链表OJ
前言
本篇讲解两道链表OJ题目
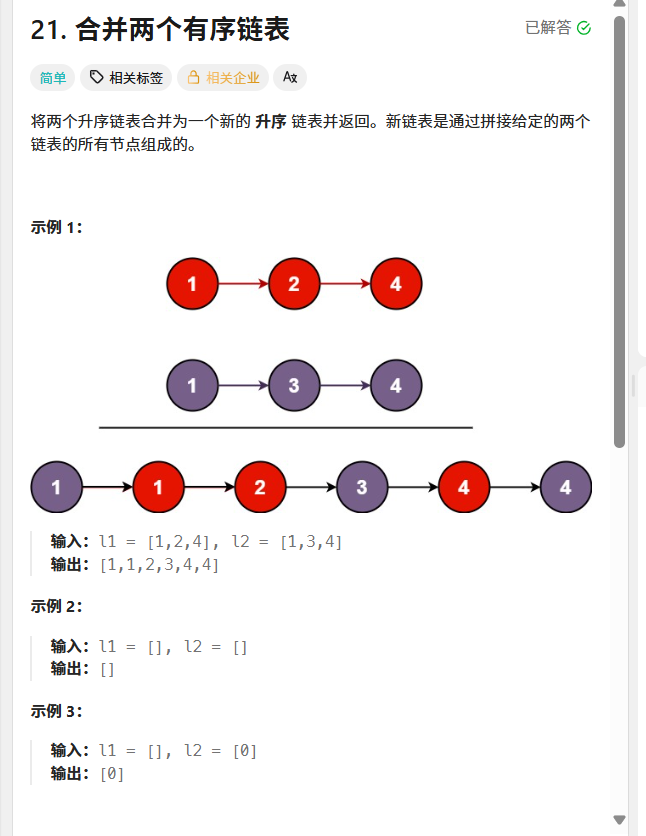
一、合并两个有序链表
题目链接:https://leetcode.cn/problems/merge-two-sorted-lists/description/
本题思路简单,仅需按部就班比较再尾插即可
c
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {
if(list1 == NULL)
return list2;
if(list2 == NULL)
return list1;
struct ListNode* newlist = NULL;
struct ListNode* new = newlist;
struct ListNode* newhead1 = list1;
struct ListNode* newhead2 = list2;
while(newhead1 && newhead2)
{
if(newlist == NULL)
{
if(newhead1->val > newhead2->val)
{
newlist = newhead2;
new = newlist;
newhead2 = newhead2->next;
}
else
{
newlist = newhead1;
new = newlist;
newhead1 = newhead1->next;
}
}
else
{
if(newhead2->val <= newhead1->val)
{
newlist->next = newhead2;
newhead2 = newhead2->next;
newlist = newlist->next;
}
else
{
newlist->next = newhead1;
newhead1 = newhead1->next;
newlist = newlist->next;
}
}
}
if(newhead2)
newlist->next = newhead2;
if(newhead1)
newlist->next = newhead1;
return new;
}二、链表分割
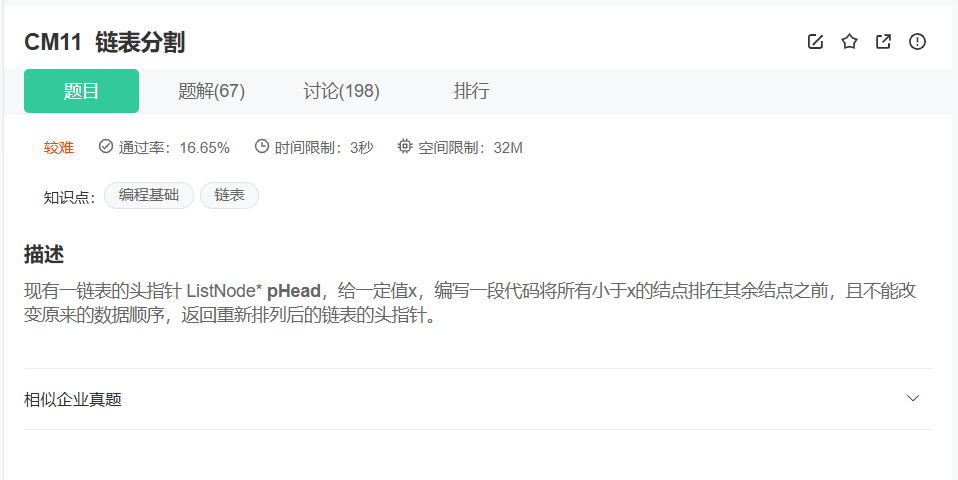
这道题我们有两种思路,先看第一种思路,它有两种实现方式
开辟一个新链表,一个存储大于等于x的结点,另一个存储小于x的结点,最后两个链表链接起来即可
第一种实现方式:
c
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};*/
class Partition {
public:
ListNode* partition(ListNode* pHead, int x) {
// write code here
if(pHead == NULL)
{
return pHead;
}
ListNode* newhead = NULL;
ListNode* newnext = NULL;
ListNode* pnext = pHead;
ListNode* prev = NULL;
ListNode* head = NULL;
while(pnext != NULL)
{
if(pnext->val >= x)
{
if(prev == NULL)
{
prev = pnext;
head = prev;
}
else
{
prev->next = pnext;
prev = prev->next;
}
pnext = pnext->next;
}
else
{
if(newhead == NULL)
{
newhead = pnext;
newnext = newhead;
}
else
{
newnext->next = pnext;
newnext = newnext->next;
}
pnext = pnext->next;
}
}
if(prev == NULL)
{
return newhead;
}
else
{
if(newhead)
{
prev->next = NULL;
newnext->next = head;
}
else
{
prev->next = NULL;
newhead = head;
}
}
return newhead;
}
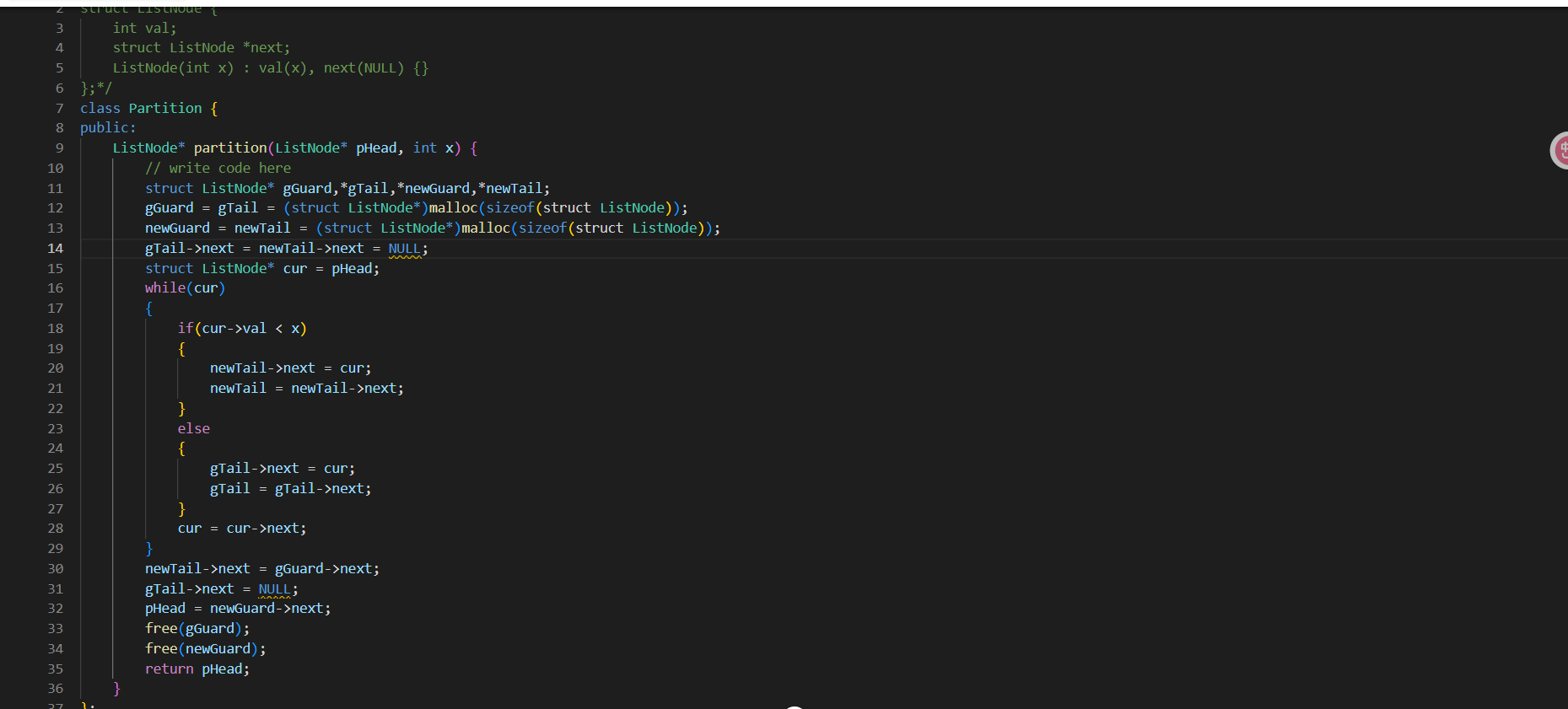
};第二种实现方式:
c
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};*/
class Partition {
public:
ListNode* partition(ListNode* pHead, int x) {
//我们需要先定义四个指针,一个作为新链表,一个一直往后走,遇到小于x的结点则尾插到新链表中
//还有一个保存大于等于x的结点,一个保存下一个结点,并且,要判断之后再更新保存的结点
ListNode* new1 = NULL;
ListNode* newlist = NULL;
ListNode* tail = pHead;
ListNode* store = NULL;
while(tail)
{
if(newlist == NULL)
{
if(tail->val < x)
{
new1 = newlist = tail;
}
else
{
if(store == NULL)
store = tail;
else
{
store->next = tail;
store = store->next;
}
}
tail = tail->next;
}
else
{
if(tail->val < x)
{
newlist->next = tail;
tail = tail->next;
newlist = newlist->next;
}
else
{
if(store == NULL)
store = tail;
else
{
store->next = tail;
store = store->next;
}
tail = tail->next;
}
}
}
if(newlist == NULL)
{
store->next = NULL;
newlist = store;
}
else
{
store->next = NULL;
newlist->next = store;
}
return new1;
}
};第二个思路其实与第一个思路大同小异,关键在于它使用了哨兵结点,使得逻辑更加顺畅、简洁
总结
例如:以上就是今天要讲的内容,本文讲解了链表的两道题目,后续会继续讲解其他进阶题目