生成式模型:generative model
大语言模型:Large Language Model LLM)
自回归语言莫i选哪个:autoregressive
训练对:training pair
unsupervised training
训练集:training set
学习:learning
分类:classification
回归:regression
微调:fine-tune
迁移学习:transfer learning
通用人工智能:Artificial General Intelligence
概率论:probability theory
决策论:decision theory
误差函数:error function
随机梯度下降(stochastic gradientdescent)法
收缩方法:shrinkage
权重衰减: weight decay
超参数:hyper parameter
误差反向传播:(error backpropagation)
先验知识(priorknowledge)或归纳偏置(inductive bias)
如果输出包括一个或多个连续变量称为回归问题。在化工生产过程中,根据温度、压力和反应物浓度预测产量,就是回归问题的一个例子。
深度学习的影响
- 医疗诊断
- 蛋白质结构预测 训练图像无标注,属于无监督
- 图像合成 生成与训练数据不同但又有类似统计特性的结果(生成式模型,变体prompt根据输入的文本字符串为提示词生成反映文本语义的图像。)
一类重要的大语言模型:自回归语言模型 ,能够输出语言。属于生成式AI的一种。以一个词序列作为输入,生成词序列最可能的下一个词。这类模型可以在大型文本数据集上通过提取训练对(trainingpair)进行训练。训练对的输入是随机选定的词序列,输出是已知的下一个词。这是自监督学习(self-supervised learning)的一个例子。在自监督学习中,模型学习从输入到输出映射函数,有标注的输出是从输入训练数据中自动获取的,无须进行另外的人工标注。这种方法能把多种来源的大量文本作为大型训练集,从而训练出超大规模神经网络。
自监督:无需人工标注标签,却能实现类似有监督学习的效果。利用数据自身的内在关系或结构,自动生成监督信号(伪标签),让模型从 "无标注数据" 中学习特征表示。其本质是将无监督问题转化为 "自监督" 的有监督问题,无需人工标注即可实现高效学习。
- 基于数据重构的任务 让模型从 "不完整输入" 中恢复 "完整输入",学习数据的底层特征。
- 基于时序或空间关系的任务 利用数据的时序顺序或空间结构生成监督信号。
- 基于对比学习的任务 让模型学习 "相似样本更接近、不同样本更远离" 的特征表示。
- 基于生成式的任务 通过生成与输入相关的内容,学习数据的潜在分布。
| 维度 | 有监督学习 | 无监督学习 | 自监督学习 |
|---|---|---|---|
| 标签来源 | 人工标注的明确标签 | 无标签 | 数据自身生成的伪标签 |
| 学习目标 | 拟合输入 - 标签映射 | 发现数据内在结构 | 学习通用特征表示,服务下游任务 |
| 数据利用率 | 仅利用有标签数据 | 利用全部无标签数据 | 利用无标签数据生成监督信号,利用率高 |
| 典型场景 | 垃圾邮件分类、房价预测 | 用户分群、文档聚类 | 预训练模型(BERT、GPT)、图像特征提取 |
例子:多项式拟合一个小型合成数据集(监督学习)
我们的目标是根据x的某个新值来预测相应的t的值。机器学习的一个关键目标是对以前未见过的输人进行准确预测,这种能力称为泛化能力(generalization)
机器学习的核心:从数据中学习概率
线性模型
曲线拟合的简单方法:多项式函数来拟合数据

误差函数
多项式系数的值通过拟合训练数据来确定,可以通过最小化误差函数来实现
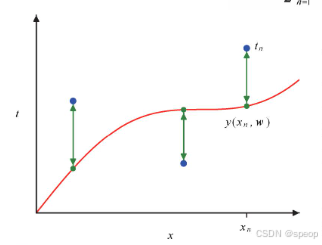
误差函数度量了对于任意给定的w,函数 y ( x , w ) y(x,w) y(x,w)与训练集中数据点之间的拟合误差
E ( w ) = 1 2 ∑ n = 1 N { y ( x n , w ) − t n } 2 E(w) = \frac{1}{2}\sum^N_{n=1} \{y ( x_n , w ) - t_n \}^2 E(w)=21∑n=1N{y(xn,w)−tn}2(残差)

其中引人系数1/2是为了后续计算方便。误差函数是非负的,当且仅当函数y(x,w)正好通过每个训练数据点时,其值等于零。
模型复杂度
M:多项式阶数
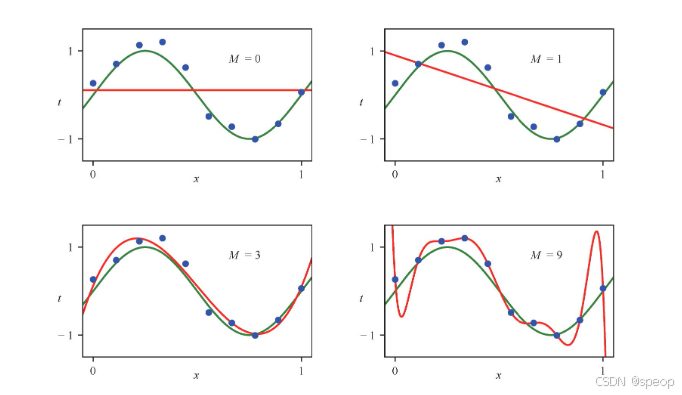
体现了过拟合和欠拟合的情况


1/N确保数据集在相同的基准下进行比较
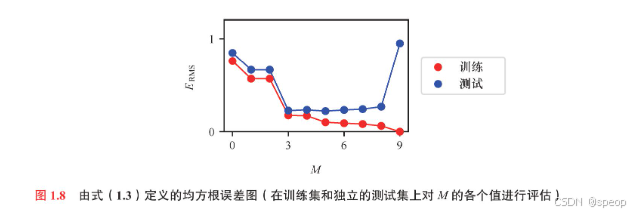
RMS 误差图(Root Mean Square Error Plot,均方根误差图)是一种用于可视化模型预测误差的统计图表,它通过计算并展示 ** 预测值与真实值之间的均方根误差(RMSE)** 来评估模型的准确性。以下从定义、计算方法、应用场景、图表解读和代码示例五个方面展开解析:

测试集上的RMS误差反映了我们根据新观测数据x预测其对应值的能力。从图1.8中可以看出,当M值较小时测试集误差较大,这是因为此时的多项式模型灵活性不足(欠拟合),无法捕捉函数 s i n ( 2 π x ) sin(2 \pi x) sin(2πx)中的振荡。当M取值在[3,8时,测试集误差较小,同时这些模型也能合理地表示出数据的生成函数 s i n ( 2 π x ) sin(2\pi x) sin(2πx),如图1.7中M=3时所示。
过拟合:
过拟合为什么表现不好

经典统计学中有一条常用的启发式经验: 训练数据点的数量应至少是模型中可学习参数数量的若干倍(比如5倍或10倍)。然而,我们在本书继续探讨深度学习后会发现即使模型参数的数量远远超过训练数据点的数量,也一样可以获得非常出色的结果(参见9.3.2小节)
正则化
根据可用训练集的大小来限制模型中参数的数量,其结果有些不尽如人意。而根据待解决问题的复杂性来选择模型的复杂性似乎更合理。作为限制参数数量的替代方案,
正则化作用:正则化(regularization)技术经常被用于控制过拟合现象,它通过向误差函数添加一个惩罚项来抑制系数取值过大。最简单的惩罚项采用所有系数的平方和的形式,误差函数变为
E ~ ( w ) = 1 2 ∑ n = 1 N y ( x n , w ) − t n 2 + λ 2 ∥ w ∥ 2 \tilde{E}(\boldsymbol{w}) = \frac{1}{2} \sum_{n=1}^{N} \left y(\\boldsymbol{x}_n, \\boldsymbol{w}) - t_n \\right^2 + \frac{\lambda}{2} \|\boldsymbol{w}\|^2 E~(w)=21∑n=1Ny(xn,w)−tn2+2λ∥w∥2
其中 ∥ w ∥ 2 ≡ w ⊤ w = w 0 2 + w 1 2 + ⋯ + w M 2 \|\boldsymbol{w}\|^2 \equiv \boldsymbol{w}^\top \boldsymbol{w} = w_0^2 + w_1^2 + \dots + w_M^2 ∥w∥2≡w⊤w=w02+w12+⋯+wM2,
并且系数 λ \lambda λ控制着正则化项与平方和误差项之间的相对重要性。注意,正则化项中通常不包含系数 w 0 w_0 w0,因为如果包含 w 0 w_0 w0,就会导致最终结果受到目标变量所选原点的影响。也可以包含 w 0 w_0 w0,但需要单独为其配置一个正则化系数
统计学:收缩方法:使得系数的值缩小
神经网络:权重衰减 ,正则化促使权重向零衰减
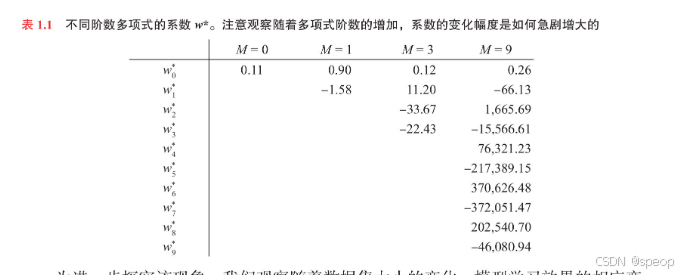
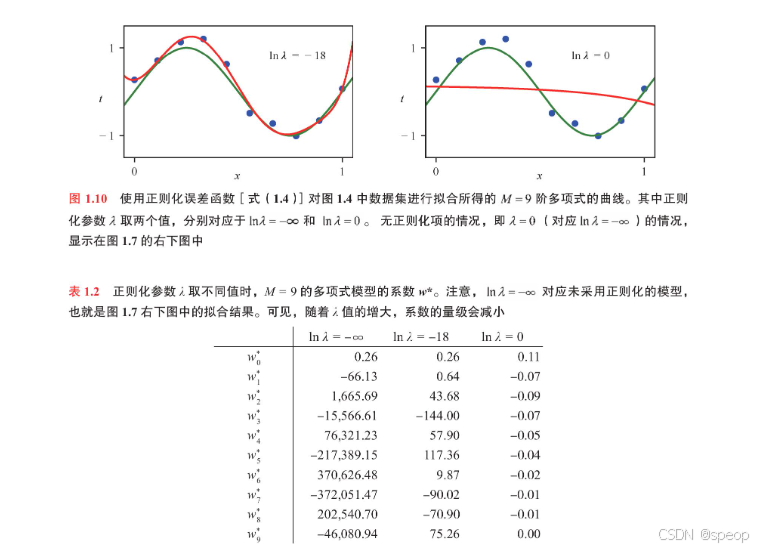
图1.10展示了采用正则化误差丽数【式(1.4)对9阶(M=9)多项式进行拟合的结果,所用数据集与之前相同。观察发现,
当取 l n λ = − 18 ln\lambda = -18 lnλ=−18时,过拟合现象被有效抑制,此时的拟合曲线与目标函数 sin(2zx)相当接近。
反之,若 λ \lambda λ取值过大,则会导致欠拟合,如图1.10中 l n λ = 0 ln\lambda =0 lnλ=0的情形。
表1.2给出了不同值下拟合得到的多项式系数这些数值表明,正则化确实发挥了预期作用,有效减小了系数的幅度
模型选择
λ \lambda λ作为一个超参数,它的值在基于误差函数最小化来确定模型参数w的过程中始终保持不变。
需要注意的是,我们不能通过同时对w和 λ \lambda λ最小化误差函数的方式来简单地确定入的取值,因为这样会导致入趋近于0,从而产生一个在训练集上误差极小甚至为零的过拟合模型
类似地,多项式的阶数M也是模型的一个超参数,单纯地优化训练集误差关于M的取值会导致M过大,同样会引发过拟合问题。因此,我们需要找到一种有效的方法来确定这些超参数的合理取值。
方法:将已有的数据集划分为训练集和验证集(validationset)也称为保留集(hold-out set)或开发集(development set),其中训练集用于确定模型系数",而我们最终选择在验证集上误差最小的模型。如果使用有限规模的数据集多次迭代模型设计,也可能会出现对验证集的过拟合现象。为此,通常需要预留出测试集,用于对最终选定模型的性能进行评估。
交叉验证:

交叉验证的主要缺点 在于所需的训练次数增加了S倍,这对于训练过程本身计算成本较高 的模型来说是一个大问题。对于单个模型可能存在多个复杂度超参数 (例如,可能有多个正则化超参数)。在最坏的情况下,探索这些超参数设置的最佳组合可能需要指数级数量的训练次数。现代机器学习的前沿领域需要非常大的模型和大规模训练数据集。因此,超参数设置的探索空间有限,很大程度上依赖于从小模型获得的经验和启发式方法。
在这些应用中,将输出映射到输入的可学习函数通常由一类被称为神经网络的模型来表征,这些模型往往具有海量的参数,其数量甚至可以达到千亿的规模。此时,误差函数将表现为这些模型参数的复杂非线性函数,无法再通过闭式解的方式进行最小化,而必须借助迭代优化的方法,利用误差函数关于模型参数的导数信息来逐步逼近最优解。
人工神经网络:神经元抽象出来的简单数学模型

a = ∑ i = 1 M w i x i a = \sum_{i=1}^{M} w_i x_i a=∑i=1Mwixi
y = f ( a ) y = f(a) y=f(a)

感知机模型:激活函数是阶跃函数 单层神经网络


反向传播
引入可微的误差函数:
对于训练具有多层可学习参数 的神经网络问题,其解决方案来自微分学的应用以及基于梯度的优化方法 。一项重要的改进是用具有非零梯度的连续可微激活函数 取代了原有的阶跃函数式 (1.7)。另一项关键的改进是引入了可微的误差函数,该函数能量化地评估 在给定参数配置下模型对训练集中目标变量的预测效果。我们在1.2节中利用平方和误差函数式(1.2)进行多项式拟合时,就已经接触到了此类误差函数的一个示例。
通过这些改进,我们现在得到了一个误差函数,它可以计算其关于网络模型中每一个参数的偏导数 。现在我们可以着手考虑具有多层参数的网络结构了。图1.16展示了一个包含两层参数的简单网络模型。位于中间层的节点称为隐藏单元(hiddenumit ) ,因为它们的值不会出现在训练数据中,训练数据仅提供了模型的输人值和输出值。图1.16中的每一个隐藏单元和每一个输出单元均计算形如式(1.5)和式(1.6)的函数值。对于一组给定的输入值,所有隐藏单元和输出单元的状态可以通过迭代地应用式(1.5)和式(1.6)进行前向计算,在这个过程中,信息沿着箭头所指的方向在网络中逐层向前传递。由于这种信息流动的特点,此类型也被称作前馈神经网络( feed-forward neural network ).
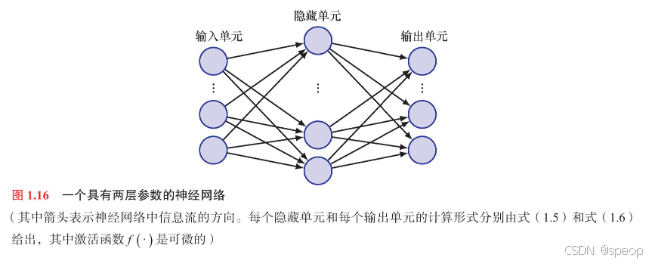
为了训练这样的神经网络,我们首先使用随机数生成器初始化参数 ,然后使用基于梯度的优化技术进行迭代更新。这需要计算误差函数的偏导数,此操作可以通过误差反向传播(error backpropagation)过程中高效地完成在反向传播中,信息从【输出端向后通过神经网络流向输入端】(方向)在机器学习领域,有许多不同的优化算法利用了待优化的函数的梯度,其中最简单和最常用的是随机梯度下降(stochastic gradientdescent)法
反向传播算法和基于梯度的优化技术显著提升了神经网络解决实际问题的能力
然而,研究人员注意到,在具有多层结构的神经网络中,通常只有最后两层的权重参数能够学习到有效的信息。除了少数例外,特别是用于图像分析的卷积神经网络模型(LeCun etal.1998)(详见第10章),具有两层以上结构的网络模型鲜有成功的应用。具有两层以上结构的网络模型鲜有成功的应用。这意味着此类网络模型不能有效解决太复杂的问题。
特征提取:将原始输人变量变换到一个新的特征空间中,希望在这个新的空间中机器学习任务能更容易解决。这种预处理步骤有时也被称为特征提取(featureextraction)。
深度网络
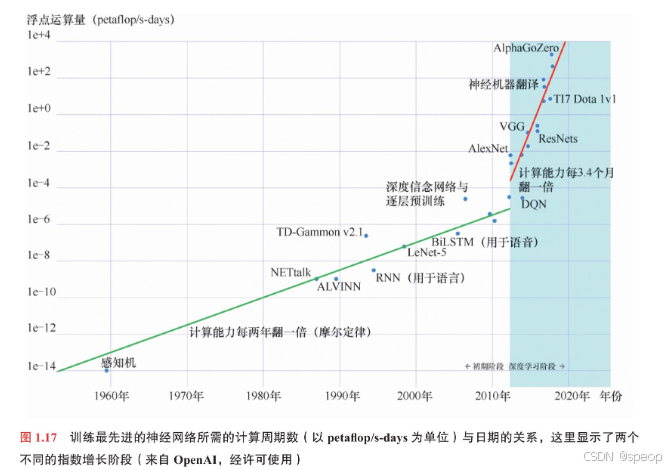
深度学习发展历程中的一个关键性主题,是神经网络模型规模的显著扩张,这集中体现在模型参数数量的爆炸式增长上。
为啥用GPU: 神经网络中某一层的各个单元所执行的运算可以高度并行地进行,这与GPU所提供的大规模并行计算架构高度契合
petaflop代表每秒执行 10 15 10^{15} 1015次(一千万亿次)浮点运算
因此,一个petaflop/s-day就代表以每秒一千万亿次的运算速率持续运行24小时所对应的计算量,这大约等价于 10 20 10^{20} 1020次浮点运算。
表征学习:我们已经了解到,网络的深度对于神经网络实现卓越性能至关重要。要理解深度神经网络中隐藏层的作用,一种有效的视角是表示学习(representationlearning,也称表征学习
在这种视角下,网络能够学习把原始输入数据转换成某种新的、富有语义信息的表示形式,从而显著降低后续网络层需要解决的问题的难度。这些学习到的内部表示还可以通过迁移学习技术被重新利用来解决其他相关问题。
在传统的简单神经网络中,训练信号随着其在深度网络中逐层反向传播而逐渐衰减(详见第9.5节)。为了解决这一难题,一种名为残差连接(residualconnection)的技术被引人网络架构中(Heetal.,2015a),它极大地提高了对数百层深度的网络的训练效率。
另一项具有里程碑意义的进展是自动微分(automaticdifferentiation)方法的提出,该方法能够基于描述网络前向传播过程的代码,自动生成用于执行反向传播以计算误差函数梯度的代码。研究人员只需要显式地编写相对简洁的前向传播函数代码,就能够快速地探索和尝试不同的神经网络架构,并快速尝试不同的架构和多种组件的不同组合。