LRU的第一个控制块上; 2、数据页B 进来时,把B 放到第一个控制块上,把A往后挪一格; 3、数据页C 进来时,A 和B都往后挪一格; 4、再次命中A 时,A 放到第一格,B 和C都往后挪一格; 5、如果空间不够,那就淘汰最后一格的数据页; |
7、LRU淘汰算法遇到的问题
InnoDB中的预读:
执行SQL时,查询优化器会预先加载可能用到的数据页到buffer pool;
- 随机预读:在读取某个区中的数据页时,如果连续读取了13个以上的页,使用异步线程预读取当前区的所有页;
sql-- 获取随机预读开关状态,默认关闭 show variables like 'innodb_random_read_ahead';
- 线性读取:在读取某个区中的数据页时,如果连续读取了56个以上的页,MySQL会自动启动一个异步线程,提前读取下一个区中的所有页;
sql-- 获取线性预读阈值 show variables like 'innodb_read_ahead_threshold';在预读数据后,会大量的将已有缓存页顶没了;
SQL语句触发全表扫描:
进行表关联,一张表可能扫描多次;
每次扫描都会淘汰一次LRU链表;
8、LRU的链表的优化
InnoDB把LRU链表分成了两段:
- young区域(热数据 63%)
- old区域(冷数据 37%)
sql
-- 查询划分规则:
show variables like 'innodb_old_blocks_pct'; 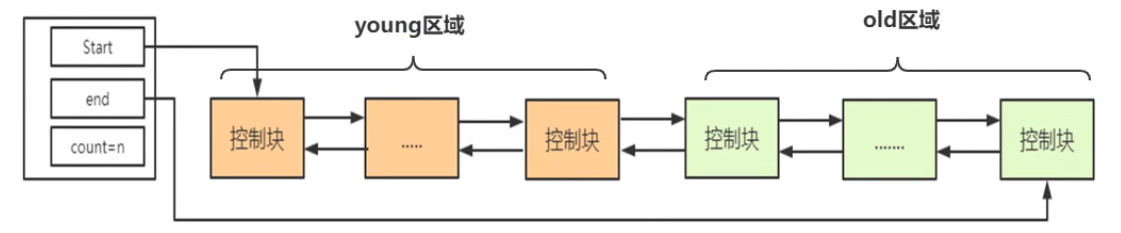
|--------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 对预读的优化 | InnoDB规定数据页初次从磁盘加载(只是加载,没有读取)到buffer pool中,该缓冲页对应的控制块会放到old区域的头部;这样预读页就只会在old区域,不会进入young区域; |
| 对全表扫描的优化 | 虽然首次加载的数据页放到old区域的头部,但是全表扫描涉及到了数据页的读取,第一次访问的时候就会将数据页放到young区域; 所以InnoDB规定:对old区域的缓冲页进行第一次访问时,在它的控制块中写入访问的时间;如果后续的访问时间与第一次的访问时间超出了1s(1000ms),才将数据页放到young区域;  |
|
| 总结 | InnoDB规定了两件事: * 新来的数据页要放在old区域 * 第一次读取old区域的页要记录时间; |
五、Buffer Pool的flush链表的管理
待补充
六、Buffer Pool的LRU链表的管理
待补充