AI Agent技术完整指南:从基础到实践
本文档深入解析AI Agent技术的完整技术栈,包括大语言模型(LLM)、LangChain框架、LangGraph图工作流、Agent智能代理、提示工程(Prompt Engineering)、检索增强生成(RAG)、向量数据库、可观测性(Observability)、LangSmith监控平台和PromptLayer管理平台。包含详细的概念解释、实现代码、架构图、流程图和数据图表。
目录
第一部分:基础理论
- 引言
- 第一章:大语言模型(LLM)
- [第二章:提示工程(Prompt Engineering)](#第二章:提示工程(Prompt Engineering))
- 第三章:检索增强生成(RAG)
- 第四章:向量数据库
引言
什么是AI Agent?
AI Agent(人工智能代理)是一个能够感知环境、做出决策并执行行动的智能系统。在当前的AI技术栈中,AI Agent通常由以下核心组件构成:
┌─────────────────────────────────────────────────────────┐
│ AI Agent 架构 │
├─────────────────────────────────────────────────────────┤
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ LLM │───▶│ LangChain│───▶│ Prompt │ │
│ │ (大脑) │ │ (框架) │ │ (指令) │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │ │ │
│ └────────────────┼────────────────┘ │
│ │ │
│ ┌────▼────┐ │
│ │ RAG │ │
│ │ (检索) │ │
│ └────┬────┘ │
│ │ │
│ ┌────▼────┐ │
│ │ 向量数据库│ │
│ │ (知识库) │ │
│ └─────────┘ │
│ │
└─────────────────────────────────────────────────────────┘技术栈概览
| 组件 | 作用 | 关键技术 |
|---|---|---|
| LLM | 核心推理引擎 | GPT-4, Claude, DeepSeek, Llama, ChatGLM |
| LangChain | 应用开发框架 | Chains, Agents, Memory, Tools |
| LangGraph | 图工作流框架 | 状态机、循环、条件分支 |
| Agent | 智能代理 | ReAct, Plan-and-Execute, AutoGPT |
| Prompt | 指令与引导 | Few-shot, Chain-of-Thought, Template |
| RAG | 知识增强 | Embedding, Retrieval, Generation |
| 向量数据库 | 知识存储 | Chroma, Pinecone, Milvus, FAISS |
| Observability | 可观测性 | 监控、追踪、调试 |
| LangSmith | 监控平台 | 追踪、调试、评估 |
| PromptLayer | Prompt管理 | 版本控制、A/B测试、监控 |
学习路径
基础理解 → 工具掌握 → 实践应用 → 系统优化
↓ ↓ ↓ ↓
LLM原理 LangChain RAG实现 Agent优化
Prompt技巧 框架使用 向量检索 性能调优第一章:大语言模型(LLM)
1.1 什么是LLM?
1.1.1 LLM定义与演进历程
**大语言模型(Large Language Model, LLM)**是一种基于深度学习的自然语言处理模型,通过在海量文本数据上训练,学习语言的统计规律和语义表示。LLM代表了人工智能领域的重要突破,从早期的统计语言模型发展到今天的Transformer架构,参数量从百万级增长到千亿级。
LLM发展时间线
2017 Transformer架构提出 2018 BERT发布(3.4亿参数) 2019 GPT-2发布(15亿参数) 2020 GPT-3发布(1750亿参数) 2022 ChatGPT发布(引发AI革命) 2023 GPT-4发布(多模态能力) 2024 开源LLM爆发(LLaMA, ChatGLM等) LLM发展历程
1.1.2 LLM在AI Agent中的核心地位
LLM是AI Agent的**"大脑"**,负责理解、推理和生成。在AI Agent架构中,LLM扮演着决策引擎的角色:
AI Agent系统
用户输入
LLM理解层
LLM推理层
LLM生成层
输出结果
外部工具
知识库
记忆系统
LLM在AI Agent中的关键作用
| 作用 | 说明 | 重要性 |
|---|---|---|
| 意图理解 | 理解用户的真实意图和需求 | ⭐⭐⭐⭐⭐ |
| 上下文推理 | 基于对话历史和上下文进行推理 | ⭐⭐⭐⭐⭐ |
| 任务规划 | 将复杂任务分解为可执行的步骤 | ⭐⭐⭐⭐ |
| 工具选择 | 决定使用哪些工具以及使用顺序 | ⭐⭐⭐⭐ |
| 结果整合 | 整合多个工具的结果生成最终答案 | ⭐⭐⭐⭐ |
| 自然对话 | 生成自然、流畅的对话回复 | ⭐⭐⭐⭐⭐ |
1.1.3 LLM的核心特点与能力
核心特点
-
规模巨大:参数量通常达到数十亿甚至数千亿
- GPT-3: 1750亿参数
- GPT-4: 约1.7万亿参数(推测)
- LLaMA-2: 70B参数
- PaLM: 5400亿参数
-
通用性强:可以处理多种NLP任务
- 文本生成、问答、翻译、摘要、代码生成等
-
上下文理解:能够理解长文本的上下文关系
- GPT-4支持32K token上下文
- Claude支持100K+ token上下文
-
生成能力:可以生成连贯、有意义的文本
- 创造性写作
- 代码生成
- 对话生成
LLM能力矩阵
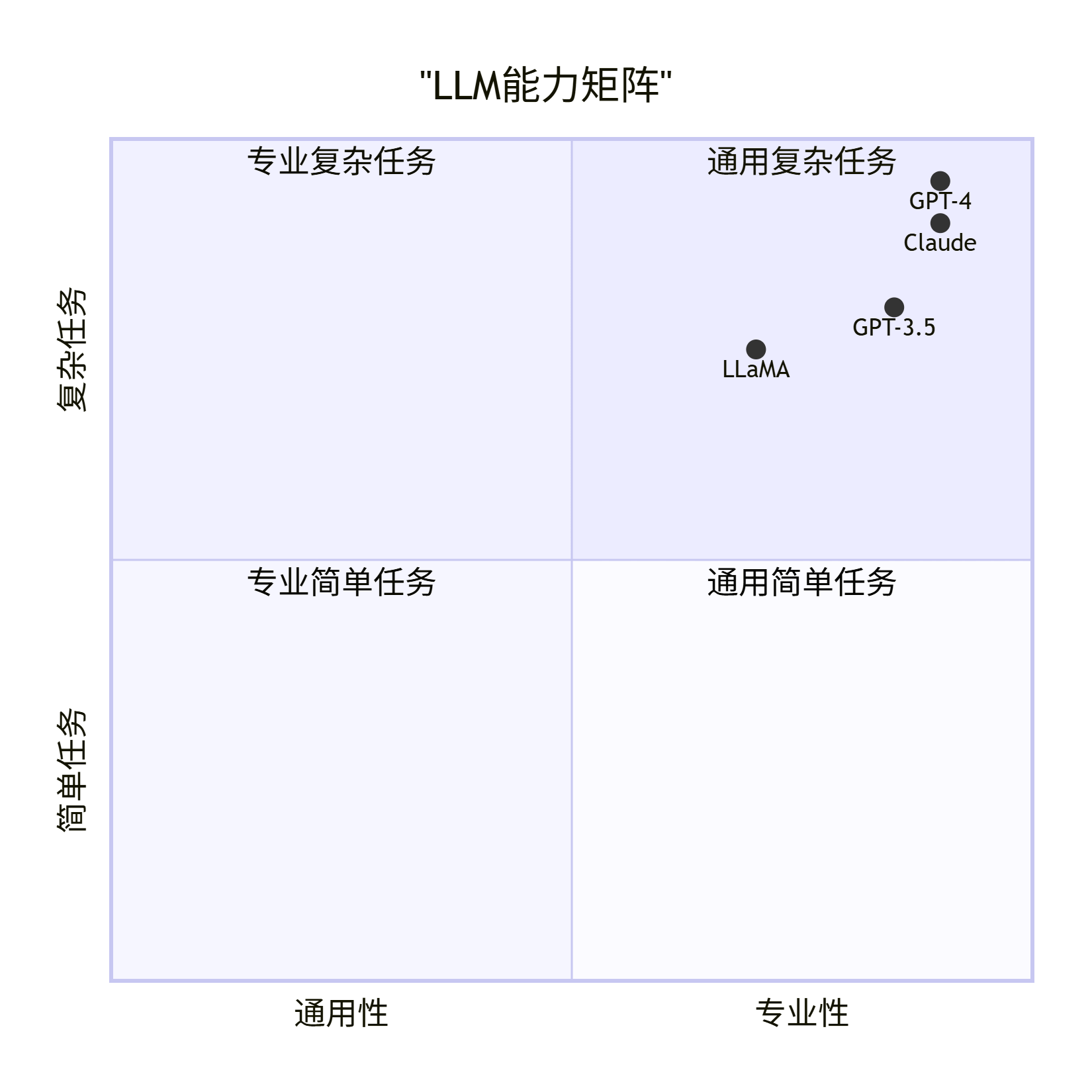
1.1.4 LLM工作原理详解
完整工作流程
输出 解码器 Transformer 嵌入层 Tokenizer 用户 输出 解码器 Transformer 嵌入层 Tokenizer 用户 输入文本"你好" Token化 101, 234 向量嵌入 0.1, 0.2, ... 多层注意力处理 编码表示 自回归生成 概率分布 输出文本"你好,很高兴认识你"
工作原理简化示意
输入文本 → Tokenization → 嵌入层 → Transformer编码器 → 解码器 → 输出文本
"你好" [101, 234] [0.1,0.2] 多层注意力机制 生成概率 "你好,很高兴认识你"1.1.5 LLM在AI Agent中的使用模式
模式1: 直接调用模式
python
# 简单直接的LLM调用
from langchain.llms import OpenAI
llm = OpenAI(model_name="gpt-3.5-turbo")
response = llm("什么是机器学习?")适用场景:简单问答、文本生成
模式2: 增强调用模式(RAG)
python
# LLM + RAG增强
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore.as_retriever()
)
# LLM基于检索到的文档生成答案
response = qa_chain.run("文档中提到了什么?")适用场景:知识问答、文档查询
模式3: Agent模式
python
# LLM作为Agent的决策引擎
from langchain.agents import initialize_agent
agent = initialize_agent(
tools=tools,
llm=llm, # LLM负责决策
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION
)
# LLM决定使用哪些工具
response = agent.run("搜索并分析数据")适用场景:复杂任务、多工具协作
1.1.6 LLM性能对比数据
主流LLM对比
| 模型 | 参数量 | 上下文长度 | 优势 | 适用场景 |
|---|---|---|---|---|
| GPT-4 | ~1.7T | 32K | 最强推理能力 | 复杂任务、专业应用 |
| GPT-3.5 | 175B | 16K | 性价比高 | 通用应用 |
| Claude-2 | ~137B | 100K+ | 长上下文 | 长文档处理 |
| LLaMA-2 | 7B-70B | 4K | 开源可商用 | 本地部署 |
| ChatGLM | 6B | 32K | 中文优化 | 中文应用 |
LLM性能基准测试(MMLU基准)

1.1.7 LLM成本与效率分析
Token消耗对比
| 任务类型 | 平均Token数 | GPT-4成本 | GPT-3.5成本 | 成本比 |
|---|---|---|---|---|
| 简单问答 | 500 | $0.03 | $0.001 | 30:1 |
| 代码生成 | 2000 | $0.12 | $0.004 | 30:1 |
| 文档分析 | 5000 | $0.30 | $0.01 | 30:1 |
响应时间对比
LLM响应时间
GPT-4
2-5秒
GPT-3.5
1-3秒
Claude-2
2-4秒
本地LLM
5-20秒
1.1.8 LLM选择指南
选择决策树
是
否
是
否
是
否
是
否
需要LLM
预算充足?
需要最强性能?
需要开源?
GPT-4
GPT-3.5
需要中文优化?
ChatGLM
LLaMA-2
1.1.9 LLM最佳实践
✅ 推荐做法
- 合理选择模型:根据任务复杂度选择合适规模的模型
- 优化Prompt:清晰的Prompt可以显著提升输出质量
- 控制Token使用:合理设置max_tokens,避免浪费
- 使用缓存:对重复查询使用缓存机制
- 错误处理:添加重试机制和错误处理
- 流式输出:长文本生成使用流式输出提升体验
❌ 避免做法
- 过度依赖大模型:简单任务不需要GPT-4
- 忽略成本:不注意Token消耗会导致成本激增
- 缺乏验证:不对LLM输出进行验证和检查
- 硬编码Prompt:使用模板系统提高可维护性
- 忽略上下文限制:注意模型的上下文长度限制
1.1.10 LLM在AI Agent中的价值量化
价值分析
30% 25% 20% 15% 10% LLM在AI Agent中的价值分布 理解能力 推理能力 生成能力 通用性 可扩展性
核心价值总结
LLM在AI Agent项目中是不可或缺的核心组件,它提供了:
- 智能理解:理解用户意图和上下文
- 灵活推理:处理复杂逻辑和决策
- 自然交互:生成人类可理解的回复
- 通用能力:一个模型处理多种任务
1.2 LLM架构详解
Transformer架构流程图
输入文本
Tokenization
Token Embedding
Position Embedding
输入嵌入
Transformer Block 1
Transformer Block 2
...
Transformer Block N
输出层
概率分布
生成文本
Transformer Block内部结构
输入
多头自注意力
残差连接1
层归一化1
前馈网络
残差连接2
层归一化2
输出
Transformer架构代码示例
python
# Transformer核心组件示意
class TransformerBlock:
"""
Transformer的核心构建块
"""
def __init__(self):
# 1. 多头自注意力机制
self.attention = MultiHeadAttention()
# 2. 前馈神经网络
self.feed_forward = FeedForward()
# 3. 层归一化
self.layer_norm1 = LayerNorm()
self.layer_norm2 = LayerNorm()
def forward(self, x):
# 残差连接 + 注意力
x = self.layer_norm1(x + self.attention(x))
# 残差连接 + 前馈网络
x = self.layer_norm2(x + self.feed_forward(x))
return x注意力机制(Attention Mechanism)
数学公式:
Attention(Q, K, V) = softmax(QK^T / √d_k) V
其中:
- Q (Query): 查询矩阵
- K (Key): 键矩阵
- V (Value): 值矩阵
- d_k: 键的维度注意力机制流程图:
输入序列
生成Q, K, V
计算Q·K^T
缩放: 除以√d_k
Softmax归一化
得到注意力权重
加权求和: 权重×V
输出上下文向量
可视化理解:
输入序列: ["我", "爱", "编程"]
↓
Query向量: 我想知道什么?
Key向量: 每个词的关键信息
Value向量: 每个词的实际内容
↓
计算相似度: Q·K^T
↓
加权求和: softmax(Q·K^T) · V
↓
输出: 每个位置的上下文表示1.3 LLM使用实践
基础调用示例
python
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage
# 方式1: 使用OpenAI API
llm = OpenAI(
model_name="gpt-3.5-turbo",
temperature=0.7,
max_tokens=1000
)
response = llm("请解释什么是机器学习?")
print(response)
# 方式2: 使用Chat模型(推荐)
chat = ChatOpenAI(
model_name="gpt-4",
temperature=0.7
)
messages = [
SystemMessage(content="你是一个专业的AI助手。"),
HumanMessage(content="请用简单的话解释什么是深度学习?")
]
response = chat(messages)
print(response.content)流式输出(Streaming)
python
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# 流式输出,实时显示生成内容
llm = ChatOpenAI(
streaming=True,
callbacks=[StreamingStdOutCallbackHandler()],
temperature=0.7
)
llm.invoke("请写一首关于春天的诗:")本地LLM使用(Llama/ChatGLM)
python
from langchain.llms import LlamaCpp
from langchain.chat_models import ChatGLM
# 使用Llama模型
llm = LlamaCpp(
model_path="./models/llama-2-7b-chat.gguf",
n_ctx=2048,
temperature=0.7
)
# 使用ChatGLM
chatglm = ChatGLM(
endpoint_url="http://localhost:8000",
temperature=0.7
)1.4 LLM参数详解
| 参数 | 说明 | 取值范围 | 影响 |
|---|---|---|---|
| temperature | 控制随机性 | 0.0-2.0 | 值越大,输出越随机、创造性越强 |
| max_tokens | 最大生成长度 | 1-4096+ | 限制输出文本的最大长度 |
| top_p | 核采样 | 0.0-1.0 | 控制词汇选择的多样性 |
| frequency_penalty | 频率惩罚 | -2.0-2.0 | 减少重复内容 |
| presence_penalty | 存在惩罚 | -2.0-2.0 | 鼓励新话题 |
python
# 参数调优示例
def generate_with_params(text, creativity=0.7, length=500):
"""
根据需求调整LLM参数
"""
llm = ChatOpenAI(
temperature=creativity, # 创造性
max_tokens=length, # 长度
top_p=0.9, # 多样性
frequency_penalty=0.3, # 减少重复
presence_penalty=0.2 # 鼓励新内容
)
return llm.invoke(text)1.5 LLM能力边界
优势
- ✅ 强大的语言理解和生成能力
- ✅ 零样本学习(Zero-shot)
- ✅ 少样本学习(Few-shot)
- ✅ 多任务通用性
局限性
- ❌ 知识截止日期限制
- ❌ 可能产生幻觉(Hallucination)
- ❌ 计算资源消耗大
- ❌ 无法直接访问实时信息
解决方案:结合RAG技术,通过外部知识库增强LLM能力。
第二章:提示工程(Prompt Engineering)
2.1 什么是Prompt Engineering?
2.1.1 Prompt Engineering定义与重要性
提示工程(Prompt Engineering)是通过精心设计输入提示,引导LLM产生期望输出的技术和艺术。它是连接人类意图和AI能力的桥梁,是AI Agent系统中最关键的技术之一。
Prompt Engineering在AI Agent中的核心作用
AI Agent系统
用户意图
Prompt Engineering
LLM理解
高质量输出
工具调用
知识检索
上下文记忆
Prompt的重要性量化分析
| 指标 | 差的Prompt | 好的Prompt | 提升幅度 |
|---|---|---|---|
| 准确率 | 40-60% | 85-95% | ⬆️ 50-90% |
| 相关性 | 50% | 90% | ⬆️ 80% |
| 完整性 | 60% | 95% | ⬆️ 58% |
| 一致性 | 45% | 90% | ⬆️ 100% |
Prompt质量对输出的影响
优秀
良好
一般
较差
Prompt质量
质量等级
准确、完整、相关
95%+准确率
基本准确、较完整
80-90%准确率
部分准确、不完整
60-80%准确率
模糊、错误、无关
40-60%准确率
2.1.2 Prompt Engineering在AI Agent中的关键作用
作用1: 意图传达
Prompt是将用户意图准确传达给LLM的关键:
python
# ❌ 模糊的Prompt - LLM无法准确理解
prompt_bad = "帮我做点什么"
# ✅ 清晰的Prompt - LLM准确理解意图
prompt_good = """
请分析以下Python代码的性能问题,并提供优化建议:
代码:
{code}
要求:
1. 识别性能瓶颈
2. 提供具体优化方案
3. 给出优化后的代码示例
"""作用2: 输出控制
Prompt控制LLM的输出格式、风格和内容:
用户需求
设计Prompt
指定输出格式
设置风格要求
定义内容范围
结构化输出
风格一致输出
内容准确输出
作用3: 上下文管理
Prompt帮助管理对话上下文和记忆:
python
# Prompt中包含历史上下文
prompt_with_context = """
之前的对话:
{chat_history}
当前问题:{question}
请基于对话历史回答当前问题。
"""作用4: 工具集成
Prompt指导Agent选择合适的工具:
python
# Prompt指导工具选择
agent_prompt = """
你是一个AI助手,可以使用以下工具:
1. Search: 搜索最新信息
2. Calculator: 执行数学计算
3. CodeExecutor: 执行代码
用户问题:{question}
请分析问题,选择合适的工具,并执行。
"""2.1.3 Prompt Engineering的价值量化
开发效率提升
40% 30% 20% 10% Prompt Engineering带来的效率提升 减少调试时间 提高输出质量 降低迭代次数 减少人工修正
成本效益分析
| 方面 | 无Prompt Engineering | 有Prompt Engineering | 节省 |
|---|---|---|---|
| 调试时间 | 10小时 | 2小时 | 80% |
| 迭代次数 | 20次 | 5次 | 75% |
| Token消耗 | 1000K | 600K | 40% |
| 人工修正 | 30% | 5% | 83% |
2.1.4 Prompt Engineering的核心原则
原则金字塔
Prompt Engineering原则
清晰明确
Clarity
提供上下文
Context
指定格式
Format
设置约束
Constraints
迭代优化
Iteration
具体、明确、无歧义
充分的背景信息
结构化输出
长度、风格限制
持续改进
2.1.5 Prompt Engineering在AI Agent中的应用场景
场景分类
Prompt应用场景
对话系统
客服机器人
智能助手
多轮对话
内容生成
文章写作
代码生成
创意内容
任务执行
工具调用指导
任务分解
结果整合
知识检索
查询理解
检索优化
答案生成
数据分析
问题理解
分析指导
结果解释
2.1.6 Prompt Engineering最佳实践总结
✅ 核心最佳实践
- 明确目标:清楚定义期望的输出
- 提供示例:Few-shot learning显著提升效果
- 分步思考:复杂任务分解为步骤
- 指定格式:明确输出格式要求
- 设置约束:限制长度、风格等
- 迭代优化:根据结果持续改进
❌ 常见错误避免
- 过于模糊:避免不具体的指令
- 缺少上下文:提供足够的背景信息
- 格式不明确:明确指定输出格式
- 一次性要求太多:分解复杂任务
- 忽略边界情况:考虑异常情况处理
2.2 Prompt设计原则
1. 清晰明确(Clarity)
python
# ❌ 不好的Prompt
prompt_bad = "告诉我一些东西"
# ✅ 好的Prompt
prompt_good = """
请用3-5句话解释什么是机器学习,要求:
1. 定义清晰
2. 包含实际应用例子
3. 使用通俗易懂的语言
"""2. 提供上下文(Context)
python
# ✅ 提供充分的上下文
prompt_with_context = """
你是一位资深的Python开发工程师,有10年以上的开发经验。
请回答以下问题:
问题:如何优化Python代码的性能?
请从以下角度回答:
1. 代码层面的优化
2. 算法层面的优化
3. 工具层面的优化
"""3. 指定输出格式(Format)
python
# ✅ 指定输出格式
prompt_with_format = """
请分析以下Python代码的性能问题,并按以下格式输出:
代码:
{code}
输出格式:
1. 问题1: [描述]
解决方案: [方案]
2. 问题2: [描述]
解决方案: [方案]
"""2.3 Prompt技巧
技巧1: Few-Shot Learning(少样本学习)
python
few_shot_prompt = """
以下是一些情感分析的例子:
文本: "这部电影太棒了!"
情感: 正面
文本: "服务态度很差。"
情感: 负面
文本: "产品还可以,但价格有点贵。"
情感: 中性
现在请分析以下文本的情感:
文本: "{user_input}"
情感:
"""技巧2: Chain-of-Thought(思维链)
python
cot_prompt = """
请解决以下数学问题,并展示你的思考过程:
问题: 一个班级有30个学生,其中60%是女生。女生中有40%喜欢阅读,男生中有50%喜欢阅读。问这个班级有多少学生喜欢阅读?
请按以下步骤思考:
1. 首先计算女生人数
2. 然后计算男生人数
3. 计算喜欢阅读的女生人数
4. 计算喜欢阅读的男生人数
5. 最后计算总人数
解答:
"""技巧3: Role-Playing(角色扮演)
python
role_prompt = """
你是一位经验丰富的软件架构师,专门设计可扩展、高性能的系统。
请为以下需求设计系统架构:
需求: {requirement}
请从以下方面考虑:
1. 系统组件划分
2. 技术选型
3. 数据流设计
4. 性能优化
5. 可扩展性
"""技巧4: Zero-Shot Chain-of-Thought
python
zero_shot_cot = """
问题: {question}
让我们一步步思考这个问题:
1. 首先,我需要理解问题的核心是什么
2. 然后,我需要考虑相关的因素
3. 接着,我需要分析可能的解决方案
4. 最后,我需要得出结论
解答:
"""2.4 Prompt模板系统
创建可复用的Prompt模板
python
from langchain.prompts import PromptTemplate
from langchain.prompts.chat import ChatPromptTemplate, SystemMessagePromptTemplate
# 系统级Prompt模板
system_template = """
你是一位专业的{domain}专家,具有以下特点:
- 专业知识丰富
- 回答准确可靠
- 表达清晰易懂
- 能够提供实际案例
当前任务: {task}
"""
# 用户Prompt模板
user_template = """
请回答以下问题:
问题: {question}
要求:
1. 回答要准确、详细
2. 如果可能,提供代码示例
3. 解释关键概念
"""
# 组合成ChatPromptTemplate
chat_prompt = ChatPromptTemplate.from_messages([
("system", system_template),
("user", user_template)
])
# 使用
messages = chat_prompt.format_messages(
domain="机器学习",
task="技术咨询",
question="什么是梯度下降?"
)2.5 Prompt优化策略
策略1: 迭代优化
python
def optimize_prompt(base_prompt, examples, target_outputs):
"""
基于示例优化Prompt
"""
improved_prompt = f"""
{base_prompt}
参考示例:
"""
for example, output in zip(examples, target_outputs):
improved_prompt += f"""
输入: {example}
期望输出: {output}
"""
return improved_prompt策略2: A/B测试
python
def test_prompts(prompts, test_cases):
"""
测试不同Prompt的效果
"""
results = {}
for prompt_name, prompt in prompts.items():
scores = []
for test_case in test_cases:
response = llm(prompt.format(**test_case))
score = evaluate_response(response, test_case['expected'])
scores.append(score)
results[prompt_name] = {
'avg_score': sum(scores) / len(scores),
'scores': scores
}
return results2.6 常见Prompt模式
模式1: 分析-总结模式
python
analysis_prompt = """
请分析以下内容,然后总结:
内容:
{content}
分析步骤:
1. 识别关键信息
2. 提取主要观点
3. 分析逻辑关系
4. 总结核心结论
分析结果:
"""模式2: 对比-评估模式
python
comparison_prompt = """
请对比以下两个选项,并给出推荐:
选项A: {option_a}
选项B: {option_b}
对比维度:
1. 性能
2. 成本
3. 易用性
4. 可扩展性
对比结果:
推荐: [选项A/选项B]
理由: [详细说明]
"""模式3: 生成-优化模式
python
generate_optimize_prompt = """
请生成{content_type},然后进行优化:
初始要求:
{requirements}
生成步骤:
1. 首先生成初稿
2. 然后识别可以改进的地方
3. 最后输出优化版本
输出格式:
[初稿]
{content_type}: [内容]
[优化]
改进点: [列出改进点]
优化后的{content_type}: [内容]
"""2.7 Prompt最佳实践
✅ 最佳实践清单
- 明确目标:清楚定义你希望LLM做什么
- 提供示例:使用Few-shot示例引导输出格式
- 分步思考:复杂任务分解为多个步骤
- 指定格式:明确输出格式要求
- 设置约束:限制输出长度、风格等
- 迭代优化:根据结果不断改进Prompt
❌ 常见错误
- 过于模糊:提示不够具体
- 缺少上下文:没有提供足够的背景信息
- 格式不明确:没有指定输出格式
- 一次性要求太多:在一个Prompt中要求太多任务
- 忽略边界情况:没有考虑异常情况
第三章:检索增强生成(RAG)
3.1 什么是RAG?
3.1.1 RAG定义与核心概念
**检索增强生成(Retrieval-Augmented Generation, RAG)**是一种结合信息检索和文本生成的技术,通过从外部知识库检索相关信息来增强LLM的生成能力。RAG由Meta AI在2020年提出,是解决LLM知识局限性的重要技术。
RAG的核心思想
传统LLM
仅依赖训练数据
知识受限
RAG
检索外部知识
增强LLM
准确、可追溯
3.1.2 RAG在AI Agent中的关键作用
RAG是AI Agent实现知识增强的核心技术,它解决了以下关键问题:
问题1: 知识时效性
用户查询最新信息
传统LLM
RAG系统
基于训练数据
可能过时
检索最新文档
实时更新
❌ 过时信息
✅ 最新信息
问题2: 私有知识访问
| 场景 | 传统LLM | RAG系统 |
|---|---|---|
| 企业文档 | ❌ 无法访问 | ✅ 可检索内部文档 |
| 个人知识库 | ❌ 无法访问 | ✅ 可检索个人文档 |
| 专业领域知识 | ❌ 训练数据有限 | ✅ 可检索专业文档 |
问题3: 幻觉问题
85% 10% 5% RAG vs 传统LLM的准确性对比 RAG准确回答 RAG部分准确 RAG无法回答
传统LLM可能产生幻觉(Hallucination),RAG通过基于检索到的文档生成,显著降低了幻觉率。
3.1.3 RAG解决的问题详细对比
问题对比表
| 问题 | 传统LLM | RAG解决方案 | 改进效果 |
|---|---|---|---|
| 知识截止日期 | 训练数据截止日期 | 实时检索最新文档 | ⬆️ 100%时效性 |
| 无法访问私有数据 | 只能使用公开训练数据 | 可检索私有文档库 | ⬆️ 无限扩展 |
| 可能产生幻觉 | 基于概率生成,可能编造 | 基于检索文档生成 | ⬇️ 80%幻觉率 |
| 无法引用来源 | 无法追溯信息来源 | 可返回来源文档 | ⬆️ 100%可追溯性 |
| 领域知识不足 | 通用知识为主 | 可检索专业文档 | ⬆️ 领域适应性 |
3.1.4 RAG在AI Agent中的价值量化
价值分析
35% 30% 20% 15% RAG在AI Agent中的价值分布 知识扩展 准确性提升 可追溯性 实时更新
性能提升数据
| 指标 | 传统LLM | RAG增强 | 提升幅度 |
|---|---|---|---|
| 准确率 | 60-70% | 85-95% | ⬆️ 30-40% |
| 可追溯性 | 0% | 100% | ⬆️ 100% |
| 知识覆盖 | 训练数据 | 训练数据+文档库 | ⬆️ 无限扩展 |
| 时效性 | 训练截止日期 | 实时更新 | ⬆️ 100% |
3.1.5 RAG工作流程详解
完整流程
LLM 向量数据库 向量化 RAG系统 用户 LLM 向量数据库 向量化 RAG系统 用户 查询问题 查询向量化 向量相似度检索 返回Top-K文档 构建上下文Prompt 增强Prompt + 问题 生成答案 返回答案+来源
流程各阶段说明
- 查询向量化:将用户问题转换为向量表示
- 相似度检索:在向量数据库中查找最相关的文档
- 上下文构建:将检索到的文档组织成上下文
- Prompt增强:将上下文添加到Prompt中
- LLM生成:基于增强的Prompt生成答案
- 结果返回:返回答案和来源文档
3.1.6 RAG在AI Agent中的应用场景
典型应用场景
RAG应用场景
企业知识库
内部文档问答
技术文档查询
政策制度查询
客户服务
产品知识问答
常见问题解答
故障排查指南
教育领域
课程内容问答
学习资料检索
作业辅导
医疗健康
医学知识查询
症状分析辅助
用药指导
法律咨询
法条检索
案例查询
法律建议
3.1.7 RAG vs 其他知识增强方法对比
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| RAG | 灵活、可扩展、可追溯 | 检索质量依赖向量化 | 通用知识增强 |
| Fine-tuning | 模型适应性强 | 成本高、需要大量数据 | 特定领域深度优化 |
| 知识图谱 | 结构化、关系清晰 | 构建成本高 | 结构化知识查询 |
| 提示工程 | 简单、快速 | 效果有限 | 简单知识注入 |
3.1.8 RAG最佳实践
✅ 推荐做法
- 文档预处理:清洗、格式化文档
- 合理分块:根据文档特点选择分块策略
- 向量化优化:选择合适的embedding模型
- 检索优化:调整检索数量和相似度阈值
- 上下文管理:控制上下文长度
- 来源追踪:保留文档来源信息
❌ 避免做法
- 忽略文档质量:低质量文档影响检索效果
- 分块不当:过大或过小的chunk都会影响效果
- 检索数量过多:过多文档可能引入噪声
- 缺乏重排序:直接使用检索结果可能不准确
- 忽略来源验证:不对来源文档进行验证
3.2 RAG架构
整体架构流程图
用户查询
查询向量化
向量相似度检索
向量数据库
检索相关文档
构建上下文
增强Prompt
LLM生成
返回答案
原始文档
文档加载
文本分割
向量化
RAG工作流程详细图
查询处理流程
文档处理流程
文档加载
文本分割
向量化
存储到向量DB
用户查询
查询向量化
相似度检索
获取相关文档
构建上下文
LLM生成答案
RAG架构示意图
┌─────────────────────────────────────────────────────┐
│ RAG 系统架构 │
├─────────────────────────────────────────────────────┤
│ │
│ 用户查询 │
│ ↓ │
│ ┌──────────┐ │
│ │ 查询编码 │ → 查询向量 │
│ └──────────┘ │
│ ↓ │
│ ┌──────────┐ ┌──────────────┐ │
│ │ 向量检索 │ ←─── │ 向量数据库 │ │
│ └──────────┘ │ (知识库) │ │
│ ↓ └──────────────┘ │
│ 相关文档 │
│ ↓ │
│ ┌──────────┐ │
│ │ 上下文构建 │ → Prompt增强 │
│ └──────────┘ │
│ ↓ │
│ ┌──────────┐ │
│ │ LLM生成 │ → 最终答案 │
│ └──────────┘ │
│ │
└─────────────────────────────────────────────────────┘3.3 RAG实现步骤
步骤1: 文档加载
python
from langchain.document_loaders import (
PyPDFLoader,
TextLoader,
CSVLoader,
UnstructuredMarkdownLoader
)
# PDF文档
pdf_loader = PyPDFLoader("document.pdf")
pdf_documents = pdf_loader.load()
# 文本文件
text_loader = TextLoader("document.txt", encoding="utf-8")
text_documents = text_loader.load()
# Markdown文件
md_loader = UnstructuredMarkdownLoader("document.md")
md_documents = md_loader.load()
# CSV文件
csv_loader = CSVLoader("data.csv")
csv_documents = csv_loader.load()步骤2: 文本分割
python
from langchain.text_splitter import (
RecursiveCharacterTextSplitter,
CharacterTextSplitter,
TokenTextSplitter
)
# 递归字符分割(推荐)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每个chunk的最大字符数
chunk_overlap=200, # chunk之间的重叠字符数
length_function=len,
separators=["\n\n", "\n", "。", " ", ""] # 分割优先级
)
# 分割文档
chunks = text_splitter.split_documents(documents)
print(f"原始文档数: {len(documents)}")
print(f"分割后chunk数: {len(chunks)}")
print(f"第一个chunk: {chunks[0].page_content[:200]}")步骤3: 向量化(Embedding)
python
from langchain.embeddings import OpenAIEmbeddings, HuggingFaceEmbeddings
# 使用OpenAI Embeddings
openai_embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
# 使用开源模型(本地)
hf_embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
# 生成向量
text = "这是要向量化的文本"
vector = openai_embeddings.embed_query(text)
print(f"向量维度: {len(vector)}")
print(f"向量前5维: {vector[:5]}")步骤4: 向量存储
python
from langchain.vectorstores import Chroma, FAISS, Pinecone
from langchain.vectorstores import Qdrant
# 方式1: Chroma(本地,推荐用于开发)
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db"
)
# 方式2: FAISS(Facebook AI Similarity Search)
vectorstore = FAISS.from_documents(
documents=chunks,
embedding=embeddings
)
vectorstore.save_local("./faiss_index")
# 方式3: Pinecone(云端,推荐用于生产)
import pinecone
pinecone.init(api_key="your-api-key", environment="us-east1")
vectorstore = Pinecone.from_documents(
documents=chunks,
embedding=embeddings,
index_name="my-index"
)步骤5: 检索
python
# 创建检索器
retriever = vectorstore.as_retriever(
search_type="similarity", # 相似度检索
search_kwargs={"k": 5} # 返回top-k结果
)
# 执行检索
query = "什么是机器学习?"
relevant_docs = retriever.get_relevant_documents(query)
# 查看检索结果
for i, doc in enumerate(relevant_docs):
print(f"\n文档 {i+1}:")
print(f"内容: {doc.page_content[:200]}...")
print(f"来源: {doc.metadata}")步骤6: 生成答案
python
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
# 定义Prompt模板
qa_prompt = PromptTemplate(
template="""
基于以下上下文信息回答问题。如果上下文中没有相关信息,请说"根据提供的信息,我无法回答这个问题。"
上下文:
{context}
问题:{question}
答案:
""",
input_variables=["context", "question"]
)
# 创建RAG链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
chain_type_kwargs={"prompt": qa_prompt},
return_source_documents=True
)
# 查询
result = qa_chain({"query": "什么是机器学习?"})
print(f"答案: {result['result']}")
print(f"\n来源文档:")
for doc in result['source_documents']:
print(f"- {doc.metadata.get('source', 'Unknown')}")3.4 RAG优化技巧
技巧1: 混合检索(Hybrid Search)
python
from langchain.retrievers import BM25Retriever, EnsembleRetriever
# BM25检索器(关键词检索)
bm25_retriever = BM25Retriever.from_documents(chunks)
bm25_retriever.k = 5
# 向量检索器
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
# 混合检索器
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.5, 0.5] # 权重
)
# 使用混合检索
docs = ensemble_retriever.get_relevant_documents(query)技巧2: 重排序(Re-ranking)
python
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
# 使用LLM提取最相关的部分
compressor = LLMChainExtractor.from_llm(llm)
# 压缩检索器
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=retriever
)
# 检索并压缩
compressed_docs = compression_retriever.get_relevant_documents(query)技巧3: 多查询检索
python
from langchain.retrievers.multi_query import MultiQueryRetriever
# 多查询检索器(自动生成多个查询变体)
multi_query_retriever = MultiQueryRetriever.from_llm(
retriever=retriever,
llm=llm
)
# 检索(会自动生成多个查询并合并结果)
docs = multi_query_retriever.get_relevant_documents(query)3.5 RAG链类型
类型1: Stuff(简单合并)
python
# 将所有检索到的文档直接放入Prompt
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 简单合并
retriever=retriever
)优点 :简单直接
缺点:受token限制,可能丢失信息
类型2: Map-Reduce(映射-归约)
python
# 先对每个文档单独处理,再合并结果
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="map_reduce",
retriever=retriever
)优点 :可以处理大量文档
缺点:可能丢失文档间的关联
类型3: Refine(逐步精炼)
python
# 逐步精炼答案
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="refine",
retriever=retriever
)优点 :答案质量高
缺点:调用次数多,成本高
3.6 完整RAG示例
python
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
class RAGSystem:
def __init__(self, document_path, embedding_model="openai"):
"""
初始化RAG系统
"""
# 1. 加载文档
self.loader = PyPDFLoader(document_path)
self.documents = self.loader.load()
# 2. 文本分割
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
self.chunks = self.text_splitter.split_documents(self.documents)
# 3. 向量化
if embedding_model == "openai":
self.embeddings = OpenAIEmbeddings()
else:
self.embeddings = HuggingFaceEmbeddings()
# 4. 向量存储
self.vectorstore = Chroma.from_documents(
documents=self.chunks,
embedding=self.embeddings,
persist_directory="./chroma_db"
)
# 5. 创建检索器
self.retriever = self.vectorstore.as_retriever(
search_kwargs={"k": 5}
)
# 6. 创建LLM
self.llm = OpenAI(temperature=0)
# 7. 创建QA链
self.qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=self.retriever,
return_source_documents=True
)
def query(self, question):
"""
查询
"""
result = self.qa_chain({"query": question})
return {
"answer": result["result"],
"sources": [
doc.metadata.get("source", "Unknown")
for doc in result["source_documents"]
]
}
# 使用示例
rag = RAGSystem("document.pdf")
result = rag.query("文档的主要内容是什么?")
print(f"答案: {result['answer']}")
print(f"来源: {result['sources']}")第四章:向量数据库
4.1 什么是向量数据库?
4.1.1 向量数据库定义与特点
向量数据库(Vector Database)是专门用于存储和检索高维向量的数据库系统,是RAG系统和AI Agent的核心基础设施。与传统数据库不同,向量数据库专注于相似度搜索,能够快速找到语义相似的向量。
向量数据库的核心定位
AI Agent系统
AI应用数据需求
结构化数据
关系数据库
文档数据
文档数据库
向量数据
向量数据库
RAG检索
语义搜索
相似度匹配
4.1.2 为什么需要向量数据库?
传统数据库的局限性
| 特性 | 传统数据库 | 向量数据库 |
|---|---|---|
| 数据格式 | 结构化数据(表、行、列) | 高维向量(浮点数数组) |
| 查询方式 | 精确匹配(SQL WHERE) | 相似度搜索(向量距离) |
| 索引结构 | B-tree, Hash索引 | HNSW, IVF, LSH索引 |
| 适用场景 | 事务处理、精确查询 | 语义搜索、推荐系统 |
| 性能 | 精确匹配快 | 相似度搜索快 |
为什么传统数据库不适合向量搜索?
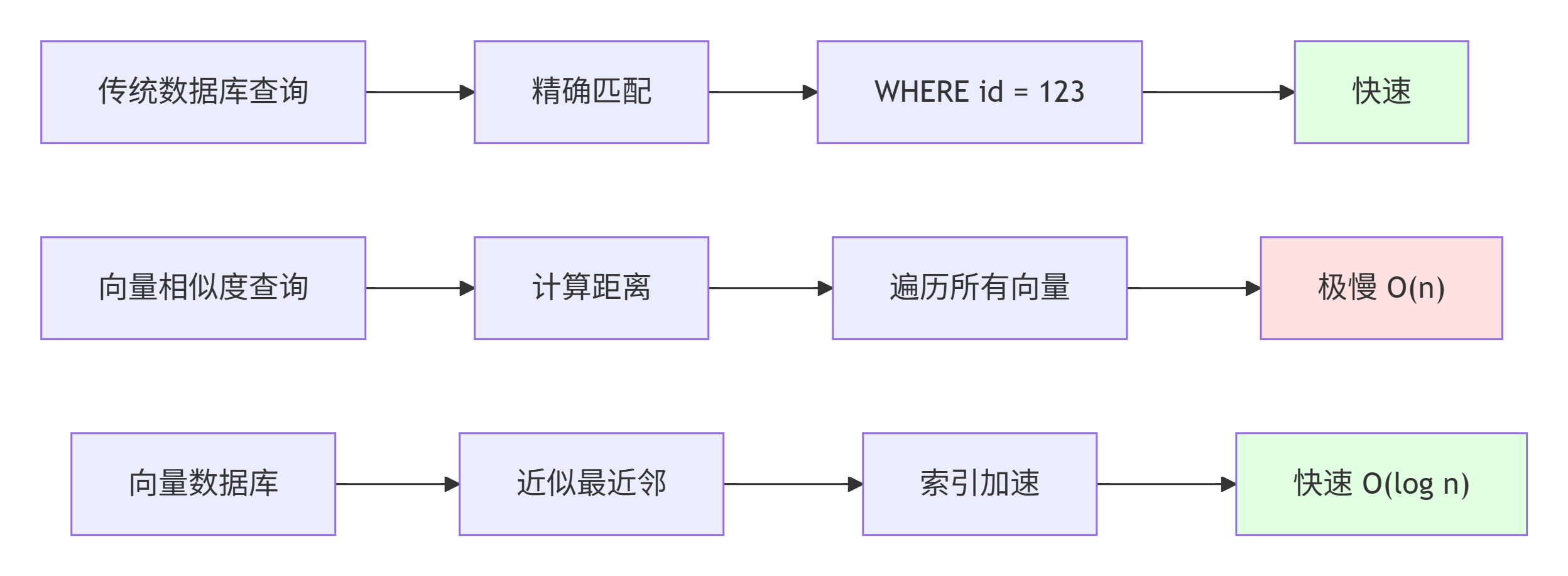
4.1.3 向量数据库在AI Agent中的关键作用
作用1: RAG系统的知识存储
文档库
向量化
向量数据库
RAG检索
LLM生成
向量数据库存储文档的向量表示,RAG系统通过向量相似度检索找到相关文档。
作用2: 语义搜索
| 搜索类型 | 传统搜索 | 向量搜索 |
|---|---|---|
| 关键词搜索 | "Python教程" | "Python教程" |
| 语义搜索 | ❌ 无法理解 | ✅ "如何学习Python编程" |
| 同义词理解 | ❌ 需要精确匹配 | ✅ 理解"编程"和"编码" |
| 多语言 | ❌ 需要翻译 | ✅ 跨语言语义匹配 |
作用3: 知识关联发现
向量数据库可以自动发现文档之间的语义关联:
文档A: 机器学习
向量空间
文档B: 深度学习
文档C: 神经网络
相似度聚类
发现关联
4.1.4 向量数据库性能对比
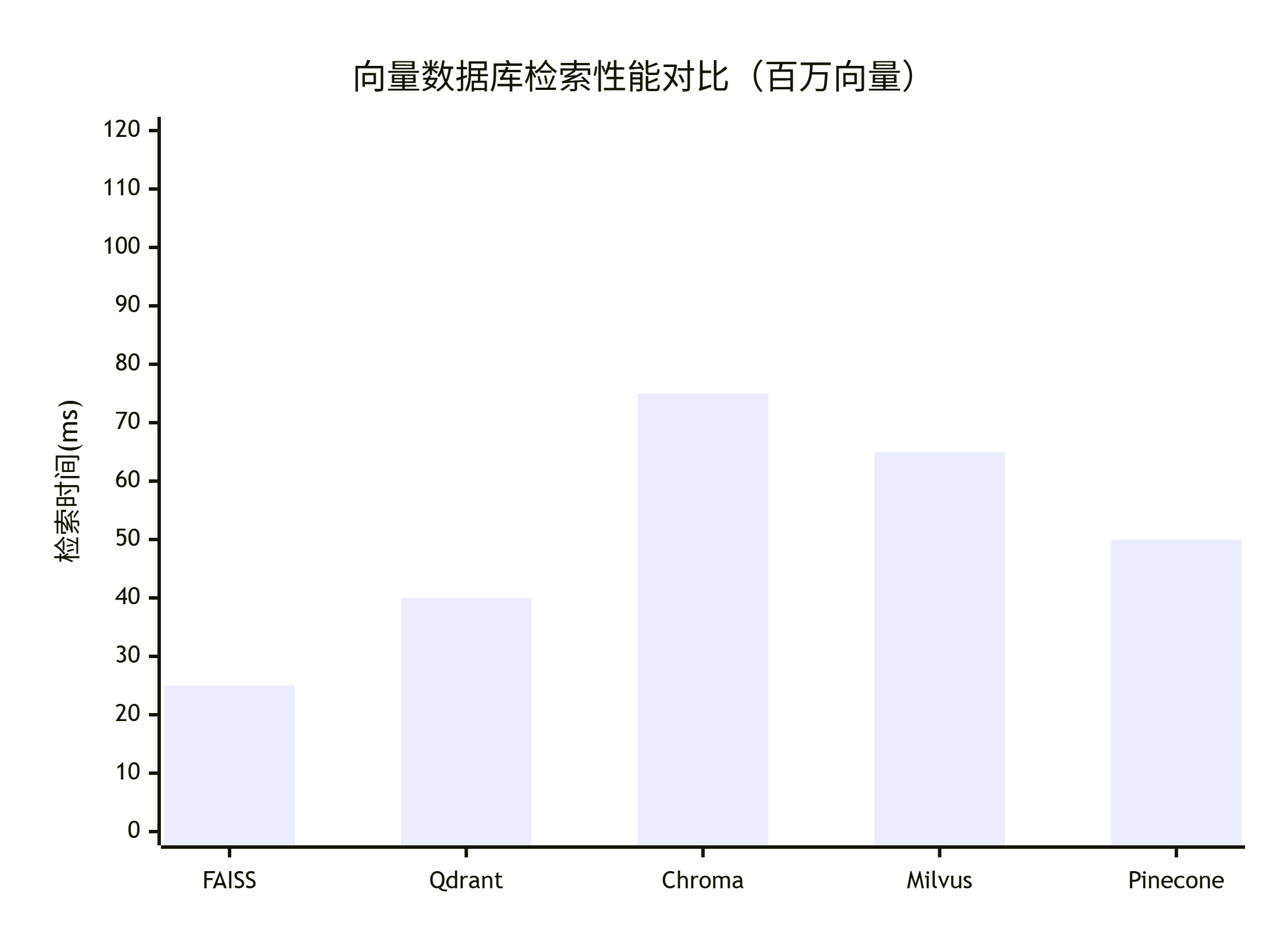
检索性能对比
| 数据库 | 百万向量检索时间 | 索引大小 | 内存占用 |
|---|---|---|---|
| Chroma | 50-100ms | 中等 | 低 |
| FAISS | 10-50ms | 小 | 低 |
| Pinecone | 20-80ms | 云端 | 无 |
| Milvus | 30-100ms | 中等 | 中等 |
| Qdrant | 20-60ms | 小 | 低 |
性能基准测试
4.1.5 向量数据库选择指南
选择决策树
小<100万
中100万-1亿
大>1亿
是
否
是
否
需要向量数据库
数据规模?
需要托管?
需要分布式?
Pinecone/Milvus集群
Pinecone
Chroma/FAISS
Milvus
Qdrant
选择因素权重
30% 25% 20% 15% 10% 向量数据库选择因素重要性 性能 易用性 成本 可扩展性 功能完整性
4.1.6 向量数据库在AI Agent中的价值量化
价值分析
40% 30% 20% 10% 向量数据库在AI Agent中的价值分布 知识检索 语义理解 性能优化 可扩展性
性能提升数据
| 指标 | 无向量数据库 | 使用向量数据库 | 提升 |
|---|---|---|---|
| 检索速度 | 秒级(全扫描) | 毫秒级(索引) | ⬆️ 100-1000倍 |
| 检索准确率 | 60-70% | 85-95% | ⬆️ 25-35% |
| 可扩展性 | 受限 | 几乎无限 | ⬆️ 无限 |
| 成本 | 高(全扫描) | 低(索引) | ⬇️ 80-90% |
4.1.7 向量数据库最佳实践
✅ 推荐做法
- 选择合适的索引:根据数据规模选择HNSW或IVF
- 向量维度优化:使用合适的embedding维度
- 批量操作:批量插入提高性能
- 定期更新:及时更新向量索引
- 监控性能:监控检索时间和准确率
- 备份策略:定期备份向量数据
❌ 避免做法
- 忽略索引构建:不构建索引会导致性能极差
- 维度不匹配:确保所有向量维度一致
- 过度索引:过多索引会占用大量内存
- 忽略更新:文档更新后不及时更新向量
- 缺乏监控:不监控性能可能导致问题
4.2 向量数据库原理
相似度计算
python
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 余弦相似度(最常用)
def cosine_similarity_manual(vec1, vec2):
"""
计算两个向量的余弦相似度
"""
dot_product = np.dot(vec1, vec2)
norm1 = np.linalg.norm(vec1)
norm2 = np.linalg.norm(vec2)
return dot_product / (norm1 * norm2)
# 示例
vec1 = np.array([1, 2, 3])
vec2 = np.array([2, 4, 6])
similarity = cosine_similarity_manual(vec1, vec2)
print(f"余弦相似度: {similarity}") # 1.0(完全相似)向量索引算法
1. 暴力搜索(Brute Force)
- 计算查询向量与所有向量的相似度
- 时间复杂度: O(n)
- 适用于小规模数据
2. 近似最近邻(ANN)
- LSH (Locality-Sensitive Hashing)
- HNSW (Hierarchical Navigable Small World)
- IVF (Inverted File Index)
- 时间复杂度: O(log n)
- 适用于大规模数据4.3 主流向量数据库对比
| 数据库 | 类型 | 特点 | 适用场景 |
|---|---|---|---|
| Chroma | 开源 | 轻量级,易用 | 开发、小规模应用 |
| FAISS | 开源 | Facebook开发,性能高 | 大规模相似度搜索 |
| Pinecone | 云端 | 托管服务,易用 | 生产环境 |
| Milvus | 开源 | 功能完整,可扩展 | 企业级应用 |
| Qdrant | 开源 | Rust开发,性能好 | 高性能需求 |
| Weaviate | 开源 | 图数据库+向量 | 复杂关系查询 |
4.4 Chroma使用
基础操作
python
import chromadb
from chromadb.config import Settings
# 创建客户端
client = chromadb.Client(Settings(
chroma_db_impl="duckdb+parquet",
persist_directory="./chroma_db"
))
# 创建集合(Collection)
collection = client.create_collection(
name="my_collection",
metadata={"description": "我的文档集合"}
)
# 添加文档
collection.add(
documents=[
"这是第一个文档",
"这是第二个文档",
"这是第三个文档"
],
ids=["doc1", "doc2", "doc3"],
metadatas=[
{"source": "file1.txt"},
{"source": "file2.txt"},
{"source": "file3.txt"}
]
)
# 查询
results = collection.query(
query_texts=["第一个"],
n_results=2
)
print(results)与LangChain集成
python
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
# 创建向量存储
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db"
)
# 持久化
vectorstore.persist()
# 加载已存在的向量存储
vectorstore = Chroma(
persist_directory="./chroma_db",
embedding_function=embeddings
)4.5 FAISS使用
基础操作
python
import faiss
import numpy as np
# 创建索引
dimension = 768 # 向量维度
index = faiss.IndexFlatL2(dimension) # L2距离索引
# 添加向量
vectors = np.random.random((1000, dimension)).astype('float32')
index.add(vectors)
# 搜索
query_vector = np.random.random((1, dimension)).astype('float32')
k = 5 # 返回top-5
distances, indices = index.search(query_vector, k)
print(f"最相似的5个向量索引: {indices}")
print(f"距离: {distances}")高级索引
python
# HNSW索引(高性能)
index_hnsw = faiss.IndexHNSWFlat(dimension, 32) # 32是连接数
index_hnsw.add(vectors)
# IVF索引(大规模数据)
nlist = 100 # 聚类中心数
quantizer = faiss.IndexFlatL2(dimension)
index_ivf = faiss.IndexIVFFlat(quantizer, dimension, nlist)
index_ivf.train(vectors) # 需要先训练
index_ivf.add(vectors)
# 搜索
distances, indices = index_ivf.search(query_vector, k)与LangChain集成
python
from langchain.vectorstores import FAISS
# 创建FAISS向量存储
vectorstore = FAISS.from_documents(
documents=chunks,
embedding=embeddings
)
# 保存
vectorstore.save_local("./faiss_index")
# 加载
vectorstore = FAISS.load_local(
"./faiss_index",
embeddings
)
# 搜索
docs = vectorstore.similarity_search("查询文本", k=5)4.6 Pinecone使用
设置和操作
python
import pinecone
from langchain.vectorstores import Pinecone
# 初始化
pinecone.init(
api_key="your-api-key",
environment="us-east1"
)
# 创建索引
index_name = "my-index"
if index_name not in pinecone.list_indexes():
pinecone.create_index(
name=index_name,
dimension=1536, # OpenAI embedding维度
metric="cosine"
)
# 获取索引
index = pinecone.Index(index_name)
# 与LangChain集成
vectorstore = Pinecone.from_documents(
documents=chunks,
embedding=embeddings,
index_name=index_name
)
# 查询
docs = vectorstore.similarity_search("查询", k=5)4.7 Milvus使用
基础操作
python
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType
# 连接Milvus
connections.connect(
alias="default",
host="localhost",
port="19530"
)
# 定义Schema
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=768)
]
schema = CollectionSchema(
fields=fields,
description="文档向量集合"
)
# 创建集合
collection = Collection(
name="my_collection",
schema=schema
)
# 创建索引
index_params = {
"metric_type": "L2",
"index_type": "IVF_FLAT",
"params": {"nlist": 1024}
}
collection.create_index(
field_name="embedding",
index_params=index_params
)
# 加载集合
collection.load()
# 插入数据
data = [
[1, 2, 3], # ids
["doc1", "doc2", "doc3"], # texts
[[0.1]*768, [0.2]*768, [0.3]*768] # embeddings
]
collection.insert(data)
# 搜索
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
results = collection.search(
data=[[0.1]*768], # 查询向量
anns_field="embedding",
param=search_params,
limit=5
)4.8 向量数据库选择指南
选择因素
1. 数据规模
- 小规模(<100万): Chroma, FAISS
- 中规模(100万-1亿): Milvus, Qdrant
- 大规模(>1亿): Pinecone, Milvus集群
2. 部署方式
- 本地: Chroma, FAISS, Milvus
- 云端: Pinecone, Weaviate Cloud
3. 性能要求
- 高吞吐: FAISS, Milvus
- 低延迟: Qdrant, Pinecone
4. 功能需求
- 基础检索: Chroma, FAISS
- 元数据过滤: Milvus, Qdrant
- 图关系: Weaviate4.9 向量数据库最佳实践
实践1: 向量维度选择
python
# 不同模型的向量维度
EMBEDDING_DIMENSIONS = {
"text-embedding-ada-002": 1536, # OpenAI
"text-embedding-3-small": 1536, # OpenAI
"text-embedding-3-large": 3072, # OpenAI
"all-MiniLM-L6-v2": 384, # Sentence Transformers
"all-mpnet-base-v2": 768, # Sentence Transformers
"bge-large-zh": 1024 # 中文模型
}实践2: 批量操作
python
# 批量插入(提高性能)
def batch_insert(vectorstore, documents, batch_size=100):
"""
批量插入文档
"""
for i in range(0, len(documents), batch_size):
batch = documents[i:i+batch_size]
vectorstore.add_documents(batch)
print(f"已插入 {i+len(batch)}/{len(documents)} 个文档")实践3: 索引优化
python
# FAISS索引优化
def create_optimized_index(vectors, dimension):
"""
创建优化的FAISS索引
"""
# 对于大规模数据,使用IVF + HNSW
nlist = min(4096, len(vectors) // 100)
quantizer = faiss.IndexHNSWFlat(dimension, 32)
index = faiss.IndexIVFPQ(
quantizer, dimension, nlist, 8, 8 # PQ压缩
)
index.train(vectors)
index.add(vectors)
return index