DAY 51 复习日
**作业:**day43的时候我们安排大家对自己找的数据集用简单cnn训练,现在可以尝试下借助这几天的知识来实现精度的进一步提高
kaggl的一个图像数据集;数据集地址:Lung Nodule Malignancy 肺结核良恶性判断
三层卷积CNN做到的精度63%,现在需要实现提高。
昨天代码
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
# 定义通道注意力
class ChannelAttention(nn.Module):
def __init__(self, in_channels, ratio=16):
"""
通道注意力机制初始化
参数:
in_channels: 输入特征图的通道数
ratio: 降维比例,用于减少参数量,默认为16
"""
super().__init__()
# 全局平均池化,将每个通道的特征图压缩为1x1,保留通道间的平均值信息
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 全局最大池化,将每个通道的特征图压缩为1x1,保留通道间的最显著特征
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 共享全连接层,用于学习通道间的关系
# 先降维(除以ratio),再通过ReLU激活,最后升维回原始通道数
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // ratio, bias=False), # 降维层
nn.ReLU(), # 非线性激活函数
nn.Linear(in_channels // ratio, in_channels, bias=False) # 升维层
)
# Sigmoid函数将输出映射到0-1之间,作为各通道的权重
self.sigmoid = nn.Sigmoid()
def forward(self, x):
"""
前向传播函数
参数:
x: 输入特征图,形状为 [batch_size, channels, height, width]
返回:
调整后的特征图,通道权重已应用
"""
# 获取输入特征图的维度信息,这是一种元组的解包写法
b, c, h, w = x.shape
# 对平均池化结果进行处理:展平后通过全连接网络
avg_out = self.fc(self.avg_pool(x).view(b, c))
# 对最大池化结果进行处理:展平后通过全连接网络
max_out = self.fc(self.max_pool(x).view(b, c))
# 将平均池化和最大池化的结果相加并通过sigmoid函数得到通道权重
attention = self.sigmoid(avg_out + max_out).view(b, c, 1, 1)
# 将注意力权重与原始特征相乘,增强重要通道,抑制不重要通道
return x * attention #这个运算是pytorch的广播机制
## 空间注意力模块
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super().__init__()
self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 通道维度池化
avg_out = torch.mean(x, dim=1, keepdim=True) # 平均池化:(B,1,H,W)
max_out, _ = torch.max(x, dim=1, keepdim=True) # 最大池化:(B,1,H,W)
pool_out = torch.cat([avg_out, max_out], dim=1) # 拼接:(B,2,H,W)
attention = self.conv(pool_out) # 卷积提取空间特征
return x * self.sigmoid(attention) # 特征与空间权重相乘
## CBAM模块
class CBAM(nn.Module):
def __init__(self, in_channels, ratio=16, kernel_size=7):
super().__init__()
self.channel_attn = ChannelAttention(in_channels, ratio)
self.spatial_attn = SpatialAttention(kernel_size)
def forward(self, x):
x = self.channel_attn(x)
x = self.spatial_attn(x)
return x
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 数据预处理(与原代码一致)
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 加载数据集(与原代码一致)
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=train_transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, transform=test_transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
import torch
import torchvision.models as models
from torchinfo import summary #之前的内容说了,推荐用他来可视化模型结构,信息最全
# 加载 vgg16(预训练)
model = models.vgg16(pretrained=True)
model.eval()
# 输出模型结构和参数概要
summary(model, input_size=(1, 3, 224, 224))
import torch
import torch.nn as nn
from torchvision import models
# 自定义VGG16模型,插入CBAM模块
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import models
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class CBAM(nn.Module):
def __init__(self, in_planes, ratio=16, kernel_size=7):
super(CBAM, self).__init__()
self.ca = ChannelAttention(in_planes, ratio)
self.sa = SpatialAttention(kernel_size)
def forward(self, x):
x = x * self.ca(x)
x = x * self.sa(x)
return x
class VGG16_CBAM(nn.Module):
def __init__(self, num_classes=10, pretrained=True):
super().__init__()
# 加载预训练VGG
original_vgg = models.vgg16(pretrained=pretrained)
# 修改特征提取部分适应32x32输入
self.features = nn.Sequential(
# 替换第一个卷积层(原始kernel_size=7太大)
nn.Conv2d(3, 64, kernel_size=3, padding=1),
*list(original_vgg.features.children())[1:-1] # 保留后续层,去掉最后的MaxPool
)
# 插入CBAM模块
self.cbam_block4 = CBAM(512) # 对应block4输出
self.cbam_block5 = CBAM(512) # 对应block5输出
# 调整分类器
self.avgpool = nn.AdaptiveAvgPool2d((7, 7)) # 保证输出维度一致
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.cbam_block4(x) # 在block4后添加
x = self.cbam_block5(x) # 在block5后添加
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
# 初始化模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = VGG16_CBAM(num_classes=10).to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', patience=3, factor=0.5)
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import models
import matplotlib.pyplot as plt
import time
# ======================================================================
# 训练函数(适配VGG16-CBAM结构)
# ======================================================================
def set_trainable_layers_vgg(model, trainable_parts):
"""设置VGG16-CBAM模型的可训练层"""
print(f"\n---> 解冻以下部分并设为可训练: {trainable_parts}")
for name, param in model.named_parameters():
param.requires_grad = False
for part in trainable_parts:
if part in name:
param.requires_grad = True
break
def train_vgg_staged_finetuning(model, criterion, train_loader, test_loader, device, epochs=50):
optimizer = None
scheduler = None
# 初始化历史记录
all_iter_losses, iter_indices = [], []
train_acc_history, test_acc_history = [], []
train_loss_history, test_loss_history = [], []
for epoch in range(1, epochs + 1):
epoch_start_time = time.time()
# --- 阶段式解冻策略 ---
if epoch == 1:
print("\n" + "="*50 + "\n🚀 **阶段 1:训练CBAM模块和分类头**\n" + "="*50)
set_trainable_layers_vgg(model, ["cbam", "classifier"])
optimizer = optim.Adam([
{'params': [p for n,p in model.named_parameters() if 'cbam' in n], 'lr': 1e-4},
{'params': [p for n,p in model.named_parameters() if 'classifier' in n], 'lr': 1e-3}
])
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)
elif epoch == 11:
print("\n" + "="*50 + "\n✈️ **阶段 2:解冻高层卷积层 (features.16及以上)**\n" + "="*50)
set_trainable_layers_vgg(model, ["cbam", "classifier", "features.16", "features.23", "features.30"])
optimizer = optim.Adam([
{'params': [p for n,p in model.named_parameters() if 'features.0' in n or
'features.5' in n or 'features.10' in n], 'lr': 1e-5}, # 低层保持冻结
{'params': [p for n,p in model.named_parameters() if 'features.16' in n or
'features.23' in n or 'features.30' in n], 'lr': 1e-4}, # 高层
{'params': [p for n,p in model.named_parameters() if 'cbam' in n], 'lr': 1e-4},
{'params': [p for n,p in model.named_parameters() if 'classifier' in n], 'lr': 1e-4}
])
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', patience=3, factor=0.5)
elif epoch == 26:
print("\n" + "="*50 + "\n🛰️ **阶段 3:解冻所有层,全局微调**\n" + "="*50)
for param in model.parameters():
param.requires_grad = True
optimizer = optim.Adam([
{'params': model.features[:10].parameters(), 'lr': 1e-6}, # 最底层
{'params': model.features[10:20].parameters(), 'lr': 1e-5}, # 中间层
{'params': model.features[20:].parameters(), 'lr': 1e-4}, # 高层
{'params': [p for n,p in model.named_parameters() if 'cbam' in n], 'lr': 1e-4},
{'params': model.classifier.parameters(), 'lr': 1e-4}
])
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs-25)
# --- 训练循环 ---
model.train()
running_loss, correct, total = 0.0, 0, 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 记录迭代损失
iter_loss = loss.item()
all_iter_losses.append(iter_loss)
iter_indices.append((epoch - 1) * len(train_loader) + batch_idx + 1)
running_loss += iter_loss
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
if (batch_idx + 1) % 100 == 0:
print(f'Epoch: {epoch}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} '
f'| Loss: {iter_loss:.4f} | Avg Loss: {running_loss/(batch_idx+1):.4f}')
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = 100. * correct / total
train_loss_history.append(epoch_train_loss)
train_acc_history.append(epoch_train_acc)
# --- 测试循环 ---
model.eval()
test_loss, correct_test, total_test = 0, 0, 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = output.max(1)
total_test += target.size(0)
correct_test += predicted.eq(target).sum().item()
epoch_test_loss = test_loss / len(test_loader)
epoch_test_acc = 100. * correct_test / total_test
test_loss_history.append(epoch_test_loss)
test_acc_history.append(epoch_test_acc)
# 学习率调度
if epoch >= 11 and isinstance(scheduler, optim.lr_scheduler.ReduceLROnPlateau):
scheduler.step(epoch_test_acc)
elif scheduler is not None:
scheduler.step()
# 打印epoch结果
print(f'Epoch {epoch}/{epochs} | Time: {time.time()-epoch_start_time:.1f}s | '
f'Train Loss: {epoch_train_loss:.4f} | Test Loss: {epoch_test_loss:.4f} | '
f'Train Acc: {epoch_train_acc:.2f}% | Test Acc: {epoch_test_acc:.2f}%')
# 绘制结果
plot_iter_losses(all_iter_losses, iter_indices)
plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)
return epoch_test_acc
# ======================================================================
# 绘图函数(与之前相同)
# ======================================================================
def plot_iter_losses(losses, indices):
plt.figure(figsize=(10, 4))
plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')
plt.xlabel('Iteration(Batch序号)')
plt.ylabel('损失值')
plt.title('每个 Iteration 的训练损失')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):
epochs = range(1, len(train_acc) + 1)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs, train_acc, 'b-', label='训练准确率')
plt.plot(epochs, test_acc, 'r-', label='测试准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率 (%)')
plt.title('训练和测试准确率')
plt.legend(); plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(epochs, train_loss, 'b-', label='训练损失')
plt.plot(epochs, test_loss, 'r-', label='测试损失')
plt.xlabel('Epoch')
plt.ylabel('损失值')
plt.title('训练和测试损失')
plt.legend(); plt.grid(True)
plt.tight_layout()
plt.show()
# ======================================================================
# 执行训练
# ======================================================================
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化模型
model = VGG16_CBAM(num_classes=10).to(device) # 假设CIFAR-10分类
criterion = nn.CrossEntropyLoss()
# 数据加载器 (需根据实际数据集实现)
# train_loader, test_loader = get_dataloaders()
print("开始VGG16-CBAM的阶段式微调训练...")
final_acc = train_vgg_staged_finetuning(
model=model,
criterion=criterion,
train_loader=train_loader,
test_loader=test_loader,
device=device,
epochs=50
)
print(f"训练完成!最终测试准确率: {final_acc:.2f}%")
# torch.save(model.state_dict(), 'vgg16_cbam_finetuned.pth')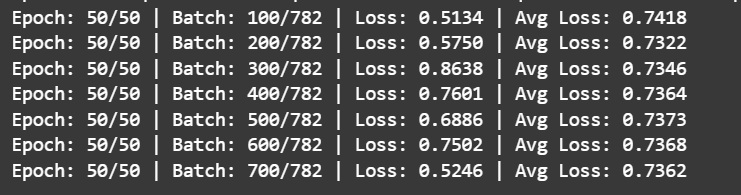

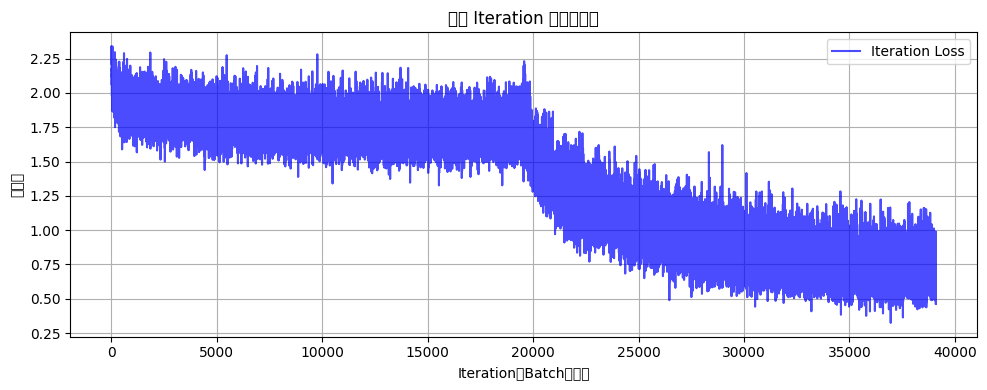
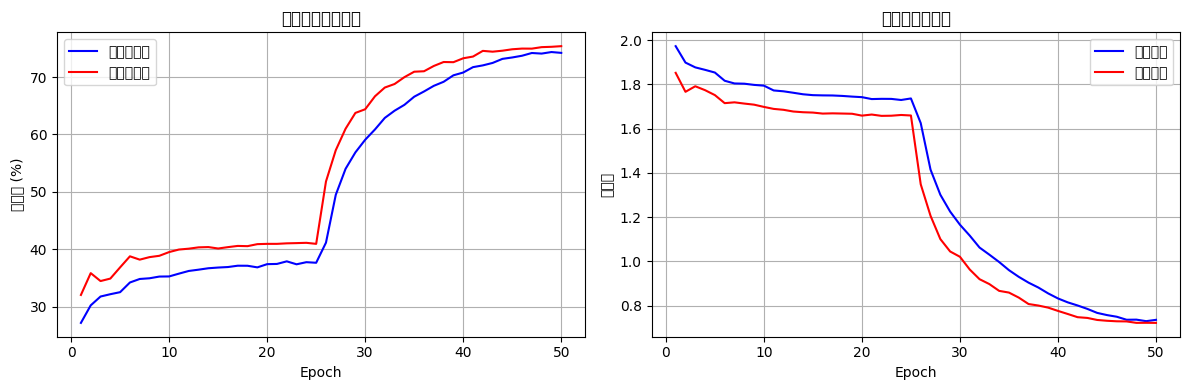
why? 难道残差网络比vgg16更适合训练cifar数据集吗?
今日作业:
python
import os
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import torch
from torchvision import transforms
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
# 1. 读标签并映射 0/1
df = pd.read_csv('archive/malignancy.csv')
# 2. 按 patch_id 划 train/val
ids = df['NoduleID'].values
labels = df['malignancy'].values
train_ids, val_ids = train_test_split(
ids, test_size=0.2, random_state=42, stratify=labels
)
train_df = df[df['NoduleID'].isin(train_ids)].reset_index(drop=True)
val_df = df[df['NoduleID'].isin(val_ids)].reset_index(drop=True)
# 3. Dataset:多页 TIFF 按页读取
class LungTBDataset(Dataset):
def __init__(self, tif_path, df, transform=None):
self.tif_path = tif_path
self.df = df
self.transform = transform
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
row = self.df.iloc[idx]
pid = int(row['NoduleID'])
label = int(row['malignancy'])
try:
with Image.open(self.tif_path) as img:
# 检查 pid 是否超出实际帧数
total_pages = sum(1 for _ in ImageSequence.Iterator(img))
if pid >= total_pages:
pid = total_pages - 1 # 取最后一帧
img.seek(pid)
img = img.convert('RGB')
except Exception as e:
# 返回黑色占位图
img = Image.new('RGB', (224, 224), (0, 0, 0))
if self.transform:
img = self.transform(img)
return img, label
# 4. 变换 & DataLoader
transform = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485,0.456,0.406],
std =[0.229,0.224,0.225])
])
train_ds = LungTBDataset('archive/ct_tiles.tif', train_df, transform)
val_ds = LungTBDataset('archive/ct_tiles.tif', val_df, transform)
train_loader = DataLoader(train_ds, batch_size=16, shuffle=True, num_workers=0, pin_memory=True)
val_loader = DataLoader(val_ds, batch_size=16, shuffle=False, num_workers=0, pin_memory=True)
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import models
from torch.optim.lr_scheduler import ReduceLROnPlateau
# ==================== 1. 定义VGG16-CBAM模型 ====================
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
nn.Conv2d(in_planes, in_planes//ratio, 1, bias=False),
nn.ReLU(),
nn.Conv2d(in_planes//ratio, in_planes, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super().__init__()
self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
class CBAM(nn.Module):
def __init__(self, in_planes, ratio=16, kernel_size=7):
super().__init__()
self.ca = ChannelAttention(in_planes, ratio)
self.sa = SpatialAttention(kernel_size)
def forward(self, x):
x = x * self.ca(x)
x = x * self.sa(x)
return x
# ==== 定义VGG16-CBAM模型 ====
class VGG16_CBAM(nn.Module):
def __init__(self, num_classes=2, pretrained=True):
super().__init__()
original_vgg = models.vgg16(pretrained=pretrained)
# 特征提取部分
self.features = original_vgg.features
# 在block4和block5后插入CBAM
self.cbam_block4 = CBAM(512) # 对应block4输出
self.cbam_block5 = CBAM(512) # 对应block5输出
# 分类器部分
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
def forward(self, x):
# 前向传播过程
x = self.features(x)
x = self.cbam_block4(x) # 在block4后应用CBAM
x = self.cbam_block5(x) # 在block5后应用CBAM
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
# ==================== 2. 训练策略配置 ====================
def set_trainable_layers(model, trainable_layers):
"""阶段式解冻层"""
for name, param in model.named_parameters():
param.requires_grad = any(layer in name for layer in trainable_layers)
def get_optimizer(model, lr_dict):
"""差异化学习率优化器"""
params = []
for name, param in model.named_parameters():
if param.requires_grad:
# 不同层组设置不同学习率
lr = lr_dict['features'] if 'features' in name else lr_dict['classifier']
params.append({'params': param, 'lr': lr})
return optim.Adam(params)
# ==================== 3. 训练流程 ====================
def train_model(model, train_loader, val_loader, num_epochs=10):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
# 阶段式训练配置
training_phases = [
{'name': 'Phase1-Classifier', 'train_layers': ['classifier'], 'epochs': 2, 'lr': {'features': 1e-5, 'classifier': 1e-4}},
{'name': 'Phase2-Conv5+CBAM', 'train_layers': ['features.24', 'features.25', 'features.26', 'features.27', 'features.28', 'classifier'], 'epochs': 3, 'lr': {'features': 5e-5, 'classifier': 1e-4}},
{'name': 'Phase3-Conv4+CBAM', 'train_layers': ['features.16', 'features.17', 'features.18', 'features.19', 'features.20', 'features.21', 'features.22', 'features.23', 'features.24', 'features.25', 'features.26', 'features.27', 'features.28', 'classifier'], 'epochs': 3, 'lr': {'features': 1e-4, 'classifier': 1e-4}},
{'name': 'Phase4-FullModel', 'train_layers': ['features', 'classifier'], 'epochs': 2, 'lr': {'features': 2e-4, 'classifier': 1e-4}}
]
criterion = nn.CrossEntropyLoss()
best_acc = 0.0
for phase in training_phases:
print(f"\n=== {phase['name']} ===")
set_trainable_layers(model, phase['train_layers'])
optimizer = get_optimizer(model, phase['lr'])
scheduler = ReduceLROnPlateau(optimizer, mode='max', patience=1, factor=0.5)
for epoch in range(phase['epochs']):
# 训练阶段
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / len(train_loader.dataset)
# 验证阶段
model.eval()
correct = 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
correct += (preds == labels).sum().item()
epoch_acc = correct / len(val_loader.dataset)
print(f'Epoch {epoch+1}/{phase["epochs"]} - Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
scheduler.step(epoch_acc)
# 保存最佳模型
if epoch_acc > best_acc:
best_acc = epoch_acc
# torch.save(model.state_dict(), 'best_vgg16_cbam.pth')
print(f'Best Validation Accuracy: {best_acc:.4f}')
# ==================== 4. 初始化并训练模型 ====================
model = VGG16_CBAM(num_classes=2, pretrained=True)
train_model(model, train_loader, val_loader, num_epochs=10)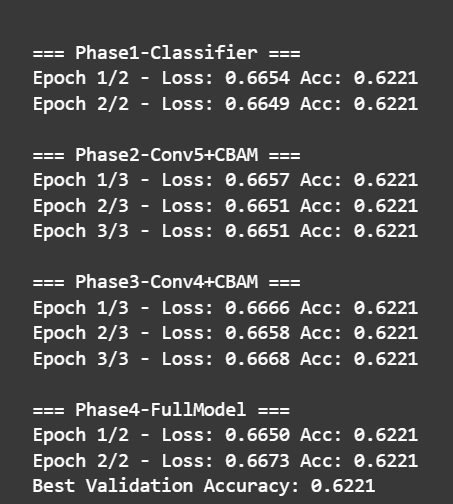 感觉可能是数据集的问题
感觉可能是数据集的问题