微服务架构日志采集及可视化平台搭建详解(EFK框架:ElasticSearch、Fluentd、kibana)
简介
在微服务架构下,服务众多,日志分散,难以整合进行全局检索分析,日志平台提供了全局日志采集、传输、存储与检索功能。
常用的日志解决技术方案
1、ELK:ElasticSearch + Logstash + kibana
ElasticSearch是一个分布式分析搜索引擎,可以存储大量日志数据,快速搜索日志和聚合功能,实现大规模日志的高效处理
Logstash是一个日志采集、过滤、转发工具,可以从文件、网络、消息队列中采集日志并发送到ElasticSearch进行存储
Kibana是日志的可视化平台,从ElasticSearch获取日志数据,进行数据分析,提供了更富的日志分析工具
2、EFK :ElasticSearch + Fluentd + kibana
Fluentd是日志采集工具,从日志文件采集日志进行格式转换,并上传到ElasticSearch进行存储,EFK是对ELK的改进,Fluentd性能比Logstash更高,适合处理大量日志数据
3、 PLG Stack: Promtail + Loki + Grafana
Promtail 日志采集器(读取文件、输出到 Loki)
Loki 类似 Elasticsearch 的日志存储,但为日志优化(轻量级)
Grafana 可视化日志,结合 Prometheus 实现日志+监控统一视图
三种方案比较:
ELK和EFK作为日志可视化平台,功能强大,具有强大的日志索引能力,占用资源更高,性能高,适合大量数据。
PLG不支持复杂字段索引,但是部署更轻量,适合云原生、功能较为简单,处理数据量少。
下面详细介绍如何实现微服务日志可视化EFK
1、微服务日志输出可以输出到指定目录中
springboot默认采用logback日志框架,日志输出格式可以选择json或者按正则表达视式输出,不同格式当然需要配置不同解析器,这里我们可以先不管,主要准备好日志源文件。
输出json日志:
pom.xml
java
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>7.4</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId
</dependency>resource/logback-spring.xml
java
<?xml version="1.0" encoding="UTF-8"?>
<!--debug 是否打印logback中的日志 scan 是否检测logback配置文件变化更新-->
<configuration scan="true" debug="false">
<!--springProperty 是spring结合logback的新属性,会解析application.yml中的配置变量 :-logs 是默认值写法${BUILD-FOLDER:-logs} spring不支持-->
<springProperty scope="context" name="LOG_PATH" source="logging.file.path" defaultValue="logs/${spring.application.name}"/>
<springProperty scope="context" name="LOG_NAME" source="spring.application.name" defaultValue="app"/>
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_PATH}/${LOG_NAME}.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_PATH}/${LOG_NAME}-%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<!-- JSON 编码 -->
<encoder class="net.logstash.logback.encoder.LogstashEncoder">
<customFields>{"appName":"${LOG_NAME}"}</customFields>
</encoder>
</appender>
<!-- 控制台输出 -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<root level="INFO">
<appender-ref ref="FILE"/>
<appender-ref ref="STDOUT"/>
</root>
</configuration>java代码:
java
Logger logger = LoggerFactory.getLogger(AccountServiceImpl.class);
@Autowired
AccountTblMapper accountTblMapper;
@Transactional //本地事务
@Override
public void debit(String userId, int money) {
logger.info("account -debit 扣减余额服务");
// 扣减账户余额
accountTblMapper.debit(userId,money);
}这里就可以拿到一个json格式日志文件了,fluentd解析json不需要额外配置,相对简单
java
{"@timestamp":"2025-06-09T10:45:45.1149641+08:00","@version":"1","message":"Find sentinel dashboard server list: []","logger_name":"com.alibaba.cloud.sentinel.endpoint.SentinelHealthIndicator","thread_name":"RMI TCP Connection(5)-192.168.56.1","level":"INFO","level_value":20000,"nacosConfigLogLevel":"info","logPath":"${user.home}/logs","logRetainCount":"7","LOG_NAME":"seata-account","LOG_PATH":"logs/${spring.application.name}","logFileSize":"10MB","appName":"seata-account"}
{"@timestamp":"2025-06-09T10:48:50.9341798+08:00","@version":"1","message":"Initializing Spring DispatcherServlet 'dispatcherServlet'","logger_name":"org.apache.catalina.core.ContainerBase.[Tomcat].[localhost].[/]","thread_name":"http-nio-10001-exec-1","level":"INFO","level_value":20000,"nacosConfigLogLevel":"info","logPath":"${user.home}/logs","logRetainCount":"7","LOG_NAME":"seata-account","LOG_PATH":"logs/${spring.application.name}","logFileSize":"10MB","appName":"seata-account"}
{"@timestamp":"2025-06-09T10:48:50.9351812+08:00","@version":"1","message":"Initializing Servlet 'dispatcherServlet'","logger_name":"org.springframework.web.servlet.DispatcherServlet","thread_name":"http-nio-10001-exec-1","level":"INFO","level_value":20000,"nacosConfigLogLevel":"info","logPath":"${user.home}/logs","logRetainCount":"7","LOG_NAME":"seata-account","LOG_PATH":"logs/${spring.application.name}","logFileSize":"10MB","appName":"seata-account"}很多时候我们的日志格式并不是json,以文本格式存储的,如:
java
[2024-11-29 09:59:41.452] [] [com.example.order.Application] INFO 55: Starting Application using Java 1.8.0_361 on LAPTOP-TOOUJOQT with PID 35752 (E:\AiTrade2\KOCA_OCDES\aitrade\target\classes started by kxh in E:\AiTrade2\KOCA_OCDES\aitrade)这种时候就要针对这种正则表达式进行解析。多种格式日志也没关系,fluentd支持配置多个日志源采集,只要配置解析器就可以。
比如:json格式日志输出到一个目录,text格式日志输出到一个目录
bash
还有一种情况,日志分布在不同宿主机器上,这个时候可能需要在每一个节点部署一个fluentd代理采集日志发送到EL中心2、日志源准备好了,开始采集吧
fluentd服务部署,部署方案有两种:
- Linux服务器本地部署
- Docker部署
我们这里介绍docker部署,机器配置2核2G足够,用到了docker-compose构建
bash
efk-docker/
├── docker-compose.yml
│── flutend/
├──conf
│ ──fluent.conf
│ ──DockerfileDockerfile需要引入插件:
bash
[root@master2 fluentd]# cat Dockerfile
FROM fluent/fluentd:v1.16-1
USER root
# 安装 elasticsearch 插件
RUN gem install fluent-plugin-elasticsearch --no-document
USER fluentdocker-compose.yml:
bash
[root@master2 efk-docker]# cat docker-compose.yml
services:
fluentd:
#image: fluent/fluentd:v1.16-1
build:
context: ./fluentd
container_name: fluentd
volumes:
- ./fluentd/conf:/fluentd/etc
- /var/log:/var/log
- /opt/log:/opt/log
ports:
- "24224:24224"
- "24224:24224/udp"
# depends_on:
# - elasticsearch
networks:
- efk-net
networks:
efk-net:
driver: bridge
[root@master2 efk-docker]# fluentd配置文件需要配置采集日志源,输出目标地址ELSearch,配置文件我们放在构建路径下,/opt/efk-docker/fluentd/conf/fluent.conf
bash
[root@master2 efk-docker]# cat ./fluentd/fluent.conf
<source>
@type tail
path /opt/log/myapp/*.log # 监控的日志文件路径
pos_file /fluentd/log/myapp.log.pos # 记录读取位置的文件,防止重复读
tag myapp.log # 产生事件的标签
format json # 直接指定格式为json,tail插件内置支持
read_from_head true # 启动时从文件开头开始读取
</source>
# 非json日志
<source>
@type tail
path /opt/log/aitrade/*.log # 监控的日志文件路径
pos_file /fluentd/log/aitrade.log.pos # 记录读取位置的文件,防止重复读
tag myapp.textlog # 产生事件的标签
read_from_head true # 启动时从文件开头开始读取
<parse>
@type multiline
format_firstline /^\[\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d+\]/
format1 /^\[(?<time>[^\]]+)\] \[(?<trace_id>[^\]]*)\] \[(?<logger>[^\]]+)\] (?<level>\w+) (?<line>\d+): (?<message>.*)/
time_format %Y-%m-%d %H:%M:%S.%L
</parse>
</source>
<match myapp.**>
@type copy # 多路输出
<store>
@type elasticsearch # 输出到 Elasticsearch
host 42.192.135.223
port 9200
scheme http
logstash_format true # 启用Logstash格式,生成时间戳索引
logstash_prefix myapp-log # 索引前缀
include_tag_key true # 包含tag字段
reconnect_on_error true
reload_on_failure true
</store>
<store>
@type stdout # 同时打印到标准输出,方便调试
</store>
</match>这里就配置好了,可以直接启动docker
bash
docker compose up -d查看fluentd采集日志
bash
docker logs fluentd -f3、部署ElsaticSearch
首先要部署的是ElsaticSearch,因为fluentd启动会去找el的地址,这个我们单独一台服务器部署,测试机器2核2G部署三个服务资源不足,另外找一台机器部署。
ELsearch和kinbana很容易部署的
bash
[root@master1 efk-docker]# cat docker-compose.yml
services:
elasticsearch:
image: 6541ba648813
container_name: elasticsearch
environment:
- discovery.type=single-node
- bootstrap.memory_lock=true
- ES_JAVA_OPTS=-Xms512m -Xmx512m
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- esdata:/usr/share/elasticsearch/data
ports:
- "9200:9200"
- "9300:9300"
networks:
- efk-net
kibana:
image: docker.elastic.co/kibana/kibana:7.17.17
container_name: kibana
environment:
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
depends_on:
- elasticsearch
ports:
- "5601:5601"
networks:
- efk-net
volumes:
esdata:
networks:
efk-net:
driver: bridge
[root@master1 efk-docker]# 直接启动这个docker compose就好了
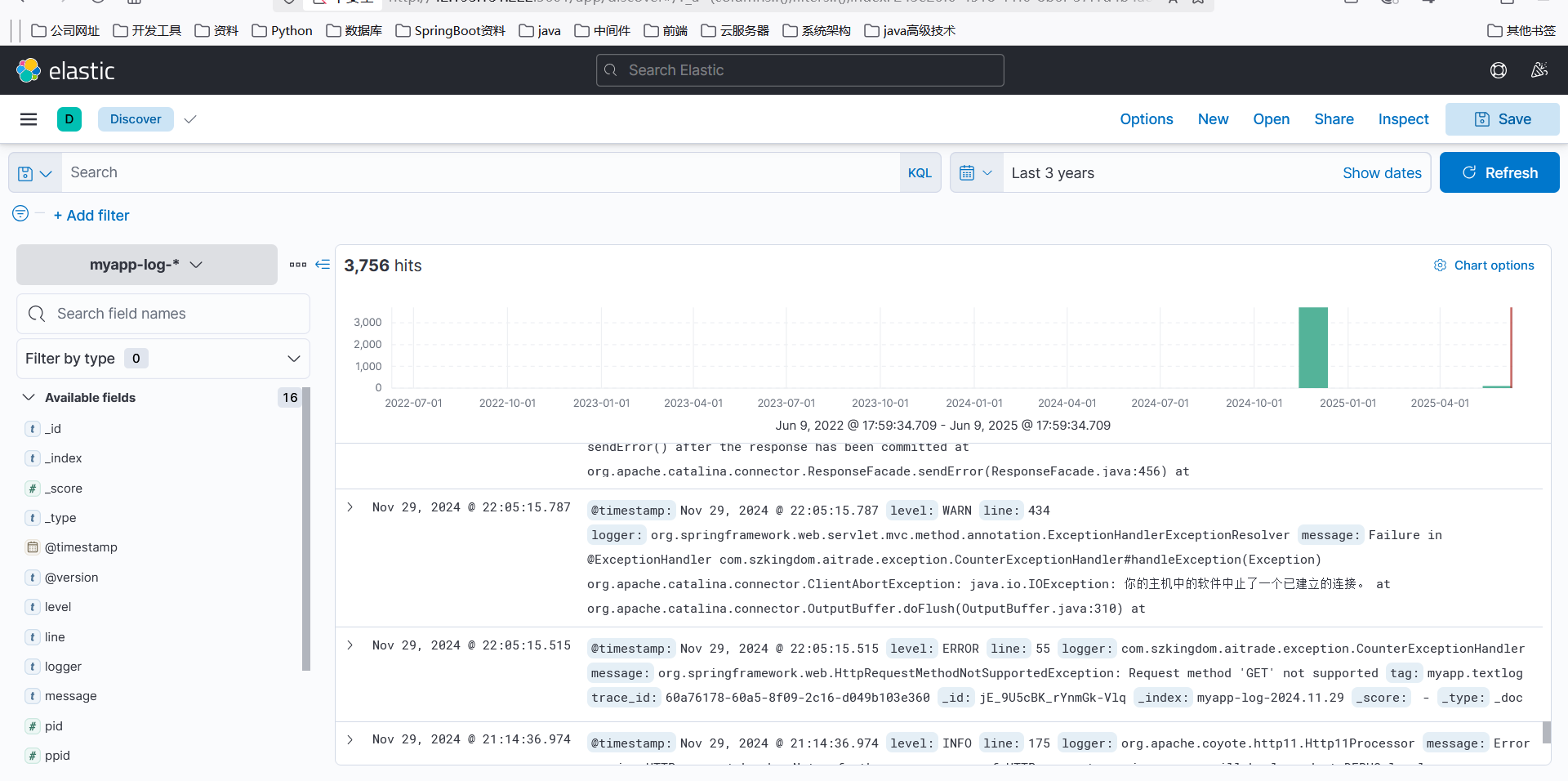
启动好了后,前端访问http://42.192.133.32:5601,ip为kinbana宿主机地址,就可以进入kinbana页面了。
4、前端访问
kinbana还看不到日志数据,需要创建索引,进入页面就会提示Create Index Pattern 进入创建 ,name填写之前配置的( logstash_prefix myapp-log # 索引前缀) ,这里填myapp-log*,另外一个空选择@timestamp即可,回到日志页面就可以看到我们的日志信息了