⭐ 深度学习入门体系(第 7 篇): 什么是损失函数?
------为什么交叉熵几乎是所有分类任务的默认选择?
在深度学习训练流程里,你一定见过一句话:
"模型要通过反向传播最小化损失函数。"
但很多同学会疑惑:
- 损失函数到底是什么?
- 为什么训练模型需要一个"损失"?
- 回归用 MSE,分类用交叉熵,这种约定到底是怎么来的?
- 交叉熵为什么比 MSE 更适合分类?
- 损失函数和优化器的关系是什么?
这篇文章会把这些问题讲透,用生活化类比帮你建立清晰的"直觉理解",不用死记公式也能说清楚。
文章目录
- [⭐ 深度学习入门体系(第 7 篇): 什么是损失函数?](#⭐ 深度学习入门体系(第 7 篇): 什么是损失函数?)
- [🎯 一、什么是损失函数?一句话解释](#🎯 一、什么是损失函数?一句话解释)
- [🧪 二、为什么训练模型必须有损失函数?](#🧪 二、为什么训练模型必须有损失函数?)
- [📉 三、损失与反向传播是什么关系?](#📉 三、损失与反向传播是什么关系?)
- [🧱 四、不同任务为什么要不同损失函数?](#🧱 四、不同任务为什么要不同损失函数?)
- [🎯 五、为什么分类任务常用"交叉熵"?](#🎯 五、为什么分类任务常用“交叉熵”?)
- [🥤 类比:买饮料选择的"信心程度"](#🥤 类比:买饮料选择的“信心程度”)
- [📌 六、为什么 MSE 不适合分类?(非常重要)](#📌 六、为什么 MSE 不适合分类?(非常重要))
- [🧨 七、交叉熵的本质一句话总结](#🧨 七、交叉熵的本质一句话总结)
- [🧪 八、分类任务中的交叉熵到底怎么计算?(直观理解版)](#🧪 八、分类任务中的交叉熵到底怎么计算?(直观理解版))
- [🎨 九、一些常见损失函数的直观解释](#🎨 九、一些常见损失函数的直观解释)
-
- [① MSE(均方误差)](#① MSE(均方误差))
- [② MAE(平均绝对误差)](#② MAE(平均绝对误差))
- [③ BCE(二分类交叉熵)](#③ BCE(二分类交叉熵))
- [④ Dice Loss / IoU Loss](#④ Dice Loss / IoU Loss)
- [⑤ Smooth L1](#⑤ Smooth L1)
- [🧱 十、损失函数 + 优化器 = 才能训练模型](#🧱 十、损失函数 + 优化器 = 才能训练模型)
- [🧭 十一、30 秒掌握本篇内容](#🧭 十一、30 秒掌握本篇内容)
- [🔜 下一篇](#🔜 下一篇)
🎯 一、什么是损失函数?一句话解释
损失函数就是"用来衡量模型犯错程度的标尺"。
模型预测得越准,损失越小;
预测得越差,损失越大。
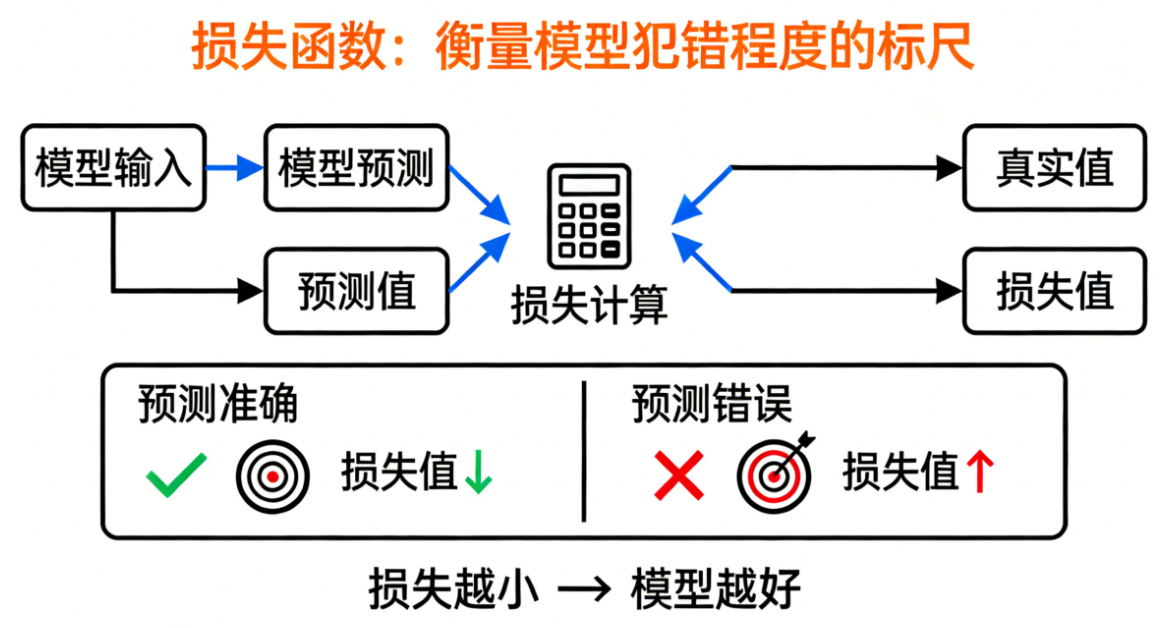
🧪 二、为什么训练模型必须有损失函数?
我们再用一个非常"生活化"的比喻。
想象你在学投篮:
- 你投歪了
- 你需要知道"偏多少"、"往哪偏"、"偏得离谱不离谱"
- 这样你才能不断调整姿势
损失函数就是告诉模型:
你现在"投歪了多少"。
没有损失,它根本不知道如何调整。
📉 三、损失与反向传播是什么关系?
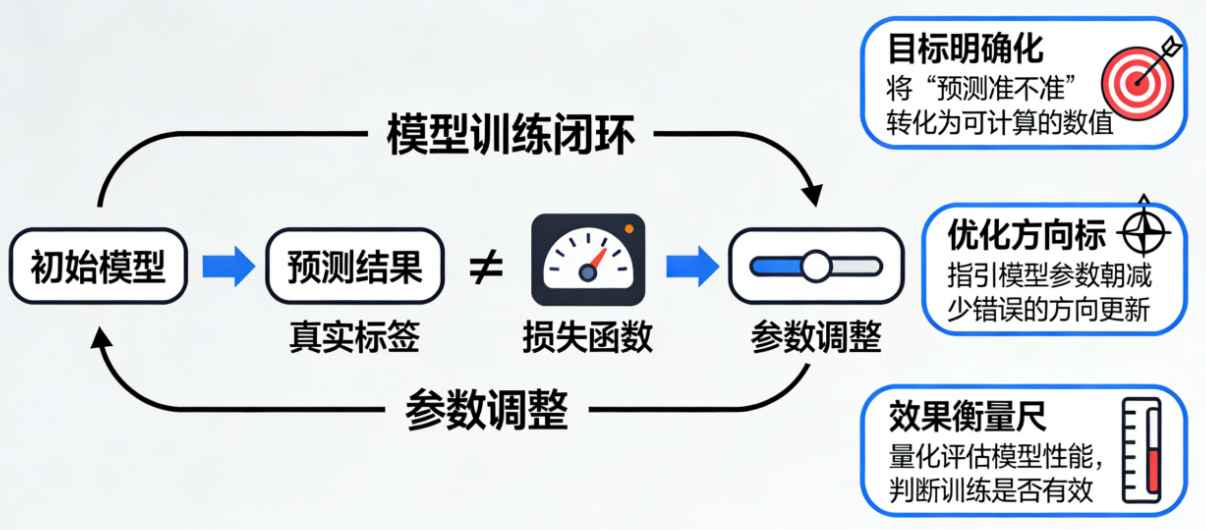
整个深度学习训练过程可以总结为一句话:
模型根据损失的大小决定"往哪个方向改变自身参数"。
损失像地图上的"高度",
模型的任务就是沿着最快下降的方向走,
不断调低损失,直到找到一个"低谷"。
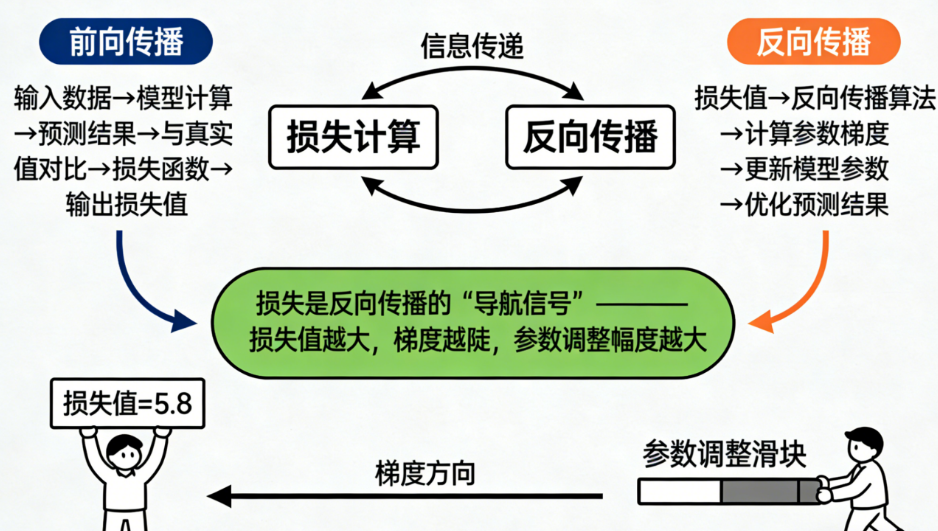
这个下降路径就是"反向传播"(Backpropagation)实现的。
不用背公式,只需要理解:
损失给出"方向",优化器决定"走法",模型负责"移动"。
🧱 四、不同任务为什么要不同损失函数?
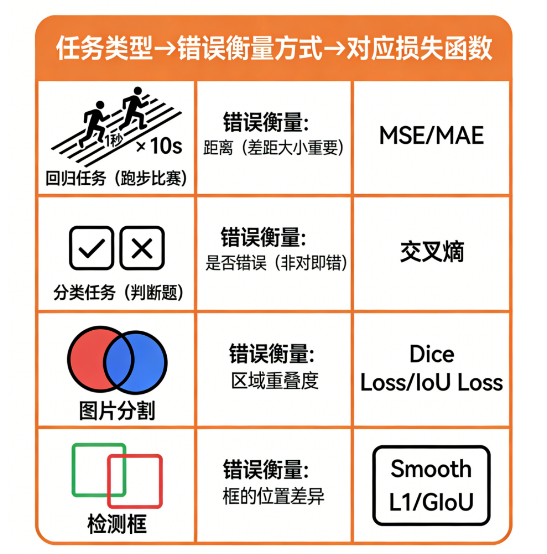
因为不同任务的"错误衡量方式"不同。
日常类比非常简单:
-
比赛跑步(回归任务)
你在意的是距离差:
差 1 秒 vs 差 10 秒本质不同。
------对应 MSE / MAE
-
判断题(分类任务)
你在意的是对 OR 错,而不是错多少度。
------对应交叉熵
-
图片分割
你关注"两个区域重叠程度"
------Dice Loss / IoU Loss
-
检测框
你关注"框的位置差异"
------Smooth L1 / GIoU
所以:
不同问题 = 不同错误形式 = 用不同损失衡量更科学。
🎯 五、为什么分类任务常用"交叉熵"?
这是初学者最困惑的问题,我们用生活类比讲明白。
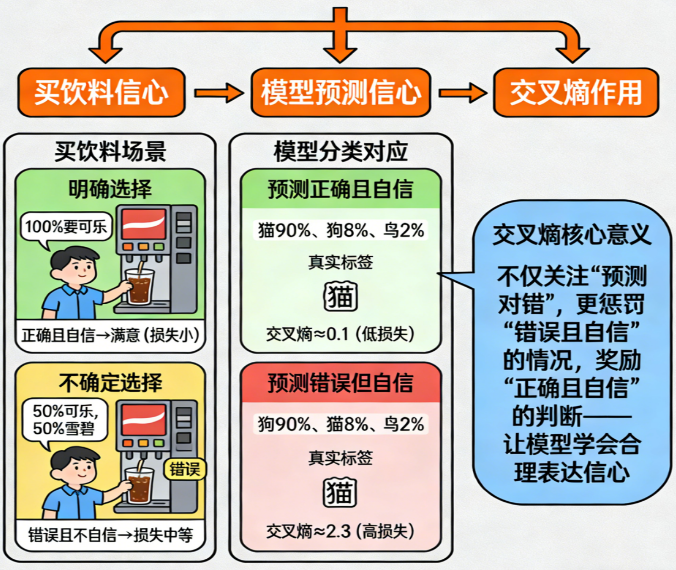
🥤 类比:买饮料选择的"信心程度"
假设你去便利店买饮料,店员问:
你确定自己要买哪种饮料吗?
你可能回答:
- 我 100% 就是要可乐(明确)
- 我大概 50% 想喝可乐,50% 想喝雪碧(不确定)
模型做分类也是一样:
- softmax 给出每个类别的"概率"
- 交叉熵用来衡量"模型有多确定地预测错了"
你希望:
- 预测错误但不自信 → 损失小
- 预测错误但超级自信 → 损失巨大
- 预测正确且自信 → 损失很小
这就是交叉熵最核心的意义:
交叉熵不仅关心你"对不对",还关心你"信心是否合理"。
📌 六、为什么 MSE 不适合分类?(非常重要)
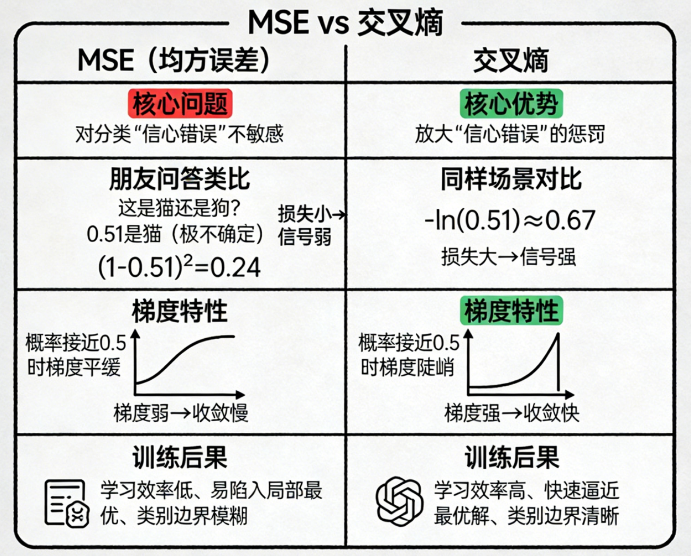
很多新手可能想:
分类也只是 0 和 1,那是不是也能用 MSE?
理论上可以,但效果很烂。
原因也可以类比。
假设你问朋友:
"这是猫还是狗?"
朋友回答:
- 我觉得 0.51 是猫(非常不确定)
- 你说:好,算对了,奖励你 0.49 分(因为差 1 - 0.51 = 0.49)
模型得到的信号非常弱。
MSE 对分类的梯度非常小,会导致:
- 梯度弱
- 收敛慢
- 训练困难
- 越靠近最终类别越难学
而交叉熵在这种情况下会"狠狠地惩罚":
预测正确但特别不自信 → 损失依然大
这让训练信号更强、学习更快。
🧨 七、交叉熵的本质一句话总结
如果你只能记住一句话:
交叉熵奖励"正确并且自信",
惩罚"错误并且自信"。
这正是分类任务需要的行为。

🧪 八、分类任务中的交叉熵到底怎么计算?(直观理解版)
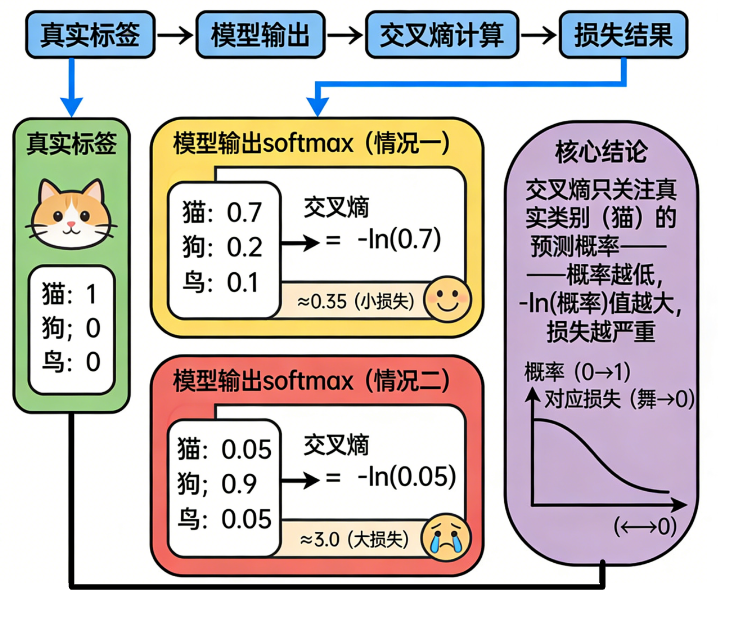
不用公式,我们这样理解:
假设真实标签是:
- 猫:1
- 狗:0
- 鸟:0
模型输出 softmax:
- 猫:0.7
- 狗:0.2
- 鸟:0.1
交叉熵只看"真实类别"的概率,也就是猫的:
-0.7 的 log 值 → 一个小小的损失
如果模型输出:
- 猫:0.05
- 狗:0.9
- 鸟:0.05
那损失是:
-log(0.05) → 超大
这就解释了为什么交叉熵这么敏感。
🎨 九、一些常见损失函数的直观解释
为了让你以后选损失更清晰,我们给几个常用类型做"生活解释"。
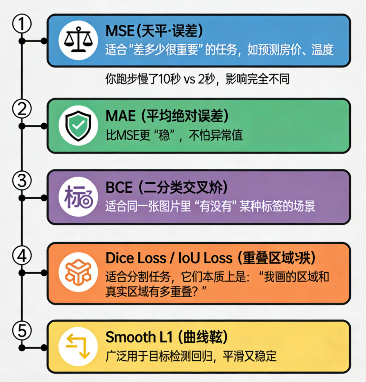
① MSE(均方误差)
适合"差多少很重要"的任务,比如预测房价、温度。
像:你跑步慢了 10 秒 vs 2 秒,影响完全不同。
② MAE(平均绝对误差)
比 MSE 更"稳",不怕异常值。
③ BCE(二分类交叉熵)
适合同一张图片里"有/没有某种标签"的场景。
④ Dice Loss / IoU Loss
适合分割任务,它们本质上是:
"我画的区域和真实区域有多重叠?"
⑤ Smooth L1
广泛用于目标检测框回归,平滑又稳定。
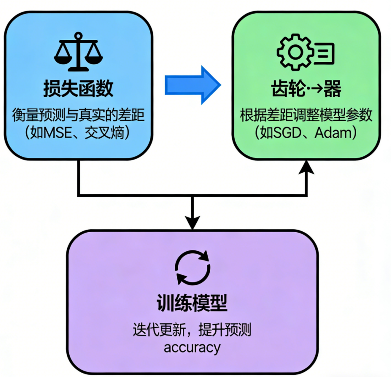
🧱 十、损失函数 + 优化器 = 才能训练模型
很多新手会把损失函数和优化器搞混。
简单解释:
- 损失函数告诉模型:"犯错多少?"
- 优化器告诉模型:"怎么改才更好?"
两者合作才能完成训练。
一个直观类比:
- 损失 = 你考试成绩
- 优化器 = 老师告诉你怎么改错
两个缺一不可。
🧭 十一、30 秒掌握本篇内容
- 损失函数是衡量"模型犯错"的标尺
- 没有损失就无法训练
- 不同任务需要不同损失
- 分类任务用交叉熵,因为它能衡量"预测概率的正确性"
- 交叉熵惩罚"错误但自信"的预测
- softmax 生成概率分布
- 交叉熵 + softmax = 分类任务黄金组合
- MSE 不适合分类,因为梯度太弱
- 损失函数负责"告诉模型方向",优化器负责"调整参数"
交叉熵为什么几乎是所有分类默认值?
答案简单又关键:
它能提供强而稳定的梯度,让模型更快更准地学会分类。
🔜 下一篇
《深度学习入门体系(第 8 篇):什么是优化器?为什么 Adam 几乎是所有新手首选?》