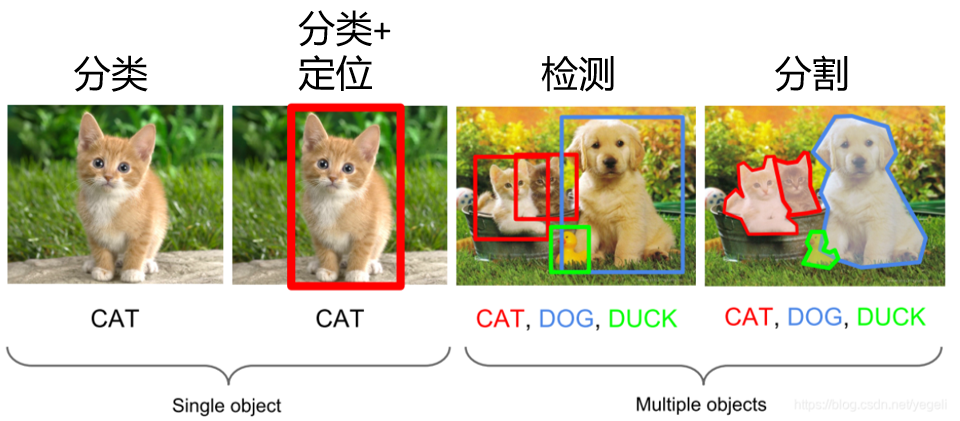
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置。目标检测是计算机视觉的核心任务,其目标是任务是找出图像中所有感兴趣的目标。以下面这个图为例,对于一个输入的 图像,目标检测的目的是在输入的图像有多个目标的情况下,准确识别出目标的个数,各个目标的种类,以及目标的位置。但是对于目标的具体形状,以及每个像素的归属,目标检测是不用做的。
传统目标检测
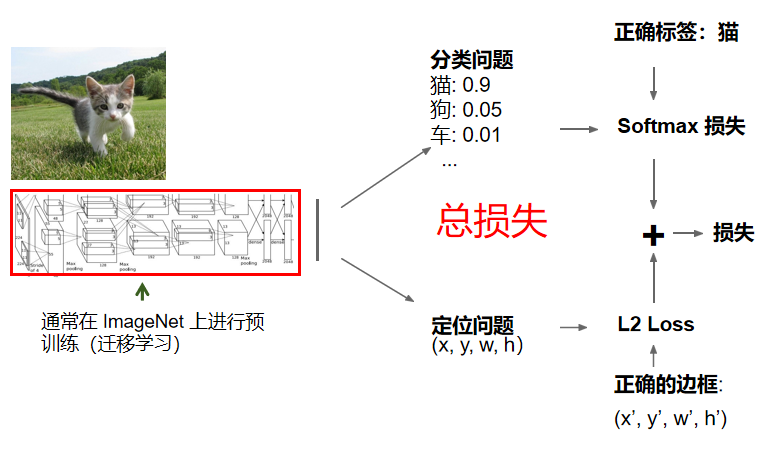
目标:图像识别+定位 方法:滑动窗口 + 特征提取 + SVM分类
核心内容:
- 突变检测:指在序列(如时间序列、图像像素序列、文本 token 序列)中,识别出与正常模式存在显著差异的 "突变片段",并确定其类别(如异常类型)和位置范围。
- 滑动窗口:将长序列切分为多个固定长度的重叠 / 非重叠子序列(窗口),每个窗口作为模型的基本输入单元,通过逐个分析窗口实现对全序列的突变扫描。
具体执行步骤
预处理 - 滑动窗口划分序列
- 确定窗口参数
- 设定窗口长度 L、步长 S。
- 步长越小,检测精度越高,但计算量越大;步长越大,效率越高,但可能漏检小范围突变。
- 序列分窗
- 从序列的起始位置开始,按步长 S 滑动窗口,生成 N 个窗口子序列 W1,W2,...,WN。
推理阶段 - 分类 + 定位
- 步骤 1:窗口分类识别(判 "是否突变 + 突变类型")
- 将每个窗口 Wi 输入分类网络,网络输出两个结果:
- 突变判定:二分类概率 Pmut(Wi);
- 类型分类:多分类概率分布 Ptype(Wi)。
- 输出窗口标签:对每个窗口标注
- 将每个窗口 Wi 输入分类网络,网络输出两个结果:
- 步骤 2:基于窗口标签定位突变区域
- 初步定位:筛选出所有标注为 "突变" 的窗口,记录其在原序列中的起始位置 starti 和结束位置 endi。
- 合并相邻突变窗口:若多个突变窗口存在重叠或连续,则合并为一个连续的突变区域,得到区域的总起始位置 starttotal=min(start3,start4,start5)、总结束位置 endtotal=max(end3,end4,end5)。
- 细化边界(可选):若需要更高精度的定位,可对合并后的突变区域边缘,用更小步长的窗口再次扫描,确定突变的精确起止点。
训练阶段 - 联合损失优化
训练的目标是让模型同时学会 "准确分类窗口" 和 "精准定位突变",因此需要设计分类损失 + 定位损失的联合损失函数。
- 损失函数构建总损失为分类损失与定位损失的加权和:Ltotal=λ1⋅Lcls+λ2⋅Lloc
- 分类损失 Lcls:衡量预测标签与真实标签的差异,常用 交叉熵损失。
-
二分类(是否突变):
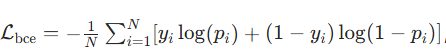
-
多分类(突变类型)
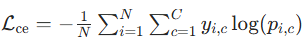 ,C 为类型数,yi,c 为独热标签。
,C 为类型数,yi,c 为独热标签。
-
- 定位损失 Lloc:衡量预测位置与真实位置的差异,常用 L1 损失 / 平滑 L1 损失。
- 若预测突变区域起止点 (startpred,endpred),则:
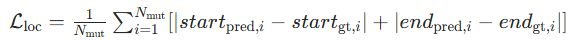 其中 Nmut 为突变窗口数量。
其中 Nmut 为突变窗口数量。
- 若预测突变区域起止点 (startpred,endpred),则:
- 权重系数 λ1,λ2:平衡两类损失的重要性(如分类任务优先级高则 λ1 取较大值)。
- 分类损失 Lcls:衡量预测标签与真实标签的差异,常用 交叉熵损失。
- 模型优化
- 反向传播总损失 Ltotal,更新主干网络和双分支的所有参数,实现分类和定位任务的协同优化。
但是,传统的方法有一个问题。如果遇到多目标的时候该怎么办?每一张图的目标数量不一定,就造成了网络训练与识别的困难。

在传统的方法中,只能不断地用滑动进行识别。这种方法的问题是,如何选择图块?目标可以以任意比例、任意大小出现。如果用蛮力把每种类型的窗口都滑动一遍,就需要很大的计算量,才能处理这个问题,计算的复杂度过高。
基于深度学习的目标检测方法
分类:
-
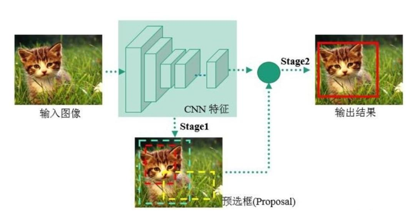
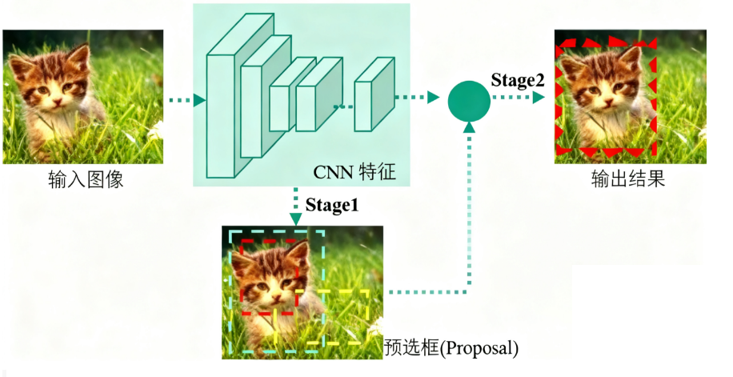
Two-Stage 先进行区域生成,该区域称之为region proposal(简称RP,一个有可能包含待检物体的预选框),再通过卷积神经网络进行样本分类。 任务流程:特征提取 -- 生成RP -- 分类/定位回归。 代表:R-CNN系列算法
-
-
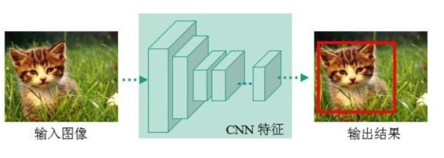
One Stage 不用RP,直接在网络中提取特征来预测物体分类和位置。 任务流程:特征提取-- 分类/定位回归。 代表:YOLO 系列、SSD、RetinaNet
-
R-CNN系列算法
R-CNN
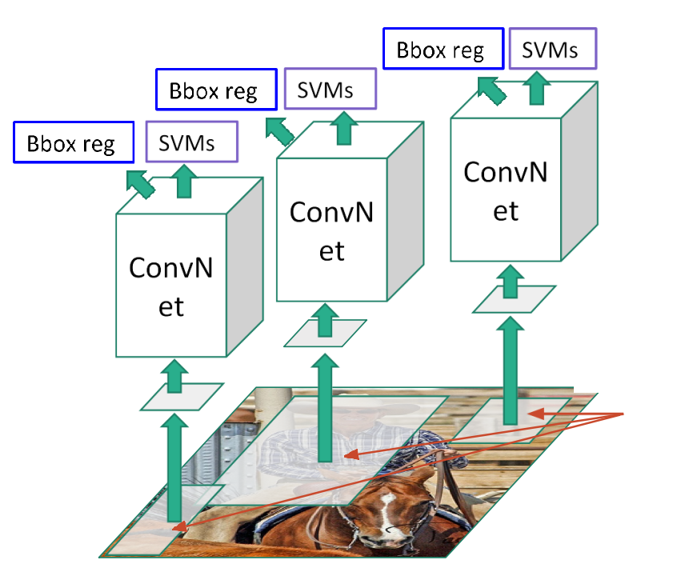
R-CNN(全称Regions with CNN features) ,是R-CNN系列的第一代算法,其实没有过多的使用"深度学习"思想,而是将"深度学习"和传统的"计算机视觉"的知识相结合。比如R-CNN pipeline中的第二步和第四步其实就属于传统的"计算机视觉"技术。使用selective search提取region proposals,使用SVM实现分类。
2013 年 R - CNN 提出,核心流程:
- 区域生成(Region Proposal):利用纹理、边缘、颜色等,找目标可能位置,生成预选框(RP)
- CNN 处理:用卷积神经网络,基于 RP 做特征提取、样本分类与定位回归
具体步骤
**步骤 1:生成候选区域(Region Proposal):**这一步的目标是从输入图像中,筛选出所有可能包含目标的区域,过滤掉明显的背景区域。
- 算法选择:采用传统的选择性搜索(Selective Search) 算法。
- 具体操作
- 对输入图像进行过分割,生成大量小的初始区域
- 按照相似度准则,逐步合并相似的小区域,形成不同尺度、不同形状的候选区域。
- 最终输出 约 2000 个候选区域,这些区域覆盖了图像中几乎所有可能存在的目标。
- 关键特点:候选区域的形状和大小是不规则的,且数量固定,解决了目标尺度变化的问题。
**步骤 2:候选区域的归一化处理:**CNN 的输入要求固定尺寸,但步骤 1 生成的候选区域尺寸、形状各不相同,因此需要做归一化:
- 对每个候选区域,采用变形缩放的方式,将其调整为 CNN 要求的固定尺寸
- 注意:这种变形可能会导致目标的几何形变,但在当时是兼顾效率和精度的折中方案。
**步骤 3:CNN 特征提取:**这一步是 R-CNN 的核心,用预训练的 CNN 对每个归一化后的候选区域提取特征。
- 预训练 CNN 初始化
- 采用在 ImageNet 数据集上预训练好的分类网络,去掉网络的最后一层全连接层和 Softmax 层。
- 特征提取
- 将每个归一化后的候选区域图像,输入到预训练的 CNN 中。
- 取 CNN 最后一个全连接层的输出作为该候选区域的特征向量
- 生成 特征矩阵。
**步骤 4:分类 + 边界框回归(Bounding Box Regression):**这一步分为两个并行的子任务:判断候选区域的目标类别,以及修正候选区域的位置,实现精准定位。
- 分类任务:SVM 分类器
- 由于 CNN 预训练的类别与目标检测的类别不一致,R-CNN 采用支持向量机(SVM) 做分类,而非直接用 CNN 分类。
- 操作流程:
- 对每个目标类别(如人、车、猫),训练一个二分类 SVM(区分 "该类目标" 和 "背景")。
- 将步骤 3 提取的 4096 维特征向量,输入到所有类别的 SVM 中。
- SVM 输出该候选区域属于每个类别的得分,得分超过阈值的候选区域被判定为对应类别。
- 边界框回归任务:回归器修正位置
选择性搜索生成的候选区域位置并不精准,因此需要用回归器修正边界框坐标。
- 操作流程:
- 对每个目标类别,训练一个线性回归器。
- 回归器的输入:候选区域的 4096 维特征向量 + 候选区域的原始坐标 (x1,y1,x2,y2)
- 回归器的输出:边界框的偏移量 (Δx,Δy,Δw,Δh),用于修正原始坐标,得到精准的目标框。
- 修正公式:通过偏移量计算最终的目标框坐标,使预测框更贴近真实框。
- 非极大值抑制(NMS)
同一目标可能会被多个候选区域检测到,导致重复框。因此需要执行非极大值抑制:
- 对同一类别的所有预测框,按分类得分排序。
- 保留得分最高的框,删除所有与该框交并比(IoU) 超过阈值的重复框。
- 最终输出每个目标的唯一精准检测框。
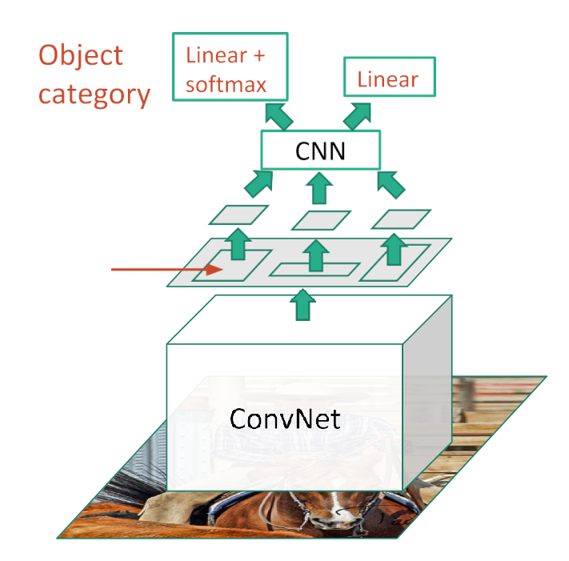
Fast R-CNN
Fast R-CNN 是对 R-CNN 的核心改进版本,其核心目标是 解决 R-CNN 重复计算、训练繁琐、内存占用大的问题,通过共享卷积特征和端到端训练,在保证精度的同时,将检测速度提升了一个数量级。
1.R-CNN 的问题:对输入图像生成约 2000 个候选区域后,需要逐个将候选区域缩放到固定尺寸,再输入 CNN 提取特征。这意味着 2000 个候选区域要重复运行 2000 次 CNN,计算量巨大且高度冗余。
Fast R-CNN 的解决方案:
这一改进将 CNN 计算量从 O(2000×CNN计算量) 降至 O(1×CNN计算量),效率提升显著。
-
对整张输入图像只运行 1 次 CNN,得到一张共享的卷积特征图(Feature Map),避免重复计算。
-
用选择性搜索生成 2000 个候选区域后,直接在卷积特征图上截取对应区域(而非原始图像),得到候选区域的特征矩阵。
-
引入 ROI Pooling 层:由于不同候选区域在特征图上的尺寸不同,ROI Pooling 会将每个候选区域的特征矩阵统一池化为固定尺寸(如 7×7),满足后续全连接层的输入要求。
-
-
端到端训练,简化训练流程
R-CNN 的训练分为三步独立流程,步骤繁琐且需要存储大量中间特征:
- 预训练 CNN → 2. 用 CNN 提取所有候选区域的特征并保存 → 3. 分别训练 SVM 分类器和边界框回归器。
Fast R-CNN 将分类和回归任务整合到同一个网络中,实现端到端训练:
-
网络结构:共享卷积层 → ROI Pooling → 全连接层 → 两个并行分支
-
分类分支:输出候选区域属于 K+1 类的概率(K 个目标类 + 1 个背景类),用交叉熵损失训练,替代了 R-CNN 的 SVM 分类器。
-
回归分支:对每个目标类,输出边界框的 4 个偏移量 (Δx,Δy,Δw,Δh),用平滑 L1 损失训练,与分类分支共享全连接层特征。
-
-
总损失函数:将分类损失和回归损失加权求和,一次反向传播即可更新所有参数:Ltotal=Lcls(p,u)+λu≥1Lloc(tu,v)其中 u≥1 表示仅对目标类(非背景)计算回归损失,λ 为平衡系数。
- 用 Softmax 分类替代 SVM,无需额外存储特征
-
R-CNN 中,CNN 仅作为特征提取器,分类任务需要单独训练 SVM,且必须将所有候选区域的特征向量保存到硬盘,占用大量存储空间。
-
Fast R-CNN 直接在网络中用 Softmax 层完成分类,分类器与网络其他部分一起训练,无需额外存储中间特征,节省内存的同时简化了流程。
- 支持多尺度训练,提升检测精度
Fast R-CNN 支持在训练时输入不同尺度的图像,生成不同尺度的卷积特征图。
-
多尺度训练可以让模型适应不同大小的目标,提升对小目标和大目标的检测能力。
-
R-CNN 由于候选区域需要固定尺寸输入,难以高效实现多尺度训练。
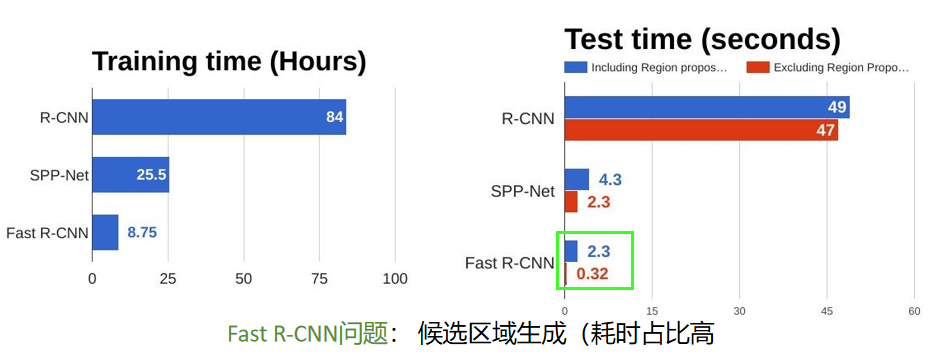
Fast R-CNN 对比 R-CNN
Faster R-CNN
Faster R-CNN 是 2015 年提出的目标检测算法,它在 Fast R-CNN 的基础上,解决了 "候选区域生成速度慢" 的核心痛点,通过引入 RPN(Region Proposal Network,区域建议网络) 替代传统的选择性搜索,实现了真正端到端的目标检测,将检测速度和精度提升到了新的高度。
其核心思想是:用深度神经网络自主生成高质量候选区域,与检测网络共享卷积特征,实现候选区域生成 + 目标分类 + 边界框回归的端到端联合训练。
一、Faster R-CNN 核心改进点(相对于 Fast R-CNN)
Fast R-CNN 的最大瓶颈是:候选区域仍由选择性搜索 生成,这是一个传统的非深度学习方法,速度慢且无法与网络联合优化。Faster R-CNN 的核心改进就是 用 RPN 替代选择性搜索 ,并实现 RPN 与检测网络的卷积特征共享。
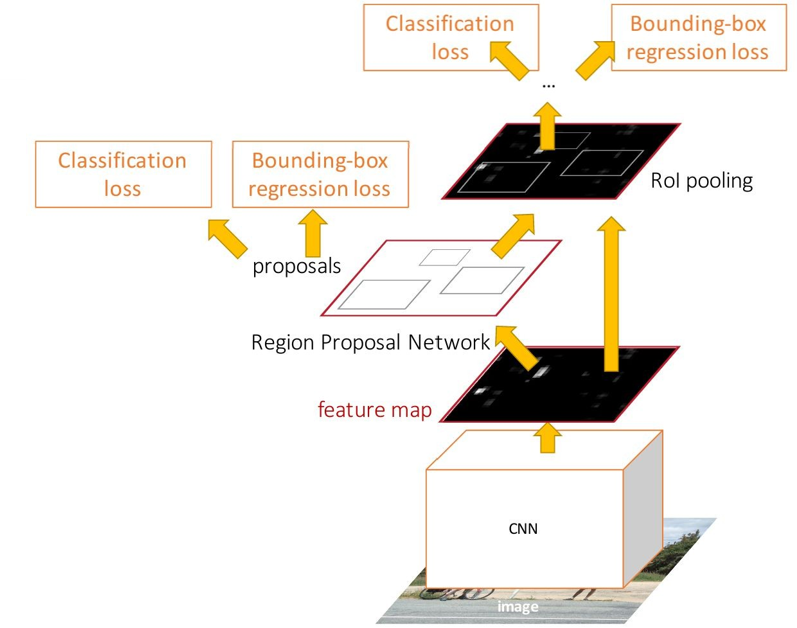
二、Faster R-CNN 完整算法流程
Faster R-CNN 的整体架构可分为 4 个核心模块,且所有模块共享同一套卷积特征图:
-
共享卷积层
-
RPN 模块(生成候选区域)
-
ROI Pooling 层(特征归一化)
-
检测头(分类 + 边界框回归)
-
共享卷积层:提取全局特征
与 Fast R-CNN 一致,对整张输入图像 只运行一次卷积神经网络(如 VGG16、ResNet),生成一张高维的共享卷积特征图。这一步的作用是为后续的 RPN 和检测头提供统一的特征输入,避免重复计算。
- RPN 模块:生成高质量候选区域
RPN 是一个轻量级的全卷积网络(FCN),直接作用在共享卷积特征图上,自主生成候选区域,无需任何传统方法介入。
(1)RPN 的核心组件
-
锚点(Anchor)机制:
-
对卷积特征图上的每个像素点 ,预设 k 个不同尺度、不同宽高比的锚点框(论文中 k=9:3 个尺度 {1282,2562,5122} × 3 个宽高比 {1:1,1:2,2:1})。
-
锚点框对应到原始图像上,覆盖了不同大小、不同形状的潜在目标区域,解决了目标尺度变化的问题。
-
-
两个并行分支:RPN 的卷积层输出特征后,接两个 1×1 卷积分支:
-
分类分支:输出每个锚点框是 "前景(包含目标)" 还是 "背景" 的概率,维度为 2k(2 类 × k 个锚点)。
-
回归分支 :输出每个锚点框的边界框偏移量 (Δx,Δy,Δw,Δh),用于修正锚点框的位置,维度为 4k(4 个偏移量 × k 个锚点)。
-
(2)RPN 的训练目标
-
分类损失:采用交叉熵损失,区分前景 / 背景锚点。
-
回归损失:采用平滑 L1 损失,仅对前景锚点计算(背景锚点无需回归)。
-
RPN 的损失函数:Lrpn=Ncls1Lcls(pi,pi∗)+λNreg1∑i∈fgLreg(ti,ti∗)其中 pi 是预测概率,pi∗ 是真实标签(前景 = 1,背景 = 0);ti 是预测偏移量,ti∗ 是真实偏移量;λ 是平衡系数。
(3)候选区域生成
RPN 输出所有锚点框的前景概率和修正偏移量后,执行两步筛选:
-
保留前景概率高于阈值的锚点框,修正其位置得到初步候选区域。
-
对候选区域执行非极大值抑制(NMS) ,去除重复框,最终输出约 2000 个高质量候选区域。
-
ROI Pooling 层:特征归一化
与 Fast R-CNN 完全一致:
-
将 RPN 生成的候选区域,映射到共享卷积特征图上,截取对应的特征区域。
-
对每个特征区域执行池化操作,统一缩放到固定尺寸(如 7×7),满足后续全连接层的输入要求。
- 检测头:分类 + 边界框回归
与 Fast R-CNN 的检测模块一致,包含两个并行分支:
-
分类分支:对每个候选区域,输出其属于 K+1 类(K 个目标类 + 1 个背景类)的概率,用交叉熵损失训练。
-
回归分支:对每个目标类,输出候选区域的边界框偏移量,用平滑 L1 损失训练,仅对目标类计算损失。
-
总损失函数 :Faster R-CNN 的总损失是 RPN 损失 + 检测头损失 的加权和,实现端到端联合优化:
Ltotal=Lrpn+Ldet
YOLO系列
R-CNN系列曾算法在目标检测领域独占鳌头。2016年,一种单阶段(one-stage)的目标检测网络被提出,作者将其取名为:You Only Look Once(简称YOLO)。YOLOv1每秒可以处理45帧图片,其速度之快和其使用的特殊方法引起了广泛地关注。
其核心思想是:将目标检测任务转化为一个端到端的回归问题,输入图像经过一次卷积网络后,直接输出固定数量的边界框及其类别概率。
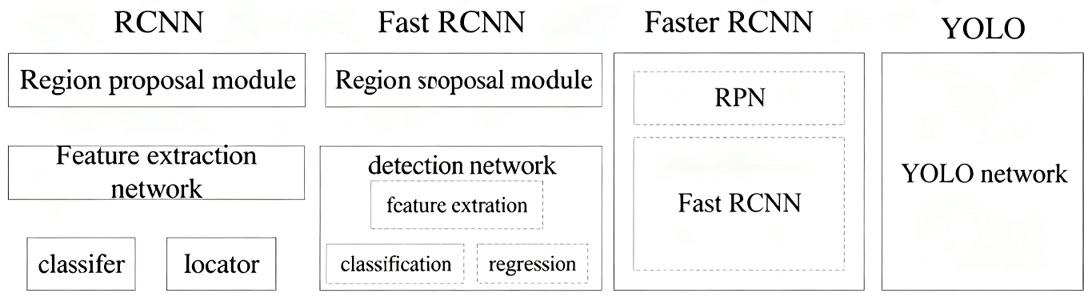
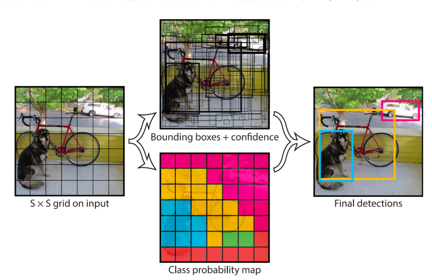
YOLO创造性的将物体检测任务直接当作回归问题(regression problem)来处理,将候选区和检测两个阶段合二为一。只需一眼就能知道每张图像中有哪些物体以及物体的位置。下图展示了各物体检测系统的流程图。
YOLO v1 核心算法流程
YOLO v1 是该系列的奠基版本,后续 v2、v3、v5 等版本均基于其核心思想优化,以下以 v1 为例介绍完整流程。
- 输入图像预处理
将输入图像统一缩放到固定尺寸 448×448,消除尺寸差异对模型的影响。
- 卷积特征提取
采用自定义的卷积神经网络(由 24 个卷积层 + 2 个全连接层组成)对预处理后的图像进行特征提取:
-
卷积层:负责提取图像的语义特征(如边缘、纹理、目标轮廓);
-
全连接层:将卷积特征图映射为一个 7×7×30 的输出张量。
- 网格划分与预测原理
这是 YOLO 的核心创新点:
-
网格划分 将 448×448 的输入图像划分为 S×S 的网格(YOLO v1 中 S=7)。
-
每个网格的尺寸为 64×64(448/7=64);
-
规则:若目标的中心点落在某个网格内,则该网格负责预测这个目标。
-
-
预测张量解析输出张量 S×S×30 的含义为:
-
每个 7×7 的网格,输出一个 30 维的向量;
-
这 30 维向量包含两类信息:
-
2 个边界框参数:每个网格预测 2 个边界框,每个框包含 5 个参数 (x,y,w,h,conf),共 2×5=10 维。
-
x,y:边界框相对于当前网格左上角的偏移量(取值范围 0,1);
-
w,h:边界框的宽和高相对于整张图像的比例(取值范围 0,1);
-
conf:置信度,反映该框包含目标的概率 + 框的定位精度,公式为:
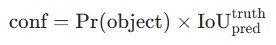 若网格内无目标,则 conf=0;否则为预测框与真实框的交并比(IoU)。
若网格内无目标,则 conf=0;否则为预测框与真实框的交并比(IoU)。
-
-
20 个类别概率:预测该网格内目标属于 VOC 数据集 20 类的概率 Pr(Classi∣object),共 20 维。
-
-
-
最终置信度计算 每个边界框的类别置信度 = 类别概率 × 边界框置信度,公式为:
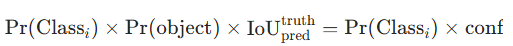 该值同时反映 "框内是某类目标的概率" 和 "框的定位准确度"。
该值同时反映 "框内是某类目标的概率" 和 "框的定位准确度"。 -
后处理:非极大值抑制(NMS)
模型会输出 7×7×2=98 个边界框,其中大部分是冗余或低置信度的框,需要 NMS 筛选:
-
过滤低置信度框:设定置信度阈值(如 0.5),剔除阈值以下的框;
-
按类别置信度排序:对剩余的框按类别分组,每组内按置信度从高到低排序;
-
剔除重复框:保留置信度最高的框,删除所有与该框 IoU 超过阈值(如 0.5)的重复框;
-
输出最终检测结果:每个目标对应一个最优边界框和类别。
-
二、YOLO 的损失函数
YOLO v1 的损失函数设计复杂,目的是平衡分类、定位和置信度的误差,总损失公式为:
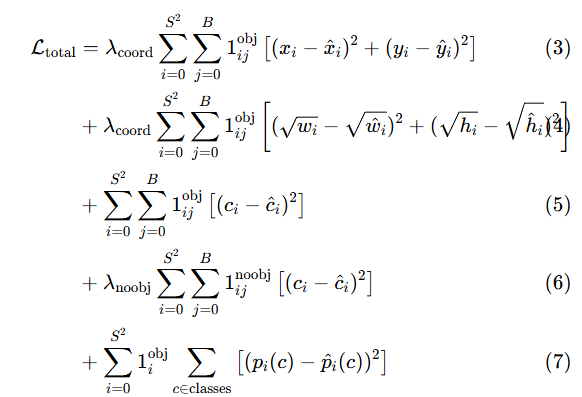
其中关键参数:
-
λcoord=5:提升定位损失的权重;
-
λnoobj=0.5:降低无目标框的置信度损失权重;
-
1ijobj:指示函数,网格 i 的第 j 个框负责预测目标时为 1,否则为 0。
YOLOv3
网络结构
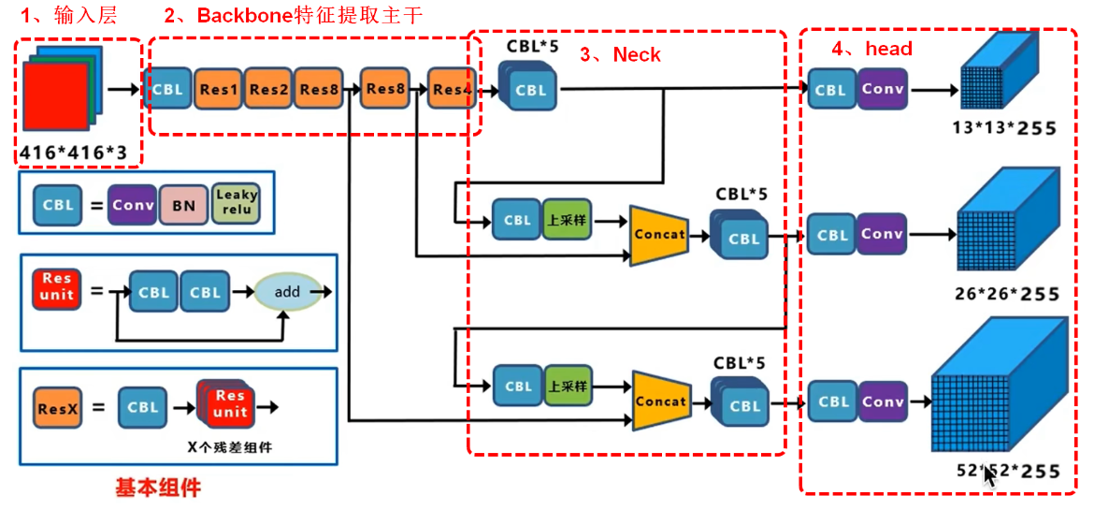
Backbone
- 负责特征提取
- 使用 Darknet-53 作为骨干网络,有 53 层卷积层,采用残差结构
- 不同层次的网络提取不同的特征,,保留空间信息。
Neck
- 负责特征融合
- 采用卷积层、特征金字塔网络等,融合多尺度特征。 从 Backbone 的 3 个不同尺度的特征图输出增强对不同大小目标的检测能力
Head
- 负责检测预测
- 处理neck提供的特征,每个尺度的特征图输出固定数量的先验框,包括边框的坐标、置信度和类别概率。
- 对每个尺度分别进行预测,最后再通过 非极大值抑制(NMS) 去除重复框
更多模型和应用
DenseCap
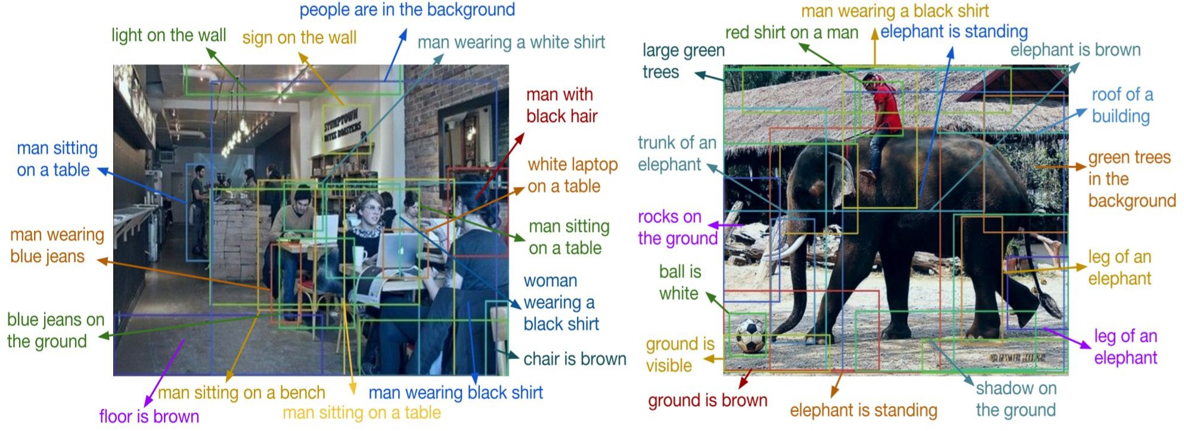
DenseCap 是由李飞飞等人在 CVPR 2016 提出的一个视觉与语言结合的里程碑项目。它的核心目标是:在图像中自动检测出多个有意义的区域,并为每个区域生成自然语言描述。这与传统的图像描述(整张图像一句话)不同,DenseCap 要求对图像进行细粒度理解,因此也被称为 密集图像描述。
- 密集图像描述
- 检测目标区域 + 对每个区域生成文字描述
基于RGB图像的3D目标检测
基于RGB图像的3D目标检测有好几个项目在做,就不一一列举了。三维检测比二维要难得多。2D 目标检测:仅需预测目标在图像平面的2D 边界框(x,y,w,h)。而3D 目标检测:需构建3D 有向边界框(x,y,z,w,h,l,r,p,y) ,不仅要定位目标在空间中的 3D 坐标(x,y,z)、尺寸(w,h,l,即宽高深 ),还要预测姿态角(roll 翻滚、pitch 俯仰、yaw 偏航 ),精准描述目标在真实世界的 "位置、大小、朝向"。由于 3D 检测需从 2D 图像反推三维空间信息,且要解算更多维度参数(如深度、姿态),其技术难度远高于 2D 目标检测,是计算机视觉在自动驾驶、智能交通等场景落地的关键挑战之一。
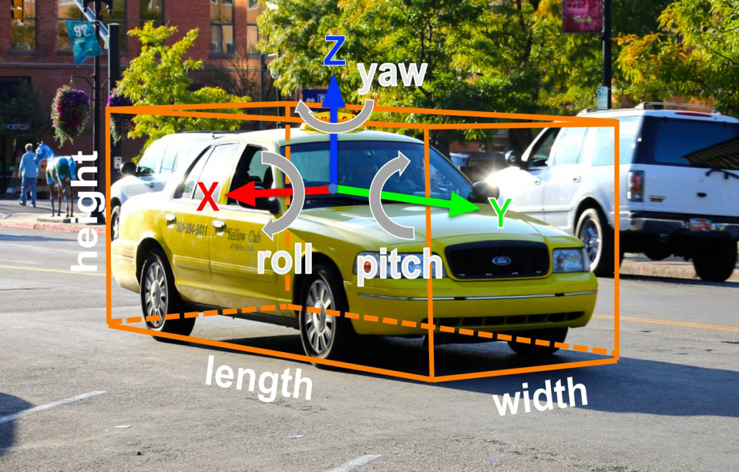
- 2D 目标检测
- 2D 边界框
- (x,y,w,h) 3D 目标检测 3D 有向边界框
- (x,y,z,w,h,l,r,p,y) 简化版边界框: 无翻滚角与俯仰角 比 2D 目标检测困难得多
基于RGB图像的3D目标检测
这是三维检测中比较常用的简单的相机模型。通过图中的透视等等来估计检测框的方位和形状。
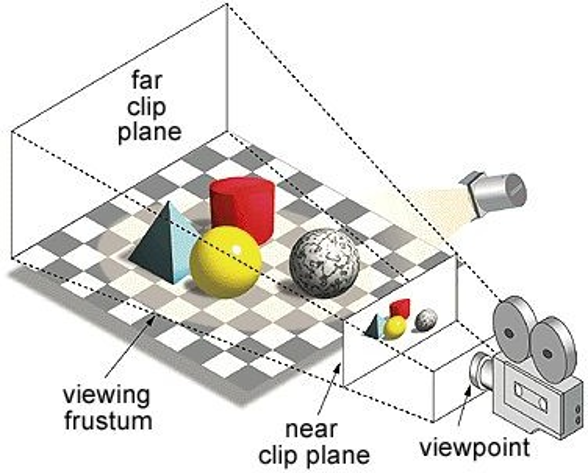
- 图像平面上的一个点对应三维空间中的一条射线 。
- 图像上的一个二维边界框对应三维空间中的一个视锥 。
- 三维空间中定位物体:物体可能位于相机视锥内的任意位置
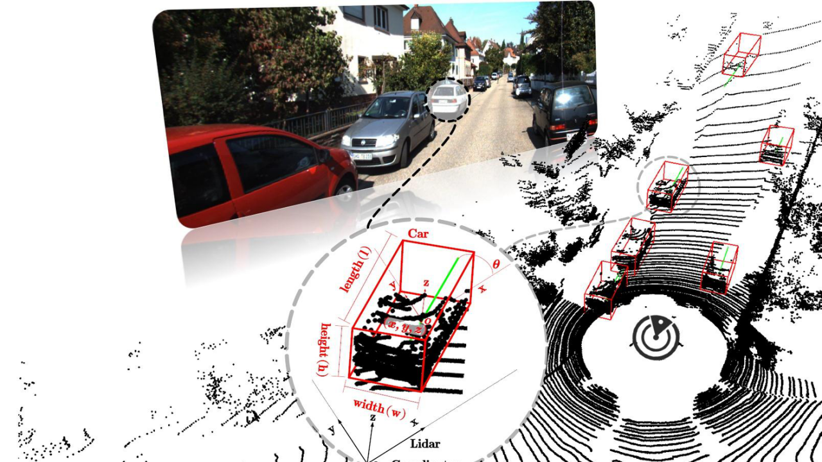
OpenPCDet
在三维空间里做目标检测:雷达点云检测
刚才介绍的都是在二维中进行图像分割。在无人驾驶领域里,在三维中应用检测也是十分有价值的一件事情。许多无人驾驶依赖雷达传感器,而雷达通常生成的都是三维的点云图像。OpenPCDet是一款比较经典的雷达点云检测模型 (不过雷达点云检测还算cv的范畴吗?)