在视觉定位应用中,选择了基于Aruco码的ChAruco(【ChArUco Marker】标定板检测)和ArucoBoard(【ArUco boards】标定板检测)两种标记,即使用的是2D相机,根据PNP算法也可以得到深度信息,核心是通过cv::solvePnP函数实现。
solvePnP
- 1.函数源代码
-
- [1.1 输入输出参数说明](#1.1 输入输出参数说明)
- [1.2 注意事项:](#1.2 注意事项:)
- 2.在ChAruco和ArucoBoard中的使用
-
- [2.1 背景说明](#2.1 背景说明)
- [2.2 原理概述](#2.2 原理概述)
- [2.3 关于迭代法(SOLVEPNP_ITERATIVE)](#2.3 关于迭代法(SOLVEPNP_ITERATIVE))
solvePnP 是 OpenCV 库中的一个重要函数,主要用于解决 Perspective-n-Point(PnP)问题。所谓 PnP 问题,就是在已知 3D 物体点坐标以及它们在图像中对应 2D 投影点的情况下,求解相机的位姿,也就是相机的旋转和平移参数。该函数在计算机视觉领域用途广泛,像增强现实、相机标定、机器人导航等场景都会用到它。
1.函数源代码
- 以opencv-4.10.0 版本为例,
opencv-4.10.0\include\opencv4\opencv2\calib3d.hpp
cpp
/** @example samples/cpp/tutorial_code/features2D/Homography/homography_from_camera_displacement.cpp
An example program about homography from the camera displacement
Check @ref tutorial_homography "the corresponding tutorial" for more details
*/
/** @brief Finds an object pose from 3D-2D point correspondences.
@see @ref calib3d_solvePnP
This function returns the rotation and the translation vectors that transform a 3D point expressed in the object
coordinate frame to the camera coordinate frame, using different methods:
- P3P methods (@ref SOLVEPNP_P3P, @ref SOLVEPNP_AP3P): need 4 input points to return a unique solution.
- @ref SOLVEPNP_IPPE Input points must be >= 4 and object points must be coplanar.
- @ref SOLVEPNP_IPPE_SQUARE Special case suitable for marker pose estimation.
Number of input points must be 4. Object points must be defined in the following order:
- point 0: [-squareLength / 2, squareLength / 2, 0]
- point 1: [ squareLength / 2, squareLength / 2, 0]
- point 2: [ squareLength / 2, -squareLength / 2, 0]
- point 3: [-squareLength / 2, -squareLength / 2, 0]
- for all the other flags, number of input points must be >= 4 and object points can be in any configuration.
@param objectPoints Array of object points in the object coordinate space, Nx3 1-channel or
1xN/Nx1 3-channel, where N is the number of points. vector\<Point3d\> can be also passed here.
@param imagePoints Array of corresponding image points, Nx2 1-channel or 1xN/Nx1 2-channel,
where N is the number of points. vector\<Point2d\> can be also passed here.
@param cameraMatrix Input camera intrinsic matrix \f$\cameramatrix{A}\f$ .
@param distCoeffs Input vector of distortion coefficients
\f$\distcoeffs\f$. If the vector is NULL/empty, the zero distortion coefficients are
assumed.
@param rvec Output rotation vector (see @ref Rodrigues ) that, together with tvec, brings points from
the model coordinate system to the camera coordinate system.
@param tvec Output translation vector.
@param useExtrinsicGuess Parameter used for #SOLVEPNP_ITERATIVE. If true (1), the function uses
the provided rvec and tvec values as initial approximations of the rotation and translation
vectors, respectively, and further optimizes them.
@param flags Method for solving a PnP problem: see @ref calib3d_solvePnP_flags
More information about Perspective-n-Points is described in @ref calib3d_solvePnP
@note
- An example of how to use solvePnP for planar augmented reality can be found at
opencv_source_code/samples/python/plane_ar.py
- If you are using Python:
- Numpy array slices won't work as input because solvePnP requires contiguous
arrays (enforced by the assertion using cv::Mat::checkVector() around line 55 of
modules/calib3d/src/solvepnp.cpp version 2.4.9)
- The P3P algorithm requires image points to be in an array of shape (N,1,2) due
to its calling of #undistortPoints (around line 75 of modules/calib3d/src/solvepnp.cpp version 2.4.9)
which requires 2-channel information.
- Thus, given some data D = np.array(...) where D.shape = (N,M), in order to use a subset of
it as, e.g., imagePoints, one must effectively copy it into a new array: imagePoints =
np.ascontiguousarray(D[:,:2]).reshape((N,1,2))
- The methods @ref SOLVEPNP_DLS and @ref SOLVEPNP_UPNP cannot be used as the current implementations are
unstable and sometimes give completely wrong results. If you pass one of these two
flags, @ref SOLVEPNP_EPNP method will be used instead.
- The minimum number of points is 4 in the general case. In the case of @ref SOLVEPNP_P3P and @ref SOLVEPNP_AP3P
methods, it is required to use exactly 4 points (the first 3 points are used to estimate all the solutions
of the P3P problem, the last one is used to retain the best solution that minimizes the reprojection error).
- With @ref SOLVEPNP_ITERATIVE method and `useExtrinsicGuess=true`, the minimum number of points is 3 (3 points
are sufficient to compute a pose but there are up to 4 solutions). The initial solution should be close to the
global solution to converge.
- With @ref SOLVEPNP_IPPE input points must be >= 4 and object points must be coplanar.
- With @ref SOLVEPNP_IPPE_SQUARE this is a special case suitable for marker pose estimation.
Number of input points must be 4. Object points must be defined in the following order:
- point 0: [-squareLength / 2, squareLength / 2, 0]
- point 1: [ squareLength / 2, squareLength / 2, 0]
- point 2: [ squareLength / 2, -squareLength / 2, 0]
- point 3: [-squareLength / 2, -squareLength / 2, 0]
- With @ref SOLVEPNP_SQPNP input points must be >= 3
*/
CV_EXPORTS_W bool solvePnP( InputArray objectPoints, InputArray imagePoints,
InputArray cameraMatrix, InputArray distCoeffs,
OutputArray rvec, OutputArray tvec,
bool useExtrinsicGuess = false, int flags = SOLVEPNP_ITERATIVE );1.1 输入输出参数说明
-
函数的各个输入参数:
- objectPoints[in]:输入数组,存放的是物体在自身坐标系下的 3D 点坐标(物体坐标系下)
- imagePoints[in]:输入数组,存储的是与 objectPoints 相对应的图像中的 2D 点坐标(像素坐标系下)
- cameraMatrix[in]:相机内参矩阵
- distCoeffs[in]:相机畸变系数向量 \f,当传入 NULL 或者空向量时,就会默认使用零畸变系数
- rvec[out]:是输出的旋转向量,要借助罗德里格斯公式(Rodrigues)将其转换为旋转矩阵。这个向量和 tvec 一起,能把点从模型坐标系转换到相机坐标系
- tvec[out]:为输出的平移向量
- useExtrinsicGuess[in]:缺省参数,用于 SOLVEPNP_ITERATIVE 方法的参数。若设为 true,函数就会把传入的 rvec 和 tvec 分别作为旋转向量和平移向量的初始近似值,然后再进一步对它们进行优化。
- flags[in]:缺省参数,表示求解 PnP 问题的方法,可参考 @ref calib3d_solvePnP_flags
-
函数支持多种求解方法,不同方法有不同的要求:
P3P 方法(SOLVEPNP_P3P、SOLVEPNP_AP3P):需要 4 个输入点才能得到唯一解。
SOLVEPNP_IPPE:输入点的数量要大于等于 4,并且物体点必须共面。
SOLVEPNP_IPPE_SQUARE:这是适用于标记物位姿估计的特殊情况,输入点数量必须为 4,物体点的定义顺序有严格要求:
点 0:[-squareLength / 2, squareLength / 2, 0]
点 1:[squareLength / 2, squareLength / 2, 0]
点 2:[squareLength / 2, -squareLength / 2, 0]
点 3:[-squareLength / 2, -squareLength / 2, 0]
其他方法:输入点数量要大于等于 4,物体点可以是任意构型。
1.2 注意事项:
- 在使用某些方法时,对输入点的数量和构型有特定要求,使用前要确认是否满足条件。
- 当使用
SOLVEPNP_ITERATIVE方法且useExtrinsicGuess=true时,至少需要 3 个点,但初始解要接近全局解才能保证收敛。 SOLVEPNP_DLS和SOLVEPNP_UPNP这两种方法当前的实现不稳定,可能会给出错误结果,若传入这两个标志,会改用SOLVEPNP_EPNP方法。
2.在ChAruco和ArucoBoard中的使用
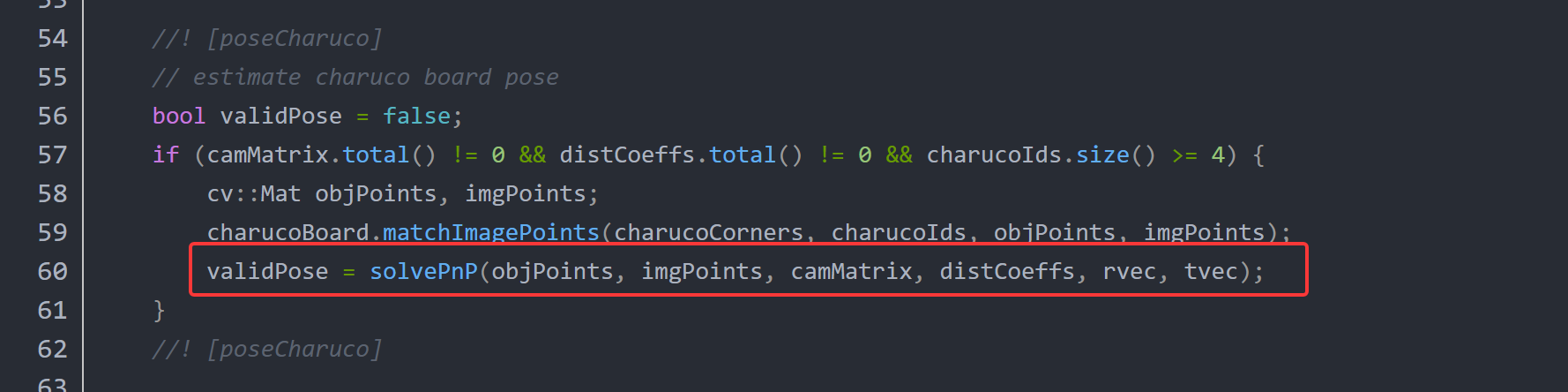
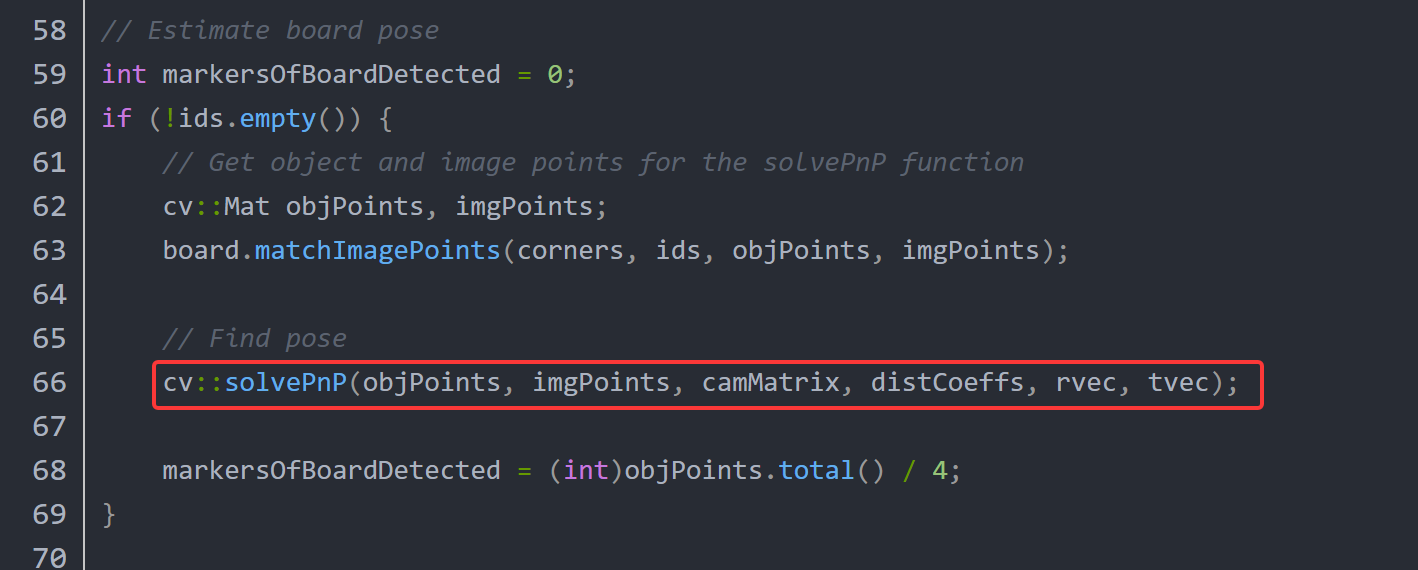
上面两种标记调用solvePnP函数时,都没有给useExtrinsicGuess和flags传递参数,它们会采用默认值:
- useExtrinsicGuess:它的默认值为false,意味着在求解 PnP 问题时,函数不会使用外部提供的初始值。也就是说,函数会自行寻找旋转向量(rvec)和平移向量(tvec)的初始估计值,而不会依赖用户传入的初始猜测值。
- flags :默认值是
SOLVEPNP_ITERATIVE。这表明函数会运用迭代方法来求解 PnP 问题。该方法是一种非线性优化方法,它的工作原理是最小化 3D 点经过投影后的重投影误差,但这种方法至少需要 4 个点才能得到稳定的解。
这种默认配置在实际应用中很常见,适用于大多数不需要初始猜测值的场景,它能为各种物体构型提供比较稳定的解,但如果物体点是共面的,使用SOLVEPNP_EPNP 可能会更合适;要是处理的是方形标记物,那么SOLVEPNP_IPPE_SQUARE会是更好的选择。
2.1 背景说明
上面两种标记调用solvePnP函数时,输入参数objPoints和imgPoints分别表示:
- objPoints :表示每个标记(如 ArUco 标记或 Charuco 角点)在世界坐标系中的 3D 坐标,因为每个标记的图案在检测之前都有预设值,即每个标记中的任何一个aruco的实际物理坐标都事先知道。
std::vector<cv::Point3f> - imgPoints :表示检测到的标记如角点在图像中的 2D 像素坐标。
std::vector<cv::Point2f>
2.2 原理概述
这里我们将solvePnP算法应用于aruco标记的位姿估计中,实际我们使用的是2D工业相机,拍摄了多组标记如Charuco或者ArucoBoard,这些标记都是已知实际物理尺寸的,所以标记上的每个aruco相对于标记原点即物体坐标系的3D坐标都是已知的,记为T_point_to_tag;根据拍摄的图像通过模板匹配或角点检测算法都可以已知图像中每个aruco的像素坐标。最终我们需要求得的是相机的外参,即标记相对于相机坐标系的位姿关系,记为T_tag_to_cam。
算法步骤:
- 1.刚体变换 :这里假设
T_tag_to_cam是已知的,将标记中每个aruco的位姿从基于物体坐标系的(这里的物体坐标系指的是如charuco标记上面的原点坐标系),转换到基于相机坐标系中; - 2.透视投影 :将相机坐标系下的 3D 点投影到归一化图像平面,即
T_point_to_cam; - 3.畸变校正 (若存在畸变):因为我们已知
相机畸变系数,可以进行畸变校正; - 4.内参变换 :(在https://blog.csdn.net/qq_45445740/article/details/142931046博文中介绍了如何将2D像素坐标转换为3D实际坐标,这里我们将过程反过来,将3D实际坐标转换为2D像素坐标点);
- 5.重投影误差:每张图像中标记的每个aruco像素坐标通过识别检测都能知道其像素坐标,上一步中又求得到了实际aruco点转换过来的像素坐标点,两个值之间存在差值即误差;
- 6.迭代优化求解相机外参数:核心是通过迭代优化求解相机外参数(旋转向量 rvec 和平移向量 tvec),使得 3D 物体点到 2D 图像点的重投影误差最小化。

2.3 关于迭代法(SOLVEPNP_ITERATIVE)
PS:这部分我还没理解,知识瓶颈了属实是,先去补点基础回头再看,先把参考的资料放下面。

