在企业数字化加速的背景下,越来越多的组织开始意识到:传统的数据系统正逐渐成为增长的"瓶颈"而非"助力"。其中,SQL Server 作为许多企业IT架构中曾经的中坚力量,正面临前所未有的挑战。它曾以稳定、易用、成本可控等优势,在企业各大业务系统中广泛部署。但随着数据规模的指数级增长与使用方式的全面升级,企业正逐步走到这样一个转折点:SQL Server,不够用了。
本文将系统解析企业在面对SQL Server瓶颈时,如何构建面向未来的分布式数据架构,并分享某客户海外业务如何从SQL Server迁移到分布式大数据平台。

SQL Server为何"失效"?
SQL Server本质上并未失效,仍以其"高稳定、低门槛、生态丰富"而广泛应用于中小型数据量场景中。"失效"是因为面对高复杂、高并发、高频次数据场景时,原有架构已经"吃不动了"。SQL Server 本质上是一种典型的单体关系型数据库系统,它适合结构化数据、事务处理和中低并发的数据操作。但随着企业实际业务演进中,以下问题愈发凸显:
-
数据体量突破亿级,查询变得缓慢且不稳定;
-
查询任务越来越复杂,涉及多表join、大量逻辑判断与计算操作;
-
查询任务运行时间长(往往需数小时),严重占用计算资源,阻塞其他任务;
-
报表时效性要求提升,从天级逐渐逼近小时甚至分钟级;
-
数据来源多样化,SQL Server难以对接流数据、对象存储、异构数据源。
这些问题的本质,是SQL Server的架构范式------以单体、集中式、强耦合为核心,已难以支撑"高并发、高复杂度、高异构"的现代数据需求。

迁移的底层逻辑:从"优化SQL"到"重构计算架构"
很多企业在SQL任务变慢时,第一反应往往是"调SQL"、"加索引"、"扩内存",但效果有限。真正的出路是架构转换 ------迈向分布式计算平台。
其核心逻辑包括:
-
存储计算解耦:将数据存储于分布式文件系统(如HDFS、对象存储),计算任务则由独立计算引擎按需调度;
-
任务并行拆解:原本串行执行的大SQL语句,被拆解为多个子任务并发执行;
-
多源适配与统一治理:构建统一的数据接入层,支持关系型、半结构化、流数据等异构数据源;
-
调度与监控能力升级:实现任务级调度编排、失败重试、运行监控、指标埋点等平台级能力;
-
应用标准化与服务化:为后续构建指标平台、智能洞察等高级数智应用服务能力奠定基础。

从SQL Server到分布式大数据平台迁移方案设计
以袋鼠云方案为例,典型的SQL Server迁移解决方案由以下五个核心步骤组成:
产品部署
**目标:**构建高可用、可扩展的计算与存储平台。
关键动作:
-
通过部署大数据存储计算平台 EasyMR 和离线平台 BatchWorks,快速搭建分布式运行底座;
数据接入
**目标:**快速适配多种数据源,实现统一采集能力。
关键动作:
-
支持主流关系型数据库(如 SQL Server、Oracle)、非关系型数据库(如 MongoDB)、消息队列(如 Kafka)等;
-
通过标准化连接器配置方式,实现数据源快速打通及连通性验证。
数据同步
**目标:**实现历史数据与实时数据的高效同步与治理。
关键动作:
-
全量同步:支持一次性将 SQL Server 中的历史数据导入 Hive,效率可控、过程可监控;
-
增量同步:支持分钟级的多表增量调度,保障数据实时性,适配日常运行需求。
业务SQL拆解
**目标:**重构 SQL 执行逻辑,提升计算效率与并发处理能力。
关键动作:
-
将传统单体大 SQL 拆解为多个可并行的子任务,自动映射为 Trino 等计算引擎中的执行单元;
-
结合任务依赖关系构建工作流,支持串联与并联组合执行;
-
利用 MPP 架构与联邦查询,提升多源计算与跨表分析能力。
任务调度
**目标:**提供灵活稳定的调度机制,保障数据服务可靠输出。
关键动作:
-
支持 Cron 表达式与多粒度调度策略,覆盖分钟级到小时级的调度需求;
-
调度作业可视化监控,提供实时运行状态、资源使用情况等指标;
-
配置自动重试与告警机制,提升系统稳定性与任务成功率。

某客户海外业务SQL Server迁移实践:查询任务耗时从 4 小时缩短至 20 分钟
为应对日益增长的数据处理需求,某客户海外业务在近期的数字化升级过程中,完成了核心数据任务从 SQL Server 向袋鼠云离线平台 BatchWorks+大数据存储计算平台 EasyMR 的成功迁移,原先需运行 3-4 小时的复杂 SQL 查询任务,现已稳定控制在 20 分钟以内,显著提升了运营效率与数据响应能力
业务挑战
某客户海外业务日常运营高度依赖数据支撑。然而,部分核心数据处理任务依然运行于传统的 SQL Server 等关系型数据库平台。在任务数量庞大、逻辑复杂的情况下,大型查询任务不仅耗时极长,还会严重占用系统资源,进一步影响其他任务的执行效率。
尤其典型的是某个用于运营分析的查询任务,SQL 长度逾千行、涉及数十张数据表、字段数百不等,处理数据规模从百万至亿级。该任务每日必须执行,单次运行耗时超过 3 小时,并频繁阻塞其他关键任务,成为数据系统性能的瓶颈,也限制了业务部门对关键指标的及时获取。
客户希望在不影响现有系统稳定性的前提下,通过更先进的技术架构,将该类任务耗时控制在半小时以内。
解决方案
针对客户需求,袋鼠云基于数栈离线开发平台与自主研发的 EMR 产品,设计并交付了一套完整的 SQL Server 向分布式平台迁移方案,覆盖从数据接入、任务拆解到调度执行的全流程,具体包括以下五个阶段:
产品部署
构建高可用的分布式计算环境。部署 3 节点 Trino EMR 集群(6 核 CPU、32GB 内存、500GB 磁盘),配合离线开发平台,实现统一管理与任务开发。
数据接入
接入 SQL Server 数据源,配置连接器并验证连通性。同时预留对 MongoDB、Kafka 等多源接入能力,支持未来多样化的数据场景。

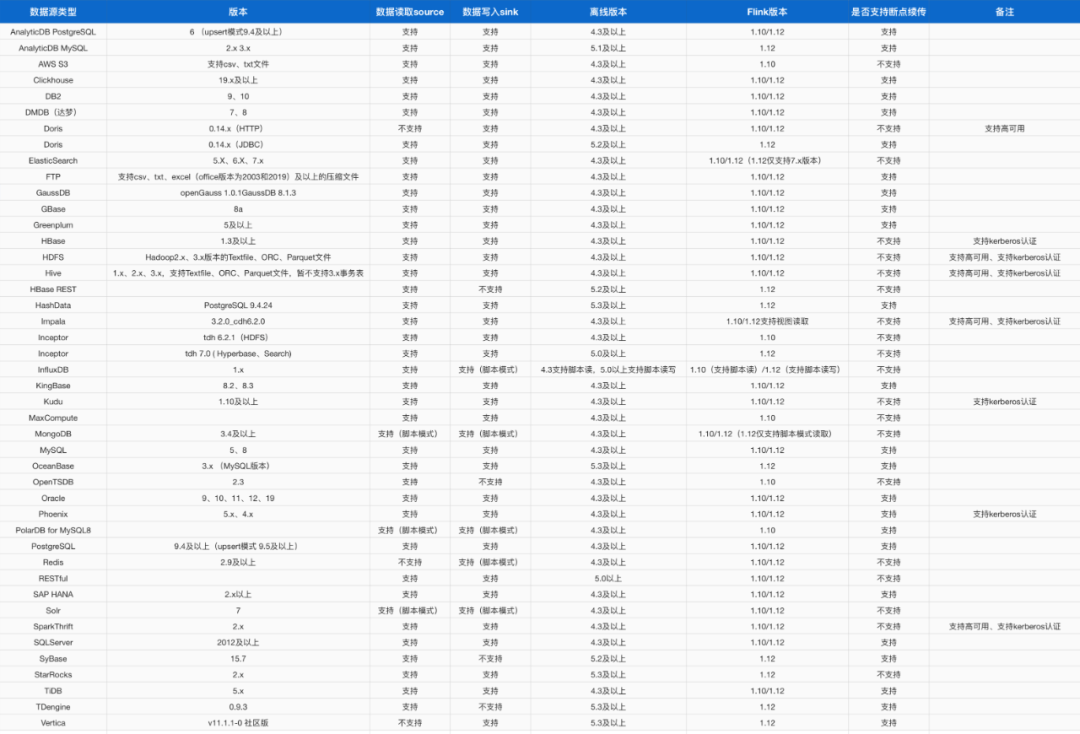
袋鼠云适配数据源清单
一次性完成历史数据全量同步至 Hive 表(耗时约 1 小时),后续通过日调度任务实现分钟级增量同步,保障数据的持续更新。
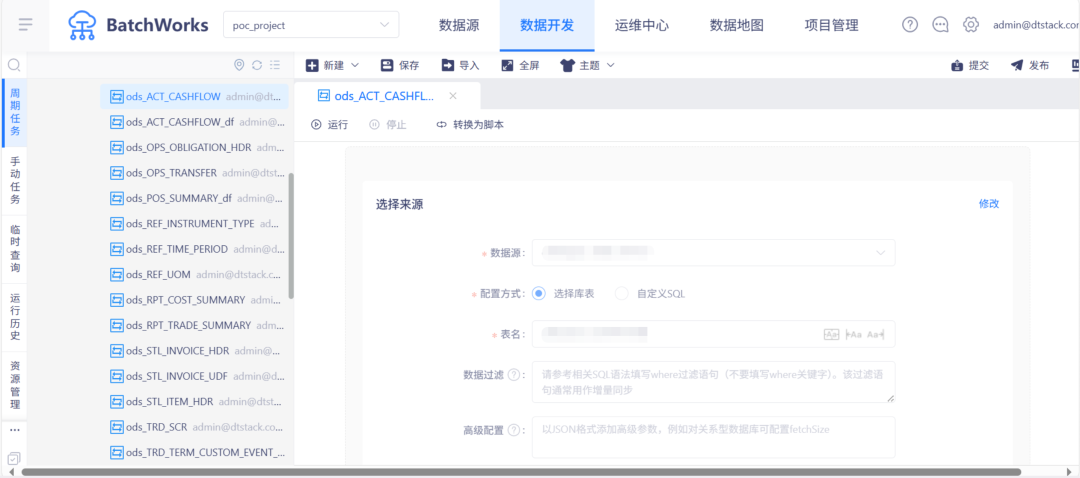
业务 SQL 拆解与并行重构
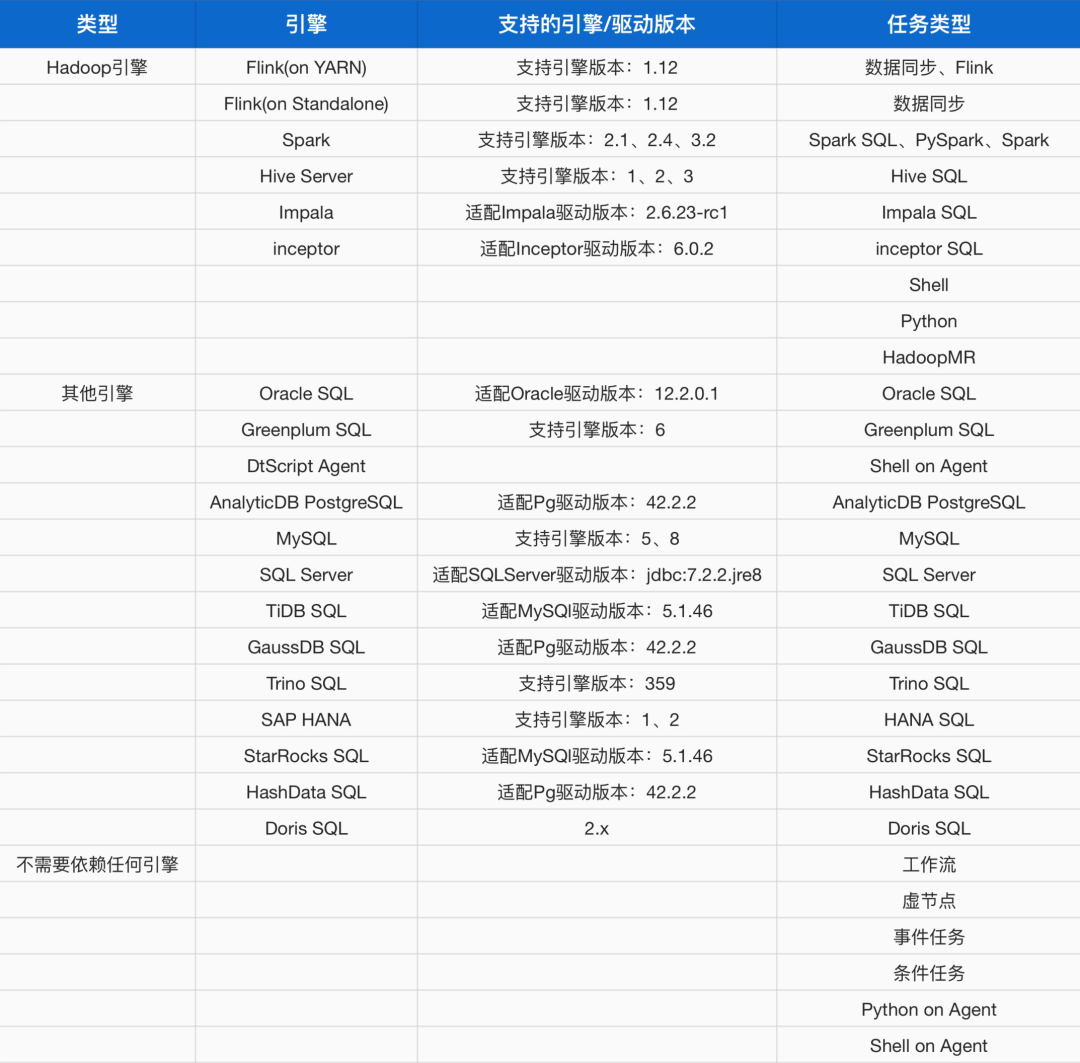
迁移后使用袋鼠EMR Trino底层计算引擎,通过Trino查询同步到Hive中的数据,即可达到原来相同效果。同时Trino相对于 SQL Server 有如下优势:大规模并行处理能力、多数据源联邦查询、弹性扩展、任务资源使用限制。离线产品不仅可以对接我们EMR中的Trino引擎,还支持对接以下引擎:
将原有复杂 SQL 按依赖关系拆解为多个子任务,通过 Trino 引擎并行执行。
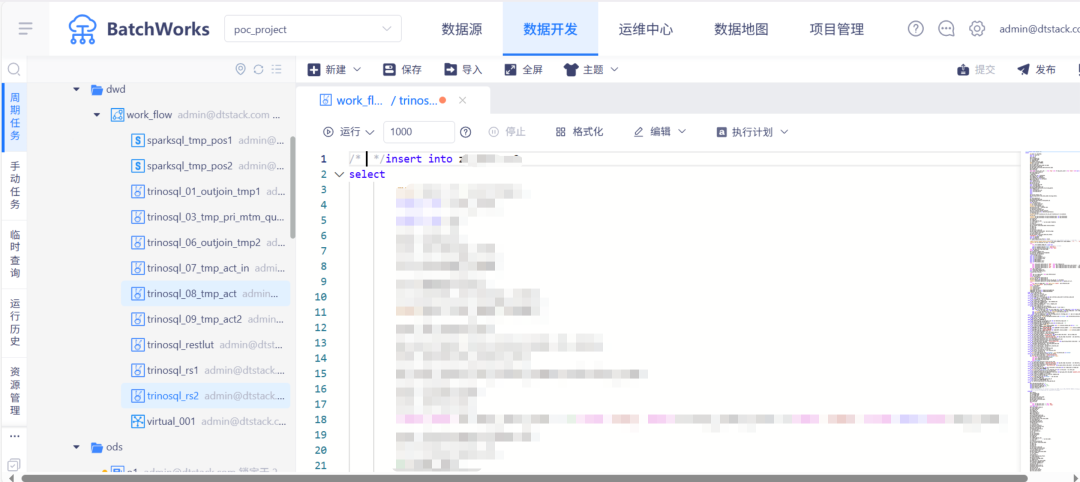
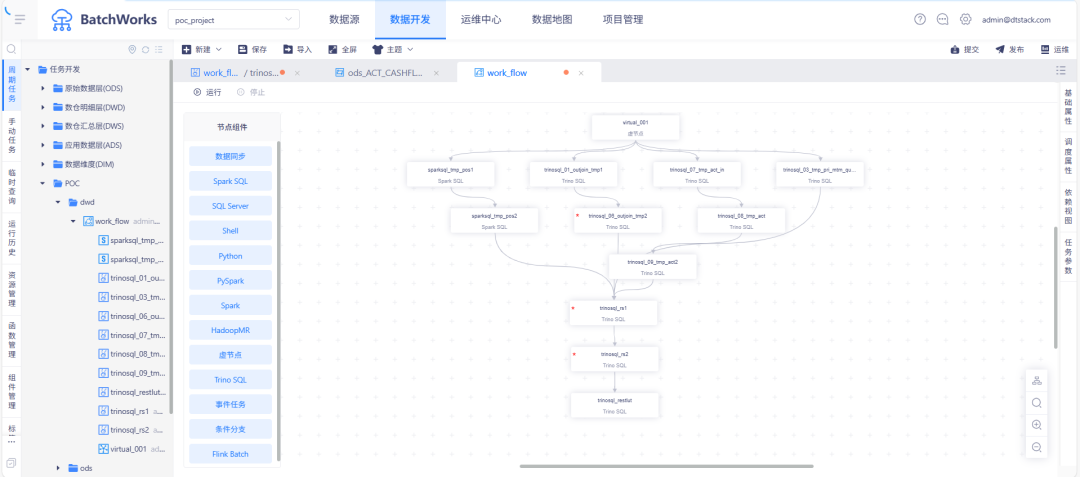
结合离线平台的工作流定义能力,实现串并联组合,显著提升执行效率。
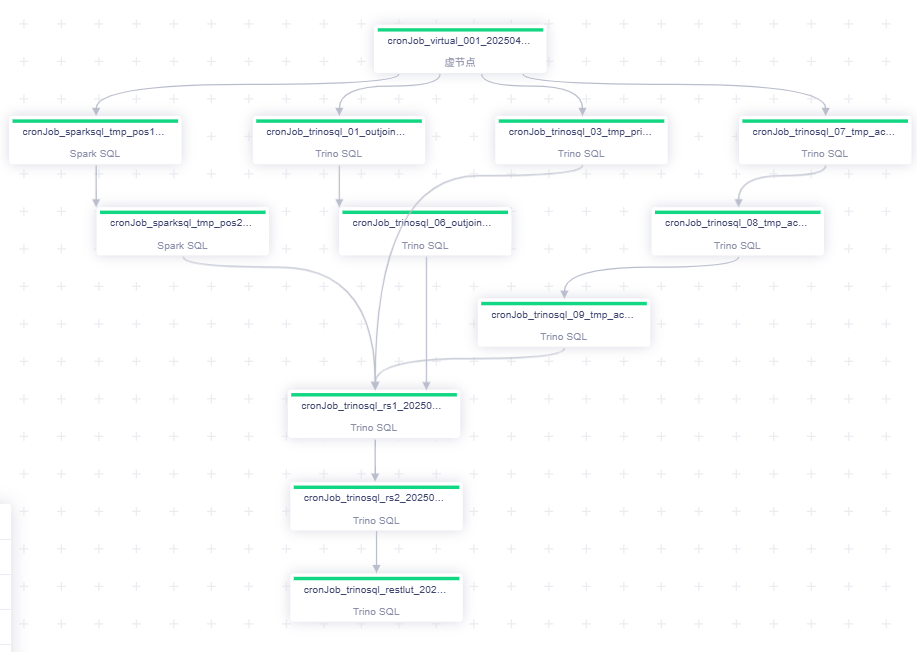
任务调度与可视化监控
基于离线平台支持多颗粒度调度策略(分钟/小时/天/周/Cron 等),实现任务准时运行、状态追踪、自动告警与失败重试,确保数据按时产出。

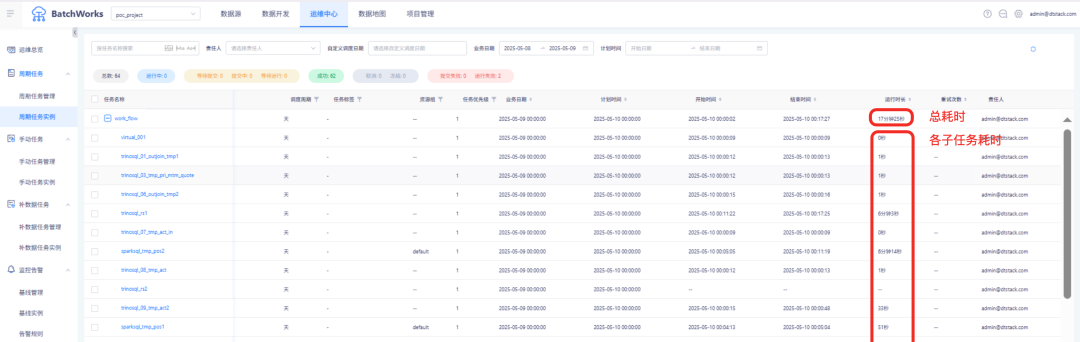
迁移成效
通过本次技术改造,该客户海外业务的关键数据任务运行耗时从 3-4 小时大幅缩短至 20 分钟以内,不仅释放了计算资源,提升了整体任务并发能力,也为运营分析、业务决策提供了更加及时的数据支持。更重要的是,客户团队对新平台的可操作性、可维护性及拓展能力给予高度认可,为后续更多业务场景的迁移与数据治理奠定了坚实基础。