1st author: Zhenting Qi
paper: [2408.06195v1 Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers](https://arxiv.org/abs/2408.06195v1)
code: zhentingqi/rStar
5. 总结 (结果先行)
rStar 提出了一种新颖且有效的框架,通过模拟人类的互洽推理过程,在不依赖外部监督或强教师模型的情况下,显著增强了小型语言模型的复杂推理能力。它巧妙地结合了 MCTS 的探索能力、更丰富的行动空间以及创新的互洽一致性验证机制,为提升 SLM 的"思考"质量提供了新的途径。
这项工作揭示了即便是参数量较小的模型,也蕴含着强大的潜能,关键在于如何设计有效的引导和验证策略来释放这些潜能。rStar 的成功为未来探索更高级的 SLM 自我进化和协作推理机制提供了有益的启示。后续研究可以进一步探索更高效的 MCTS 变体、更智能的行动选择策略,以及多模型协作推理的更多可能性。
1. 思想
论文提出了一种名为 rStar (Self-play muTuAl Reasoning) 的新方法,旨在提升小型语言模型 (SLMs) 在复杂推理任务上的性能,而无需 进行模型微调 或依赖更强大的 "教师"模型 。
思想源于对当前 SLM 自我提升方法瓶颈的察觉:
- 探索效率低下:SLMs 在广阔的解空间中进行自我探索时,往往容易陷入低质量推理步骤的循环,难以发现优质解。
- 评估能力不足:即使 SLMs 偶尔能生成高质量的推理步骤,它们自身也难以准确判断哪些步骤更优,或哪个最终答案是正确的,尤其在缺乏外部反馈时。
思想: rStar 通过一种自博弈 (self-play) 的互洽生成-判别 (mutual generation-discrimination) 过程来解耦和优化推理过程,模拟了人类在缺乏绝对权威指导时,通过同行评议或相互验证来增强结论可靠性的方式。简而言之,如果两个能力相当的"思考者"独立地(或基于部分相同前提)得出了相似的推理路径和结论,那么这个路径和结论更可信。
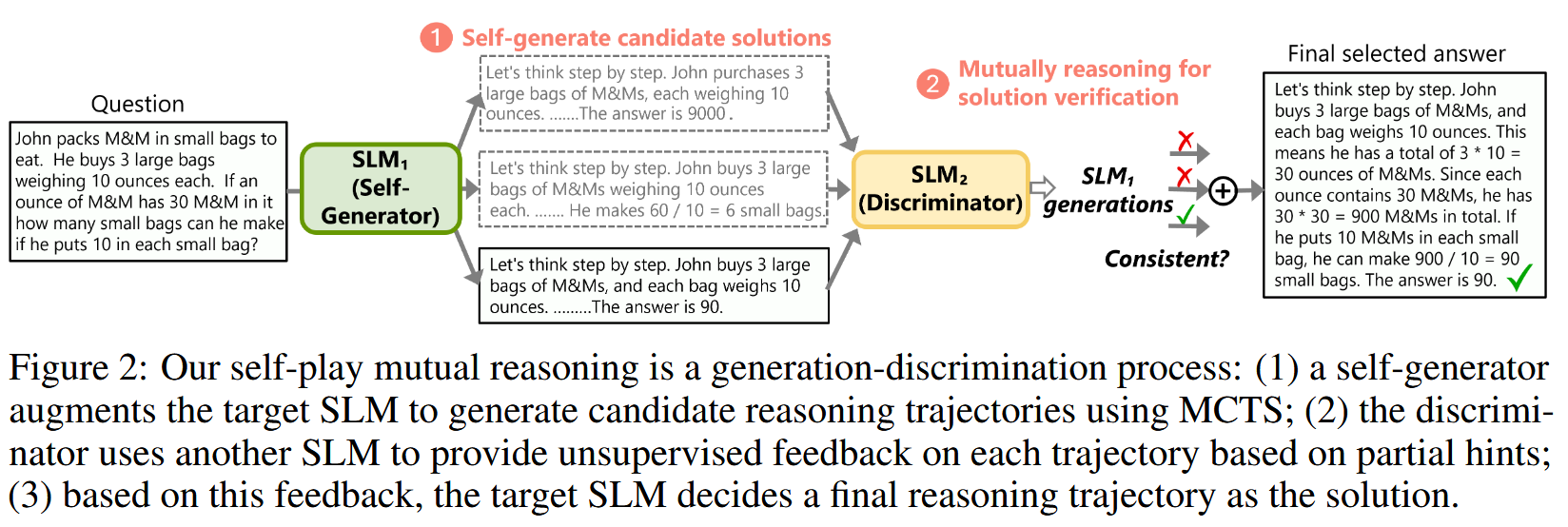
2. 方法详解
rStar 的工作流程可以概括为图2所示的三个主要步骤:
-
候选推理轨迹的自生成 (Self-Generator SLM₁ + MCTS):
-
目标:利用目标 SLM (记为 SLM₁) 生成多样化且高质量的候选推理轨迹。
-
机制:采用蒙特卡洛树搜索 (MCTS) 来指导 SLM₁ 的多步推理过程。MCTS 是一种启发式搜索算法,通过在决策空间中构建搜索树,并根据模拟结果(rollouts)来平衡探索(exploration)和利用(exploitation)。
-
增强的行动空间 (Action Space) :与传统 MCTS 方法通常只采用单一行动(如生成下一步或子问题)不同,rStar 为 SLM₁ 设计了一个更丰富的、模拟人类解题行为的行动集合 A = { A 1 , A 2 , A 3 , A 4 , A 5 } A = \{A_1, A_2, A_3, A_4, A_5\} A={A1,A2,A3,A4,A5}:
- A 1 A_1 A1: 提出单步思考 (Propose a one-step thought)。
- A 2 A_2 A2: 完成剩余思考步骤 (Complete remaining thought)。
- A 3 A_3 A3: 提出下一个子问题并回答 (Propose next sub-question & answer)。
- A 4 A_4 A4: 重新回答子问题 (Re-answer the sub-question),通常使用 few-shot CoT。
- A 5 A_5 A5: 重述问题/子问题 (Rephrase the question),旨在澄清理解。
这些行动使得 MCTS 搜索更具灵活性和针对性。
-
奖励函数 (Reward Function) Q ( s , a ) Q(s, a) Q(s,a) :对于一个节点 s s s(代表当前推理状态)和一个行动 a a a,其奖励值 Q ( s , a ) Q(s, a) Q(s,a) 的设计借鉴了 AlphaGo 的思想,即中间节点的价值取决于其对最终获得正确答案的贡献。
- 初始时,未探索节点的 Q ( s i , a i ) = 0 Q(s_i, a_i) = 0 Q(si,ai)=0。
- 当搜索到达一个叶节点 s d s_d sd (terminal node,代表一个完整的推理轨迹) 时,计算其奖励 Q ( s d , a d ) Q(s_d, a_d) Q(sd,ad)。该奖励基于自洽性 (self-consistency) 的多数投票结果的置信度。具体来说,通过多次采样生成最终答案,并以多数答案的出现频率作为置信度得分。
- 该叶节点奖励 Q ( s d , a d ) Q(s_d, a_d) Q(sd,ad) 会反向传播更新路径上所有父节点的奖励:对于路径 x → s 1 → ⋯ → s d x \rightarrow s_1 \rightarrow \dots \rightarrow s_d x→s1→⋯→sd 上的任意中间节点 s i s_i si 及其对应行动 a i a_i ai,奖励更新为 Q ( s i , a i ) ← Q ( s i , a i ) + Q ( s d , a d ) Q(s_i, a_i) \leftarrow Q(s_i, a_i) + Q(s_d, a_d) Q(si,ai)←Q(si,ai)+Q(sd,ad)。
-
MCTS 搜索与 UCT 选择 :在 MCTS 的选择阶段,rStar 使用标准的 UCT (Upper Confidence Bound 1 applied to Trees) 算法来选择下一个要扩展的节点:
U C T ( s , a ) = Q ( s , a ) N ( s , a ) + c ln N ( s p , a p ) N ( s , a ) UCT(s, a) = \frac{Q(s, a)}{N(s, a)} + c \sqrt{\frac{\ln N(s_p, a_p)}{N(s, a)}} UCT(s,a)=N(s,a)Q(s,a)+cN(s,a)lnN(sp,ap)其中:
- s s s:当前状态, s p s_p sp:当前状态的 parent 状态。
- Q ( s , a ) Q(s, a) Q(s,a) 是行动 a a a 在状态 s s s 下的估计价值(累积奖励)。
- N ( s , a ) N(s, a) N(s,a) 是边 ( s , a ) (s,a) (s,a) 被访问的次数。
- c c c 是一个探索常数,用于平衡利用和探索。
-
-
基于互洽一致性的解路径验证 (Discriminator SLM₂):
- 目标:对 SLM₁ 生成的候选推理轨迹进行有效筛选,找出更可靠的路径。
- 机制 :引入另一个能力与 SLM₁ 相当的 SLM (记为 SLM₂) 作为判别器。对于 SLM₁ 生成的每条候选轨迹 t = x ⊕ s 1 ⊕ s 2 ⊕ ⋯ ⊕ s d t = x \oplus s_1 \oplus s_2 \oplus \dots \oplus s_d t=x⊕s1⊕s2⊕⋯⊕sd(其中 x x x 是初始问题, s i s_i si 是第 i i i 个推理步骤, ⊕ \oplus ⊕ 代表连接),执行以下操作:
- 随机选择一个切分点 i < d i < d i<d,将轨迹分为前半部分 t p r e f i x = x ⊕ s 1 ⊕ ⋯ ⊕ s i − 1 t_{prefix} = x \oplus s_1 \oplus \dots \oplus s_{i-1} tprefix=x⊕s1⊕⋯⊕si−1 和后半部分 t s u f f i x = s i ⊕ ⋯ ⊕ s d t_{suffix} = s_i \oplus \dots \oplus s_d tsuffix=si⊕⋯⊕sd。
- 将 t p r e f i x t_{prefix} tprefix 作为提示 (prompt) 输入给 SLM₂ ,要求其补全剩余的推理步骤并给出最终答案。
- 比较 SLM₂ 补全得到的答案与原始轨迹 t t t 的答案。如果两者一致 ,则认为该轨迹 t t t 通过了互洽一致性 (mutual consistency)检验,被视为一个"有效轨迹 (validate trajectory)"。
- 原理:这种方法模拟了同行评审:如果另一个独立的思考者(SLM₂)在给定相同初始步骤的情况下,能够独立推导出相同的结论,那么这个结论的可靠性就更高。这为 SLM 提供了一种无需外部标注的反馈机制。
-
最终推理轨迹的选择 (SLM₁):
- 经过互洽一致性验证后,会得到一个有效轨迹集合。
- SLM₁ (作为主导者) 从这些有效轨迹中选择最终的解决方案。选择标准是结合 轨迹的原始奖励 (来自 MCTS 生成阶段的 Q Q Q 值)和 其在 MCTS rollout 过程中获得的终端节点置信度 得分。具体来说,可以将 MCTS 奖励 与自洽性投票的置信度相乘或以某种方式组合。
- 得分最高的有效轨迹被选为最终输出。
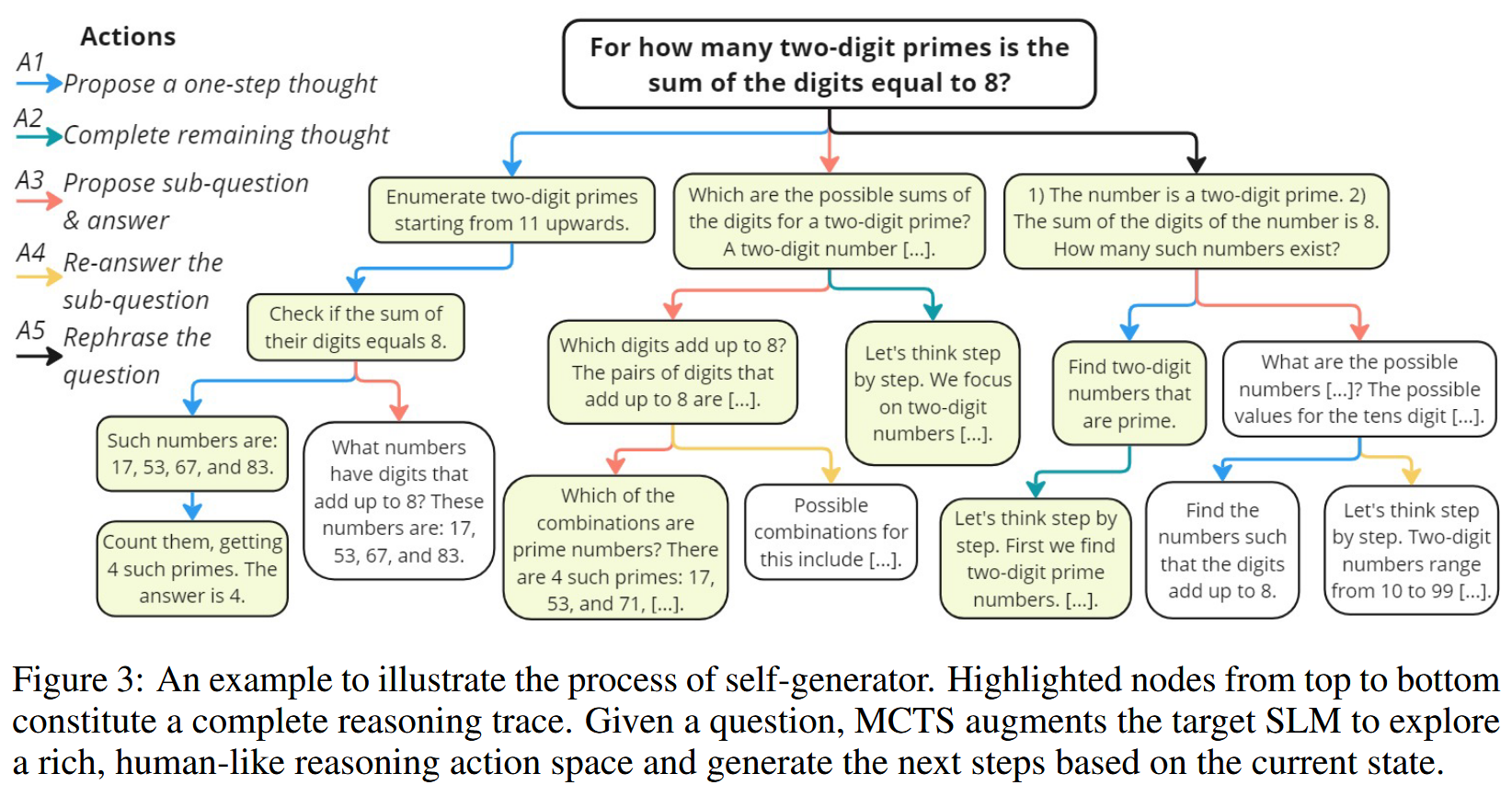
3. 优势
rStar 方法相较于现有技术,展现出以下显著优势:
- 无需微调或强教师模型:它在推理时增强 SLM 能力,不依赖额外的监督数据或更强大的模型进行知识蒸馏。
- 提升探索质量:通过 MCTS 和更丰富的行动空间,SLM 能够更有效地探索解空间,生成更高质量的候选推理步骤。
- 更可靠的验证机制:互洽一致性为 SLM 提供了一种比单纯的自评估(self-rewarding,在 SLM 中往往不可靠)更鲁棒的验证方式,有效避免了 SLM 因自身能力局限导致的评估偏差。
- 普适性强:实验证明 rStar 对多种不同的 SLMs(如 LLaMA2-7B, Mistral-7B, LLaMA3-8B)和多种推理任务(数学、常识推理)均有显著效果。
- 解决 SLM 自提升关键痛点:有效缓解了 SLM 在自我改进过程中面临的"探索难"和"评估难"两大核心问题。
- 避免过拟合风险:相较于训练奖励模型的方法,rStar 的互洽验证机制降低了对特定任务或数据集过拟合的风险。
4. 实验
论文通过在多个基准数据集和多种 SLM 上的大量实验来验证 rStar 的有效性。
-
实验设置:
- 模型:Phi3-mini (3.8B), LLaMA2-7B, Mistral-7B, LLaMA3-8B, LLaMA3-8B-Instruct。
- 数据集:GSM8K (数学), GSM-Hard (数学), MATH (数学竞赛), SVAMP (数学), StrategyQA (常识推理)。
- 对比基线:Few-shot CoT, Self-Consistency (SC@k), Tree-of-Thoughts (ToT), Reasoning via Planning (RAP)。
- rStar (generator@maj):表示仅使用 rStar 的生成器部分(MCTS)并采用多数投票进行答案验证,以展示生成器本身的效能。
- 判别器 SLM₂:通常使用 Phi3-mini-4k,即使目标 SLM₁ 是更大的模型。
-
主要发现 :
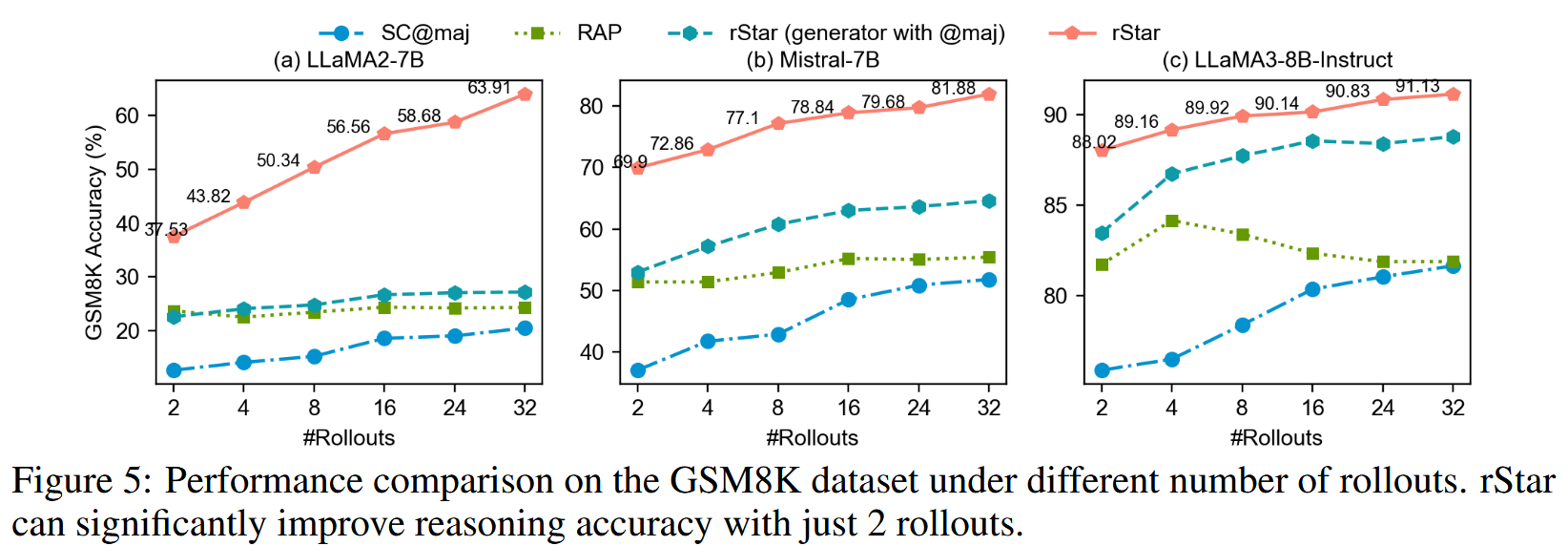
- 显著性能提升 :rStar 在所有测试的 SLM 和数据集上均取得了SOTA或接近SOTA 的性能。:
- LLaMA2-7B:从 Few-shot CoT 的 12.51% 提升至 rStar 的 63.91%。
- Mistral-7B:从 Few-shot CoT 的 36.46% 提升至 rStar 的 81.88% (甚至超过了微调的 MetaMath 77.7%)。
- LLaMA3-8B-Instruct:从 Few-shot CoT 的 74.53% 提升至 rStar 的 91.13%。
- 生成器与判别器的协同作用 :
rStar (generator@maj)的结果表明,仅 MCTS 生成器部分就能比 RAP 等基线方法产生更好的候选集。- 完整的 rStar (包含判别器) 进一步大幅提升准确率,显示了互洽一致性验证的强大作用。
- 对挑战性数据集的有效性:在 GSM-Hard 和 MATH-500 等更难的数据集上,rStar 同样展现出比基线方法更强的性能。
- 丰富的行动空间至关重要 :消融实验表明,包含全部5种行动的 rStar 比仅使用部分行动(如 RAP 仅用 A 3 A_3 A3)效果更好。
- 判别器模型选择的鲁棒性:即使使用相对较小的 Phi3-Mini 作为判别器,也能有效提升 LLaMA3-8B-Instruct 的性能,使用更强的 GPT-4 作为判别器带来的提升有限,证明了互洽机制的有效性而非依赖判别器本身的强大。
- 少量 Rollouts 即有效:即使 MCTS 的 rollout 次数较少(如2次),rStar 也能显著提升性能,并在更多 rollouts 时持续受益。
- 显著性能提升 :rStar 在所有测试的 SLM 和数据集上均取得了SOTA或接近SOTA 的性能。: