研究背景与意义
研究背景与意义
甘蔗作为全球重要的经济作物之一,其产量和质量直接影响到糖业、酒业及生物能源等多个行业的发展。然而,甘蔗在生长过程中常常受到多种病害的侵袭,尤其是叶片病害,这不仅会导致产量下降,还会影响甘蔗的糖分含量和品质。因此,及时、准确地检测和识别甘蔗叶片病害,对于保障甘蔗的健康生长和提高经济效益具有重要意义。
近年来,随着计算机视觉技术的快速发展,基于深度学习的图像识别方法逐渐成为植物病害检测的主流手段。其中,YOLO(You Only Look Once)系列模型因其高效的实时检测能力而备受关注。YOLOv11作为该系列的最新版本,具有更强的特征提取能力和更高的检测精度,能够在复杂的环境中实现对甘蔗叶片病害的精准识别。通过对甘蔗叶片的图像进行实例分割,可以更好地理解病害的分布情况,为后续的防治措施提供科学依据。
本研究旨在基于改进的YOLOv11模型,构建一个高效的甘蔗叶片病害检测系统。我们将利用包含1400张图像的甘蔗叶片数据集,涵盖"叶片"、"马赛克"、"红腐病"和"锈病"四种类别,进行模型训练和评估。通过对数据集的精细标注和多样化的数据增强处理,提升模型的泛化能力和鲁棒性,力求在实际应用中实现高准确率和高召回率的检测效果。
此外,甘蔗叶片病害检测系统的建立,不仅可以为农民提供及时的病害预警,帮助其采取有效的防治措施,还能为农业管理部门提供数据支持,推动智能农业的发展。通过本研究,我们希望能够为甘蔗病害的早期检测和精准防治提供一种新思路,促进农业可持续发展,提升甘蔗产业的整体竞争力。
图片演示
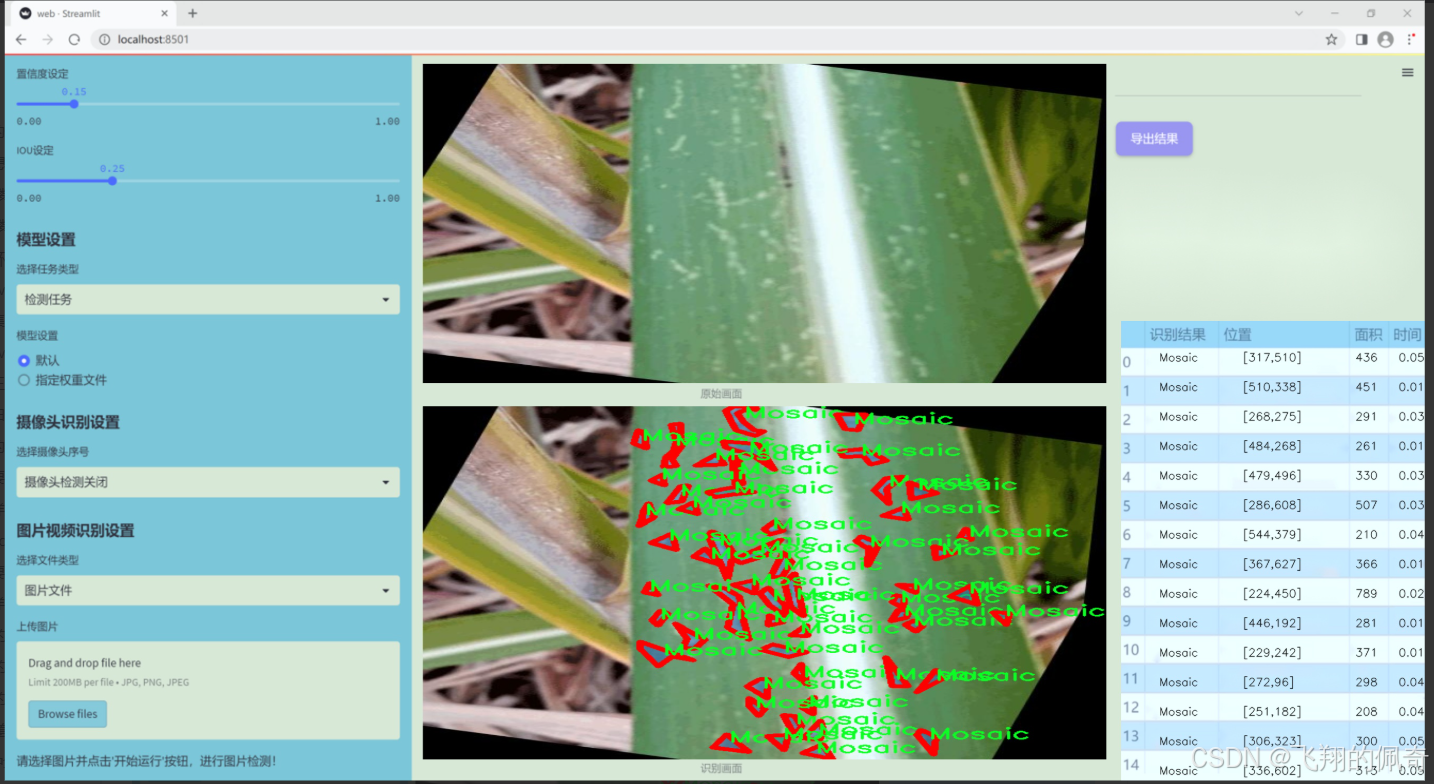
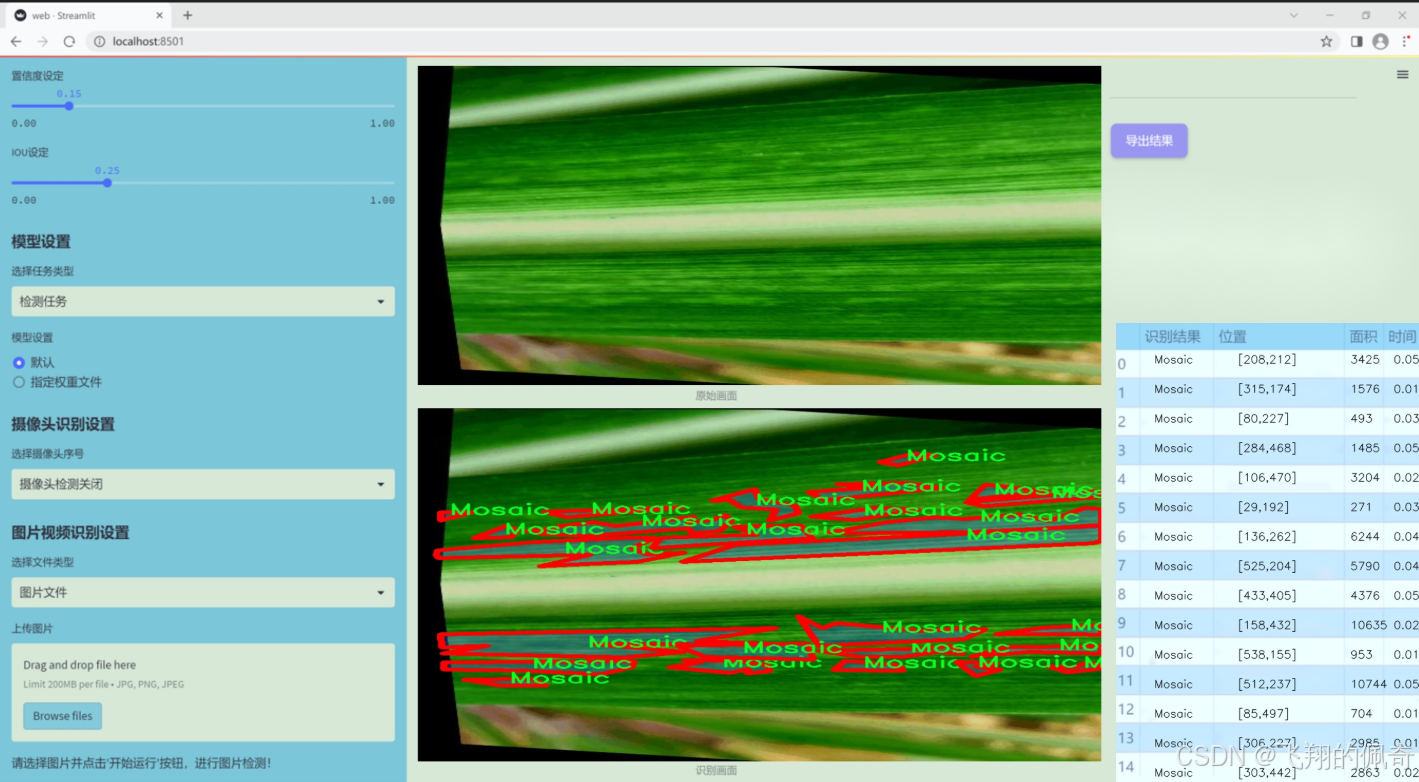
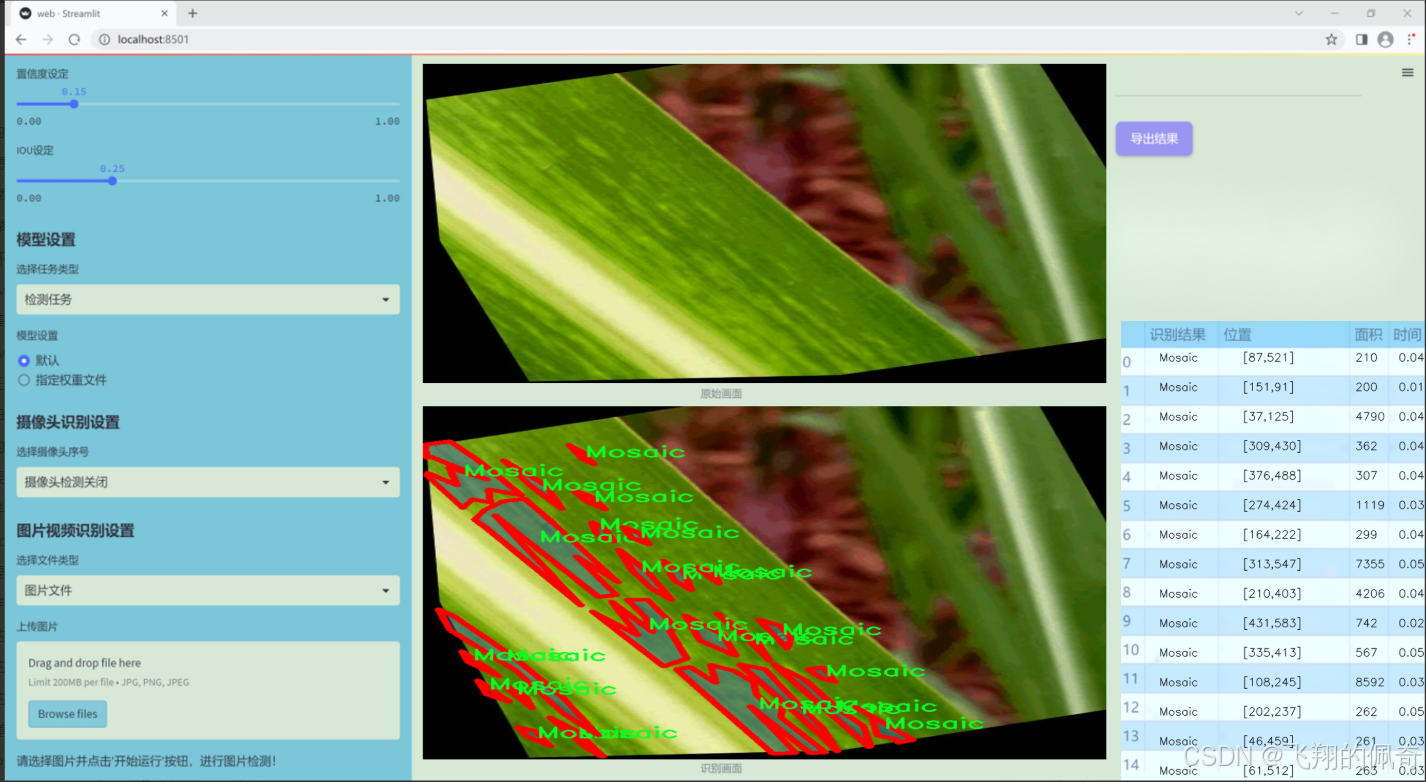
数据集信息展示
本项目数据集信息介绍
本项目所使用的数据集专注于甘蔗叶片的病害检测,旨在通过改进YOLOv11模型,提高对甘蔗叶片病害的识别精度和效率。该数据集包含四个主要类别,分别为"Leaves"(健康叶片)、"Mosaic"(马赛克病)、"Red-Rot"(红腐病)和"Rust"(锈病)。这些类别涵盖了甘蔗叶片在生长过程中可能遭遇的主要病害,具有重要的农业应用价值。
在数据集的构建过程中,我们采集了大量的甘蔗叶片图像,确保每个类别的样本数量均衡且具有代表性。健康叶片的图像提供了一个基准,以便模型能够识别正常的生长状态。而马赛克病、红腐病和锈病的图像则展示了不同病害对叶片外观的影响,帮助模型学习到病害特征的多样性。这种多样化的样本不仅提高了模型的泛化能力,还能有效应对实际应用中可能遇到的各种变异情况。
此外,数据集中的图像经过精心标注,确保每个类别的特征清晰可辨。通过高质量的标注,模型在训练过程中能够准确学习到各类病害的视觉特征,从而在实际应用中实现高效的病害检测。数据集的设计考虑到了不同光照条件、角度和背景的变化,使得模型在面对复杂环境时依然能够保持较高的识别率。
综上所述,本项目的数据集不仅为甘蔗叶片病害检测提供了坚实的基础,也为后续的模型训练和优化奠定了良好的数据支持。通过利用这一数据集,我们期望能够显著提升甘蔗病害的自动检测能力,为农业生产提供更为精准的技术支持。





项目核心源码讲解(再也不用担心看不懂代码逻辑)
以下是经过简化和注释的核心代码部分:
import torch
import torch.nn as nn
from functools import partial
导入自定义的归一化模块
from .prepbn import RepBN, LinearNorm
from ...modules.transformer import TransformerEncoderLayer
定义可用的模块
all = 'AIFI_RepBN'
定义线性归一化的部分应用
ln = nn.LayerNorm
linearnorm = partial(LinearNorm, norm1=ln, norm2=RepBN, step=60000)
class TransformerEncoderLayer_RepBN(TransformerEncoderLayer):
def init (self, c1, cm=2048, num_heads=8, dropout=0, act=..., normalize_before=False):
初始化父类
super().init(c1, cm, num_heads, dropout, act, normalize_before)
# 使用自定义的归一化方法
self.norm1 = linearnorm(c1)
self.norm2 = linearnorm(c1)class AIFI_RepBN(TransformerEncoderLayer_RepBN):
"""定义AIFI变换器层。"""
def __init__(self, c1, cm=2048, num_heads=8, dropout=0, act=nn.GELU(), normalize_before=False):
"""使用指定参数初始化AIFI实例。"""
super().__init__(c1, cm, num_heads, dropout, act, normalize_before)
def forward(self, x):
"""AIFI变换器层的前向传播。"""
c, h, w = x.shape[1:] # 获取输入的通道数、高度和宽度
pos_embed = self.build_2d_sincos_position_embedding(w, h, c) # 构建位置嵌入
# 将输入张量从形状[B, C, H, W]展平为[B, HxW, C]
x = super().forward(x.flatten(2).permute(0, 2, 1), pos=pos_embed.to(device=x.device, dtype=x.dtype))
# 将输出张量的形状转换回[B, C, H, W]
return x.permute(0, 2, 1).view([-1, c, h, w]).contiguous()
@staticmethod
def build_2d_sincos_position_embedding(w, h, embed_dim=256, temperature=10000.0):
"""构建2D正弦-余弦位置嵌入。"""
assert embed_dim % 4 == 0, "嵌入维度必须是4的倍数,以便进行2D正弦-余弦位置嵌入"
# 创建宽度和高度的网格
grid_w = torch.arange(w, dtype=torch.float32)
grid_h = torch.arange(h, dtype=torch.float32)
grid_w, grid_h = torch.meshgrid(grid_w, grid_h, indexing="ij")
pos_dim = embed_dim // 4 # 计算位置维度
omega = torch.arange(pos_dim, dtype=torch.float32) / pos_dim
omega = 1.0 / (temperature**omega) # 温度缩放
# 计算位置嵌入
out_w = grid_w.flatten()[..., None] @ omega[None]
out_h = grid_h.flatten()[..., None] @ omega[None]
# 返回拼接的正弦和余弦嵌入
return torch.cat([torch.sin(out_w), torch.cos(out_w), torch.sin(out_h), torch.cos(out_h)], 1)[None]代码说明:
导入模块:导入了必要的PyTorch模块和自定义的归一化模块。
归一化设置:使用partial函数定义了线性归一化和自定义的RepBN归一化的组合。
TransformerEncoderLayer_RepBN类:继承自TransformerEncoderLayer,初始化时设置了两个归一化层。
AIFI_RepBN类:继承自TransformerEncoderLayer_RepBN,实现了AIFI变换器层的初始化和前向传播。
前向传播:在forward方法中,输入张量被展平并传递给父类的前向方法,同时生成并使用位置嵌入。
位置嵌入构建:build_2d_sincos_position_embedding静态方法生成2D正弦-余弦位置嵌入,确保嵌入维度是4的倍数,并使用温度缩放。
这个程序文件 transformer.py 定义了一个基于 Transformer 架构的模型,主要包含了 AIFI(Attention with Information Flow Injection)层的实现,并使用了改进的归一化方法(RepBN)。以下是对代码的详细讲解。
首先,文件导入了必要的 PyTorch 库和模块,包括 torch、torch.nn 和 torch.nn.functional,这些都是构建神经网络所需的基础组件。此外,还导入了 RepBN 和 LinearNorm 这两个自定义的归一化模块,以及 TransformerEncoderLayer 和 AIFI 模块。
接下来,定义了一个名为 linearnorm 的部分函数,它是 LinearNorm 的一个实例,使用了 LayerNorm 和 RepBN 作为归一化方法,并设定了一个步数参数为 60000。这一设置为后续的模型层提供了灵活的归一化选项。
然后,定义了 TransformerEncoderLayer_RepBN 类,它继承自 TransformerEncoderLayer。在初始化方法中,调用了父类的构造函数,并定义了两个归一化层 norm1 和 norm2,它们都是使用 linearnorm 创建的。这使得该层在前向传播时可以使用改进的归一化策略。
接着,定义了 AIFI_RepBN 类,它继承自 TransformerEncoderLayer_RepBN,并且是 AIFI transformer 层的具体实现。在初始化方法中,除了调用父类的构造函数外,还可以指定激活函数(默认为 GELU),以及其他参数。
在 forward 方法中,首先获取输入张量 x 的形状信息(通道数 c、高度 h 和宽度 w)。然后,调用 build_2d_sincos_position_embedding 方法生成二维的正弦余弦位置嵌入,这对于处理图像数据时保持空间信息是非常重要的。接下来,将输入张量 x 进行展平和维度变换,以适应 Transformer 的输入格式。最后,调用父类的 forward 方法进行前向传播,并将输出结果重新排列为原始的形状。
build_2d_sincos_position_embedding 是一个静态方法,用于构建二维的正弦余弦位置嵌入。该方法首先检查嵌入维度是否能被 4 整除,这是为了满足正弦余弦嵌入的要求。然后,通过生成网格坐标并计算对应的正弦和余弦值,返回一个包含位置嵌入的张量。
总的来说,这个文件实现了一个基于 Transformer 的编码层,结合了 AIFI 的注意力机制和改进的归一化方法,适用于处理图像等高维数据。
10.3 block.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""自动填充以保持输出形状不变。"""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else d \* (x - 1) + 1 for x in k # 实际的卷积核大小
if p is None:
p = k // 2 if isinstance(k, int) else x // 2 for x in k # 自动填充
return p
class Conv(nn.Module):
"""定义卷积层,包含卷积、批归一化和激活函数。"""
def init (self, in_channels, out_channels, kernel_size=3, stride=1, padding=None, groups=1, act=True):
super().init ()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, autopad(kernel_size, padding), groups=groups, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.SiLU() if act else nn.Identity() # 使用SiLU激活函数
def forward(self, x):
"""前向传播。"""
return self.act(self.bn(self.conv(x)))class Bottleneck(nn.Module):
"""标准瓶颈模块,包含两个卷积层。"""
def init (self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
super().init ()
c_ = int(c2 * e) # 隐藏通道数
self.cv1 = Conv(c1, c_, k0, 1) # 第一个卷积层
self.cv2 = Conv(c_, c2, k1, 1, g=g) # 第二个卷积层
self.add = shortcut and c1 == c2 # 是否使用快捷连接
def forward(self, x):
"""前向传播。"""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class C3k(nn.Module):
"""C3k模块,包含多个瓶颈模块。"""
def init (self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=3):
super().init ()
self.m = nn.Sequential(*(Bottleneck(c1, c2, shortcut, g, k=(k, k), e=e) for _ in range(n))) # 创建n个瓶颈模块
def forward(self, x):
"""前向传播。"""
return self.m(x)class C3k2(nn.Module):
"""C3k2模块,包含多个C3k模块。"""
def init (self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
super().init ()
self.m = nn.ModuleList(C3k(c1, c2, n, shortcut, g, e) for _ in range(n)) # 创建n个C3k模块
def forward(self, x):
"""前向传播。"""
for m in self.m:
x = m(x) # 依次通过每个模块
return xclass FocusFeature(nn.Module):
"""特征聚焦模块,结合了不同特征图的上下文信息。"""
def init (self, inc, kernel_sizes=(3, 5, 7, 9, 11), e=0.5):
super().init ()
hidc = int(inc1 * e) # 隐藏通道数
self.conv1 = Conv(inc[0], hidc, 1, 1) # 1x1卷积
self.conv2 = Conv(inc[1], hidc, 1) # 1x1卷积
self.conv3 = ADown(inc[2], hidc) # 下采样卷积
self.dw_conv = nn.ModuleList(nn.Conv2d(hidc * 3, hidc * 3, kernel_size=k, padding=autopad(k), groups=hidc * 3) for k in kernel_sizes) # 多尺度卷积
self.pw_conv = Conv(hidc * 3, hidc * 3) # 1x1卷积
def forward(self, x):
"""前向传播。"""
x1, x2, x3 = x # 分别获取三个输入特征图
x1 = self.conv1(x1) # 处理第一个特征图
x2 = self.conv2(x2) # 处理第二个特征图
x3 = self.conv3(x3) # 处理第三个特征图
x = torch.cat([x1, x2, x3], dim=1) # 连接三个特征图
feature = torch.sum(torch.stack([x] + [layer(x) for layer in self.dw_conv], dim=0), dim=0) # 多尺度卷积
feature = self.pw_conv(feature) # 1x1卷积
x = x + feature # 残差连接
return x # 返回结果以上是核心部分的代码和详细注释,涵盖了网络结构、模块功能及其前向传播过程。
以上代码片段展示了深度学习模型中的一些核心模块,包括卷积层、瓶颈模块、特征聚焦模块等。每个模块都有其特定的功能和结构,通过注释详细解释了每个部分的作用和前向传播的过程。
这个程序文件 block.py 定义了一系列用于深度学习模型的模块,主要集中在卷积神经网络(CNN)和注意力机制的实现上。以下是对文件中主要内容的说明:
首先,文件引入了多个必要的库,包括 torch 和 torch.nn,以及一些自定义的模块和函数。这些库和模块为后续的网络结构提供了基础。
文件中定义了多个类,主要分为以下几类:
卷积和注意力模块:文件中定义了多种卷积层(如 Conv、DWConv、DSConv 等),这些卷积层可能包含不同的激活函数和归一化层。注意力机制的实现也有多种,如 GOLDYOLO_Attention、SMA、PSA 等,利用这些机制可以增强模型对特征的关注能力。
基础模块:如 Bottleneck、C3k 和 C3k2 等,这些模块通常是构建更复杂网络的基础单元。它们实现了基本的卷积操作和残差连接,常用于构建深层网络。
特定结构的模块:如 CSPStage、C3k_Faster、C3k2_Faster 等,这些模块实现了特定的网络结构,可能结合了不同的卷积层和注意力机制,以实现更好的特征提取和融合。
自适应和动态模块:如 DynamicConv、DynamicInterpolationFusion 等,这些模块允许在运行时根据输入的特征动态调整卷积操作的参数,增强了模型的灵活性。
融合模块:如 Fusion、AdvPoolFusion、DynamicAlignFusion 等,这些模块用于将来自不同来源的特征进行融合,以提高模型的表现。
上采样和下采样模块:如 WaveletPool、WaveletUnPool、V7DownSampling 等,这些模块实现了特征图的上采样和下采样操作,常用于构建特征金字塔网络(FPN)。
其他模块:文件中还定义了一些其他的模块,如 SEAM、SDFM、CSP_PTB 等,这些模块结合了不同的特征处理方法,旨在提高模型的性能。
整体而言,block.py 文件构建了一个复杂的深度学习模型框架,包含了多种卷积、注意力机制和特征融合的实现,适用于图像处理、目标检测等任务。每个模块都可以单独使用或组合使用,以构建出不同的网络结构。
10.4 ui.py
import sys
import subprocess
def run_script(script_path):
"""
使用当前 Python 环境运行指定的脚本。
Args:
script_path (str): 要运行的脚本路径
Returns:
None
"""
# 获取当前 Python 解释器的路径
python_path = sys.executable
# 构建运行命令,使用 streamlit 运行指定的脚本
command = f'"{python_path}" -m streamlit run "{script_path}"'
# 执行命令,并等待其完成
result = subprocess.run(command, shell=True)
# 检查命令执行的返回码,如果不为0,表示出错
if result.returncode != 0:
print("脚本运行出错。")实例化并运行应用
if name == "main ":
指定要运行的脚本路径
script_path = "web.py" # 假设脚本在当前目录下
# 调用函数运行脚本
run_script(script_path)代码核心部分及注释说明:
导入模块:
import sys:用于访问与 Python 解释器相关的变量和函数。
import subprocess:用于执行外部命令和管理子进程。
定义 run_script 函数:
该函数接受一个参数 script_path,表示要运行的 Python 脚本的路径。
函数内部首先获取当前 Python 解释器的路径,以便后续执行脚本。
构建命令:
使用 streamlit 模块运行指定的脚本,构建命令字符串。
执行命令:
使用 subprocess.run 方法执行构建的命令,并等待其完成。
通过检查 result.returncode 来判断命令是否成功执行,返回码为0表示成功,其他值表示出错。
主程序入口:
在 if name == "main ": 块中,指定要运行的脚本路径,并调用 run_script 函数来执行该脚本。
这个程序文件名为 ui.py,主要功能是通过当前的 Python 环境运行一个指定的脚本,具体是一个名为 web.py 的文件。程序首先导入了必要的模块,包括 sys、os 和 subprocess,这些模块分别用于获取系统信息、处理文件路径和执行外部命令。
在文件中定义了一个名为 run_script 的函数,该函数接受一个参数 script_path,表示要运行的脚本的路径。函数内部首先获取当前 Python 解释器的路径,使用 sys.executable 可以得到当前 Python 环境的完整路径。接着,构建一个命令字符串,命令格式为 python -m streamlit run script_path,其中 streamlit 是一个用于构建和共享数据应用的库。
然后,使用 subprocess.run 方法执行这个命令。shell=True 参数表示在一个新的 shell 中执行命令。执行完命令后,程序检查返回码 result.returncode,如果返回码不为 0,说明脚本运行过程中出现了错误,此时会打印出一条错误信息。
在文件的最后部分,使用 if name == "main": 语句来确保当这个文件作为主程序运行时,才会执行下面的代码。这里指定了要运行的脚本路径为 web.py,并调用 run_script 函数来执行这个脚本。
整体来看,这个程序的主要作用是提供一个简单的接口,通过命令行来运行一个 Streamlit 应用,方便用户在当前 Python 环境中启动指定的应用脚本。
源码文件

源码获取
大家点赞、收藏、关注、评论 啦 、查看👇🏻获取联系方式👇🏻