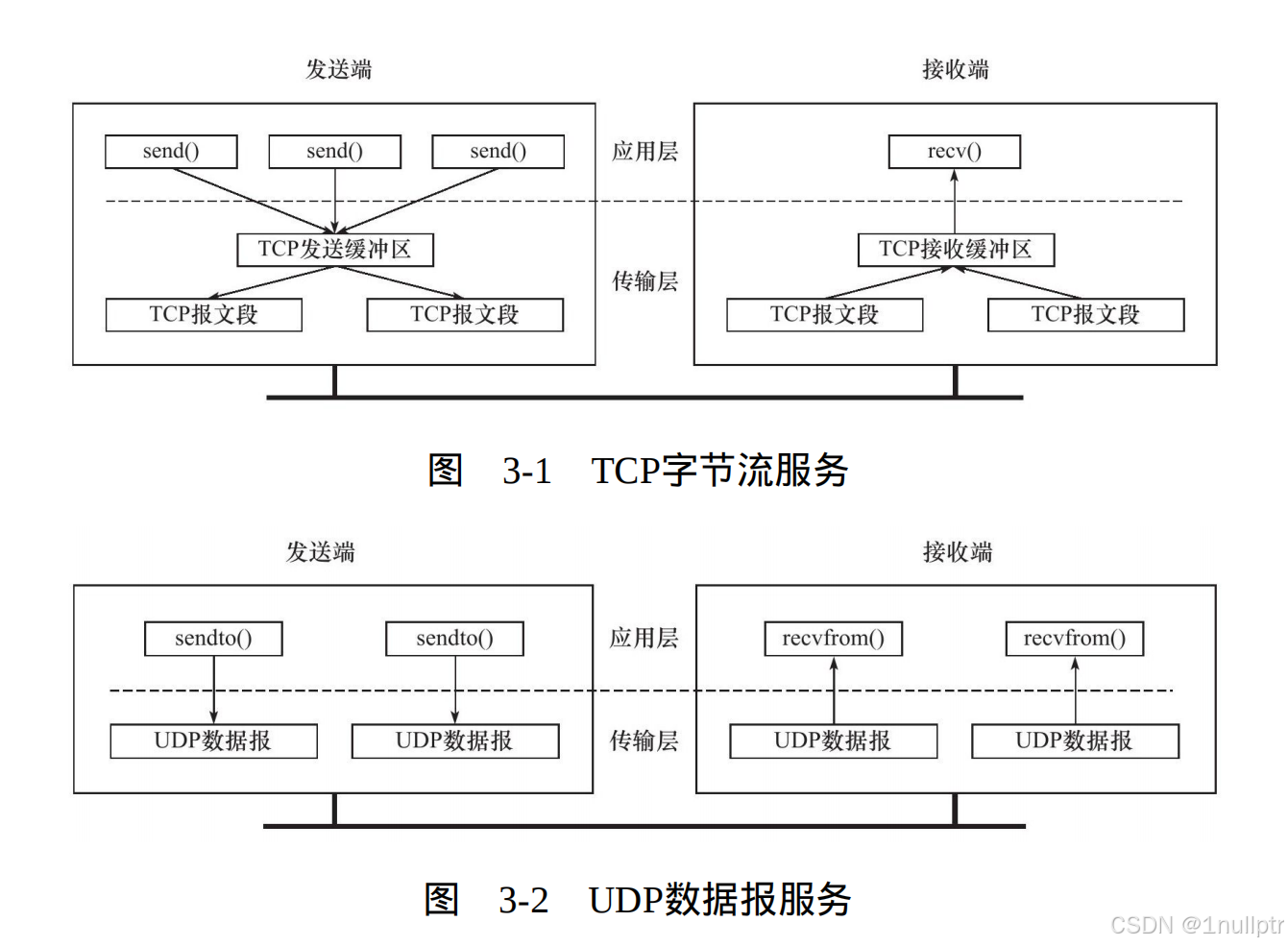
问题1
请详细解释以下场景中TCP数据是如何在发送端和接收端处理的:
python
# 假设应用程序执行了以下写操作
write("Hello")
write("World")
write("!")
# 假设应用程序执行了以下读操作
read(buffer, 5) # 读取5个字节
read(buffer, 6) # 读取6个字节- 发送端的三个write操作是否一定会产生三个TCP报文段?为什么?
- 接收端收到数据后,两个read操作是否一定能分别读取到"Hello"和"World"?为什么?
- 如果接收端的read操作改为一次性读取11个字节,会得到什么结果?
- 这种机制对应用程序开发有什么影响?
- 在实际开发中,如何处理TCP的粘包问题?
答案
1.发送端:
- 不一定产生三个TCP报文段
- 原因:
- TCP模块会先将数据放入发送缓冲区
- 根据TCP的Nagle算法和发送窗口大小
- 可能会将多个小数据合并成一个TCP报文段发送
- 也可能会将一个大数据分割成多个TCP报文段发送
2.接收端:
- 不一定能分别读取到"Hello"和"World"
- 原因:
- TCP模块将数据按序号放入接收缓冲区
- 应用程序的read操作只是从接收缓冲区读取数据
- 如果第一个read操作时,接收缓冲区中只有"Hel",那么只能读取到"Hel"
- 第二个read操作会继续读取剩余数据
3.一次性读取11个字节:
- 会得到"HelloWorld!"
- 原因:
- 接收缓冲区中的数据是完整的
- 应用程序可以一次性读取所有数据
- 读取的数据大小取决于应用程序指定的缓冲区大小
数据完整性挑战:
- 需要处理数据分片
- 需要处理数据粘包
- 需要确保数据按正确顺序重组
性能考虑:
- 缓冲区大小的设置会影响性能
- 频繁的小数据写入可能导致性能下降
- 需要权衡实时性和吞吐量
错误处理:
- 需要处理网络异常
- 需要处理数据丢失
- 需要实现重传机制
消息边界处理:
python
# 使用特殊分隔符
def send_with_delimiter(socket, data):
# 添加分隔符
message = data + b'\r\n'
socket.send(message)
def receive_with_delimiter(socket):
buffer = b''
while True:
data = socket.recv(1024)
if not data:
break
buffer += data
if b'\r\n' in buffer:
message, buffer = buffer.split(b'\r\n', 1)
yield message消息队列处理:
python
class MessageQueue:
def __init__(self):
self.buffer = b''
self.message_length = 0
def append(self, data):
self.buffer += data
self._process_messages()
def _process_messages(self):
while len(self.buffer) >= 4: # 消息头长度
if self.message_length == 0:
self.message_length = struct.unpack('!I', self.buffer[:4])[0]
if len(self.buffer) >= self.message_length + 4:
message = self.buffer[4:4+self.message_length]
self.buffer = self.buffer[4+self.message_length:]
self.message_length = 0
yield message
else:
break