TensorFlow深度学习实战(26)------生成对抗网络详解与实现
0. 前言
生成对抗网络 (Generative Adversarial Network, GAN) 能够学习高维复杂数据分布,受到了广泛的研究。自 2016 年首次提出 GAN 到以来,不到十年间,相关的研究论文已超过数十万篇。GAN 能够应用于生成图像、视频、音乐,甚至自然语言,例如,图像到图像的转换、图像超分辨率、药物发现,视频帧预测,GAN 在合成数据生成任务中表现尤为出色。在本节中,我们将学习 GAN 的原理并使用 TensorFlow 实现 GAN。
1. 生成对抗网络原理
生成对抗网络 (Generative Adversarial Network, GAN) 的关键思想可以通过将其比作艺术作品伪造来理解,艺术作品伪造是创作被错误鉴别为著名艺术家的艺术作品。GAN 同时训练两个神经网络。生成器 Generator G ( z ) G(z) G(z) 负责伪造作品,而判别器 Discriminator D ( x ) D(x) D(x) 则根据对真实作品和伪造作品的观察来判断伪造作品的真实性。 D ( x ) D(x) D(x) 接受输入 x x x (例如一张图像),并给出表示输入真实程度的值。一般来说,值接近 1 表示"真实",值接近 0 表示"伪造"。
生成器 G ( z ) G(z) G(z) 从随机噪声 z z z 中采样输入,并训练以欺骗判别器,让判别器认为 G ( z ) G(z) G(z) 生成的输出是真实的。训练判别器 D ( x ) D(x) D(x) 的目标是最大化每个来自真实数据分布样本的 D ( x ) D(x) D(x) 值,并最小化每个非真实数据分布样本的 D ( x ) D(x) D(x) 值,这也就是对抗训练 (adversarial training) 名称的由来。交替训练生成器和判别器,将每个网络目标都表示为通过梯度下降优化的损失函数。生成器不断提高其伪造能力,而判别器不断提高其伪造识别能力。
在图像领域,判别器通常是一个标准卷积神经网络,分类输入图像是真实的还是生成的,通过判别器和生成器进行反向传播,调整生成器的参数,使生成器能够以更高的概率欺骗判别器。最终,生成器将学会生成与真实图像无法区分的图像。

GAN 涉及两个模型之间的博弈,在这个博弈中我们期望达到平衡状态。训练开始时,我希望其中一个模型比另一个更优秀,这促使另一个模型提高性能,从而生成器和判别器相互推动着彼此进步。最终,会达到平衡状态,此时两者不会再有明显的改进。可以通过绘制损失函数来检查平衡点,查看两个损失(生成器损失和判别器损失)何时不再改进。我们不希望训练过程过于偏向某一方,如果生成器能够立即学会欺骗判别器,那么生成器就没有更多学习的必要。实际上,训练 GAN 的过程非常困难,研究人员对 GAN 的收敛性进行了大量研究。在 GAN 的生成应用中,通常希望生成器的学习能力略高于判别器。
接下来,我们深入了解 GAN 的学习过程。判别器和生成器交替进行学习,学习过程可以分为两个步骤:
- 首先,判别器 D ( x ) D(x) D(x) 进行学习。生成器 G ( z ) G(z) G(z) 用随机噪声 z z z (遵循某个先验分布 P ( z ) P(z) P(z) )生成伪造图像。将生成器生成的伪造图像和训练数据集中的真实图像都输入到判别器中,判别器进行监督学习,尝试将伪造图像与真实图像区分开来。如果 P d a t a ( x ) P_{data}(x) Pdata(x) 是训练数据集的分布,那么判别器的目标是最大化其目标函数,使得当输入数据为真实时, D ( x ) D(x) D(x) 接近
1,当输入数据为伪造时, D ( x ) D(x) D(x) 接近0 - 然后,生成器网络进行学习。其目标是欺骗判别器网络,使其认为生成的 G ( z ) G(z) G(z) 是真实的,即令 D ( G ( z ) ) D(G(z)) D(G(z)) 接近
1
顺序重复以上两个步骤。训练结束后,判别器将不再能够区分真实数据和伪造数据,而生成器将非常擅长生成与训练数据相似的数据。
了解了 GAN 的基本原理后,实现一个 GAN 用于生成 MNIST 手写数字。
2. 构建 GAN 生成 MNIST 数据
本节中,我们将构建一个简单的生成对抗网络 (Generative Adversarial Network, GAN) 来生成 MNIST 手写数字,使用 MNIST 手写数字数据集训练网络。
(1) 首先,导入 TensorFlow 模块:
python
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Input, Dense, Reshape, Flatten, Dropout
from tensorflow.keras.layers import BatchNormalization, Activation, ZeroPadding2D
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.layers import UpSampling2D, Conv2D
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras import initializers
import matplotlib.pyplot as plt
import sys
import numpy as np
import tqdm(2) 使用 TensorFlow Keras 数据集访问 MNIST 数据。数据集包含 60,000张手写数字作为训练图像,每张图像的大小为 28 × 28,像素值在 0 到 255 之间,将输入值归一化,使每个像素的值范围在 [-1, 1] 之间:
python
randomDim = 10
# Load MNIST data
(X_train, _), (_, _) = mnist.load_data()
X_train = (X_train.astype(np.float32) - 127.5)/127.5(3) 由于本节使用简单的多层感知器 (multi-layered perceptron, MLP) 构建网络,因此将图像重塑为大小为 784 的一维向量输入:
python
X_train = X_train.reshape(60000, 784)(4) 构建生成器和判别器。生成器接受一个噪声输入,并生成一个与训练数据集相似的图像。噪声输入的大小由变量 randomDim 决定,可以将其初始化为任何整数值,本节中,我们将其设为 10,将输入馈送到一个具有 256 个神经元的全连接层,并使用 LeakyReLU 激活函数。接下来,添加另一个具有 512 个神经元的隐藏层,之后是一个具有 1024 个神经元的隐藏层,最后是一个具有 784 个神经元的输出层。可以改变隐藏层中神经元的数量,观察性能的变化,但输出单元中的神经元数量必须与训练图像中的像素数量相匹配:
python
generator = Sequential()
generator.add(Dense(256, input_dim=randomDim)) #, kernel_initializer=initializers.RandomNormal(stddev=0.02)))
generator.add(LeakyReLU(0.2))
generator.add(Dense(512))
generator.add( LeakyReLU(0.2))
generator.add(Dense(1024))
generator.add(LeakyReLU(0.2))
generator.add(Dense(784, activation='tanh'))接下来,构建判别器。判别器接收来自训练集的图像和生成器生成的图像,因此其输入大小为 784。此外,使用 TensorFlow 的初始化器初始化全连接层的权重,采用标准差为 0.02、均值为 0 的正态分布作为初始化器。判别器的输出是一个二元值,0 表示伪造图像(由生成器生成), 1` 表示真实图像(来自训练数据集):
python
discriminator = Sequential()
discriminator.add(Dense(1024, input_dim=784, kernel_initializer=initializers.RandomNormal(stddev=0.02)))
discriminator.add(LeakyReLU(0.2))
discriminator.add(Dropout(0.3))
discriminator.add(Dense(512))
discriminator.add(LeakyReLU(0.2))
discriminator.add(Dropout(0.3))
discriminator.add(Dense(256))
discriminator.add(LeakyReLU(0.2))
discriminator.add(Dropout(0.3))
discriminator.add(Dense(1, activation='sigmoid'))(5) 将生成器和判别器组合起来形成 GAN。在 GAN 中,通过将 trainable 参数设置为 False 来确保判别器的权重保持不变:
python
# Combined network
discriminator.trainable = False
ganInput = Input(shape=(randomDim,))
x = generator(ganInput)
ganOutput = discriminator(x)
gan = Model(inputs=ganInput, outputs=ganOutput)(6) 训练生成器与判别器。首先单独训练判别器,对判别器使用二元交叉熵损失。之后,固定判别器权重,并训练整个 GAN,以此训练生成器,损失同样使用二元交叉熵:
python
adam_1 = Adam(lr=0.0002, beta_1=0.5)
adam_2 = Adam(lr=0.0002, beta_1=0.5)
discriminator.compile(loss='binary_crossentropy', optimizer=adam_1)
gan.compile(loss='binary_crossentropy', optimizer=adam_2)(7) 为了绘制损失值和生成的手写数字图像,定义两个辅助函数,plotLoss() 和 saveGeneratedImages():
python
# Plot the loss from each batch
def plotLoss(epoch):
plt.figure(figsize=(10, 8))
plt.plot(dLosses, label='Discriminitive loss')
plt.plot(gLosses, label='Generative loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.savefig('images/gan_loss_epoch_%d.png' % epoch)
# Create a wall of generated MNIST images
def saveGeneratedImages(epoch, examples=100, dim=(10, 10), figsize=(10, 10)):
noise = np.random.normal(0, 1, size=[examples, randomDim])
generatedImages = generator.predict(noise)
generatedImages = generatedImages.reshape(examples, 28, 28)
plt.figure(figsize=figsize)
for i in range(generatedImages.shape[0]):
plt.subplot(dim[0], dim[1], i+1)
plt.imshow(generatedImages[i], interpolation='nearest', cmap='gray_r')
plt.axis('off')
plt.tight_layout()
plt.savefig('images/gan_generated_image_epoch_%d.png' % epoch)saveGeneratedImages() 函数将图像保存到 images 文件夹中,因此需要在当前工作目录下创建该文件夹。
(8) 训练网络。在每个训练 epoch,首先取一个随机噪声样本,将其输入到生成器中,生成器会生成一个伪造图像。将生成的伪造图像和真实训练图像组合在一个批次中,并使用这些图像及其标签训练判别器:
python
dLosses = []
gLosses = []
def train(epochs=1, batchSize=128):
batchCount = int(X_train.shape[0] / batchSize)
print ('Epochs:', epochs)
print ('Batch size:', batchSize)
print ('Batches per epoch:', batchCount)
for e in range(1, epochs+1):
print ('-'*15, 'Epoch %d' % e, '-'*15)
for _ in range(batchCount):
# Get a random set of input noise and images
noise = np.random.normal(0, 1, size=[batchSize, randomDim])
imageBatch = X_train[np.random.randint(0, X_train.shape[0], size=batchSize)]
# Generate fake MNIST images
generatedImages = generator.predict(noise)
# print np.shape(imageBatch), np.shape(generatedImages)
X = np.concatenate([imageBatch, generatedImages])
# Labels for generated and real data
yDis = np.zeros(2*batchSize)
# One-sided label smoothing
yDis[:batchSize] = 0.9
# Train discriminator
discriminator.trainable = True
dloss = discriminator.train_on_batch(X, yDis)需要注意的是,在分配标签时,对伪造图像和真实图像分别使用了 0 和 0.9 而非 0 和 1,这称为标签平滑。研究表明,使用平滑标签可以提高模型泛化能力和学习速度。
接下来,在同一个循环中,训练生成器。我们希望生成器生成的图像被判别器识别为真实图像,因此使用随机向量(噪声)作为生成器的输入,生成伪造图像,并训练 GAN 使得判别器将该图像视为真实图像(输出为 1):
python
# Train generator
noise = np.random.normal(0, 1, size=[batchSize, randomDim])
yGen = np.ones(batchSize)
discriminator.trainable = False
gloss = gan.train_on_batch(noise, yGen)可以保存生成器和判别器的损失值以及生成的图像。接下来,在每 20 个 epoch 后保存损失值和生成的图像:
python
# Store loss of most recent batch from this epoch
dLosses.append(dloss)
gLosses.append(gloss)
if e == 1 or e % 20 == 0:
saveGeneratedImages(e)
# Plot losses from every epoch
plotLoss(e)(9) 通过调用训练函数训练 GAN,可以看到 GAN 学习过程中的生成损失和判别损失的变化:
python
train(200, 128)
GAN 生成的手写数字图像如下,可以看到,随着训练的增加,GAN 生成的手写数字变得越来越逼真。

3. 经典 GAN 架构
自 GAN 提出以来,研究人员进行了大量相关研究,包括对 GAN 训练、架构和应用。在本节中,我们将介绍一些经典的 GAN 架构。
3.1 SRGAN
超分辨率 (Super Resolution, SR) 是一种图像处理技术,用于从低分辨率图像生成高分辨率图像,可以应用于多个领域,如医疗影像、卫星图像、视频监控以及计算机视觉等。超分辨率的目标是通过恢复图像的细节和清晰度,使低分辨率图像的视觉质量得到显著提升。
超分辨率 GAN (Super Resolution GAN, SRGAN)可以实现超分辨率,获得高分辨率图像,GAN 经过训练,可以在给定低分辨率图像时生成照片级的高分辨率图像。SRGAN 架构包括三个神经网络:生成器网络、判别器网络,以及一个预训练的 VGG-16 网络。
SRGAN 使用感知损失函数进行训练。在 SRGAN 中,首先将高分辨率图像下采样,并使用生成器获得其"高分辨率"版本。判别器训练以区分真实的高分辨率图像和生成的高分辨率图像。VGG 网络高层中的特征图激活之间的差异,即网络输出和高分辨率部分之间的差异,构成了感知损失函数。除了感知损失,还添加了内容损失和对抗损失,使生成的图像看起来更自然,细节更丰富。感知损失定义为内容损失和对抗损失的加权和:
l S R = l X S R + 1 0 − 3 × l G e n S R l^{SR}=l_X^{SR}+10^{-3}\times l_{Gen}^{SR} lSR=lXSR+10−3×lGenSR
公式右侧第一个项是内容损失,使用预训练的 VGG 19 生成的特征图获得。从数学上讲,它是重建图像(即由生成器生成的图像)特征图与原始高分辨率参考图像之间的欧几里得距离。第二项是对抗损失,是标准的生成对抗损失项,旨在确保生成器生成的图像能够欺骗判别器。在下图中可以看出,SRGAN 生成的图像与原始高分辨率图像的 PSNR 值为 37.61,接近原始图像:

3.2 CycleGAN
CycleGAN 于 2017 年提出,可以执行图像转换任务。训练完成后,可以将图像从源域转换到目标域。例如,在马和斑马数据集上训练 CycleGAN 后,可以将马的图像转换为具有相同背景的斑马的图像。
CycleGAN 能够用于在没有成对训练样本的情况下执行图像转换,即在没有成对训练样本的情况下,将一个域(例如风景)的图像转移到另一个域,例如将风景照片转换为具有相同内容的梵高风格画作。
为了实现图像转换,使用两个 GAN,每个 GAN 的生成器执行从一个域到另一个域的图像转换。具体来说,假设输入是 X X X,那么第一个 GAN 的生成器执行映射 G : X → Y G:X\rightarrow Y G:X→Y,其输出为 Y = G ( X ) Y = G(X) Y=G(X);第二个 GAN 的生成器执行逆映射 F : Y → X F:Y\rightarrow X F:Y→X,结果为 X = F ( Y ) X = F(Y) X=F(Y)。每个判别器都训练用于区分真实图像和生成图像:
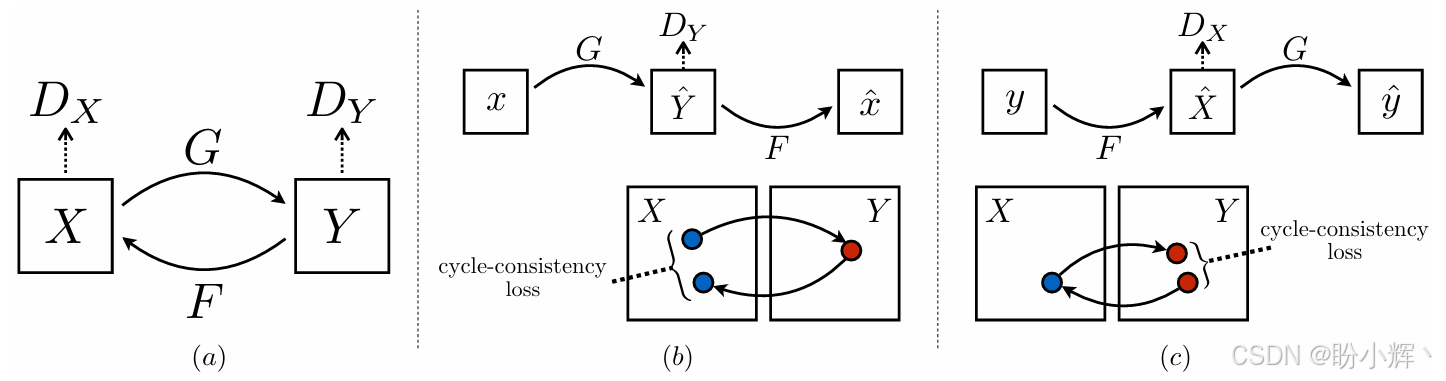
为了训练 CycleGAN,除了传统的对抗损失外,还添加了循环一致性损失,用于确保给定图像 X X X 作为输入,那么经过两次转换 F ( G ( X ) ) ∼ X F(G(X)) \sim X F(G(X))∼X 后得到的图像与 X X X 相同,类似地,需要损失确保 G ( F ( Y ) ) ∼ Y ) G(F(Y)) \sim Y) G(F(Y))∼Y)。CycleGAN 的应用示例如下:

接下来,我们将介绍 InfoGAN,这是一种条件 GAN,不仅能够生成图像,还可以通过控制变量来控制生成的图像。
3.3 InfoGAN
传统 GAN,对生成图像的控制非常有限或没有控制。InfoGAN 提供了对生成图像的各种属性的控制。InfoGAN 使用信息论中的概念,将噪声项转换为潜编码,从而对输出提供可预测和系统的控制。
InfoGAN 中的生成器接受两个输入:潜空间向量 Z Z Z 和潜编码 c c c,因此生成器的输出为 G ( Z , c ) G(Z, c) G(Z,c)。InfoGAN 的训练目标是最大化潜编码 c c c 与生成图像 G ( Z , c ) G(Z, c) G(Z,c) 之间的互信息。InfoGAN 网络架构如下:

连接向量 ( Z , c ) (Z, c) (Z,c) 输入到生成器中。 Q ( c ∣ X ) Q(c|X) Q(c∣X) 也是一个神经网络,与生成器结合,形成了随机噪声 Z Z Z 和其潜编码 c ^ \hat c c^ 之间的映射,目标是给定 X X X 估计 c c c。通过在传统 GAN 的目标函数中添加一个正则化项来实现:
m i n D m a x G L ( D , G ) = L G ( D , G ) − λ I ( c ; G ( Z , c ) ) min_Dmax_GL(D,G)=L_G(D,G)-\lambda I(c;G(Z,c)) minDmaxGL(D,G)=LG(D,G)−λI(c;G(Z,c))
其中, L G ( D , G ) L_G(D,G) LG(D,G) 是传统 GAN 的损失函数,第二项是正则化项, λ \lambda λ 是常数,在原始论文实现中, λ \lambda λ 的值设置为 1, I ( c ; G ( Z , c ) ) I(c;G(Z,c)) I(c;G(Z,c)) 是潜编码 c c c 和生成器生成的图像 G ( Z , c ) G(Z,c) G(Z,c) 之间的互信息。
InfoGAN 在 MNIST 数据集训练后得到的结果如下:

4. GAN 应用
生成器可以学习如何创建新的合成数据,且看起来非常逼真。StackGAN 使用 GAN 从文本描述中合成伪造图像,通过 `StackGAN· 的第一阶段和第二阶段从相同文本描述生成的图像如下所示:

GAN 能够对生成器的向量 Z Z Z 进行算术运算。例如,在生成图像的空间中,可以看到:微笑的女人 - 女人 + 男人 = 微笑的男人,或者:戴眼镜的男人 - 不戴眼镜的男人 + 不戴眼镜的女人 = 戴眼镜的女人:

经过五个 epoch 训练生成的卧室图像:

GAN 能够应用于生成面部图像。NVIDIA 在 2018 年提出了 StyleGAN 模型,可以用于生成逼真的人脸图像。经过 1,000 个 epoch 训练后,StyleGAN 生成的逼真的人脸图像:

StyleGAN 不仅可以生成伪造图像,而且可以像 InfoGAN 一样,控制生成人脸图像的特征,这可以通过在潜向量 Z Z Z 之后添加非线性映射网络实现。映射网络将潜向量转换为相同大小的映射;映射向量的输出馈送到生成器网络的不同层,使得 StyleGAN 可以控制不同的视觉特征。
小结
生成对抗网络是一种强大的深度学习模型,由生成器网络和判别器网络组成,通过彼此之间的竞争来提高性能,已经在图像生成、图像修复、图像转换和自然语言处理等领域取得了巨大的成功。其核心思想是通过生成器和判别器之间的博弈过程来实现真实样本的生成。生成器负责生成逼真的样本,而判别器则负责判断样本是真实还是伪造。通过不断的训练和迭代,生成器和判别器会相互竞争并逐渐提高性能。
系列链接
TensorFlow深度学习实战(1)------神经网络与模型训练过程详解
TensorFlow深度学习实战(2)------使用TensorFlow构建神经网络
TensorFlow深度学习实战(3)------深度学习中常用激活函数详解
TensorFlow深度学习实战(4)------正则化技术详解
TensorFlow深度学习实战(5)------神经网络性能优化技术详解
TensorFlow深度学习实战(6)------回归分析详解
TensorFlow深度学习实战(7)------分类任务详解
TensorFlow深度学习实战(8)------卷积神经网络
TensorFlow深度学习实战(9)------构建VGG模型实现图像分类
TensorFlow深度学习实战(10)------迁移学习详解
TensorFlow深度学习实战(11)------风格迁移详解
TensorFlow深度学习实战(12)------词嵌入技术详解
TensorFlow深度学习实战(13)------神经嵌入详解
TensorFlow深度学习实战(14)------循环神经网络详解
TensorFlow深度学习实战(15)------编码器-解码器架构
TensorFlow深度学习实战(16)------注意力机制详解
TensorFlow深度学习实战(17)------主成分分析详解
TensorFlow深度学习实战(18)------K-means 聚类详解
TensorFlow深度学习实战(19)------受限玻尔兹曼机
TensorFlow深度学习实战(20)------自组织映射详解
TensorFlow深度学习实战(21)------Transformer架构详解与实现
TensorFlow深度学习实战(22)------从零开始实现Transformer机器翻译
TensorFlow深度学习实战(23)------自编码器详解与实现
TensorFlow深度学习实战(24)------卷积自编码器详解与实现
TensorFlow深度学习实战(25)------变分自编码器详解与实现