一、全文搜索
全文搜索是一种通过匹配文本中特定关键词或短语来检索文档的传统方法。它根据词频等因素计算出的相关性分数对结果进行排序。语义搜索更善于理解含义和上下文,而全文搜索则擅长精确的关键词匹配,因此是语义搜索的有益补充。BM25 算法被广泛用于全文搜索的排序,并在检索增强生成(RAG)中发挥着关键作用。
Milvus 2.5 引入了使用 BM25 的本地全文搜索功能。这种方法将文本转换为代表 BM25 分数的稀疏向量。我们只需输入原始文本,Milvus 就会自动生成并存储稀疏向量,无需手动生成稀疏嵌入。
LangChain 与 Milvus 的集成也引入了这一功能,简化了将全文检索纳入 RAG 应用程序的过程。通过将全文搜索与密集向量的语义搜索相结合,可以实现一种混合方法,既能利用密集嵌入的语义上下文,又能利用单词匹配的精确关键词相关性。这种整合提高了搜索系统的准确性、相关性和用户体验。
本文将展示如何使用 LangChain 和 Milvus 在应用程序中实现 全文搜索。
二、前提条件
1、依赖安装
bash
pip install --upgrade --quiet langchain langchain-core langchain-community langchain-text-splitters langchain-milvus langchain-openai pymilvus[model]2、OPENAI API 服务
这里需要用到嵌入模型 bge-m3,当然也可以使用其他模型,最简单的方法就是申请 OPENAI_API_KEY 或者在国内大模型服务平台申请一个,例如硅基流动、阿里云百炼、火山引擎等,如果有硬件条件可以使用 Ollama 或者 vLLM 本地部署。
python
import os
# 设置环境变量
os.environ["OPENAI_BASE_URL"] = "http://localhost:8000/v1"
os.environ["OPENAI_API_KEY"] = "EMPTY"3、Milvus 服务器
使用本地服务器或者云服务器,都可以。
python
URI = "http://localhost:19530"4、数据准备
准备一些示例文档,即按主题或流派分类的虚构故事摘要。
python
from langchain_core.documents import Document
docs = [
Document(page_content="I like this apple", metadata={"category": "fruit"}),
Document(page_content="I like swimming", metadata={"category": "sport"}),
Document(page_content="I like dogs", metadata={"category": "pets"}),
]三、使用 BM25 函数初始化
1、混合搜索
对于全文检索,Milvus VectorStore 接受一个 builtin_function 参数。通过该参数,可以传入 BM25BuiltInFunction 的实例。这与语义搜索不同,语义搜索通常将密集嵌入传入 VectorStore 。
下面是一个在 Milvus 中使用 OpenAI dense embedding 进行语义搜索和 BM25 进行全文搜索的混合搜索的简单示例:
python
from langchain_milvus import Milvus, BM25BuiltInFunction
from langchain_openai import OpenAIEmbeddings
vectorstore = Milvus.from_documents(
documents=docs,
embedding=OpenAIEmbeddings(model="BAAI/bge-m3),
builtin_function=BM25BuiltInFunction(),
# `dense` is for OpenAI embeddings, `sparse` is the output field of BM25 function
vector_field=["dense", "sparse"],
connection_args={
"uri": URI,
...
},
drop_old=False,
)在上面的代码中,我们定义了 BM25BuiltInFunction 的一个实例,并将其传递给 Milvus 对象。BM25BuiltInFunction 是一个轻量级的封装类,Function 的轻量级封装类。
我们可以在 BM25BuiltInFunction 的参数中指定该函数的输入和输出字段:
- input_field_names (str):输入字段的名称,默认为 text。它表示此函数读取哪个字段作为输入。
- output_field_names (str):输出字段的名称,默认为 sparse。它表示此函数将计算结果输出到哪个字段。
请注意,在上述 Milvus 初始化参数中,我们也指定了 vector_field=["dense", "sparse"] 。由于 sparse 字段被当作由BM25BuiltInFunction 定义的输出字段,因此其他 dense 字段将被自动分配给 OpenAIEmbeddings 的输出字段。
在实践中,尤其是在组合多个 Embeddings 或函数时,建议明确指定每个函数的输入和输出字段,以避免歧义。
在下面的示例中,我们明确指定了 BM25BuiltInFunction 的输入字段和输出字段,从而清楚地说明了内置函数用于哪个字段。
python
# from langchain_voyageai import VoyageAIEmbeddings
embedding1 = OpenAIEmbeddings(model="text-embedding-ada-002")
embedding2 = OpenAIEmbeddings(model="text-embedding-3-large")
# embedding2 = VoyageAIEmbeddings(model="voyage-3") # You can also use embedding from other embedding model providers, e.g VoyageAIEmbeddings
vectorstore = Milvus.from_documents(
documents=docs,
embedding=[embedding1, embedding2],
builtin_function=BM25BuiltInFunction(
input_field_names="text", output_field_names="sparse"
),
text_field="text", # `text` is the input field name of BM25BuiltInFunction
# `sparse` is the output field name of BM25BuiltInFunction, and `dense1` and `dense2` are the output field names of embedding1 and embedding2
vector_field=["dense1", "dense2", "sparse"],
connection_args={
"uri": URI,
},
drop_old=False,
)
vectorstore.vector_fields['dense1', 'dense2', 'sparse']在这个示例中,我们有三个向量字段。其中,sparse 作为 BM25BuiltInFunction 的输出字段,而其他两个字段 dense1 和dense2 则被自动指定为两个 OpenAIEmbeddings 模型的输出字段(根据顺序)。
这样,就可以定义多个向量场,并为其分配不同的嵌入或函数组合,从而实现混合搜索。
执行混合搜索时,我们只需传入查询文本,并选择性地设置 topK 和 Reranker 参数。vectorstore 实例会自动处理向量嵌入和内置函数,最后使用 Reranker 对结果进行细化。搜索过程的底层实现细节对用户是隐藏的。
python
vectorstore.similarity_search(
"Do I like apples?", k=1
) # , ranker_type="weighted", ranker_params={"weights":[0.3, 0.3, 0.4]})[Document(metadata={'category': 'fruit', 'pk': 454646931479251897}, page_content='I like this apple')]2、无嵌入的 BM25 搜索
如果只想使用 BM25 函数执行全文搜索,而不想使用任何基于嵌入的语义搜索,可以将嵌入参数设置为 None ,并只保留指定为 BM25 函数实例的 builtin_function ,向量字段只有 "稀疏 "字段。
python
vectorstore = Milvus.from_documents(
documents=docs,
embedding=None,
builtin_function=BM25BuiltInFunction(
output_field_names="sparse",
),
vector_field="sparse",
connection_args={
"uri": URI,
},
drop_old=False,
)
vectorstore.vector_fields['sparse']四、自定义分析器
分析器在全文检索中至关重要,它可以将句子分解成词块,并执行词法分析,如词干分析和停止词删除。
分析器通常针对特定语言。
Milvus 支持两种类型的分析器:内置分析器和自定义分析器。默认情况下,BM25BuiltInFunction 将使用标准的内置分析器,这是最基本的分析器,会用标点符号标记文本。
如果想使用其他分析器或自定义分析器,可以在 BM25BuiltInFunction 初始化时传递analyzer_params 参数。
python
analyzer_params_custom = {
"tokenizer": "standard",
"filter": [
"lowercase", # Built-in filter
{"type": "length", "max": 40}, # Custom filter
{"type": "stop", "stop_words": ["of", "to"]}, # Custom filter
],
}
vectorstore = Milvus.from_documents(
documents=docs,
embedding=OpenAIEmbeddings(),
builtin_function=BM25BuiltInFunction(
output_field_names="sparse",
enable_match=True,
analyzer_params=analyzer_params_custom,
),
vector_field=["dense", "sparse"],
connection_args={
"uri": URI,
},
drop_old=False,
)我们可以看看 Milvus Collections 的 Schema,确保定制的分析器设置正确。
python
vectorstore.col.schema{'auto_id': True, 'description': '', 'fields': [{'name': 'text', 'description': '', 'type': <DataType.VARCHAR: 21>, 'params': {'max_length': 65535, 'enable_match': True, 'enable_analyzer': True, 'analyzer_params': {'tokenizer': 'standard', 'filter': ['lowercase', {'type': 'length', 'max': 40}, {'type': 'stop', 'stop_words': ['of', 'to']}]}}}, {'name': 'pk', 'description': '', 'type': <DataType.INT64: 5>, 'is_primary': True, 'auto_id': True}, {'name': 'dense', 'description': '', 'type': <DataType.FLOAT_VECTOR: 101>, 'params': {'dim': 1536}}, {'name': 'sparse', 'description': '', 'type': <DataType.SPARSE_FLOAT_VECTOR: 104>, 'is_function_output': True}, {'name': 'category', 'description': '', 'type': <DataType.VARCHAR: 21>, 'params': {'max_length': 65535}}], 'enable_dynamic_field': False, 'functions': [{'name': 'bm25_function_de368e79', 'description': '', 'type': <FunctionType.BM25: 1>, 'input_field_names': ['text'], 'output_field_names': ['sparse'], 'params': {}}]}五、在 RAG 中使用混合搜索
我们已经学习了如何在 LangChain 和 Milvus 中使用基本的 BM25 内置函数,接下来我们结合混合搜索来实现一个 RAG 例子。
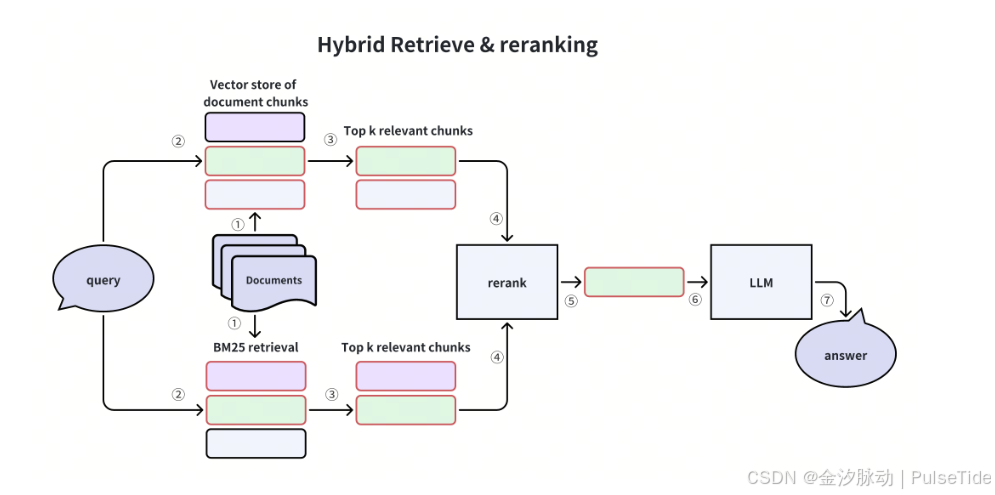
该图显示了混合检索和重排过程,将用于关键词匹配的 BM25 和用于语义检索的向量搜索结合在一起。来自两种方法的结果经过合并、Rerankers 和传递给 LLM 生成最终答案。
混合搜索兼顾了精确性和语义理解,提高了不同查询的准确性和稳健性。它通过 BM25 全文检索和向量搜索检索候选内容,同时确保语义、上下文感知和精确检索。
1、准备数据
我们使用 PyPDFLoader 加载 PDF 文档,并使用 RecursiveCharacterTextSplitter 将文档分割成块。
python
from langchain_community.document_loaders import PyPDFLoader
file_path = "data/0001.pdf"
loader = PyPDFLoader(file_path)
docs = loader.load()
print(f"文档页数:{len(docs)} 页")文档页数:2 页
python
# 页面的字符串内容
print(f"{docs[0].page_content[:200]}\n")
# 包含文件名和页码的元数据
print(docs[0].metadata)标题:意大利面与 42 号混凝土混合对挖掘机扭矩和环境稳定性的跨学科影响分析:剑桥大学研究
报告
摘要:
本研究报告深入研究了烹饪制品和建筑材料的融合,特别调查了将意大利面与 42 号混凝土混合对
挖掘机扭矩效率的潜在影响。 令人惊讶的是,螺丝长度、高能蛋白质、核污染、核扩散、三角函
数和地缘政治人物之间的相互作用成为一个重要的研究点。 通过利用毕达哥拉斯定理和历史类比
进行细致的检查,该研究阐明
{'producer': 'LibreOffice 24.2', 'creator': 'Writer', 'creationdate': '2025-05-29T15:22:12+08:00', 'source': 'data/0001.pdf', 'total_pages': 2, 'page': 0, 'page_label': '1'}
python
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=100, add_start_index=True
)
all_splits = text_splitter.split_documents(docs)
len(all_splits)42、将文档加载到 Milvus 向量存储中
如果数据库 milvus_demo 已经储存了其他类型的数据,测试时可以设置 drop_old=True 清掉
python
vectorstore = Milvus.from_documents(
documents=all_splits,
embedding=OpenAIEmbeddings(model="BAAI/bge-m3"),
builtin_function=BM25BuiltInFunction(),
vector_field=["dense", "sparse"],
connection_args={
"uri": URI,
"token": "root:Milvus",
"db_name": "milvus_demo"
},
consistency_level="Strong", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/consistency.md#Consistency-Level for more details.
drop_old=False,
)2025-06-16 14:24:36,268 [DEBUG][_create_connection]: Created new connection using: 5490932c80494891865d6e46857b5cf2 (async_milvus_client.py:599)3、构建 RAG 链
我们准备好 LLM 实例和提示,然后使用 LangChain 表达式语言将它们结合到 RAG 管道中。
python
from langchain_openai import ChatOpenAI
import os
os.environ["DASHSCOPE_API_KEY"] = "sk-xxx"
# Initialize the OpenAI language model for response generation
llm = ChatOpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen-plus", # 此处以qwen-plus为例,您可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
# other params...
)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁?"}]
response = llm.invoke(messages)
print(response.json()){"content":"我是通义千问,阿里巴巴集团旗下的超大规模语言模型。我能够回答问题、创作文字,如写故事、公文、邮件、剧本等,还能进行逻辑推理、编程等任务。如果你有任何问题或需要帮助,欢迎随时告诉我!","additional_kwargs":{"refusal":null},"response_metadata":{"token_usage":{"completion_tokens":54,"prompt_tokens":22,"total_tokens":76,"completion_tokens_details":null,"prompt_tokens_details":{"audio_tokens":null,"cached_tokens":0}},"model_name":"qwen-plus","system_fingerprint":null,"id":"chatcmpl-a5a8e18e-efbd-9c10-85bb-30dfe7242854","service_tier":null,"finish_reason":"stop","logprobs":null},"type":"ai","name":null,"id":"run--c570416c-b01f-493a-9d87-778a44f93ddf-0","example":false,"tool_calls":[],"invalid_tool_calls":[],"usage_metadata":{"input_tokens":22,"output_tokens":54,"total_tokens":76,"input_token_details":{"cache_read":0},"output_token_details":{}}}
/tmp/ipykernel_4268/4214353893.py:17: PydanticDeprecatedSince20: The `json` method is deprecated; use `model_dump_json` instead. Deprecated in Pydantic V2.0 to be removed in V3.0. See Pydantic V2 Migration Guide at https://errors.pydantic.dev/2.11/migration/
print(response.json())
python
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
# Define the prompt template for generating AI responses
PROMPT_TEMPLATE = """
Human: You are an AI assistant, and provides answers to questions by using fact based and statistical information when possible.
Use the following pieces of information to provide a concise answer to the question enclosed in <question> tags.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
<context>
{context}
</context>
<question>
{question}
</question>
The response should be specific and use statistics or numbers when possible.
Assistant:"""
# Create a PromptTemplate instance with the defined template and input variables
prompt = PromptTemplate(
template=PROMPT_TEMPLATE, input_variables=["context", "question"]
)
# Convert the vector store to a retriever
retriever = vectorstore.as_retriever()
# Define a function to format the retrieved documents
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)使用 LCEL(LangChain 表达式语言)构建 RAG 链。
python
# Define the RAG (Retrieval-Augmented Generation) chain for AI response generation
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
python
# LangGraph 还附带内置实用程序,用于可视化您应用程序的控制流
from IPython.display import Image, display
display(Image(rag_chain.get_graph().draw_mermaid_png()))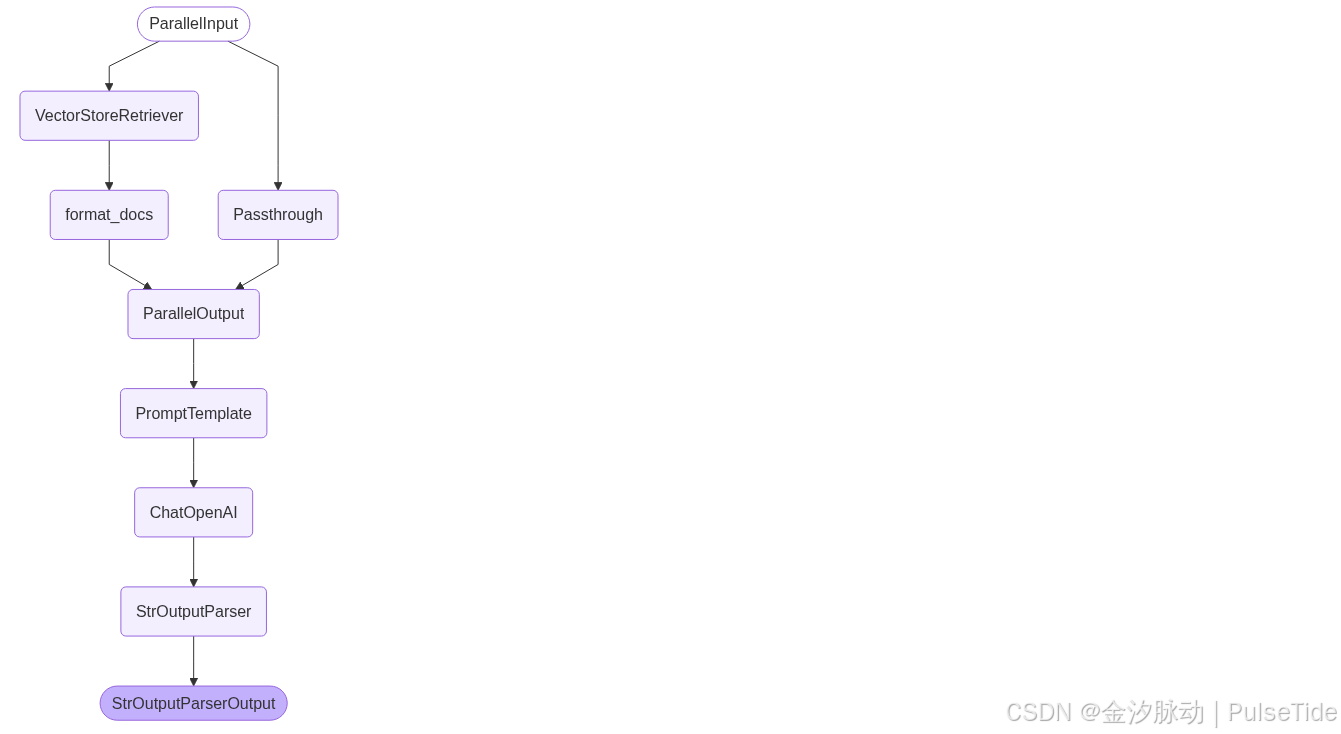
使用特定问题调用 RAG 链并获取响应:
python
query = "如何理解混凝土拌意大利面?"
res = rag_chain.invoke(query)
res'根据研究报告《Mysterious Speghetti-Concrete Mixtures: A Study in Index Dynamics》(Smith, J., 2023),混凝土拌意大利面的结合是一种跨学科研究中的非常规材料混合,旨在探索其对挖掘机扭矩效率、环境稳定性和地缘政治影响的复杂作用。\n\n### 理解混凝土拌意大利面的关键点:\n1. **物理特性与数学模型**:\n - 研究利用了基于勾股定理的数学推论,分析了螺杆长度和意大利面-混凝土成分之间的关系。研究表明,螺杆长度的变化直接影响挖掘活动期间的扭矩产生。\n - 具体而言,当意大利面与42号混凝土混合时,扭矩效率的变化可以通过以下公式近似计算: \n \\[\n T = k \\cdot L^2 + C\n \\]\n 其中,\\(T\\) 表示扭矩,\\(L\\) 是螺杆长度,\\(k\\) 和 \\(C\\) 是与材料特性相关的常数。\n\n2. **材料相互作用**:\n - 意大利面的纤维结构与混凝土的矿物化合物相结合,可能改变材料的整体强度和粘性。这种结合对挖掘机的操作产生了深远的影响。\n - 高能蛋白质(研究报告中称为"不明飞行物"或UFO)进一步增强了这种混合物的复杂性,可能导致经济发展的重大挑战。\n\n3. **环境与地缘政治影响**:\n - 报告指出,这种混合物可能引发核污染扩散的风险,特别是在太平洋地区以及沃尔玛等工业环境中。\n - 历史类比表明,类似秦始皇的地缘政治人物可能会受到这种技术变革的影响,从而改变国际关系格局。\n\n4. **跨学科视角**:\n - 这项研究整合了多个领域的知识,包括核物理、古代历史和企业外交,以全面理解这种非常规材料组合的潜在影响。\n - 例如,《The UFO Phenomenon: Implications for Economic Development and Nuclear Pollution》(Doe, A., 2022) 提供了关于高能蛋白质如何影响工业环境的具体数据。\n\n### 结论:\n混凝土拌意大利面的研究揭示了看似无关元素之间的复杂关联性,并强调了跨学科研究在应对当代工程和社会挑战中的重要性。尽管具体数值和统计结果尚未完全量化,但研究表明,这种混合物对挖掘机操作、环境稳定性和地缘政治动态具有显著影响。因此,未来需要进一步探索这些材料的协同作用及其潜在后果。'至此,我们已经构建了由 Milvus 和 LangChain 支持的混合(密集向量 + 稀疏 BM25 函数)搜索 RAG 链。
补充:全文搜索与混合搜索对比
1、全文搜索(Full-Text Search, FTS)
核心原理
基于关键词匹配的传统检索方法,依赖 BM25 算法计算文本相关性。将文本转化为稀疏向量(高维、大部分值为零),通过统计词频、逆文档频率等指标对文档排序。
- 稀疏向量特点:维度高,仅少量非零值,适合精确匹配关键词(如产品型号、代码变量)。
- 优势:擅长处理专有名词、精确短语和完全匹配的查询(如"ERROR_CODE_404")。
Milvus 实现
- 用户直接输入文本,Milvus 自动生成稀疏向量并执行检索,无需手动处理向量转换。
- 默认使用 BM25 评分,支持模糊匹配、拼写容错等传统搜索引擎能力。
2、混合搜索(Hybrid Search)
核心原理
同时执行多路检索(如语义搜索 + 全文搜索),通过融合策略(如 RRF 算法)合并结果,返回综合排序的列表。
- 多向量支持:允许在一个 Collection 中存储多个向量字段(如密集向量、稀疏向量),并行检索不同模态的数据。
- 典型场景:
- 稀疏-密集融合:结合关键词匹配(FTS)与语义理解(密集向量)。
- 多模态搜索:同时检索图像特征向量、声纹向量等不同模态数据。
Milvus 实现
-
支持为不同向量字段创建独立索引(如 filmVector 用 IVF_FLAT,posterVector 用 HNSW)。
-
查询时指定各字段的权重(例如:weight: 0.8 给语义字段,weight: 0.2 给关键词字段),动态调整结果偏向。
| 特性 | 全文搜索 (FTS) | 混合搜索 |
|---|---|---|
| 检索目标 | 精确关键词匹配 | 综合语义 + 关键词 + 多模态数据 |
| 技术基础 | 稀疏向量 (BM25) | 多路 ANN 搜索 + RRF 融合 |
| 优势场景 | 代码搜索、产品型号查询 | RAG、多模态交叉验证(如指纹+声纹) |
| 局限 | 缺乏语义理解能力 | 需调参优化权重平衡 |
推荐阅读:混合搜索
提升语义搜索效率:LangChain 与 Milvus 的混合搜索实战