解决问题:生成一个符合训练样本的图像
- 当然也可以是普通数据,不一定非要是图像
- 根据输入值不同,选择不同特性的模型
| 模型 | 输入值 | 生成能力 | 隐空间特性 |
|---|---|---|---|
| AE | 图像 | 必须使用已知图像去重绘,类似于默写的操作 | 不平滑,不连续 |
| VAE | 随机 z z z | 从随机到图像,无中生有(当然输入图像也是可以的) | 平滑、连续 |
| CAVE | 随机 z z z+条件 | 可生成指定条件的图像 | 条件化、可控生成 |
模型共性
- 模型都是基于编码器-解码器的模型来设计的
- 编码器 用来提取输入图像的特征,生成低维抽象的特征表示,即隐表示/隐变量 : z z z
- 解码器 用来将低维抽象还原回图像
AE 自编码器
-
编码器直接通过例如全连接层的操作,提取特征 z z z,此时的 z z z我们观察任意一个特征,他的数据分布是不平滑,不连续的(全连接层)的输出一定是不连续的.
-
AE的 z z z分布,可见分布是不稳定的,直接使用随机值输入,很大的概率不能落在隐空间有效值上,
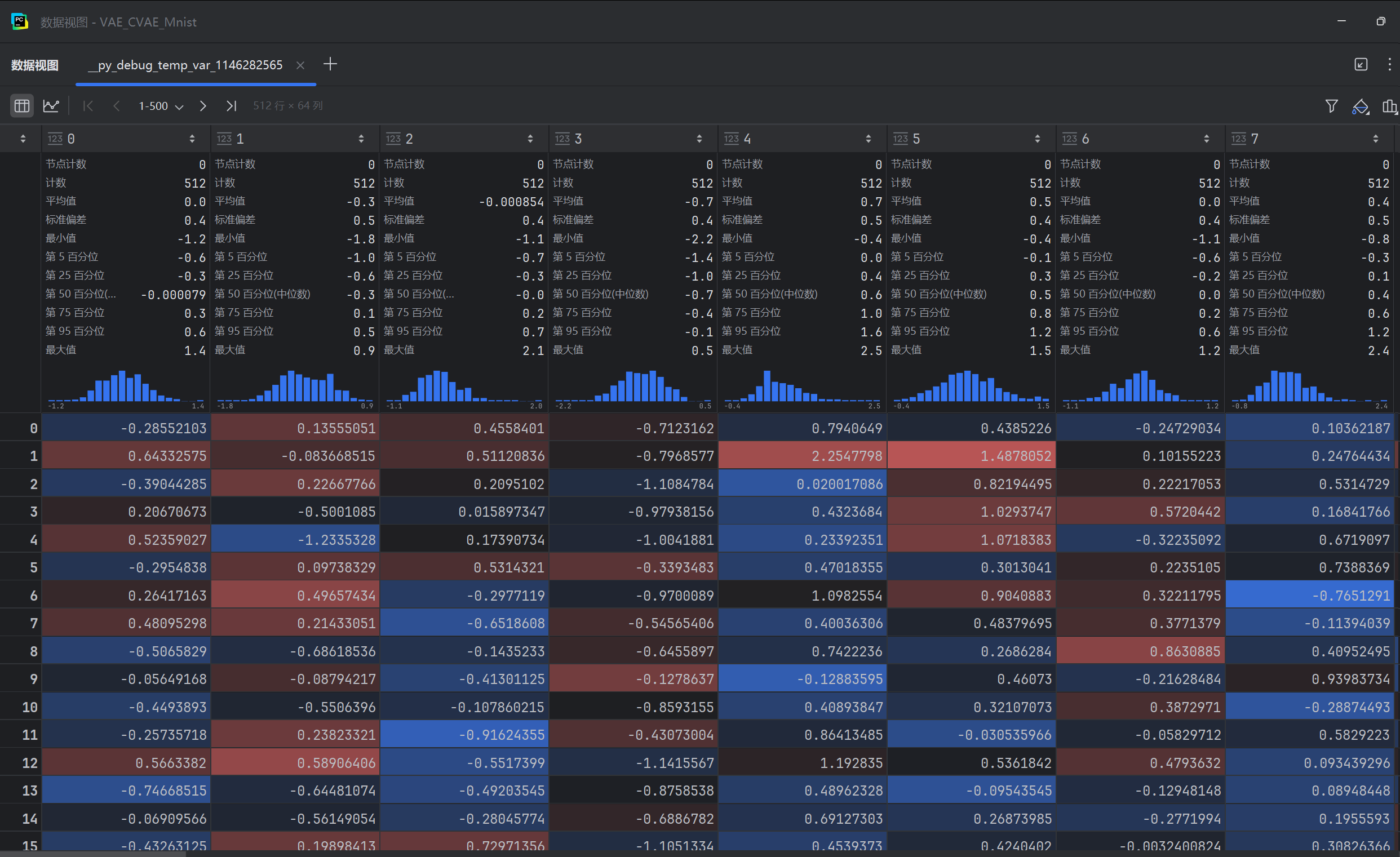
-
CAE的 z z z分布,可见均值接近0,标准差接近1
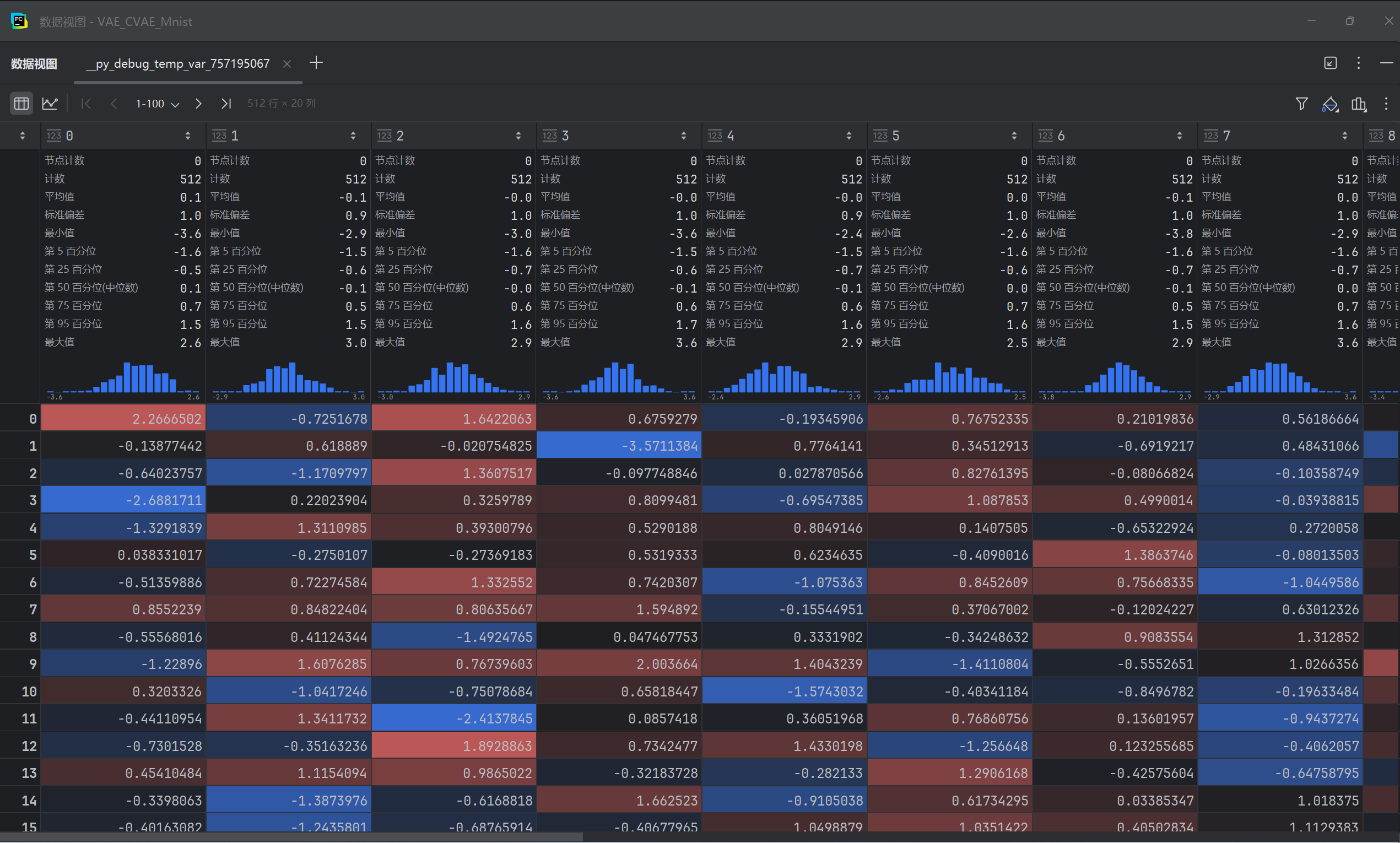
-
已经学会了如何绘制,但是需要给一个示例看一看,然后默写
以下是30epcho训练的结果
- 原图
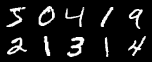
- 使用原图生成的图像(放大看可见字体边缘有些奇怪的点点)

- 使用随机数生成的图像

VAE 变分自编码器
将输入的数据(batch_size,data)执行一次全连接层操作,将其映射到隐空间;
- 和AE比,核心的改变是调整了 z z z的生成方式,使编码器编码的结果,在每一个隐空间的特征上都符合标准正态分布即: z ∼ N ( 0 , I ) z \sim \mathcal N(0,I) z∼N(0,I),这样使用同样服从此分布的随机数生成器:torch.randn(),生成的数据可以落在 z z z上;
- VAE的设计重点就变成了,如何使编码器输出的数据在特征列上服从标准正态分布;
python
self.fc1 = nn.Linear(input_size, 512)
self.fc2 = nn.Linear(512, latent_size)
self.fc3 = nn.Linear(512, latent_size)
...
def encode(self, x):
x = F.relu(self.fc1(x))
mu = self.fc2(x) # 潜在空间均值
log_var = self.fc3(x) # 潜在空间对数方差
return mu, log_var- 隐空间实际是一个概率空间,latent_size表达为空间的特征数量,例如"微笑","发色"等特征;
- 注意,每个特征由2个值:mu ,log_var 来表达,实际是一个正态分布空间的表达(表达一个正态分布有均值和标准差即可);
- mu ,log_var形状均为:batch_size,latent_size,如果输入是一张照片,那么每对数据就是,这张照片在那个特征上的分布概率;
- 例如mu 0,0,log_var0,0, 如果0代表微笑(注意特征是自动学习的,并非预先定义,只是举个例子), 那么就是这张照片是微笑的概率分布,只要再取样,即可得到微笑的概率值,即latent变量 Z Z Z.
- 那为什么不直接与预测概率值 Z Z Z.,而是需要先计算一个概率空间,再取样呢?AE自编码器是这么干的; 每次生成都基于相同的 Z Z Z.,无法探索潜在空间的其他可能性。
输入蒙娜丽莎的照片,将微笑特征设定为特定的单值(相当于断定蒙娜丽莎笑了或者没笑)显然不如将微笑特征设定为某个取值范围(例如将微笑特征设定为x到y范围内的某个数,这个范围内既有数值可以表示蒙娜丽莎笑了又有数值可以表示蒙娜丽莎没笑)更合适;[1](#1)
-
为什么不直接预测标准差,而是预测对数方差呢?
- 对数方差 logσ2logσ2 的范围是 (−∞,+∞)(−∞,+∞),而指数函数 expexp 能够更稳定地映射到正数范围。例如,当 logσ2logσ2 接近负无穷时,σ2σ2 接近0,但不会导致数值下溢。
- 此外,对数变换可以避免在优化过程中因方差过大或过小而引发的梯度爆炸或消失问题。
-
重参数化: 要反向传播,需要函数可导,采样操作不可导,故执行重参数化;将采样操作从概率分布中 分离出随机性,使得采样过程变为确定性函数。例如,对于正态分布 z∼N(μ,σ2)z∼N(μ,σ2),可以通过以下方式实现:
z ∼ N ( μ , σ ) z = μ + σ ⋅ ϵ 其中 ϵ ∼ ( 0 , I ) \begin{gather*} z \sim \mathcal N(\mu, \sigma)\\ z=\mu + \sigma\cdot\epsilon 其中 \epsilon \sim(0,I) \end{gather*} z∼N(μ,σ)z=μ+σ⋅ϵ其中ϵ∼(0,I) -
损失函数,由重构损失和KL散度计算;
- 重构损失,衡量输入数据和输出数据的相似度
- KL散度,约束隐空间的均值和方差符合标准正态分布,即使 μ → 0 , σ → 1 \mu \rightarrow 0,\sigma \rightarrow 1 μ→0,σ→1