一、写在前面
前段时间找公司订购质粒,又遇到一个实际问题:
我把目的蛋白的氨基酸序列发给公司,公司评估后,发送核酸序列让我核对。以前是有专门的小工具用于"核酸序列与氨基酸序列"相互转化,但是我没保存,找了许久没找到,然后顺手打开了DeepSeek。
这是氨基酸序列:
PCBP1蛋白的WT质粒和K115R突变质粒(也就是第115个的氨基酸K突变成R)

这是要核对的核酸序列:

借此机会,我们继续来测试DeepSeek-R1能否来解决这个实际问题?
二、序列核对
这回输入DeepSeek-R1、DeepSeek-V3、Kimi-1.5以及G老师们。
(1)咒语
请核对附件1中的核酸序列跟附件2中的氨基酸序列是否一致。
记得传附件。
(2)DeepSeek-V3 关闭深度思考(R1)模式 无联网
最终答案:
文档1中的核酸序列与文档2中的氨基酸序列一致。核酸序列正确翻译为对应的氨基酸序列,且K115R突变在核酸和氨基酸层面均正确体现。

(2)DeepSeek-R1 打开深度思考(R1)模式 无联网
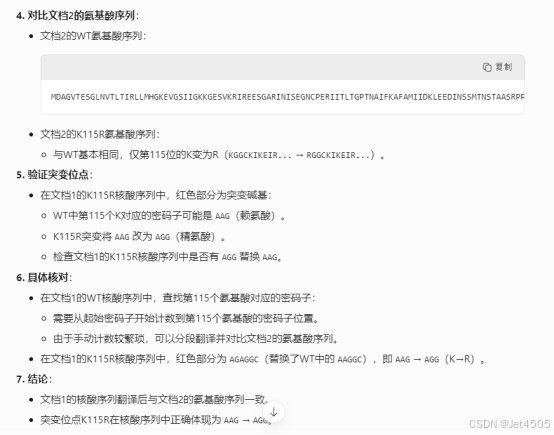
经过漫长的思考(足足在559秒),都思考到双语版本了:

终于得出结果:
一致:附件1中的核酸序列与附件2中的氨基酸序列完全一致。
对于野生型(WT),附件1的核酸序列正确编码了附件2的PCBP1氨基酸序列,包括全长331个氨基酸和突变点(第115位K)。
对于K115R突变型,附件1的核酸序列(AGA)正确编码了附件2的突变氨基酸序列(第115位R),且其余序列一致。
(3)Kimi - 关闭长思考模式 无联网
结论
文件1中的核酸序列与文件2中的氨基酸序列不一致。可能是文件1中的核酸序列不完整或存在错误。建议重新检查核酸序列的完整性和准确性。
宣告失败。
然后我打开Kimi的深度思考模式,他又行了(而且思考时间很短):
经过核对,附件1中的核酸序列与附件2中的氨基酸序列的转译是一致的。

(4)ChatGPT -4o
几乎瞬间出结论:
附件1中的核酸序列与附件2中的氨基酸序列完全对应,翻译准确,无遗漏或移码错误。K115R突变也已正确反映。

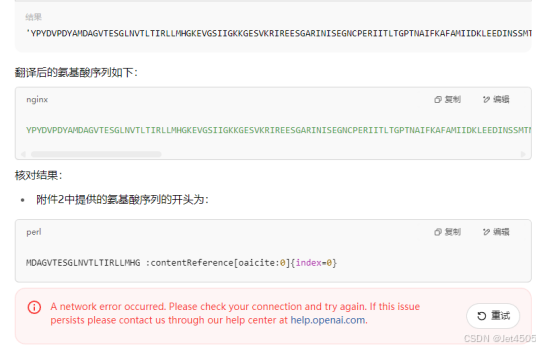
(4)ChatGPT -4.5
调用了Python,然后就死循环了。
(5)ChatGPT -4.1
也是瞬间出:
附件1中的核酸序列与附件2中的氨基酸序列完全对应、一致。
野生型核酸序列翻译得到的氨基酸序列与附件2提供的氨基酸序列一致。
K115R突变型核酸序列的翻译结果,与附件2中K115R的氨基酸序列仅在115位为R,完全对应。
两份文件的内容相互校对无误 。


五、 写在最后
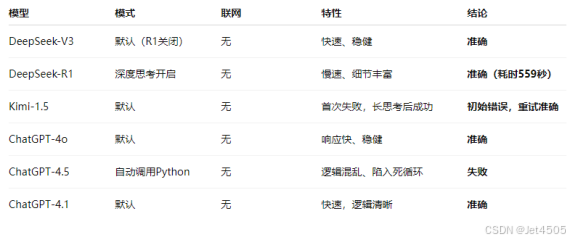
(1)共测试6种配置,涵盖主流多模态大模型:
(2)随谈一下:
ChatGPT-4o、4.1、DeepSeek-V3在无深度思考的默认配置下即可准确判断突变是否正确体现,说明当前主流模型已具备较高的生物序列理解和翻译能力。
ChatGPT-4.5自动调用Python却未能完成任务,反而陷入死循环,说明某些高级功能(如代码执行)在复杂结构或非预期输入下可能失效。
DeepSeek-R1的"深度思考"提供了详细推理路径和双语输出,适合对结果不确定时的验证,但代价是响应时间非常长(近10分钟),难以满足实时需求。
默认快速模式(如4o和V3)虽无详细过程说明,但在常规任务中表现更优,具备更高的实用性与效率。
综上,通用大模型和推理大模型各有所长,需要根据具体任务灵活切换。