好了,上次我们了解完了AVL平衡树和红黑树之后,我们就可以去了解关于map与set的底层实现原理了。
全局观STL的操作:
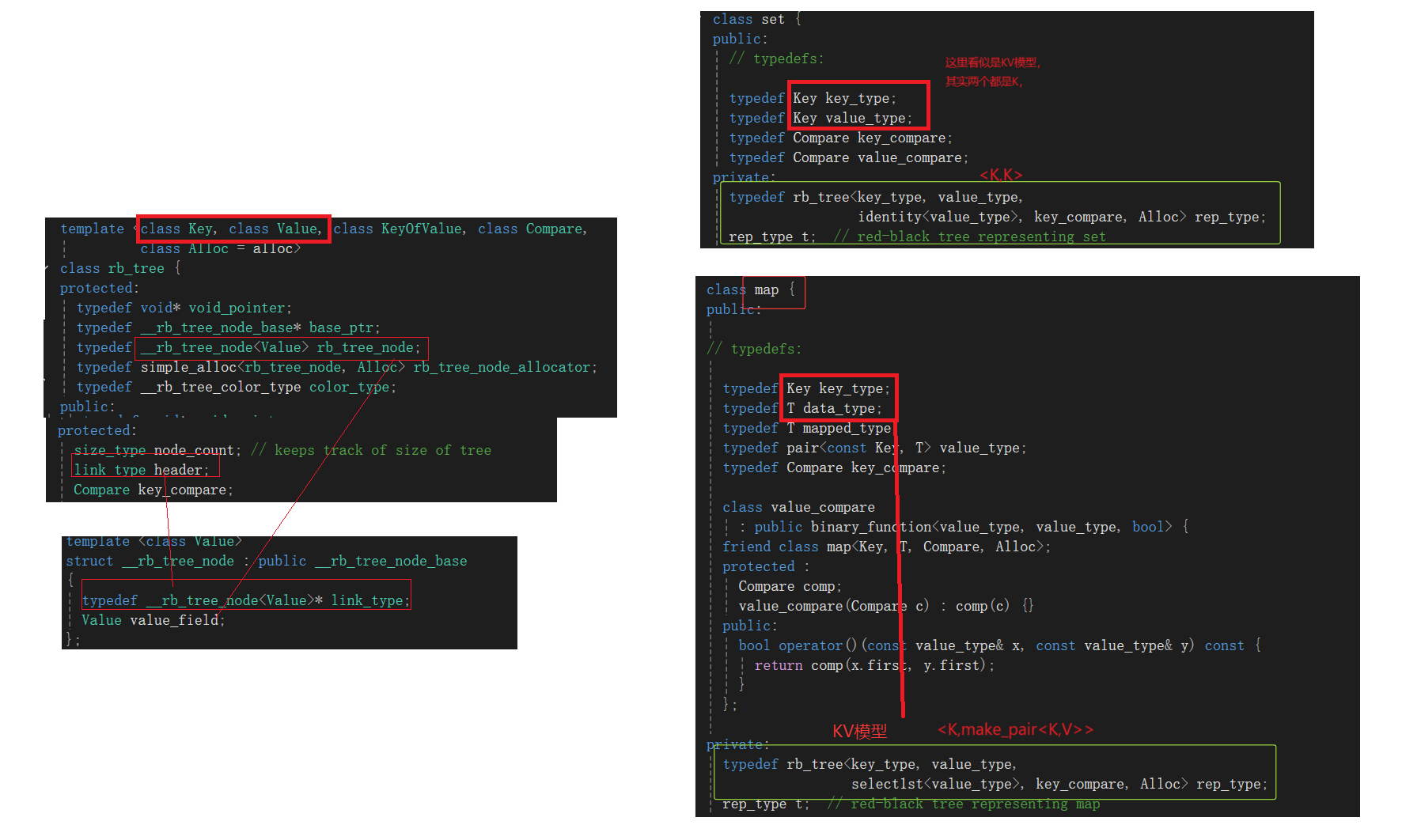
我们先来看看STL中是如何利用红黑树进行对map与set的实现的?
从上面我们可以看到:
为了实现一颗红黑树,即可map又可set,即即可key结构,也可K,V结构,这取决于 第二个模板参数你传什么?能不能只传Value,不传Key(传第二个模板参数,不传第一个模板参数?)
不能,因为当find接口时,对于set没问题,set的value就是Key,但对于map不能。
所以为了统一适配,要传两个模板参数。但实际上,set是一个模板参数,map是两个模板参数。
(ps:Key与pair中的Key是同一类型)
set的模拟实现(set是一个模板参数)
typedef Key key_type;
typedef Key value_type;
那么有人又会想:它会不会存在树被修改的问题?
答案:不存在的,因为你并不会动这棵树,你只是动map与set而已,接触不了树的那层。
看上面的图:K是为了让find接口更加好搞,T是为了决定树的结点里面存什么。
好了,上面了解库的大概实现的方式后,现在我们来实现一下:
自己模拟:
ps:这里我们会采用set与map两者之间的对比差异结合来实现(即同一部分的放在一起,并不会像之前那样set与map分开来实现。)
红黑树创建结点和颜色管理
红黑树部分跟上一篇的差不多,只不过这里改了_kv类型改了一下:
我们上一篇的是以pair<K,V> _kv,而现在改成了T _data
这里可以认为在红黑树这一层它走了一个泛型,以前实现红黑树都是确定的是pair<K,V>类型,而现在是不确定的,而是通过一个模板来接受它的类型。
这里的本意就是想要通过模板来使红黑树实例化出来两份:一份是<K,K>,一份是<K,pair<K,V>>

enum Color
{
BLACK,
RED
};
template<class T>
struct RBTreeNode
{
RBTreeNode<T>* _left;
RBTreeNode<T>* _right;
RBTreeNode<T>* _parent;
T _data;
Color _col;
RBTreeNode(const T& data)
:_left(nullptr)
,_right(nullptr)
,_parent(nullptr)
,_data(data)
,_col(RED)
{ }
};构建其成员变量:
ps:有些模板参数后面会讲,可暂时先不用管。
红黑树部分:
template<class K,class T,class KeyOFT>
class RBTree
{
typedef RBTreeNode<T> Node;
public:
private:
Node* _root = nullptr;
};set部分
namespace bai
{
template<class K>
class My_set
{
private:
RBTree<K, K, SetKeyOFT> _t;
};
}map部分
namespace bai
{
template<class K, class V>
class My_map
{
private:
RBTree<K, pair<const K, V>, MapKeyOFT> _t;
};
}插入部分
1.这里如果按照上一篇的方式之间比较的话,它就会行不通,为什么呢?
因为insert部分的比较:通过上面我们知道对于set,可以直接比较,它的结构本质上<K,K>第二个模板是K,而map的话,它的结构是<K,pair<K,V>>,第二个模板参数是pair类型,它并不可以像我们之前那样直接比较。可能有人会问:那为什么不可以直接用K模板比较?注意:我们这里比较的是值,这个K是个类型,而这比较需要拿的是对象,对象不确定,是K还是pair?所以不可以。
那么,我们该怎么去解决这个问题呢?这里就使用到了仿函数了。
之前我们说过,仿函数是可以做到像函数一样的。
这里我们可以直接在各自那里:实现一个仿函数。通过模板还传进去树的结构那里。
使用仿函数比较
set部分
struct SetKeyOFT
{
const K& operator()(const K& key)
{
return key;
}
};
bool insert(const K& key)
{
return _t.Insert(key);
}map部分
struct MapKeyOFT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
//后面我们再实现
V& operator[](const K& key);
bool insert(const pair<K, V>& kv)
{
return _t.Insert(kv);
}完了之后,就可以直接利用仿函数的使用方法,通过仿函数比较insert部分里面的比较内容了。
由于代码太多了,这里只展现出部分的:(展示如何利用上仿函数就行)其余的代码跟上一篇的红黑树插入部分已经有了。
bool Insert(const T& data)
{
..............................
..............................
KeyOfT kot;
while (cur)
{
if (kot(cur->_data) < kot(data))
{
........................
}
else if (kot(cur->_data) > kot(data))
{
........................
}
..................
..................
}说明:为什么在红黑树中不通过KeyOfT实现比较?
这样设计是为了保持KeyOfT的纯粹性。如果让KeyOfT负责比较,就会失去其核心价值。我们要思考的是:KeyOfT存在的真正意义是什么?是为了让树结构本身更清晰。
我们的做法是:使用者只需关注比较逻辑,无需理会KeyOfT的具体实现。因此将两者分离,只需传入比较接口即可实现功能。
迭代器部分:
红黑树部分:
迭代器的构造(加上构造+拷贝构造)
template<class T,class Ptr,class Ref>
struct TreeIterator
{
typedef RBTreeNode<T> Node;
typedef TreeIterator<T,Ptr,Ref> Self;
typedef TreeIterator<T, T*, T&> Iterator;
Node* _node;
TreeIterator(Node*node)
:_node(node)
{ }
TreeIterator(const Iterator&it)
:_node(it._node)
{ }
};operator*
Ref operator*()
{
return _node->_data;
}operator->
Ptr operator->()
{
return &_node->_data;
}operator!=
bool operator!=(const Self&s)
{
return _node != s._node;
}operator==
bool operator==(const Self& s) const
{
return _node == s._node;
}operator++
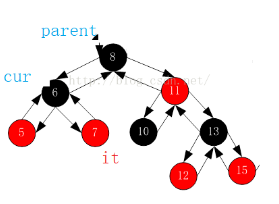
讲解:
1.首先,我们来看一下上面的图来使我们更加清楚了解它是如何进行++的?
2.我们先来看一下它的总思路:(结合着上图一起看)
1)右不为空,访问右树的最左结点(即最小结点)。
2)右为空,下一个要访问的孩子是父亲左的那个祖先。
Self& operator++()
{
//右树不为空,找右树的最左结点(即最小结点)
if (_node->_right)
{
Node* subleft = _node->_right;
while (subleft->_left)
{
subleft = subleft->_left;
}
_node = subleft;
}
//右树为空,
else
{
Node* cur = _node;
Node* parent = cur->_parent;
//找孩子是父亲左的那个祖先节点,就是下一个要访问的节点
while (parent && cur==parent->_right)
{
cur = cur->_parent;
parent = parent->_parent;
}
_node = parent;
}
return *this;
}operator--
1.减减的思路和加加的思路相反:
1)左不为空,访问左树的最右结点(即最大结点)。
2)左为空,下一个要访问的孩子是父亲右的那个祖先。
Self& operator--()
{
if (_node->_left)
{
Node* subright = _node->_right;
while (subright->_right)
{
subright = subright->_right;
}
_node = subright;
}
else
{
Node* cur = _node;
Node* parent = cur->_parent;
while (parent && cur==parent->_left)
{
cur = cur->_parent;
parent = parent->_parent;
}
_node = parent;
}
return *this;
}好了,迭代器接口的类已经写完了,现在我们利用上写的迭代器函数,进行对begin(),end()等实现上去。
begin()和end()函数
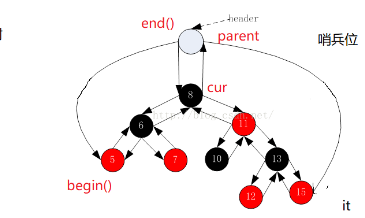
首先,我们先来看一下库里面是如何进行实现的;
库那利用了一个哨兵节点。
除了它的开销:在旋转操作中,为了维护父节点而付出了一定的代价。而且,当在最左边或最右边插入或删除节点时,也需要进行相应的维护和修改
在这里,我们就不像它那样实现了,复杂,难!
1.我们先对迭代器进行封装,还是用上我们的模板:2.begin()函数的解释:因为底层实现是红黑树,即平衡二叉搜索树,所以,我们开始的结点(中序遍历)是左子树最左的那个值,所以,要进行查找遍历到左数最小的值,最后返回。
3.end()函数的解释:直接返回迭代器为nullptr时。为什么呢?返回nullptr构造的迭代器,当遍历完红黑树时,迭代器到达这个位置就说明遍历完了有效的元素,和STL容器的迭代器使用习惯一致,方便搭配基于范围for循环等遍历方式:for(auto it=rbtree.begin();it!=end();it++).
4.下面还有就是实现了const迭代器。
template<class K,class T,class KeyOFT>
class RBTree
{
typedef RBTreeNode<T> Node;
public:
typedef TreeIterator<T,T*,T&> iterator;
iterator begin()
{
Node* LeftMin = _root;
while (LeftMin && LeftMin->_left)
{
LeftMin = LeftMin->_left;
}
return iterator(LeftMin);
}
iterator end()
{
return iterator(nullptr);
}
const_iterator begin()const
{
Node* LeftMin = _root;
while (LeftMin && LeftMin->_left)
{
LeftMin = LeftMin->_left;
}
return const_iterator(LeftMin);
}
const_iterator end()const
{
return const_iterator(nullptr);
}
private:
Node* _root = nullptr;
};好了,红黑树里的迭代器封装我们就基本实现完成了,那么现在,就开始对set与map进行对迭代器模板的使用。
set迭代器
同样,我们来进行实现两个迭代器,分别是普通迭代器和const迭代器。
但是,由上面一开始的分析我们也知道,set中是不可被修改的,否则就不是搜索树了。
所以普通迭代器底层对红黑树的迭代器封装时,也是使用了const迭代器进行封装的,从而做到不可修改。
1.注意:为什么iterator begin()后面不加const不会通过编译,会报错?
因为:不加const的话,那么_t就是普通迭代器的_t,普通迭代器的t就只能调用普通的begin,普通的begin(),end(),返回的就是普通的iterator,普通的iterator能不能跟这个匹配?不能。
那么,我们只提供const版本的迭代器,有没有价值呢?
答案是有点:反正它是不能被修改的,const对象可以调用const(平移),普通对象也是可以调用const的(缩小)。因为我们说过,对象可以平移或者缩小,但是不可以扩大。
比如:我们使用时:bai::set<int>::iterator it=_t.begin();
iterator可以转化为const_itrerator,那要单独写一个构造进行转化,但是typedef里的iterator还是要写的,因为像我们平常的话,更多习惯用的还是iterator而不是const_iterator,对吧。
2.注意补充一点:类模板没有实例化,编译器不会去找。
内嵌类型:内部类,typedef
要加typename,相当于给编译器吃一颗定心丸,告知编译器它是合法的。(具体的可以去看一下关于进阶模板的文章)
//有些代码已经省略
namespace bai
{
template<class K>
class My_set
{
public:
typedef typename RBTree<K,K,SetKeyOFT>::const_iterator iterator;
typedef typename RBTree<K, K, SetKeyOFT>::const_iterator const_iterator;
iterator begin()const
{
return _t.begin();
}
iterator end()const
{
return _t.end();
}
private:
RBTree<K, K, SetKeyOFT> _t;
};
}map迭代器
1.我们的map可以修改:即不可以修改K,可以修改Value,那么我们能不能继续像刚才set那样,,底层都是const_iterator?来保证K不变。
答:不可以,因为set只有一个,让K不可被修改,若map也用的话,它不仅仅K不可改,连V也不可修改了。
那么,我们该怎么去做到不改变K,但是改变V呢?
我们可以在pair内部进行操作,即在pair<const K,V>,这样的话pair可以被修改,但是K不可以修改了,达成我们的目的!
其他的做法,跟我们set的差不多!
namespace bai
{
template<class K, class V>
class My_map
{
public:
typedef typename RBTree<K, pair<const K,V>, MapKeyOFT>::iterator iterator;
typedef typename RBTree<K, pair<const K, V>, MapKeyOFT>::const_iterator const_iterator;
iterator begin()
{
return _t.begin();
}
iterator end()
{
return _t.end();
}
const_iterator begin()const
{
return _t.begin();
}
const_iterator end()const
{
return _t.end();
}
private:
RBTree<K, pair<const K, V>, MapKeyOFT> _t;
};
}随之我们的迭代器部分的完善,我们的insert部分也要进一步改善的!
完善insert部分
insert部分返回值要改成pair<iterator,bool>
红黑树部分
讲解
1.为什么要用newnode保存一下cur呢?不能直接用cur?
答:因为红黑树插入的过程中会有变色,cur的grandfather,cur可能往上走,不一定是新插入的结点,所以要保存一下新节点
pair<iterator, bool> insert(const T& data)
{
KeyOFT kot;
if (_root == nullptr)
{
_root = new Node(data);
_root->_col = BLACK;
return make_pair(iterator(_root),true);
}
Node* cur = _root;
Node* parent = nullptr;
//Node* newnode = cur;
while (cur)
{
if (kot(cur->_data) < kot(data))
{
parent = cur;
cur = cur->_right;
}
else if (kot(cur->_data) > kot(data))
{
parent = cur;
cur = cur->_left;
}
else
{
return make_pair(iterator(cur), false);
}
}
cur = new Node(data);
//写错1
Node* newnode = cur;
cur->_col = RED;
if (kot(parent->_data) < kot(data))
{
parent->_right=cur;
}
else
{
parent->_left=cur;
}
cur->_parent = parent;
while (parent && parent->_col == RED)
{
Node* grandfather = parent->_parent;
if (parent == grandfather->_left)
{
Node* uncle = grandfather->_right;
if (uncle && uncle->_col == RED)
{
parent->_col = BLACK;
uncle->_col = BLACK;
grandfather->_col = RED;
//继续向上更新
cur = grandfather;
parent = cur->_parent;
}
else//不存在 或者uncle为黑 旋转+变色
{
if (cur == parent->_left)
{
// g
// p
//c
RotateR(grandfather);
parent->_col = BLACK;
grandfather->_col = RED;
}
else //cur==parnet->right
{
// g
// p
// c
RotateL(parent);
RotateR(grandfather);
cur->_col = BLACK;
//parent->_col = BLACK;
grandfather->_col = RED;
}
break;
}
}
else //(parent == grandfather->_right)
{
Node* uncle = grandfather->_left;
//Node* uncle = grandfather->_right;
if (uncle && uncle->_col == RED)
{
parent->_col = uncle->_col = BLACK;
grandfather->_col = RED;
//继续向上更新
cur = grandfather;
parent = cur->_parent;
}
else //(uncle不存在时)旋转+变色
{
// g
// p
// c
if (cur == parent->_right)
{
RotateL(grandfather);
parent->_col = BLACK;
grandfather->_col = RED;
}
// g
// p
// c
else
{
RotateR(parent);
RotateL(grandfather);
cur->_col = BLACK;
//parent->_col = BLACK;
grandfather->_col = RED;
}
break;
}
}
}
_root->_col = BLACK;
return make_pair(iterator(newnode),true);
}你把树里的改了,那么set与map的也要跟着改。但是这时候就会set的insert出现问题:
现在我们来看一下改变的代码:
set部分
pair<iterator, bool> insert(const K& key)
{
return _t.insert(key);
}set没有pair,而pair又是全局的。
会出现迭代器问题:
返回值的pair<iterator,bool>是RBTree::const_iterator
而你return的 _t.Insert(key)是pair<RBTree::iterator,bool>
那么,我们在insert() const 行不行?
不能,_t是const,Insert也是const,那么必须去调用const insert,那就不能够修改树的结构了,所以不能!
再来回顾,make_pair会根据它的类型自己去推,在类里面直接用iterator,本质也是const_iterator.
这里的做法是:
拿一个普通迭代器去构造const迭代器!
按理说,迭代器不需要写拷贝构造,因为编译器默认写:浅拷贝。
template<class T,class Ptr,class Ref>
struct TreeIterator
{
typedef RBTreeNode<T> Node;
typedef TreeIterator<T,Ptr,Ref> Self;
typedef TreeIterator<T, T*, T&> Iterator;
Node* _node;
TreeIterator(Node*node)
:_node(node)
{ }
TreeIterator(const Iterator&it)
:_node(it._node)
{ }
}但这个函数也不完全是拷贝构造,因为它的返回值不是Self 。
Self与Iterator的区别:Self就是这个迭代器,但Iterator就不一定了。
可能听到这里有点疑惑,别急,让我们再来捋捋思路:
_t.insert是一个普通树的对象,
pair<typename RBTree<K,K,SetkeyofT>::iterator,bool> ret=t.insert()返回的是一个普通的迭代器,而set这层的iterator是const迭代器,传不过去,所以我们的做法是:
单独用一个pair对象普通树的迭代器的对象去接受,接受了以后,再用这个东西去构造,传参,first传的是普通迭代器,
那么,普通迭代器为什么可以初始化const迭代器?
因为const迭代器中支持了一个构造,这两个pair是同一个类模板,并不是同类型的。
当这个类被实例化成const迭代器时,这个函数是一个构造,支持普通迭代器构造const迭代器,为什么?
1.因为我实例化出const迭代器,我自己就是const迭代器,但是这个参数是iterator,特点是不管你是普通迭代器还是const迭代器,都是普通迭代器,因为这参数传的是
typedef TreeIterator<T, T*, T&> Iterator;并不受Ref,Ptr影响。
2.当这个类被实例化成普通迭代器,这个函数就是一个拷贝构造(普通构造普通)。
map部分
pair<iterator,bool> insert(const pair<K, V>& kv) { return _t.insert(kv); }也是跟上面的一样理解。
map的operator\[\]部分
V& operator[](const K& key)
{
pair<iterator, bool> ret = insert(make_pair(key, V()));
return ret.first->second;
}1.这是一个关联式容器:
make_pair(key, V()) :创建一个 pair 对象, first 是传入的 key , second 是默认构造的 V 类型对象(如果 V 是自定义类型,需有默认构造函数 )。
insert(make_pair(key, V())) :调用下方自定义的 insert 函数,尝试插入pair 。
insert 函数返回一个 pair ,其中 first 是指向插入位置(或已存在元素位置 )的迭代器, second 是 bool 类型, true 表示插入成功(之前无该 key ), false 表示已存在(未插入新元素 )。
- return ret.first->second :不管插入是否成功,通过迭代器 ret.first 访问 pair 的 second (即对应 key 的 value )并返回其引用,
大整体部分就这样了。
好的,本次分享就到处结束了,希望我们一起进步!
最后,到了本次鸡汤环节:
下面图片与大家共勉!
