本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习内容,尽在AI大模型技术社
一、自注意力机制:Transformer的核心突破
核心思想:让每个位置都能关注序列中所有位置的信息
1.1 Query-Key-Value 抽象模型
ini
import torch
import torch.nn as nn
import math
class SelfAttention(nn.Module):
def __init__(self, embed_size):
super().__init__()
self.embed_size = embed_size
# 创建Q、K、V的线性变换
self.Wq = nn.Linear(embed_size, embed_size)
self.Wk = nn.Linear(embed_size, embed_size)
self.Wv = nn.Linear(embed_size, embed_size)
def forward(self, x):
# x: [batch_size, seq_len, embed_size]
Q = self.Wq(x) # 查询向量
K = self.Wk(x) # 键向量
V = self.Wv(x) # 值向量
# 注意力分数计算
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.embed_size)
attn_weights = torch.softmax(scores, dim=-1)
# 上下文向量
context = torch.matmul(attn_weights, V)
return contextQKV角色解析:
- Query(查询):当前关注的位置("我在寻找什么?")
- Key(键):序列中每个位置的特征("我能提供什么?")
- Value(值):实际传递的信息("我的真实内容是什么?")
类比解释:
想象在图书馆查找资料:
Query:你的研究问题 Key:书籍目录的关键词 Value:书籍的实际内容 注意力机制就是根据问题(Q)与关键词(K)的匹配程度,决定从哪些书籍(V)中获取信息
二、Scaled Dot-Product Attention:数学原理与优化
计算公式:

2.1 缩放因子的重要性
ini
# 未缩放的注意力分数问题演示
d_k = 256 # 键向量维度
Q = torch.randn(1, 10, d_k) # [batch, seq_len, d_k]
K = torch.randn(1, 10, d_k)
# 计算原始分数
scores = torch.matmul(Q, K.transpose(-2, -1))
print("原始分数标准差:", scores.std().item()) # 约500-1000
# 缩放后
scaled_scores = scores / math.sqrt(d_k)
print("缩放后标准差:", scaled_scores.std().item()) # 约1-2缩放原因:
- 当 dk 较大时,点积结果方差增大
- softmax函数对较大输入敏感,容易饱和
- 缩放保持方差稳定,避免梯度消失
计算过程可视化:

三、Multi-Head Attention:并行化特征学习
核心思想:在不同子空间学习不同模式的注意力
3.1 完整多头注意力实现
ini
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, num_heads):
super().__init__()
self.embed_size = embed_size
self.num_heads = num_heads
self.head_dim = embed_size // num_heads
assert self.head_dim * num_heads == embed_size, "embed_size必须能被num_heads整除"
# 多头线性变换
self.Wq = nn.Linear(embed_size, embed_size)
self.Wk = nn.Linear(embed_size, embed_size)
self.Wv = nn.Linear(embed_size, embed_size)
self.fc_out = nn.Linear(embed_size, embed_size)
def split_heads(self, x):
# 重塑张量: [batch, seq_len, embed] -> [batch, num_heads, seq_len, head_dim]
batch_size = x.size(0)
return x.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
def forward(self, Q, K, V, mask=None):
batch_size = Q.size(0)
# 线性变换 + 分头
Q = self.split_heads(self.Wq(Q))
K = self.split_heads(self.Wk(K))
V = self.split_heads(self.Wv(V))
# 缩放点积注意力
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.head_dim)
# 掩码处理(可选)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn_weights = torch.softmax(scores, dim=-1)
# 上下文向量
context = torch.matmul(attn_weights, V)
context = context.transpose(1, 2).contiguous().view(
batch_size, -1, self.embed_size
)
# 合并多头输出
return self.fc_out(context)多头机制解析:
ini
# 示例:8头注意力在512维嵌入空间
embed_size = 512
num_heads = 8
# 每个头的维度
head_dim = embed_size // num_heads # 64
# 输入序列: [batch, seq_len, 512]
input_tensor = torch.randn(4, 32, 512)
# 分头后: [4, 8, 32, 64] (batch, num_heads, seq_len, head_dim)多头注意力优势:
- 并行学习不同关系模式(如近距离依赖、远距离依赖)
- 扩展模型表达能力而不增加计算复杂度
- 提供类似卷积的多通道学习能力

四、Transformer完整实现
4.1 编码器层(Encoder Layer)
ini
class TransformerEncoderLayer(nn.Module):
def __init__(self, embed_size, num_heads, ff_dim, dropout=0.1):
super().__init__()
self.self_attn = MultiHeadAttention(embed_size, num_heads)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, ff_dim),
nn.ReLU(),
nn.Linear(ff_dim, embed_size)
)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
# 自注意力子层
attn_output = self.self_attn(x, x, x, mask)
x = x + self.dropout(attn_output) # 残差连接
x = self.norm1(x) # 层归一化
# 前馈神经网络子层
ff_output = self.feed_forward(x)
x = x + self.dropout(ff_output)
x = self.norm2(x)
return x4.2 解码器层(Decoder Layer)
ini
class TransformerDecoderLayer(nn.Module):
def __init__(self, embed_size, num_heads, ff_dim, dropout=0.1):
super().__init__()
self.self_attn = MultiHeadAttention(embed_size, num_heads)
self.cross_attn = MultiHeadAttention(embed_size, num_heads)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, ff_dim),
nn.ReLU(),
nn.Linear(ff_dim, embed_size)
)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.norm3 = nn.LayerNorm(embed_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_output, src_mask=None, tgt_mask=None):
# 自注意力(只关注已生成部分)
attn1 = self.self_attn(x, x, x, tgt_mask)
x = x + self.dropout(attn1)
x = self.norm1(x)
# 交叉注意力(关注编码器输出)
attn2 = self.cross_attn(x, enc_output, enc_output, src_mask)
x = x + self.dropout(attn2)
x = self.norm2(x)
# 前馈网络
ff_output = self.feed_forward(x)
x = x + self.dropout(ff_output)
x = self.norm3(x)
return x五、位置编码:注入序列顺序信息
正弦位置编码公式:

代码实现:
scss
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() *
(-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # [1, max_len, d_model]
self.register_buffer('pe', pe)
def forward(self, x):
# x: [batch, seq_len, d_model]
return x + self.pe[:, :x.size(1), :]位置编码可视化:
ini
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
plt.pcolormesh(pe[0].numpy().T, cmap='viridis')
plt.xlabel('位置索引')
plt.ylabel('嵌入维度')
plt.title('位置编码模式')
plt.colorbar()
六、Transformer完整架构
python
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size,
embed_size=512, num_layers=6,
num_heads=8, ff_dim=2048, dropout=0.1):
super().__init__()
# 嵌入层
self.src_embed = nn.Embedding(src_vocab_size, embed_size)
self.tgt_embed = nn.Embedding(tgt_vocab_size, embed_size)
self.pos_encoder = PositionalEncoding(embed_size)
# 编码器堆叠
self.encoder_layers = nn.ModuleList([
TransformerEncoderLayer(embed_size, num_heads, ff_dim, dropout)
for _ in range(num_layers)
])
# 解码器堆叠
self.decoder_layers = nn.ModuleList([
TransformerDecoderLayer(embed_size, num_heads, ff_dim, dropout)
for _ in range(num_layers)
])
# 输出层
self.fc_out = nn.Linear(embed_size, tgt_vocab_size)
def encode(self, src, src_mask):
src_embedded = self.pos_encoder(self.src_embed(src))
for layer in self.encoder_layers:
src_embedded = layer(src_embedded, src_mask)
return src_embedded
def decode(self, tgt, enc_output, src_mask, tgt_mask):
tgt_embedded = self.pos_encoder(self.tgt_embed(tgt))
for layer in self.decoder_layers:
tgt_embedded = layer(tgt_embedded, enc_output, src_mask, tgt_mask)
return self.fc_out(tgt_embedded)
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
enc_output = self.encode(src, src_mask)
return self.decode(tgt, enc_output, src_mask, tgt_mask)Transformer数据流:
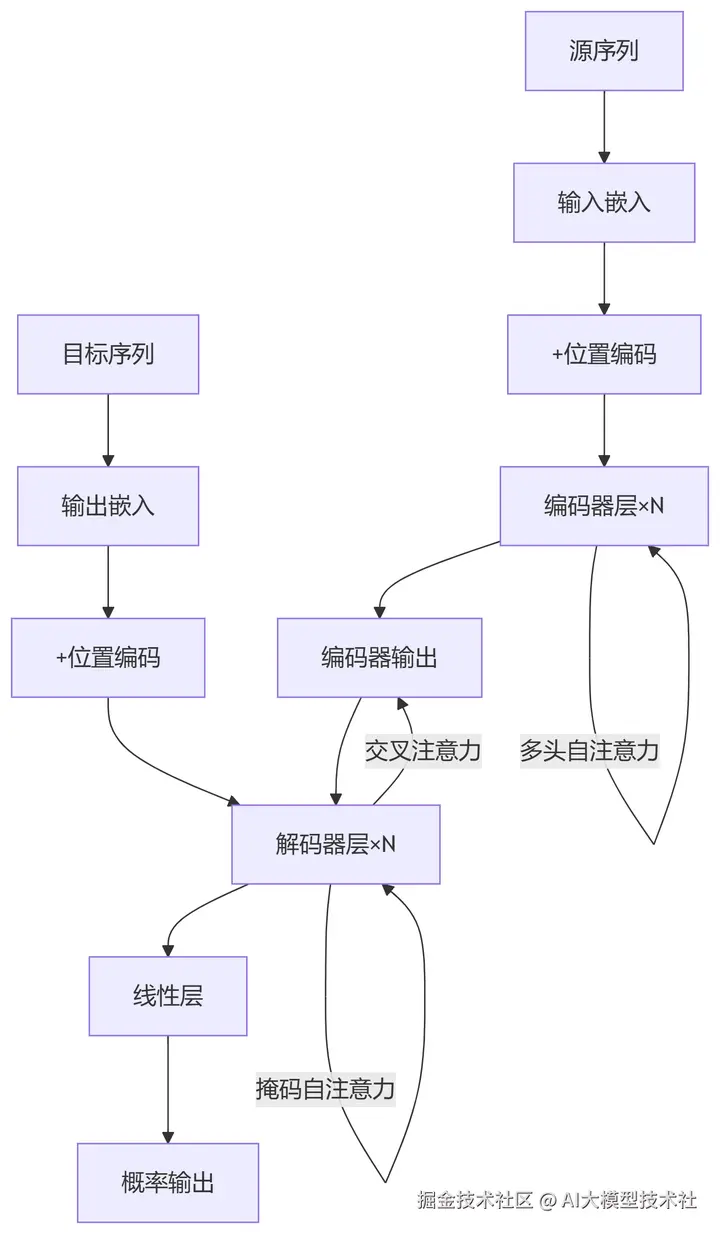
七、实战:机器翻译任务
7.1 数据处理
ini
from torchtext.datasets import Multi30k
from torchtext.data import Field, BucketIterator
# 定义字段处理
SRC = Field(tokenize="spacy", tokenizer_language="de",
init_token="<sos>", eos_token="<eos>", lower=True)
TRG = Field(tokenize="spacy", tokenizer_language="en",
init_token="<sos>", eos_token="<eos>", lower=True)
# 加载数据集
train_data, valid_data, test_data = Multi30k.splits(
exts=('.de', '.en'), fields=(SRC, TRG))
# 构建词汇表
SRC.build_vocab(train_data, min_freq=2)
TRG.build_vocab(train_data, min_freq=2)
# 创建迭代器
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator = BucketIterator(
train_data, batch_size=64, device=device)7.2 模型训练
ini
# 初始化模型
model = Transformer(
src_vocab_size=len(SRC.vocab),
tgt_vocab_size=len(TRG.vocab),
embed_size=512,
num_layers=6,
num_heads=8,
ff_dim=2048
).to(device)
# 优化器和损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
criterion = nn.CrossEntropyLoss(ignore_index=TRG.vocab.stoi["<pad>"])
# 训练循环
for epoch in range(20):
model.train()
for i, batch in enumerate(train_iterator):
src = batch.src.transpose(0, 1) # [seq_len, batch] -> [batch, seq_len]
trg = batch.trg.transpose(0, 1)
# 创建掩码
src_mask = (src != SRC.vocab.stoi["<pad>"]).unsqueeze(1).unsqueeze(2)
trg_mask = (trg != TRG.vocab.stoi["<pad>"]).unsqueeze(1).unsqueeze(2)
seq_len = trg.size(1)
nopeak_mask = torch.triu(torch.ones(1, seq_len, seq_len) == 0
trg_mask = trg_mask & nopeak_mask.to(device)
# 模型前向
output = model(src, trg[:, :-1], src_mask, trg_mask[:, :, :-1])
# 计算损失
output_dim = output.shape[-1]
output = output.contiguous().view(-1, output_dim)
trg = trg[:, 1:].contiguous().view(-1)
loss = criterion(output, trg)
# 反向传播
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1)
optimizer.step()
print(f"Epoch {epoch}: Loss={loss.item():.4f}")7.3 推理解码
ini
def translate(model, sentence, src_field, trg_field, device, max_len=50):
model.eval()
# 预处理输入
tokens = [token.lower() for token in src_field.tokenize(sentence)]
tokens = [src_field.init_token] + tokens + [src_field.eos_token]
src_indexes = [src_field.vocab.stoi[token] for token in tokens]
src_tensor = torch.LongTensor(src_indexes).unsqueeze(0).to(device)
# 编码器输出
with torch.no_grad():
src_mask = (src_tensor != src_field.vocab.stoi["<pad>"]).unsqueeze(1).unsqueeze(2)
enc_output = model.encode(src_tensor, src_mask)
# 自回归解码
trg_indexes = [trg_field.vocab.stoi[trg_field.init_token]]
for i in range(max_len):
trg_tensor = torch.LongTensor(trg_indexes).unsqueeze(0).to(device)
with torch.no_grad():
trg_mask = (trg_tensor != trg_field.vocab.stoi["<pad>"]).unsqueeze(1).unsqueeze(2)
seq_len = trg_tensor.size(1)
nopeak_mask = torch.triu(torch.ones(1, seq_len, seq_len) == 0
trg_mask = trg_mask & nopeak_mask.to(device)
output = model.decode(trg_tensor, enc_output, src_mask, trg_mask)
# 获取最后一个词预测
pred_token = output.argmax(2)[:, -1].item()
trg_indexes.append(pred_token)
if pred_token == trg_field.vocab.stoi[trg_field.eos_token]:
break
# 转换为文本
trg_tokens = [trg_field.vocab.itos[i] for i in trg_indexes]
return trg_tokens[1:] # 移除<sos>
# 测试翻译
german_sentence = "Ein Mann läuft auf einem Feld."
translation = translate(model, german_sentence, SRC, TRG, device)
print("翻译结果:", " ".join(translation)) # "A man is running in a field."八、自注意力机制变体与优化
8.1 稀疏注意力(降低计算复杂度)
ini
# 局部窗口注意力
def local_attention(Q, K, V, window_size):
seq_len = Q.size(1)
output = torch.zeros_like(V)
for i in range(seq_len):
start = max(0, i - window_size // 2)
end = min(seq_len, i + window_size // 2 + 1)
# 只计算窗口内注意力
Q_i = Q[:, i:i+1, :]
K_win = K[:, start:end, :]
V_win = V[:, start:end, :]
scores = torch.matmul(Q_i, K_win.transpose(-2, -1)) / math.sqrt(Q.size(-1))
weights = torch.softmax(scores, dim=-1)
output[:, i] = torch.matmul(weights, V_win).squeeze(1)
return output8.2 线性注意力(O(N)复杂度)
scss
def linear_attention(Q, K, V):
# 特征映射函数
def phi(x):
return torch.nn.functional.elu(x) + 1
Q_mapped = phi(Q)
K_mapped = phi(K)
KV = torch.einsum('nld,nlm->nld', K_mapped, V)
Z = 1 / (torch.einsum('nld,nl->nd', Q_mapped, K_mapped.sum(dim=1)) + 1e-6)
return Z.unsqueeze(1) * torch.einsum('nld,ndm->nlm', Q_mapped, KV)8.3 高效Transformer架构对比

Transformer在AI大模型中的应用:

作者洞见:自注意力机制的本质是动态特征路由。与传统架构相比:
- CNN:静态局部感受野 → Transformer:动态全局感受野
- RNN:顺序计算 → Transformer:并行计算
- 全连接:位置无关 → Transformer:位置感知
掌握Transformer,就掌握了当代AI大模型的通用计算引擎。从语言到视觉,从语音到科学计算,这一架构正在重塑AI的边界。更多AI大模型应用开发学习内容,尽在AI大模型技术社。