公共资源速递
5 个公共数据集:
* FirstAidQA 急救知识问答数据集
* PhysDrive 驾驶员生理测试数据集
* PolypSense3D 息肉尺寸感知数据集
* Envision 多阶段事件视觉生成数据集
* Care-PD 帕金森三维步态评估数据集
8 个公共模型:
* SAM 3
* Z-Image-Turbo
* Ovis-Image-7B
* Ministral-3-14B
* LongCat-Image
* Open-AutoGLM
* VibeVoice-Realtime-0.5B
* Eigen-Banana-Qwen-Image-Edit
5 个公共教程:
* RFdiffusion3:蛋白质设计模型
* Open-AutoGLM:手机端智能助理
* MarkItDown 微软开源的文档转换工具
* LongCat-Image:双语文本驱动图像生成系统
* LightOnOCR-1B-Interface:面向复杂文档的高速 OCR 引擎
访问官网立即使用:http://openbayes.com
公共数据集
FirstAidQA 包含 5,500 条高质量文本问答对,全部围绕急救与应急响应场景构建。数据内容覆盖急救操作流程、紧急处置方法与安全注意事项,问答结构清晰、专业性强。所有样本均基于权威急救教材生成,文本形式统一,适合用于急救知识问答与应急场景下的语言模型训练与评测。
* 在线使用:
https://go.openbayes.com/kVEdl
PhysDrive 包含约 24 小时(约 150 万帧)的多模态驾驶数据,采集自 48 名驾驶员的真实驾驶过程。每位受试者完成 6 个约 5 分钟的驾驶片段,覆盖多种光照条件、车型、驾驶动作与道路环境。数据同步提供 RGB 视频、近红外视频与毫米波雷达信号,并配套多类生理真值标注,适合用于非接触式生理测量与驾驶员状态分析。
* 在线使用:
https://go.openbayes.com/Qe9U0
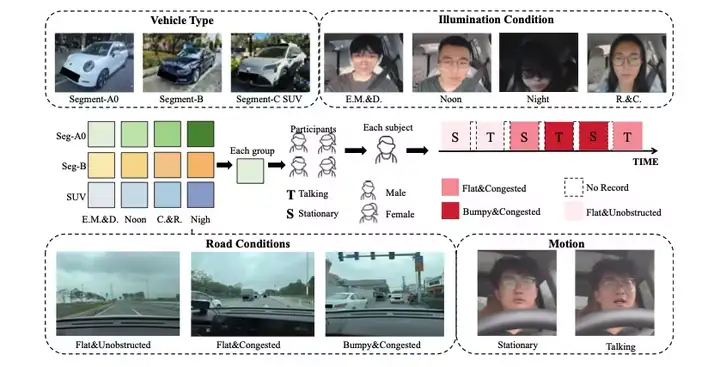
数据集示例
PolypSense3D 是一个多源内镜数据集,由虚拟仿真、实体仿体与真实临床三类数据组成。虚拟数据包含 32,000+ 帧,提供 RGB、密集深度、分割掩码与相机参数;实体仿体数据基于 3D 打印结肠模型采集,包含精确尺寸标注;临床数据来自真实内镜检查,提供冻结帧、分割结果与基于校准器具的尺寸标注,适合用于息肉检测、深度估计与尺寸测量研究。
* 在线使用:
https://go.openbayes.com/a9iPA
Envision 数据集由 1,000 个完整事件序列与 4,000 条四阶段文本提示组成,每个事件被拆分为多个时间阶段,形成明确的阶段递进结构。数据覆盖自然科学与人文历史等六大领域,事件素材来源于教材与公开资料,并经过统一生成与润色,强调因果关系与多阶段演化,适合用于事件理解与多阶段生成任务。
* 在线使用:
https://go.openbayes.com/PYeFr
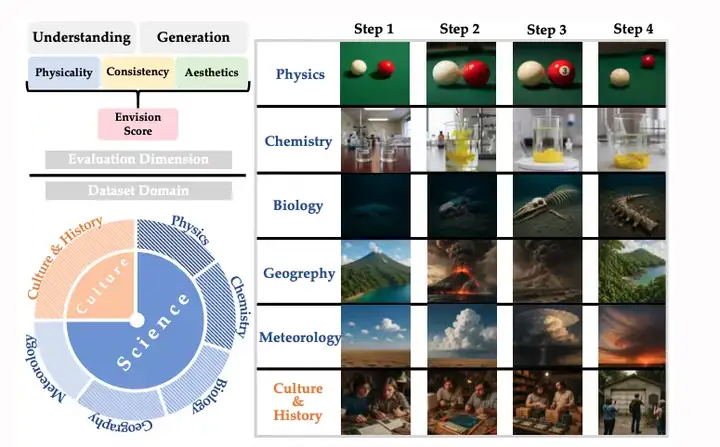
数据集示例
CARE-PD 包含 362 名受试者的步态数据,来源于 8 个临床机构、9 个独立队列,是目前公开规模较大的帕金森病三维步态数据集。所有原始视频与动作捕捉数据均被统一转换为匿名化的 SMPL 三维人体步态网格。数据集由 9 个子集构成,涵盖不同药物状态、步态亚型与临床评分信息,适合用于步态建模、疾病评估与跨队列分析研究。
* 在线使用:
https://go.openbayes.com/YrC2A
公共模型
*** 发布机构:**Meta AI
SAM 3 是新一代通用视觉分割模型,引入「可提示概念分割」机制,可通过自然语言或示例图像指定分割目标。模型能够在图像与视频中自动检测、分割并持续追踪同一概念下的所有实例,并具备良好的零样本泛化能力,同时扩展支持 3D 场景理解,在通用分割与复杂视觉理解任务中表现突出。
* 在线使用:https://go.openbayes.com/vpxfY
*** 发布机构:**阿里通义实验室
Z-Image-Turbo 总参数规模为 6B,基于单流扩散 Transformer(S3-DiT)架构,在极少采样步数下实现高质量图像生成。模型仅需约 8 步推理即可输出接近印刷级质量的图像,在推理速度与硬件成本方面具备显著优势,同时在中文提示词理解与中英文字渲染方面表现突出。
* 在线使用:https://go.openbayes.com/HGdWh
*** 发布机构:**Ovis
Ovis-Image-7B 是一款参数规模为 7B 的文本生成图像模型,针对文本渲染任务进行了专项优化。模型在文字密集、版式敏感的提示词场景中具备稳定表现,能够准确生成清晰可辨的文本内容,并兼顾整体视觉一致性,在较低资源条件下也具备良好的部署与推理效率。
* 在线使用:https://go.openbayes.com/cK8SC
*** 发布机构:**Mistral AI
Ministral-3-14B 是一款 14B 参数规模的多模态对话模型,在保持轻量化体量的同时实现了较强的指令遵循与多轮对话能力。模型支持较长上下文窗口,并在推理效率与部署友好性方面表现平衡,适合本地 AI 应用开发、对话系统构建与二次研究。
* 在线使用:https://go.openbayes.com/iITIL
*** 发布机构:**美团 LongCat 团队
LongCat-Image 是一款 6B 参数规模的图像生成与编辑基础模型,在中英文双语文本理解与文字渲染方面具备明显优势。模型在保持较高生成效率的同时,实现了真实感较强的视觉输出,并在多项生成与编辑任务中表现稳定,适合多语言内容生成与图像编辑场景。
* 在线使用:https://go.openbayes.com/PjpLD
* 发布机构:智谱 AI
Open-AutoGLM 是一款具备手机端操作能力的多模态智能体模型,能够理解真实手机屏幕内容并自动执行点击、滑动与输入等操作。模型采用「感知--规划--行动--反思」的执行框架,可稳定完成多步骤、跨应用的复杂任务,并支持敏感操作确认与人工接管,适用于移动端自动化与智能助理研究。
* 在线使用:https://go.openbayes.com/mn9Ot
*** 发布机构:**Microsoft
VibeVoice-Realtime-0.5B 参数规模为 0.5B,是一款专为超低延迟交互设计的实时文本转语音模型。该模型支持流式推理,可在约 300 毫秒内完成语音生成,并支持长时间音频输出与多说话人自然对话,在极低计算开销下实现高保真语音合成。
* 在线使用:https://go.openbayes.com/16kcX
8. Eigen-Banana-Qwen-Image-Edit
*** 发布机构:**Eigen AI
Eigen-Banana-Qwen-Image-Edit 是基于 Qwen-Image-Edit 的图像编辑 LoRA 权重,针对文本引导的高质量图像编辑任务进行了优化。模型在较少推理步骤下即可完成物体操作、风格迁移等多类编辑任务,并保持良好的编辑一致性,适合快速、交互式的图像编辑应用。
* 在线使用:https://go.openbayes.com/3xmgy
公共教程
RFdiffusion3 是一款全原子级蛋白质生成模型,能够在严格的空间与化学约束下直接建模分子间相互作用。模型支持精细到原子级的结构控制,可在设计阶段同时考虑稳定性、功能性与结合位点构型,在复杂生物分子设计任务中具备较强的生成能力与灵活性,适用于高精度蛋白设计与结构研究。
* 在线运行:
https://go.openbayes.com/STGlr
Open-AutoGLM 通过多模态模型对手机屏幕进行感知,并结合规划与执行机制实现端到端自动化操作。系统可在无需预定义脚本的情况下理解真实应用界面,并动态生成操作步骤,同时支持安全确认与人工介入,在复杂、多变的移动端场景中具备良好的泛化与可控性,适用于智能助理与自动化交互探索。
* 在线运行:
https://go.openbayes.com/3x4GU
MarkItDown 面向大模型应用场景设计,强调在文档转换过程中最大程度保留结构与语义信息。工具可稳定提取标题层级、列表关系、表格结构与链接引用,避免传统纯文本转换造成的信息丢失,使复杂文档更适合作为 LLM 的输入格式,适用于文档理解与知识处理流程。
* 在线运行:
https://go.openbayes.com/NuoO8
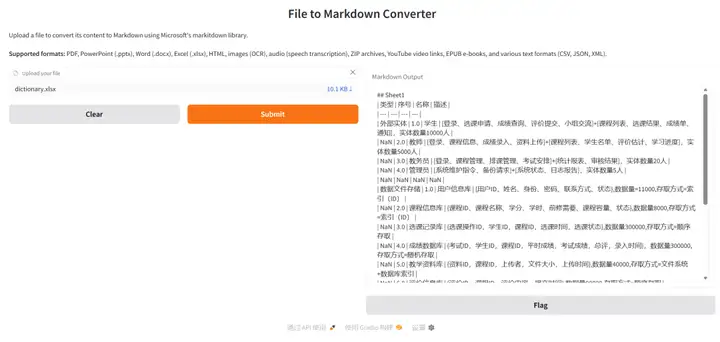
项目示例
LongCat-Image 是一款支持中英文双语的图像生成与编辑模型,在文本到图像生成任务中兼顾生成质量与效率。模型在中文文本渲染准确性与覆盖度方面表现突出,并在较小参数规模下实现高真实感的视觉输出,适用于多语言内容生成与视觉创作场景。
* 在线运行:
https://go.openbayes.com/t4VCv

项目示例
5. LightOnOCR-1B-Interface:面向复杂文档的高速 OCR 引擎
LightOnOCR-1B-Interface 基于端到端视觉--语言模型构建,可直接从高分辨率页面中完成布局感知文本解析。系统在表格、多栏排版与扫描文档等复杂结构下保持稳定表现,并兼顾处理速度与解析精度,适用于大规模文档解析与自动化 OCR 任务。
* 在线运行: