一、数据预处理
直接收集的数据通常是"脏的":
不完整、不准确、不一致

数据预处理是进行大数据的分析和挖掘的工作中占工作量最大的一个步骤 (80%)
二、处理缺失值
处理缺失数据的方法:首先确认缺失数据的影响
数据删除(可能丢失信息,或改变分布)
删除数据
删除属性
改变权重
数据填充
特殊值填充
·空值填充,不同于任何属性值。例,NLP词表补0,DL补mask
·样本/属性的均值、中位数、众数填充
使用最可能的数据填充
·热卡填充(就近补齐)
·K最近距离法(KNN)
·利用回归等估计方法
·期望值最大化方法(EM算法)
热卡填充
完整数据中找到1个与它最相似的样本,然后用该样本的值来进行填充
K最近距离法
根据相关分析(距离)来确定距离缺失数据样本的最近K个样本
将这K个值加权平均估计样本缺失数据
回归法
基于数据集,建立回归模型
将已知属性值代入模型来估计未知属性值,以此预测值
期望值最大化方法(EM算法)
在缺失类型为随机缺失的条件下,通过观测数据的边际分布可以对未知参数进行极大似然估计
EM算法在每一迭代循环过程中交替执行两个步骤:
E步(Excepctaion step, 期望步),在给定完全数据和前一次迭代所得到的隐含参数估计的情况下计算完全数据对应的对数似然函数的条件期望
M步(Maximzation step,极大化步),用极大化对数似然函数以确定参数(更新隐含参数)的值,并用于下步的迭代
三、清洗噪声
噪声是测量误差的随机部分
包括错误值,或偏离期望的孤立点值
需要对数据进行平滑
常用的处理方法
分箱(binning)
利用近邻数据对数据进行平滑
例如:

回归(Regression)
让数据适应回归函数来平滑数据识别离群点,常用聚类方法监测并且去除孤立点

四、数据集成
将多个数据源的数据整合到一个一致的数据存储中
而集成数据(库)时,经常出现冗余数据
冗余数据带来的问题: 浪费存储、重复计算
冗余的属性
冗余的样本
例如:
用户的电商记录出现在很多app中
用户的个人信息在多个app中
检测冗余的方法

而对于部分冗余样本(不同于冗余属性,属性>样本)
方法一:距离度量
欧几里得距离、曼哈顿距离、汉明距离、明氏距离......
方法二:相似度计算
余弦相似度、Jaccard相似度
五、距离度量
欧几里得距离(Euclidean Distance)

汉明距离(Hamming Distance)

两个向量之间不同值的个数。
字符串比较:比较两个相同长度的二进制字符串
明氏距离(Minkowski Distance)

r 是参数
n 表示数据 p 和 q 维度数, 和
表示数据 p 和 q 的第 k 个属性
r=1:曼哈顿距离
r=2:欧氏距离
r=:切比雪夫距离
马氏距离:数据的协方差距离

下图中,红色的数据点, 欧氏距离为14.7, 马氏距离为6

马氏距离把方差归一化,使得特征之间的关系更加符合实际情况。
六、相似度计算
数据p和q,定义如下4个变量
F01:p为0,q为1的属性数量
F10:p为1,q为0的属性数量
F00:p为0,q为0的属性数量
F11:p为1,q为1的属性数量
简单匹配****Simple Matching
SMC = number of matches / number of attributes
= (F11 + F00) / (F01 + F10 + F11 + F00)
Jaccard 相关系数
Jaccard = number of 11 matches / number of non-zero attributes
= (F11) / (F01 + F10 + F11)

余弦相似度

Pearson相关系数
衡量两个数据对象之间的线性关系
数据标准化
可以简单理解为:p和q的协方差/(p的标准差∗q的标准差)


无序数据:每个数据样本的不同维度是没有顺序关系的
余弦相似度、相关度、欧几里得距离、Jaccard
有序数据:对应的不同维度 (如特征 )是有顺序 (rank)要求的
比如在推荐系统中,如何判断不同推荐序列的好坏
引入如下两个系数:
Spearman Rank(斯皮尔曼等级)相关系数

范围-1到1,代表负相关(-1)到正相关(1),以及中间的不相关(0)
不是很显然,所以举个例子

标准化的折损累计增益(NDCG)

NDCG:由于搜索结果随着检索词的不同,返回的数量不一致,而DCG是一个累加的值,没法针对两个不同的搜索结果进行比较,因此需要标准化处理,这里是除以IDCG:

IDCG为理想(ideal)情况下最大的DCG值,指推荐系统为某一用户返回的最好推荐结果列表(或者,真实的数据序列)
也不是很直观,找到一个例题:

七、数据变换
数据变换的目的是将数据转换成适合分析建模的形式
前提条件:尽量不改变原始数据的规律
数据规范化
目的:将不同数据(属性)按一定规则进行缩放,使它们具有可比性
映射到0-1范围,又称归一化
最小-最大规范化
对原始数据进行线性变换。把数据A的观察值v从原始的区间minA,maxA映射到新区间 new_minA,new_maxA

z-score规范化
最大最小值未知,或者离群点影响较大时,假设数据服从正态分布
某一原始数据(v)与原始均值的差再除以标准差,可以衡量某数据在分布中的相对位置
小数定标规范化
通过移动小数点的位置来进行规范化。小数点移动多少位取决于属性A的取值中的最大绝对值

八、数据的离散化
信息熵:度量系统的不确定程度
信息量
定义一个时间x的概率分布为P(x)
则事件x的自信息量是-logP(x), 取值范围0到正无穷

信息熵
平均而言,发生一个事件我们得到的自信息量大小
即:熵可以表示为自信息量的期望

根据Entropy进行二分离散化
先找到一个分隔点(属性值),把所有数据分到两个区间
分别对两个子区间的数据进行二分隔
重复以上步骤

如何确定分隔点?--计算分隔后的信息增益
信息增益(Information Gain):

信息增益:表示在某个条件下,信息不确定性减少的程度。
父节点 P 被分隔为 K 个区间
n 表示总记录数,n_i表示区间 i 中的记录数
确定分隔点 j :
选择信息增益最大的分隔点,即
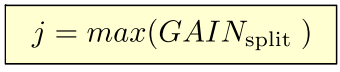
九、数据规约
目标:缩小数据挖掘所需的数据集规模
维度归约
减少所考虑的随机变量或属性的个数
方法:
主成分分析
特征子集选择
数值归约
用较小的数据表示形式替换原始数据
主成分分析(principal component analysis, PCA)
将原高维(如维度为N)数据向一个较低维度(如维度为K)的空间投影,同时使得数据之间的区分度变大。这K维空间的每一个维度的基向量(坐标)就是一个主成分


算法逻辑如下:

不足之处
·当原始数据的维度n特别大的时候,计算协方差时的 已经具有相当大的计算量
·针对协方差矩阵C的特征值求解过程计算效率不高
属性子集选择(特征子集)
做法:删除不相关或冗余的属性来减少维度与数据量
目标:找到最小属性集,使得数据的概率分布尽可能接近使用所有属性得到的原分布
例如决策树剪枝等操作
具体的奥秘还有很多:
奇异值分解(SVD)

矩阵分解(PMF)

深度学习(Deep Learning)

本节知识点非常多,欢迎大家补充,下一讲,我们讲述特征工程