一、循环神经网络基础概念
1.1 循环神经网络的定义与核心特性
循环神经网络(Recurrent Neural Network, RNN)是一类专门处理序列数据的神经网络,其显著特征是神经元连接中存在循环结构,允许信息在时间维度上传递。与前馈神经网络不同,RNN能够利用历史时刻的信息来影响当前输出,具备"记忆"能力,这使其在处理具有时序依赖的数据时表现出独特优势。
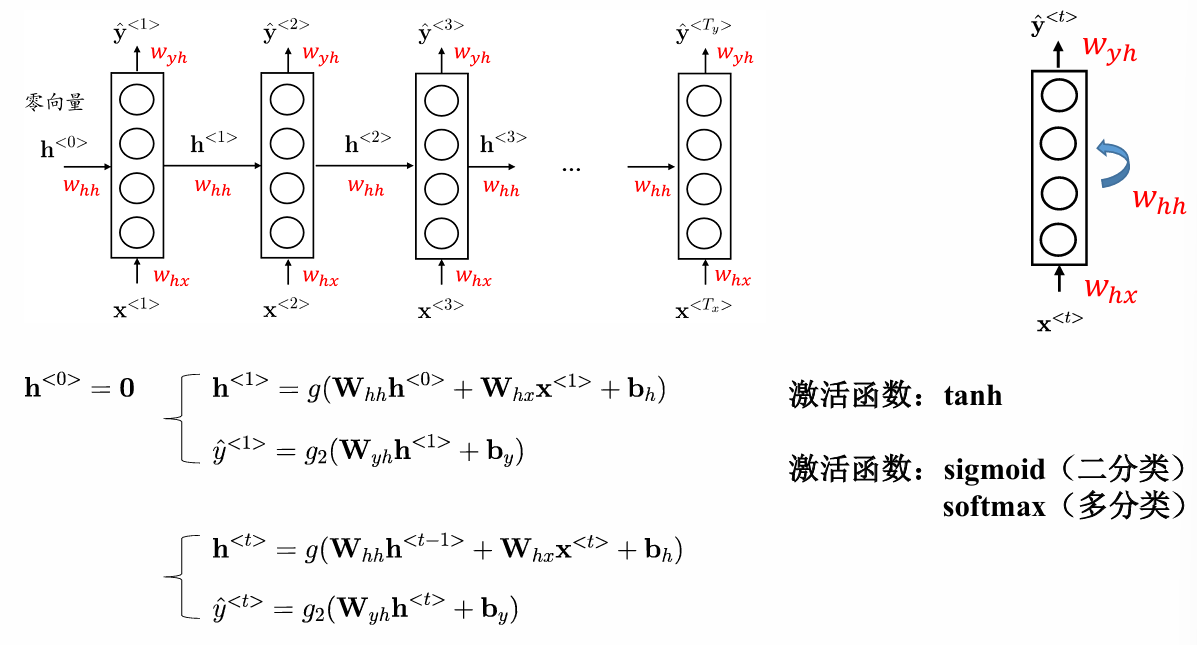
RNN的核心数学表达体现为隐藏状态的迭代更新:
h t = f ( W h h h t − 1 + W h x x t + b h ) h_t = f(W_{hh}h_{t-1} + W_{hx}x_t + b_h) ht=f(Whhht−1+Whxxt+bh)
其中, h t h_t ht为t时刻的隐藏状态, x t x_t xt为输入, W h h W_{hh} Whh和 W h x W_{hx} Whx是权重矩阵, b h b_h bh是偏置, f f f为激活函数(通常为tanh或sigmoid)。输出层的计算则为:
y ^ t = g ( W y h h t + b y ) \hat{y}t = g(W{yh}h_t + b_y) y^t=g(Wyhht+by)
其中 g g g根据任务类型选择激活函数(如softmax用于多分类)。
1.2 前馈神经网络与循环神经网络的对比
1.2.1 信息处理机制差异
-
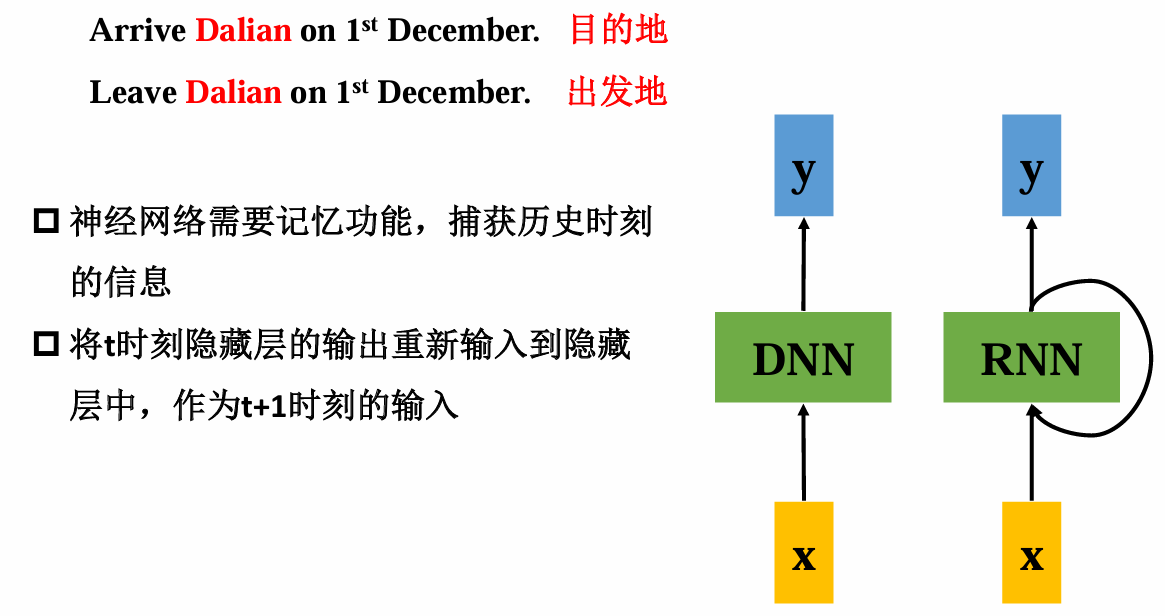
前馈神经网络 :信息单向流动,输入与输出维度固定,不考虑序列上下文。例如,对于句子"Arrive Dalian on 1st December",前馈网络无法区分"Arrive"和"Leave"语境下"Dalian"作为目的地或出发地的差异。

-
循环神经网络 :通过隐藏层状态的循环连接,将历史信息传递至当前时刻。如处理序列时,t时刻的隐藏状态 h t h_t ht依赖于 h t − 1 h_{t-1} ht−1和 x t x_t xt,实现对上下文的记忆。
1.2.2 输入输出灵活性
- 前馈网络要求输入输出维度固定,无法直接处理变长序列。
- RNN可处理不同长度的输入输出序列,且在文本序列的不同位置共享特征提取参数,解决了前馈网络中"特征不共享"的问题。
1.3 循环神经网络的结构组成
1.3.1 基础结构组件
- 输入层 :接收序列数据的当前时间步输入 x t x_t xt,通常为one-hot向量或词嵌入向量。
- 隐藏层 :核心记忆单元,通过循环连接存储历史信息。隐藏层状态 h t h_t ht既作为当前输出的计算依据,又作为下一时刻的输入。
- 输出层 :根据任务类型生成预测结果,如分类标签或序列中的下一个词。
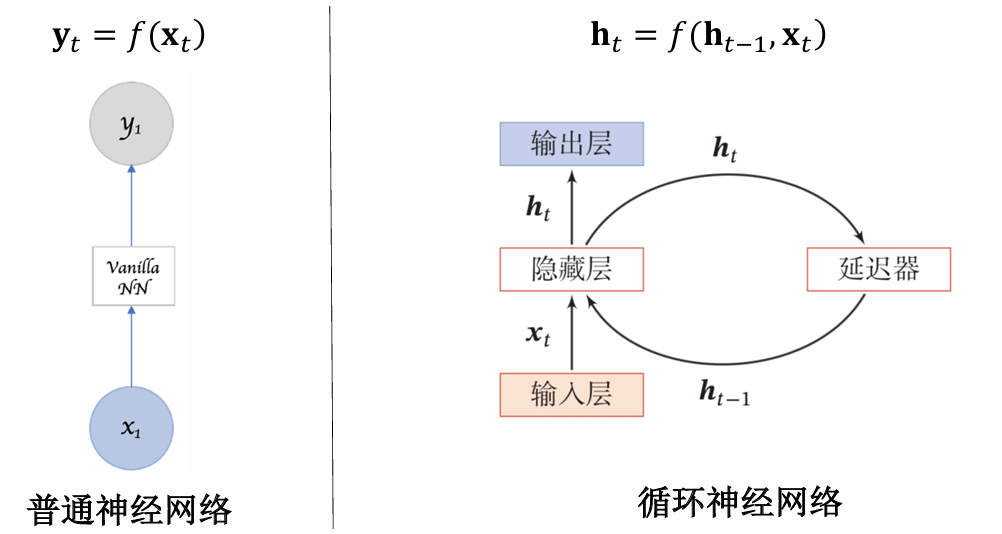
1.3.2 参数共享机制
RNN在每个时间步使用相同的权重矩阵( W h h , W h x , W y h W_{hh}, W_{hx}, W_{yh} Whh,Whx,Wyh),这使得模型能够高效处理不同长度的序列,避免了前馈网络中参数随序列长度线性增长的问题。
二、循环神经网络的核心结构
2.1 基本循环神经网络(Basic RNN)
2.1.1 工作流程
- 从左到右按时间步扫描序列数据,每个时间步t执行以下操作:
- 接收输入 x t x_t xt,结合上一时刻隐藏状态 h t − 1 h_{t-1} ht−1计算当前隐藏状态 h t h_t ht。
- 通过 h t h_t ht生成输出 y ^ t \hat{y}_t y^t。
- 典型应用场景包括:
- 语音识别、音乐生成。
- 情感分类、机器翻译、视频行为识别、命名实体识别。
2.1.2 数学模型与激活函数
- 隐藏层激活函数:通常使用tanh函数,将输出值域限制在-1,1,比sigmoid更适合处理序列中的正负信息。
- 输出层激活函数 :
- 二分类任务使用sigmoid函数,输出0-1之间的概率。
- 多分类任务使用softmax函数,输出各类别概率分布。
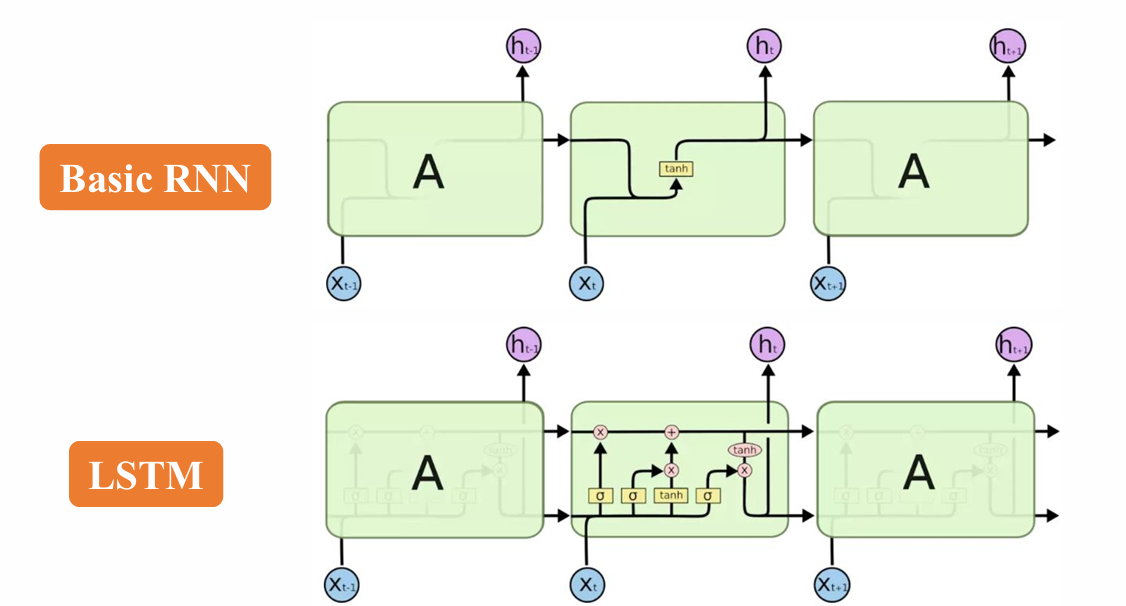
2.2 长短时记忆网络(LSTM)
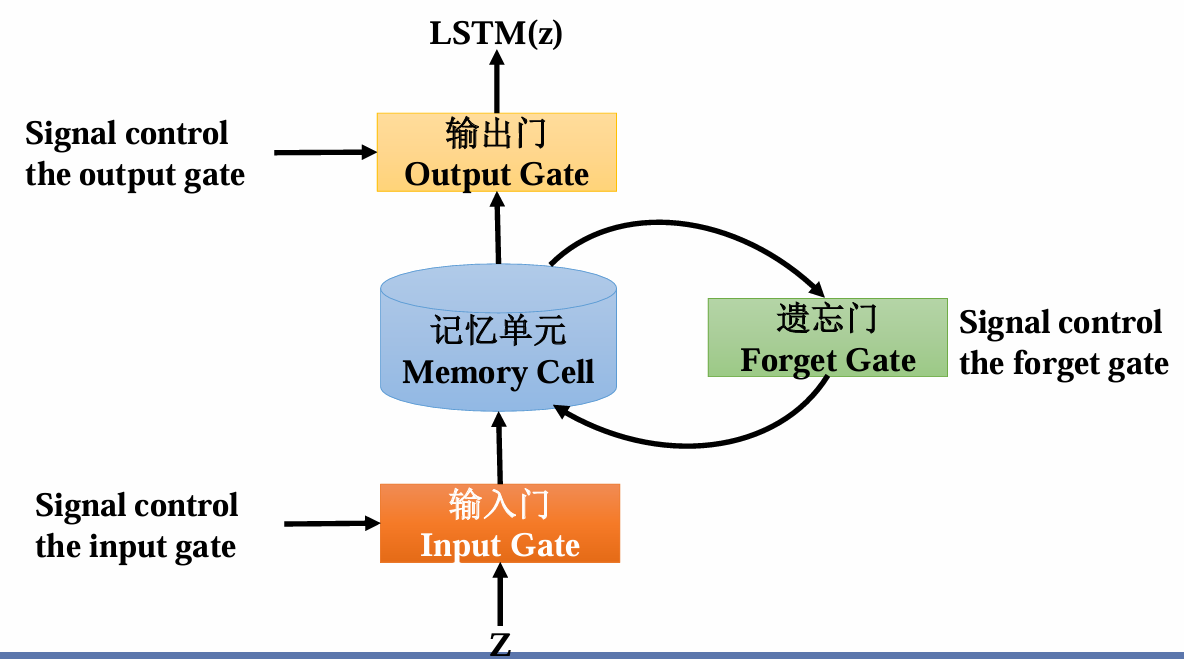
2.2.1 LSTM的核心组件
LSTM通过引入"记忆细胞"和三门控机制,解决了基本RNN的长程依赖问题:
-
记忆细胞(Cell State):
- 类似信息传送带,直接在序列中传递,仅通过线性操作修改,确保长期信息不易丢失。
- 数学表达为 c t c_t ct,贯穿整个LSTM单元。
-
三门控机制:
- 遗忘门(Forget Gate, Γ f \Gamma_f Γf) :
- 功能:决定从记忆细胞中丢弃哪些历史信息。
- 公式: Γ f = σ ( W f h t − 1 , x t + b f ) \Gamma_f = \sigma(W_fh_{t-1}, x_t + b_f) Γf=σ(Wfht−1,xt+bf),输出0-1之间的值,1表示保留,0表示丢弃。
- 输入门(Input Gate, Γ i \Gamma_i Γi) :
- 功能:确定哪些新信息存入记忆细胞。
- 公式: Γ i = σ ( W i h t − 1 , x t + b i ) \Gamma_i = \sigma(W_ih_{t-1}, x_t + b_i) Γi=σ(Wiht−1,xt+bi),配合tanh生成候选记忆单元 c ~ t = t a n h ( W c h t − 1 , x t + b c ) \tilde{c}_t = tanh(W_ch_{t-1}, x_t + b_c) c~t=tanh(Wcht−1,xt+bc)。
- 输出门(Output Gate, Γ o \Gamma_o Γo) :
- 功能:控制记忆细胞的输出内容。
- 公式: Γ o = σ ( W o h t − 1 , x t + b o ) \Gamma_o = \sigma(W_oh_{t-1}, x_t + b_o) Γo=σ(Woht−1,xt+bo),输出与 t a n h ( c t ) tanh(c_t) tanh(ct)相乘得到隐藏状态 h t = Γ o ⋅ t a n h ( c t ) h_t = \Gamma_o \cdot tanh(c_t) ht=Γo⋅tanh(ct)。
- 遗忘门(Forget Gate, Γ f \Gamma_f Γf) :
2.2.2 记忆细胞状态更新
c t = Γ f ⋅ c t − 1 + Γ i ⋅ c ~ t c_t = \Gamma_f \cdot c_{t-1} + \Gamma_i \cdot \tilde{c}_t ct=Γf⋅ct−1+Γi⋅c~t
该公式体现了LSTM的核心机制:通过遗忘门选择性丢弃旧信息,通过输入门添加新信息,实现记忆细胞的动态更新。
2.2.3 LSTM处理长程依赖的优势
- 当遗忘门接近1时,记忆细胞中的历史信息被保留,解决了基本RNN中梯度消失导致的长距离依赖问题。
- 门控机制使LSTM能够动态选择需要记忆的信息,例如在语言模型中保留主语单复数信息以正确选择系动词。
2.3 门控循环单元(GRU)
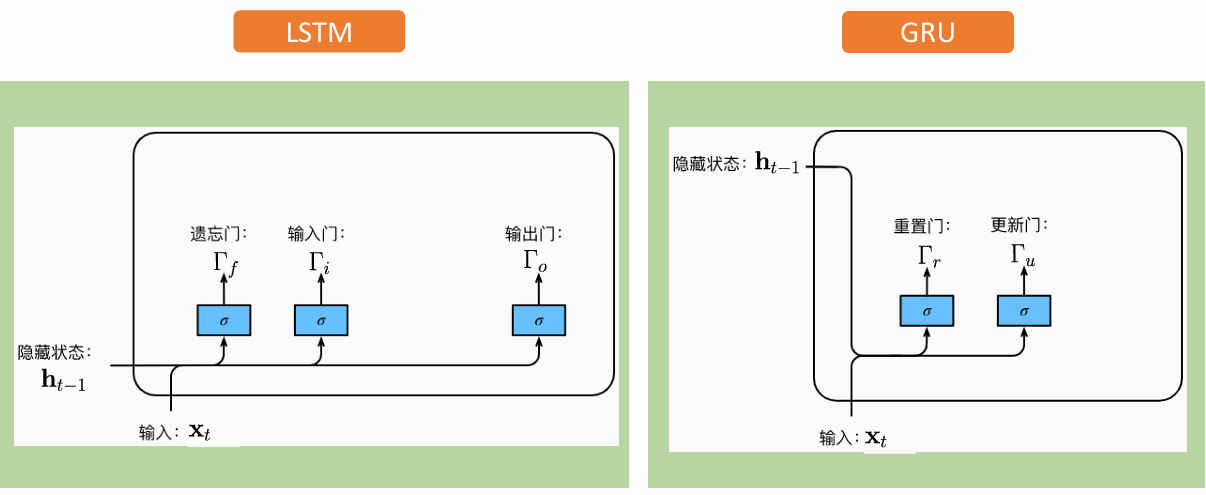
2.3.1 GRU的简化结构
GRU是LSTM的轻量级变体,合并了遗忘门和输入门为"更新门",并移除了独立的记忆细胞,结构更简洁:
- 更新门(Update Gate, Γ u \Gamma_u Γu) :
- 功能:确定是否更新上一时间步的隐藏状态,决定保留多少历史隐藏状态 h t − 1 h_{t-1} ht−1。
- 公式: Γ u = σ ( W u h t − 1 , x t + b u ) \Gamma_u = \sigma(W_uh_{t-1}, x_t + b_u) Γu=σ(Wuht−1,xt+bu)。
- 重置门(Reset Gate, Γ r \Gamma_r Γr) :
- 功能:确定是否丢弃上一时间步的隐藏状态
- 公式: Γ r = σ ( W r h t − 1 , x t + b r ) \Gamma_r = \sigma(W_rh_{t-1}, x_t + b_r) Γr=σ(Wrht−1,xt+br)。
2.3.2 隐藏状态更新
-
候选隐藏状态计算 :
h ~ t = t a n h ( W h Γ r ⋅ h t − 1 , x t + b h ) \tilde{h}_t = tanh(W_h\\Gamma_r \\cdot h_{t-1}, x_t + b_h) h~t=tanh(WhΓr⋅ht−1,xt+bh)重置门决定 h t − 1 h_{t-1} ht−1的参与程度,若 Γ r \Gamma_r Γr接近0,则忽略历史状态,专注于当前输入。
-
最终隐藏状态 :
h t = Γ u ⋅ h t − 1 + ( 1 − Γ u ) ⋅ h ~ t h_t = \Gamma_u \cdot h_{t-1} + (1-\Gamma_u) \cdot \tilde{h}_t ht=Γu⋅ht−1+(1−Γu)⋅h~t更新门控制历史状态与候选状态的融合比例,若 Γ u \Gamma_u Γu接近1,则保留历史状态;若接近0,则以新状态为主。
2.3.3 LSTM与GRU的对比
| 特性 | LSTM | GRU |
|---|---|---|
| 门控数量 | 3个(遗忘门、输入门、输出门) | 2个(更新门、重置门) |
| 记忆单元 | 独立的记忆细胞 c t c_t ct | 无独立记忆单元,隐藏状态直接更新 |
| 计算复杂度 | 较高 | 较低 |
| 长程依赖处理 | 更优 | 较好,略逊于LSTM |
2.4 双向循环神经网络(Bi-RNN)
2.4.1 结构与原理
Bi-RNN包含前向(Forward)和后向(Backward)两个RNN:
- 前向RNN从左到右处理序列,获取历史信息。
- 后向RNN从右到左处理序列,获取未来信息。
- 输出层结合两个方向的隐藏状态: y ^ t = g ( W y h ⃗ t , h ← t + b y ) \hat{y}_t = g(W_y\\vec{h}_t, \\overleftarrow{h}_t + b_y) y^t=g(Wyh t,h t+by)。
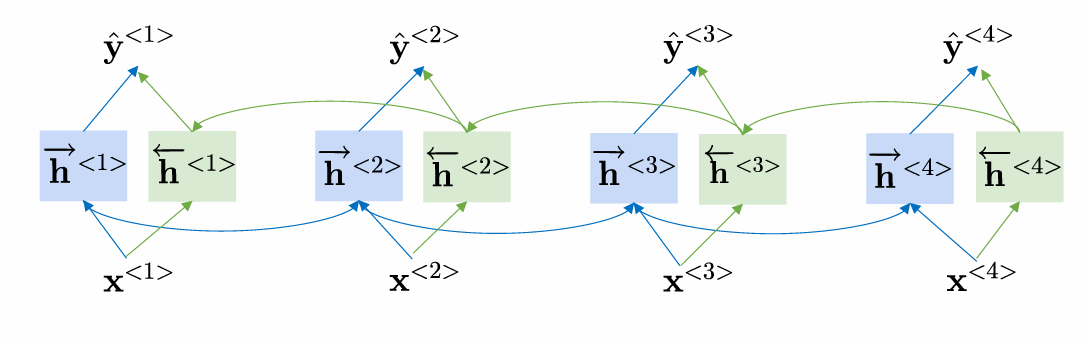
2.4.2 应用场景与局限性
- 优势:适用于需要同时利用上下文信息的任务,如命名实体识别中确定"Harry Potter"是人名,需前后文语境支持。
- 局限:必须获取完整序列后才能预测,无法处理实时流数据。
2.5 深层循环神经网络(Deep RNN)
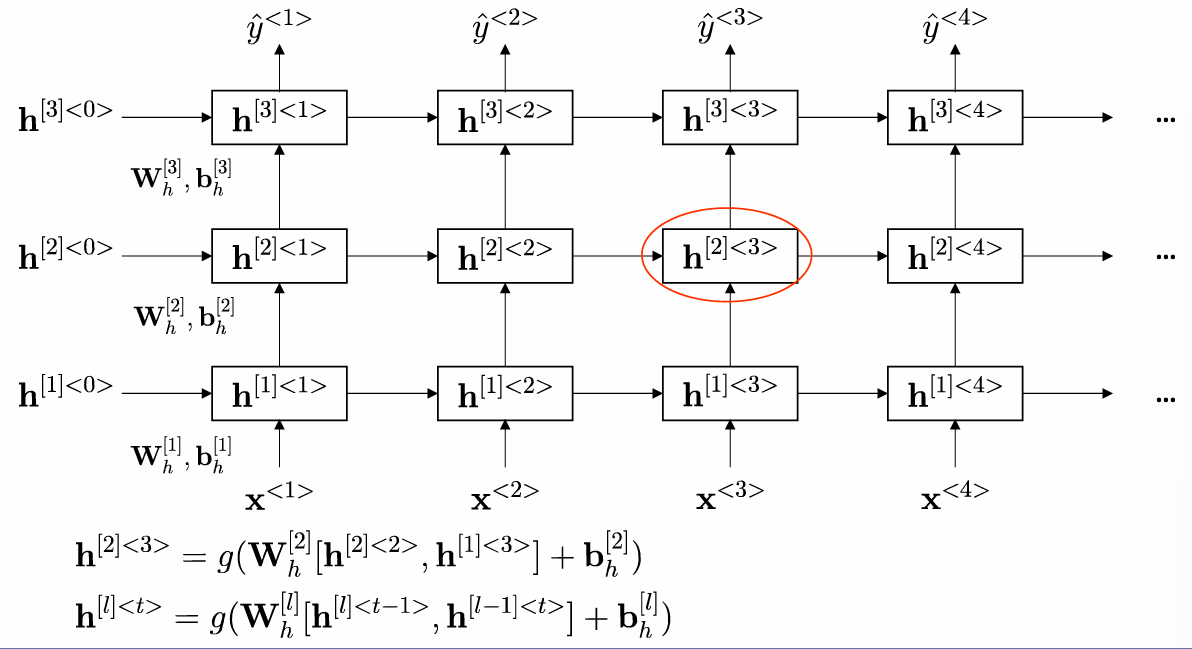
2.5.1 多层堆叠结构
深层RNN在垂直方向堆叠多个RNN层,每层的隐藏状态同时依赖:
- 同一层的前一时间步状态 h t − 1 l h^{l}_{t-1} ht−1l。
- 下一层的当前时间步状态 h t l − 1 h^{l-1}_t htl−1。
2.5.2 状态更新公式
h t l = g ( W h l h t − 1 \[ l , h t l − 1 ] + b h l ) h^{l}t = g(W_h^{l}h\^{\[l}{t-1}, h^{l-1}_t] + b_h^{l}) htl=g(Whlht−1\[l,htl−1]+bhl)
其中 l l l表示层数,深层结构增强了模型对复杂序列特征的提取能力,但也增加了训练难度。
三、循环神经网络的训练方法
3.1 随时间反向传播(BPTT)
3.1.1 BPTT的核心思想
BPTT是RNN的主要训练算法,本质是梯度下降法的时序扩展,其特点是:
- 优化参数包括 W h h , W h x , W y h W_{hh}, W_{hx}, W_{yh} Whh,Whx,Wyh。
- 由于参数在时间步间共享,梯度计算需追溯所有历史时间步,体现RNN的记忆特性。
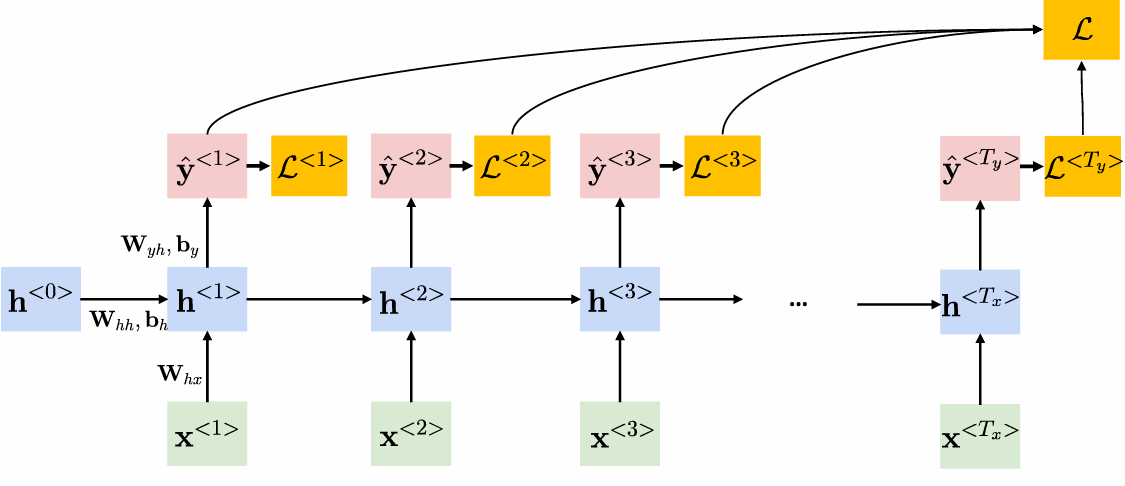
3.1.2 梯度计算细节
-
对 W y h W_{yh} Wyh的梯度 :
∂ L t ∂ W y h = ∂ L t ∂ y ^ t ⋅ ∂ y ^ t ∂ W y h \frac{\partial \mathcal{L}t}{\partial W{yh}} = \frac{\partial \mathcal{L}_t}{\partial \hat{y}_t} \cdot \frac{\partial \hat{y}t}{\partial W{yh}} ∂Wyh∂Lt=∂y^t∂Lt⋅∂Wyh∂y^t直接通过当前时间步的输出误差反向传播。
-
对 W h h W_{hh} Whh的梯度 :
∂ L t ∂ W h h = ∑ k = 1 t ∂ L t ∂ y ^ t ⋅ ∂ y ^ t ∂ h t ⋅ ( ∏ j = k + 1 t ∂ h j ∂ h j − 1 ) ⋅ ∂ h k ∂ W h h \frac{\partial \mathcal{L}t}{\partial W{hh}} = \sum_{k=1}^t \frac{\partial \mathcal{L}t}{\partial \hat{y}t} \cdot \frac{\partial \hat{y}t}{\partial h_t} \cdot \left( \prod{j=k+1}^t \frac{\partial h_j}{\partial h{j-1}} \right) \cdot \frac{\partial h_k}{\partial W{hh}} ∂Whh∂Lt=k=1∑t∂y^t∂Lt⋅∂ht∂y^t⋅ j=k+1∏t∂hj−1∂hj ⋅∂Whh∂hk涉及从当前时间步到k时间步的隐藏状态链式求导,其中 ∂ h j ∂ h j − 1 = f ′ ( W h h h j − 1 + W h x x j + b h ) ⋅ W h h \frac{\partial h_j}{\partial h_{j-1}} = f'(W_{hh}h_{j-1} + W_{hx}x_j + b_h) \cdot W_{hh} ∂hj−1∂hj=f′(Whhhj−1+Whxxj+bh)⋅Whh。
-
对 W h x W_{hx} Whx的梯度 :
与 W h h W_{hh} Whh类似,但求导对象为输入权重,体现了输入对历史隐藏状态的影响。
3.2 训练挑战与解决方案
3.2.1 梯度消失问题
- 原因:sigmoid和tanh的导数值域在0,1,多层连乘导致梯度指数级衰减,深层网络参数无法更新。
- 解决方案 :
- 改变传播结构:采用门控机制(LSTM/GRU),通过门控信号控制梯度流动,避免连乘衰减。
- 选取更好的激活函数:替换激活函数为ReLU,其导数在正数区间为1,缓解梯度消失。
3.2.2 梯度爆炸问题
- 原因 :当 W h h W_{hh} Whh较大时,梯度连乘导致数值爆炸,如 w = 1.01 w=1.01 w=1.01时,1000次迭代后 y = 20000 y=20000 y=20000,梯度异常增大。
- 解决方案 :
- 梯度裁剪(Gradient Clipping):设置阈值,当梯度范数超过阈值时按比例缩放,如 θ = 1 e − 2 \theta=1e-2 θ=1e−2。
3.2.3 记忆容量问题
- 原因 :隐藏状态 h t h_t ht持续累积新信息,若激活函数为Logistic, z t z_t zt增大导致 h t h_t ht饱和,丢失历史信息。
- 解决方案 :
- LSTM通过记忆细胞和门控机制,选择性遗忘旧信息,保持记忆容量的动态平衡。
四、循环神经网络的应用场景
4.1 自然语言处理(NLP)
4.1.1 语言模型(Language Model)
- 目标 :计算词序列的概率,预测下一个词,如 P ( The apple and pear salad ) P(\text{The apple and pear salad}) P(The apple and pear salad)。
- 构建方法 :
- 训练数据:大型文本语料库,输入为one-hot向量,输出为下一词的概率分布。
- 概率计算 :利用链式法则分解联合概率:
P ( y 1 , y 2 , ... , y T ) = ∏ t = 1 T P ( y t ∣ y 1 , ... , y t − 1 ) P(y_1, y_2, \dots, y_T) = \prod_{t=1}^T P(y_t | y_1, \dots, y_{t-1}) P(y1,y2,...,yT)=t=1∏TP(yt∣y1,...,yt−1) - 损失函数 :交叉熵损失 L = − ∑ t = 1 T y y t log y ^ t \mathcal{L} = -\sum_{t=1}^{T_y} y_t \log \hat{y}_t L=−∑t=1Tyytlogy^t。
- 应用:语音识别中区分相似发音的词(如"pair"和"pear")。
4.1.2 情感分类
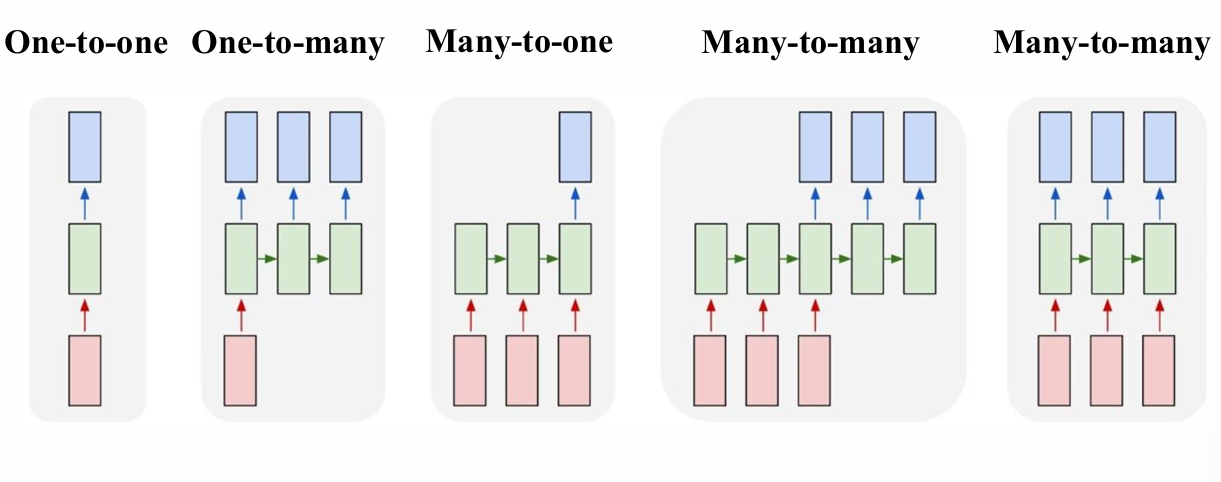
- 结构:Many-to-One RNN,输入为文本序列,输出为情感类别(如正面/负面)。
- 实现方式 :
- 取最后一时间步的隐藏状态 h T h_T hT作为文本特征,输入全连接层分类: y ^ = g ( h T ) \hat{y} = g(h_T) y^=g(hT)。
- 或对所有时间步隐藏状态取平均: y ^ = g ( 1 T ∑ t = 1 T h t ) \hat{y} = g(\frac{1}{T} \sum_{t=1}^T h_t) y^=g(T1∑t=1Tht)。
- 示例:分析句子"There is nothing to like in this movie.",输出负面情感。
4.1.3 命名实体识别(NER)
- 结构:Many-to-Many RNN,输入输出序列长度相同,为每个词标注实体类型(如人名、地名)。
- 符号标记 :
- x < t > x^{<t>} x<t>表示第t个输入词,如"Harry Potter"中的"Harry"。
- y < t > y^{<t>} y<t>表示对应标签,1表示人名,0表示其他。
- 词汇表处理:不在词汇表中的单词用标记,句尾用标记。
4.1.4 机器翻译
- 结构:Seq2Seq模型,由编码器(Encoder)和解码器(Decoder)组成,处理不同长度的源语言和目标语言序列。
- 工作流程 :
- 编码器将源语言序列(如法语"Voulez-vous chanter avec moi?")编码为固定长度向量。
- 解码器从该向量生成目标语言序列(如英语"Do you want to sing with me?")。
- 关键公式 :
- 编码器隐藏状态: h t = f 1 ( h t − 1 , x t ) h_t = f_1(h_{t-1}, x_t) ht=f1(ht−1,xt)
- 解码器隐藏状态: h T + t = f 2 ( h T + t − 1 , y ^ t − 1 ) h_{T+t} = f_2(h_{T+t-1}, \hat{y}_{t-1}) hT+t=f2(hT+t−1,y^t−1)
- 输出: y ^ t = g ( h T + t ) \hat{y}t = g(h{T+t}) y^t=g(hT+t)。
4.2 语音处理
4.2.1 语音识别
- 输入输出:输入为语音特征向量序列,输出为文字序列,长度通常不同。
- CTC(Connectionist Temporal Classification)技术 :
- 问题:解决语音帧与文字的不对齐问题,如输入"好 好 好 棒 棒 棒"对应输出"好棒"。
- 方法 :
- 引入空集字符"−",允许模型输出中间停顿。
- 训练时穷举所有可能的标签(如"好−棒", "好−−棒"等)作为样本。
- 测试时合并重复字符并移除空集,得到最终文本。
4.2.2 音乐生成
- 实现方式:使用LSTM学习音乐模式,如Deepjazz项目通过两层LSTM从MIDI文件中学习爵士音乐规律,生成新曲目。
- 技术流程 :
- 将音乐符号转换为序列输入RNN。
- 训练模型预测下一个音符的概率分布。
4.3 计算机视觉应用
4.3.1 图像加字幕(Image Captioning)
- 流程 :
- CNN提取图像特征(如"一只猫坐在椅子上"的视觉特征)。
- RNN将特征解码为自然语言描述,结构为One-to-Many RNN。
- 示例:输入图像特征,RNN逐词生成"A cat sitting on a chair"。
4.4 其他应用场景
4.4.1 触发字检测
- 应用:智能语音助手检测关键词,如"小度小度"、"Hey Siri"等。
- 实现:RNN处理音频序列,输出0/1标记是否检测到触发字。
4.4.2 视频行为识别
- 方法:将视频帧序列输入RNN,识别动作类别,如"Running"。
- 关键:利用RNN捕捉帧间时序关系,结合CNN提取视觉特征。
五、循环神经网络的关键定理与参考资源
5.1 通用近似定理
- 内容:若完全连接的RNN拥有足够数量的sigmoid隐藏神经元,可任意准确率近似任何非线性动力系统。
- 数学表达 :
s t = g ( s t − 1 , x t ) , y t = o ( s t ) s_t = g(s_{t-1}, x_t), \quad y_t = o(s_t) st=g(st−1,xt),yt=o(st)
其中 s t s_t st为隐状态, x t x_t xt为输入, g g g为状态转换函数, o o o为输出函数。
5.2 参考资源与实现案例
5.2.1 理论参考
- Andrew Ng的Recurrent Neural Network课程。
- 李宏毅的深度学习课程(B站链接:https://www.bilibili.com/video/BV1JE411g7XF)。
5.2.2 代码实现(PyTorch示例)
- RNN模型定义:
python
import torch.nn as nn
class RNNModel(nn.Module):
def __init__(self, rnn_layer, vocab_size):
super(RNNModel, self).__init__()
self.rnn = rnn_layer
self.hidden_size = rnn_layer.hidden_size
self.vocab_size = vocab_size
self.dense = nn.Linear(self.hidden_size, vocab_size)
def forward(self, inputs, state):
# 输入形状转换:(batch, seq_len) -> seq_len个(batch, vocab_size)
X = nn.functional.one_hot(inputs, self.vocab_size).float()
X = X.permute(1, 0, 2)
Y, state = self.rnn(X, state)
# 输出形状:(seq_len, batch, hidden_size) -> (batch*seq_len, hidden_size)
output = self.dense(Y.reshape(-1, Y.shape[-1]))
return output, state- 训练过程关键步骤:
python
# 梯度裁剪防止爆炸
def grad_clipping(parameters, theta, device):
if isinstance(parameters, torch.Tensor):
parameters = [parameters]
total_norm = torch.norm(torch.stack([torch.norm(p.grad.detach(), 2) for p in parameters if p.grad is not None]))
if total_norm > theta:
for param in parameters:
if param.grad is not None:
param.grad.detach().div_(total_norm / theta)- 文本生成示例:
python
def predict_rnn_pytorch(prefix, num_chars, model, vocab_size, device, idx_to_char, char_to_idx):
state = None
output = [char_to_idx[prefix[0]]]
for t in range(num_chars + len(prefix) - 1):
X = torch.tensor([output[-1]], device=device).view(1, 1)
(Y, state) = model(X, state)
if t < len(prefix) - 1:
output.append(char_to_idx[prefix[t+1]])
else:
output.append(Y.argmax(dim=1).item())
return ''.join([idx_to_char[i] for i in output])5.3 训练与应用案例结果
- 语言模型训练:经过500轮迭代,困惑度(perplexity)从初始值降至1.009586,生成文本如"分开我感动可爱女人坏坏的让我疯狂的可爱女人..."。
- 参数配置:隐藏层大小256,序列长度35,批量大小32,学习率1e-3,梯度裁剪阈值1e-2。