引言
Post-Training(即模型后训练)作为大模型落地的重要一环,能显著优化模型性能,适配特定领域需求。相比于 Pre-Training(即模型预训练),Post-Training 阶段对计算资源和数据资源需求更小,更易迭代,因此备受推崇。
近期,我们将体系化地分享基于阿里云人工智能平台 PAI 在强化学习、模型蒸馏、数据预处理、SFT等方向的技术实践,旨在清晰地展现 PAI 在 Post-Training 各个环节的产品能力和使用方法,欢迎大家随时交流探讨。
对于大模型而言,预训练由于对算⼒和数据的需求非常⼤,因此在使用大模型时,用户一般不会涉及到预训练,更多的是基于开源的预训练基础模型(如Qwen、DeepSeek、Llama等)做模型微调。
本期介绍常见的模型微调训练方式,以及如何使用阿里云人工智能平台 PAI 的产品模块实现模型微调。
常用模型微调训练方式
模型微调的目的是让模型更好地理解特定任务的需求。例如,通过使用对话数据集对模型进行微调,可以让模型在遇到问题时生成更相关的答案。
广义上说,模型微调有多种方式,常见的如监督微调、偏好对齐、强化学习微调等。下面我们介绍几种现在常用的微调算法。
SFT
SFT(Supervised Fine-Tuning,监督微调)是在预训练模型的基础上,使⽤特定任务的标注数据进⾏⼆次训练,使模型能够更好地适应⽬标任务的需求。其核⼼思想是"迁移学习",利⽤预训练模型已有的知识,通过微调快速适配新任务。
SFT需要使用有标注的数据通过有监督方式微调模型,这些标注数据通常包含了问题和答案对,或者其他特定任务的数据。
SFT根据更新参数量不同可以分为以下两种:
-
全量参数更新 FFT(Full Fine-tuning):即对预训练模型的所有参数进⾏更新,训练速度较慢,消耗机器资源较多。
-
参数⾼效微调 PEFT(Parameter-Efficient Fine-Tuning):只对部分参数做调整,训练速度快,消耗机器资源少。常见的如LoRA微调、QLoRA微调。
-
LoRA微调:在固定模型本身参数的基础上,仅对自注意力权重矩阵进行低秩分解,并更新低秩矩阵参数。该训练方法训练时间短,但效果可能会略差于全参微调,但在某些情况下可减少训练过拟合的风险。
-
QLoRA微调:QLoRA结合了模型量化和LoRA技术,除了引入LoRA旁路矩阵,QLoRA在加载时将大模型量化为4bit或8bit,相比LoRA微调进一步降低了显存占用。该训练方法训练时间短,但效果可能会略差于全参微调和LoRA。
DPO
偏好对齐也是一种微调模型的方式,目的是使大模型的输出更符合人类偏好,常用于对齐人类价值观(如减少有害内容)或提升生成结果的可读性、安全性。
DPO(Direct Preference Optimization,直接偏好优化)是一种现在常用的偏好对齐方式。大模型对齐方法有多种,如ChatGPT使用的RLHF,但RLHF较为复杂且缺乏稳定性。相比之下,DPO算法简化了这一过程:它不需要训练专门的奖励模型,而是通过简单的分类损失来解决标准的RLHF问题。DPO算法不仅具有良好的稳定性和卓越的性能,而且计算需求较低。
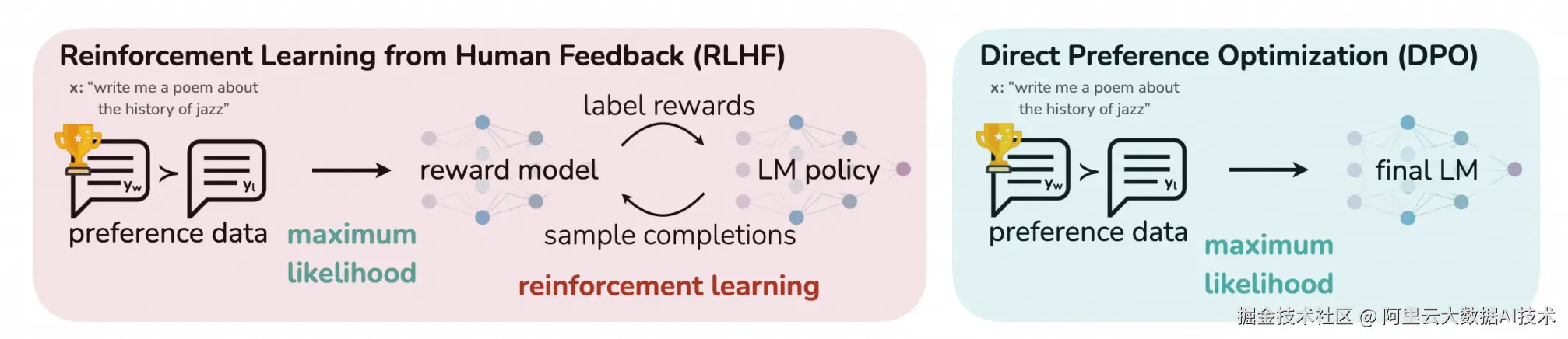
上图左侧展示了RLHF算法,而右侧则是DPO算法,通过两者的对比可以清楚地看到DPO的改进之处。
-
RLHF算法包含了奖励模型和策略模型,通过偏好数据结合强化学习进行不断迭代,以优化策略模型。
-
DPO算法去掉了奖励模型和强化学习过程,直接利用偏好数据进行模型微调,将强化学习过程简化为监督微调,从而使训练过程更加简单和高效,其主要改进集中在损失函数方面(即DPO使用监督学习的训练方式,达到了接近RLHF类似的效果)。
目前较常见的微调方式可以是先对基模进行SFT,然后再进行DPO,从而使模型具备业务领域能力同时输出符合价值观偏好。
GRPO
随着DeepSeek-R1模型的爆火,GRPO技术也收到业界的广泛关注(GPRO:Group Relative Policy Optimization,群组相对策略优化)。GRPO旨在通过优化模型在一组候选答案中的相对偏好,而不是依赖于单一的"黄金"答案来进行学习,从而提升模型的性能,尤其在数学推理等复杂任务上。
相比于PPO等传统算法,GRPO算法具备以下特点:
-
不需要单独的价值函数模型(Value Model):不同于PPO,GRPO无需维护单独的价值函数模型,简化了训练步骤,减少了内存消耗,提高了整体效率。
-
基于组的优势计算:GRPO通过为每个输入利用一组输出来计算基线奖励(Baseline Reward),计算方法为该组输出的平均得分。这种组基方法与奖励模型训练更加契合,尤其对推理任务有所帮助。
-
直接优化KL散度:GRPO将KL散度直接集成到损失函数中进行优化,实现比PPO中通过奖励信号间接控制更细致的管理。
微调算法比较
以下为 SFT、DPO和GRPO 这三种微调算法的使用门槛难度以及应用场景对比,供您参考比较。 
PAI模型微调实践
阿里云人工智能平台PAI提供了完整的模型微调产品能力,根据客户需求及代码能力层级,分别提供了PAI-Model Gallery 一键微调、PAI-DSW Notebook编程微调、PAI-DLC容器化任务微调的全套产品功能。
PAI-Model Gallery
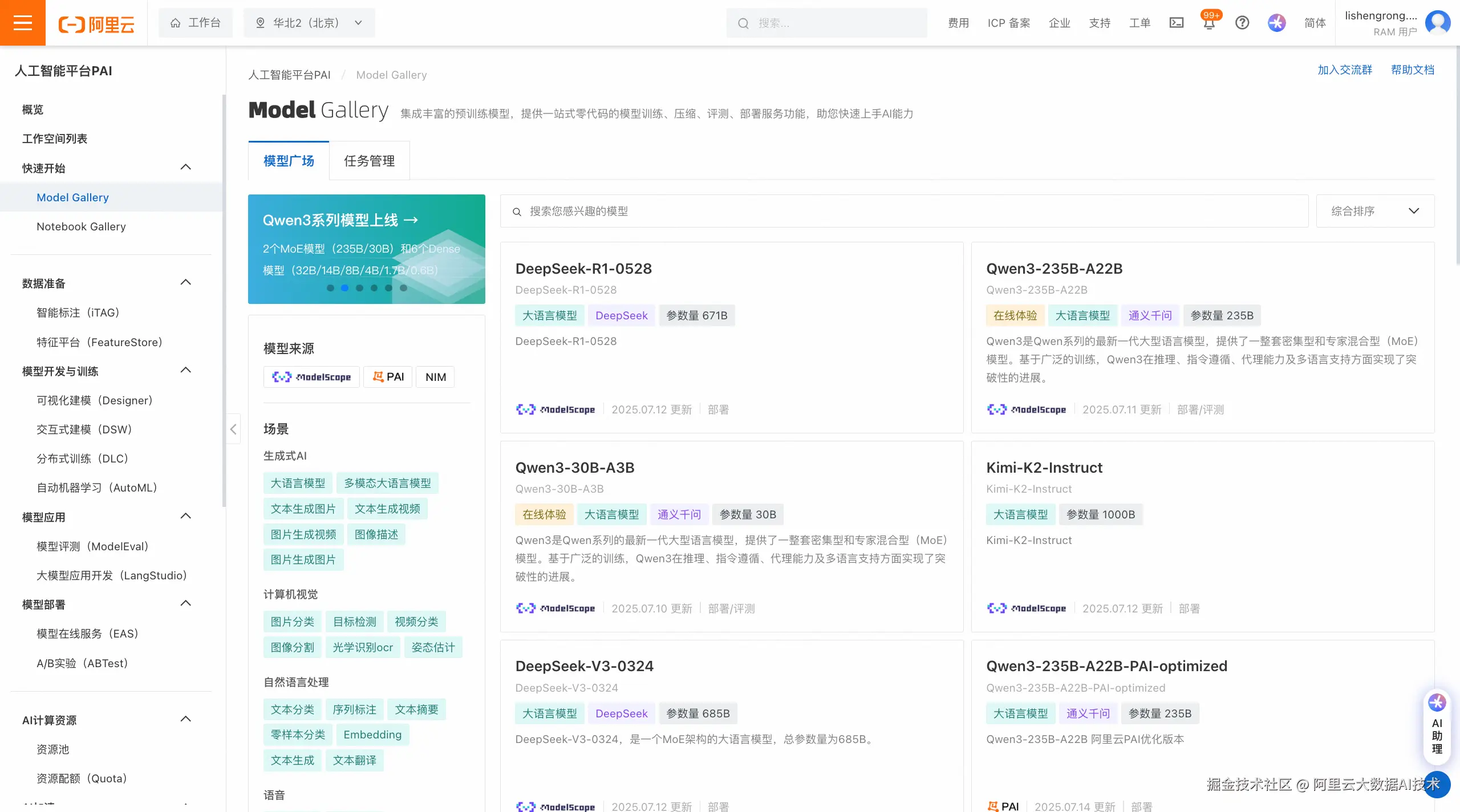
PAI-Model Gallery集成了众多AI开源社区中优质的预训练模型,支持零代码实现模型微调、模型压缩、模型评测、模型部署操作,给开发者带来更快、更高效、更便捷的AI应用体验。对于希望零代码完成模型微调的用户来说,PAI-Model Gallery的一键微调功能是您的理想选择。
-
选择想要微调的基础模型。PAI-Model Gallery提供了丰富的基础模型,您可以在模型广场浏览并选择您想要微调的基础模型,点击模型卡片进入模型详情页。
-
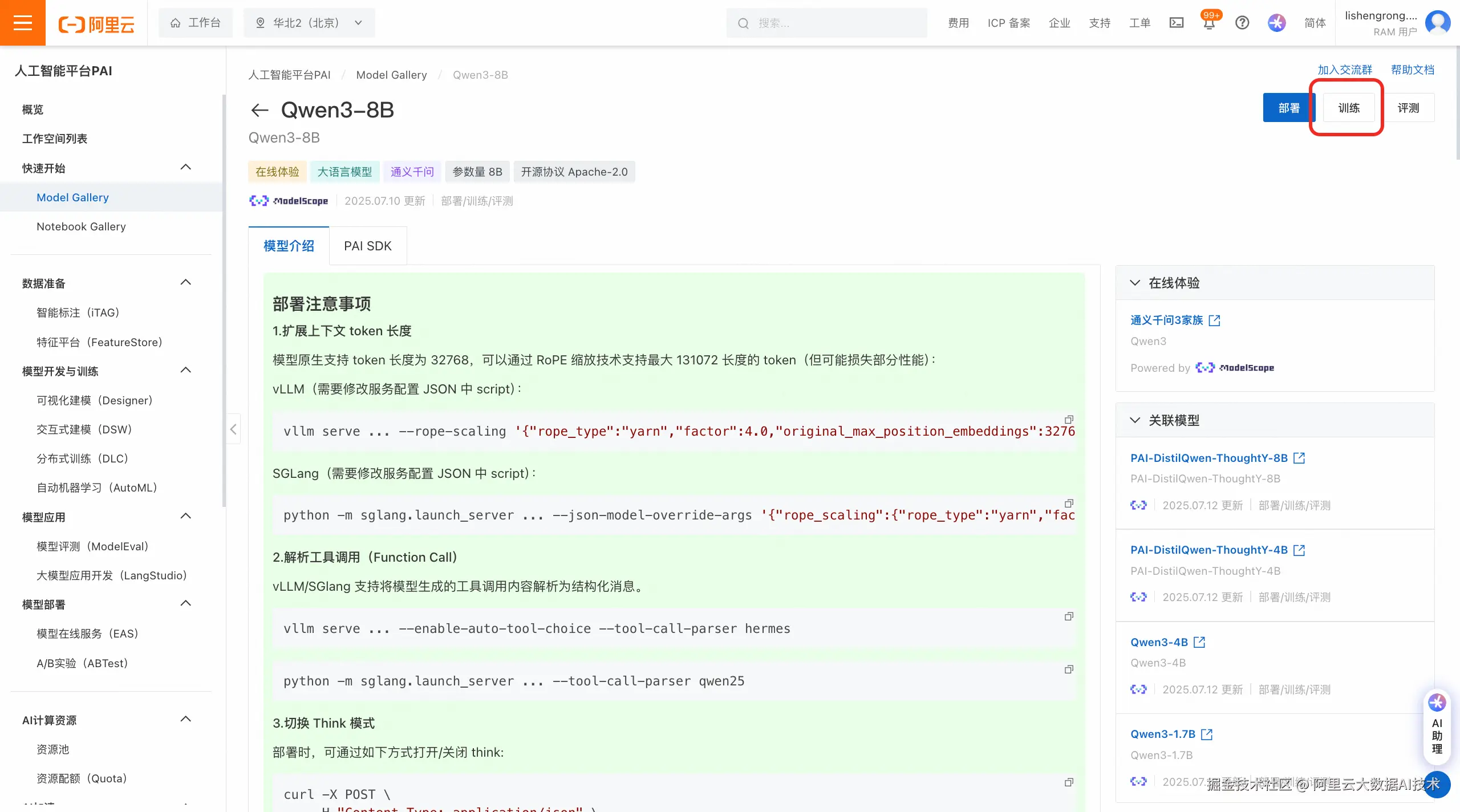
在模型详情页点击"训练"按钮。我们以Qwen3-8B模型为例,模型支持零代码完成部署、训练和评测,详情页右上角有对应的操作按钮,选择点击"训练"按钮。
-
提交训练任务。PAI-ModelGallery 支持 SFT、GRPO 等多样化的训练方式,按需选择训练方式、配置训练数据集、配置训练超参数、计算资源后,即可一键提交训练任务。
(注:不同模型提供的训练方式有所不同,具体请参照各模型详情页) 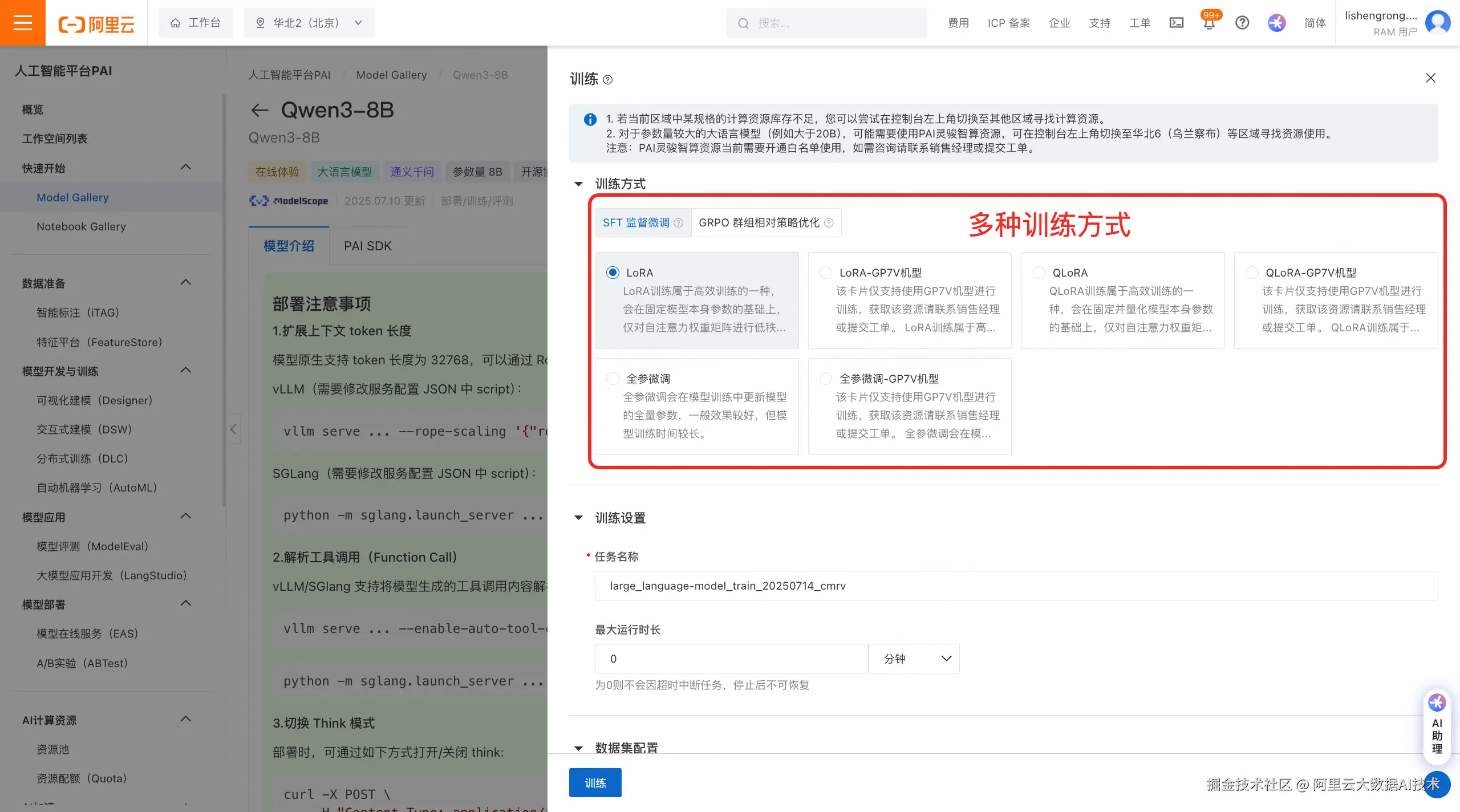
需注意的是,您需要提前准备好训练用的数据集。以SFT任务为例,训练数据集格式示例如下:(不同类型训练任务的训练集格式示例可参考模型详情页中的描述)
[
{
"instruction": "你是一个心血管科医生,请根据患者的问题给出建议:我患高血压五六年啦,天天喝药吃烦啦,哪种东西能根治高血压,高血压克星是什么?",
"output": "高血压的患者可以吃许多新鲜的水果蔬菜或者是芹菜山药之类的食物,可以起些降血压的作用,另外高血压的患者平时也应当注意低盐,低脂,低胆固醇饮食,适当的实施体育运动和锻练高血压的患者还应当在医生的指导下口服降血压的药物,断然不可擅自停药,防止对血压引发影响。"
},
{
"instruction": "你是一个呼吸科医生,请根据患者的问题给出建议:风寒感冒咳白痰怎么治疗?",
"output": "风寒感冒,咳有白痰的患者,主要症咳嗽痰多色白量多,兼具胸脘作闷,鼻塞,流清涕,全身酸痛,易疲劳等症状。临床诊断上常用杏苏散和二陈丸实施治疗。在用药物治疗的同时,应忌食辛辣刺激性的食物和寒凉性食物,多吃易消化营养丰富的食物,宜清淡饮食,留意歇息。"
}
]关于训练超参数的介绍和如何调整,可参考文档:help.aliyun.com/zh/pai/user...
-
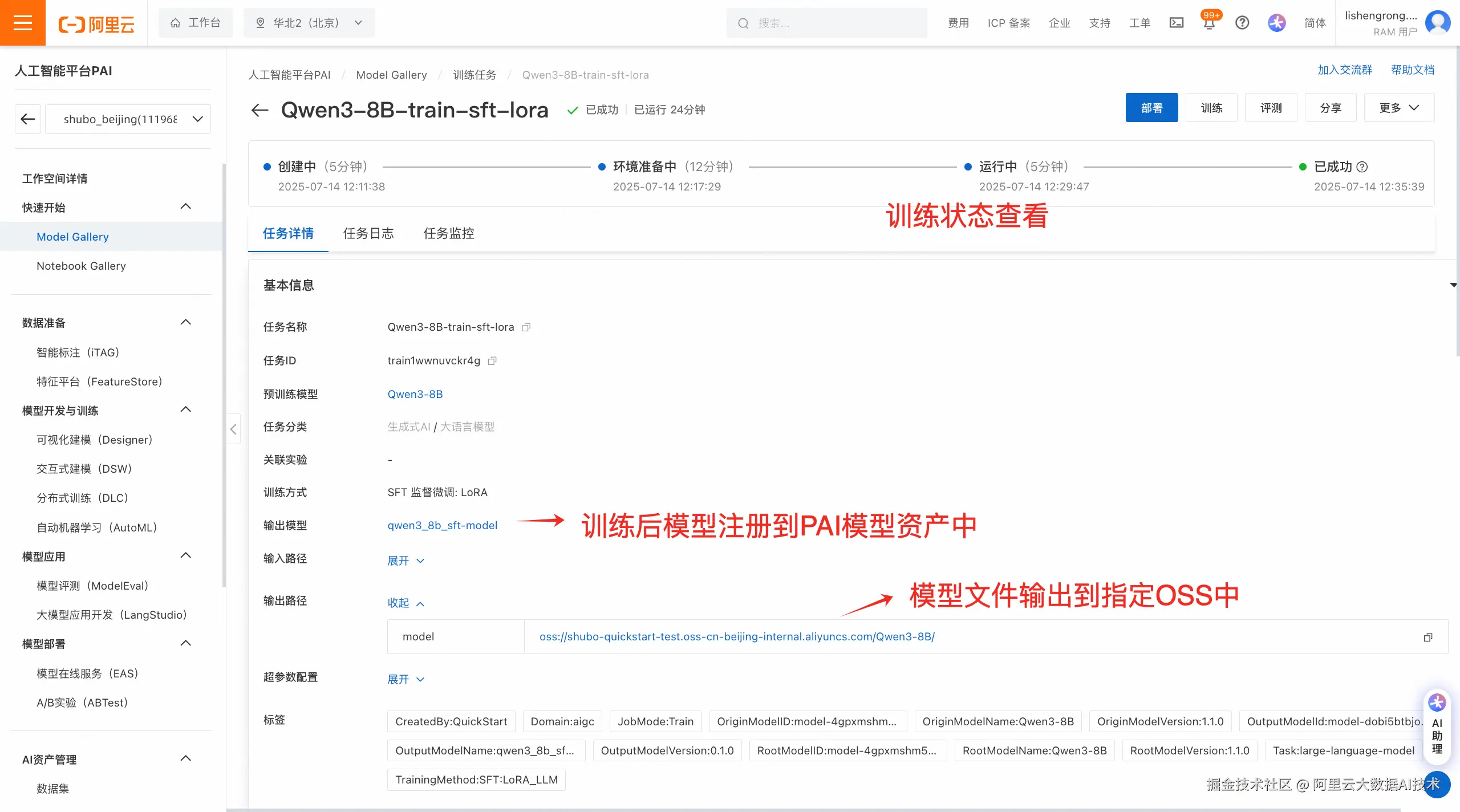
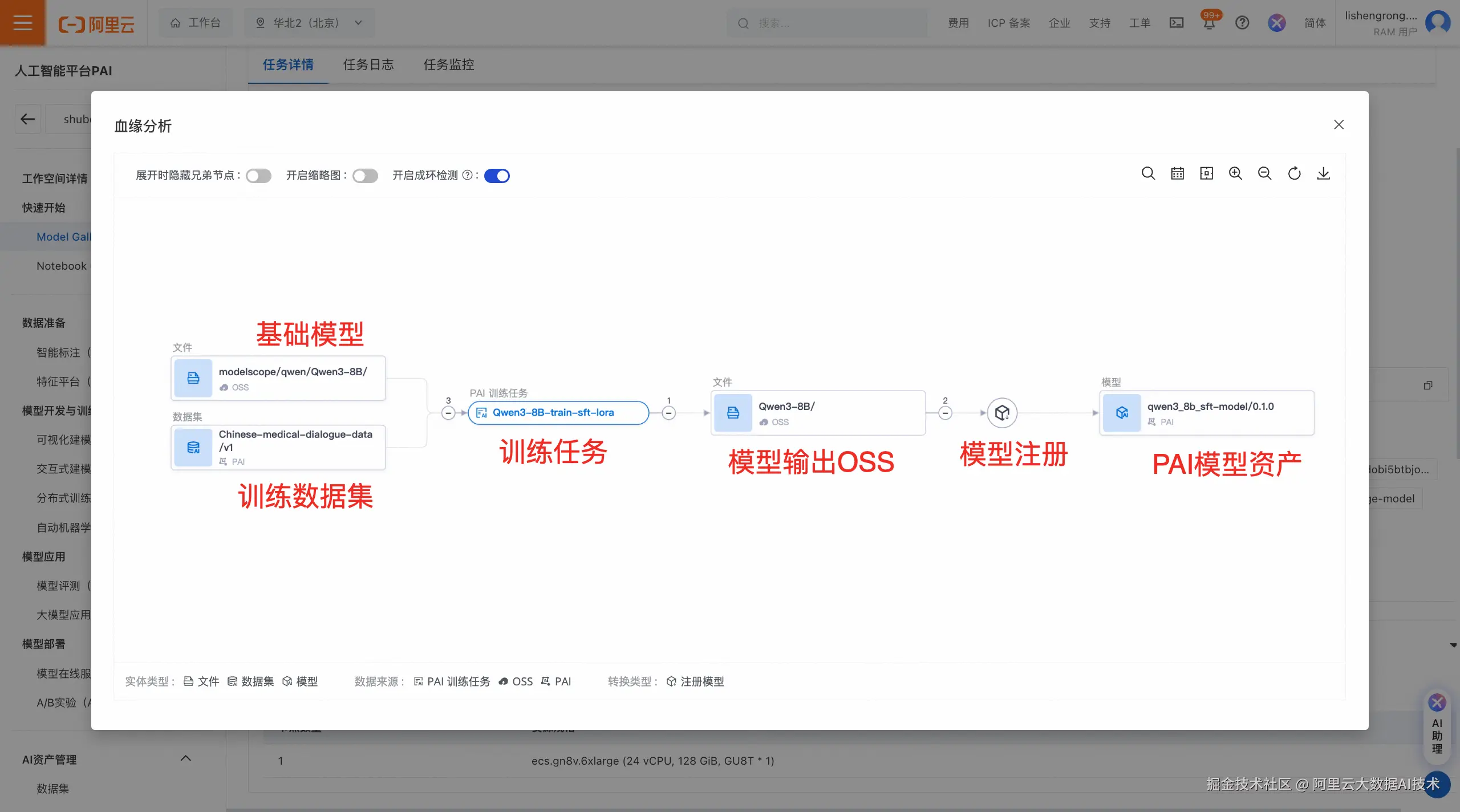
查看训练任务。提交训练任务后,页面会自动跳转到训练任务详情页(也可以从PAI-Model Gallery首页-任务管理-训练任务中找到),该页面会显示训练任务的状态。任务完成后,微调后的模型会自动注册到PAI模型资产中,模型文件会输出到您指定的对象存储OSS中。同时,PAI-Model Gallery提供模型血缘功能,帮助追踪模型的上下游全链路,根据血缘功能,可以看出模型微调任务的上游基础模型和数据集以及下游产出模型的存储路径,从整体上清晰地了解模型微调训练任务流程。
-
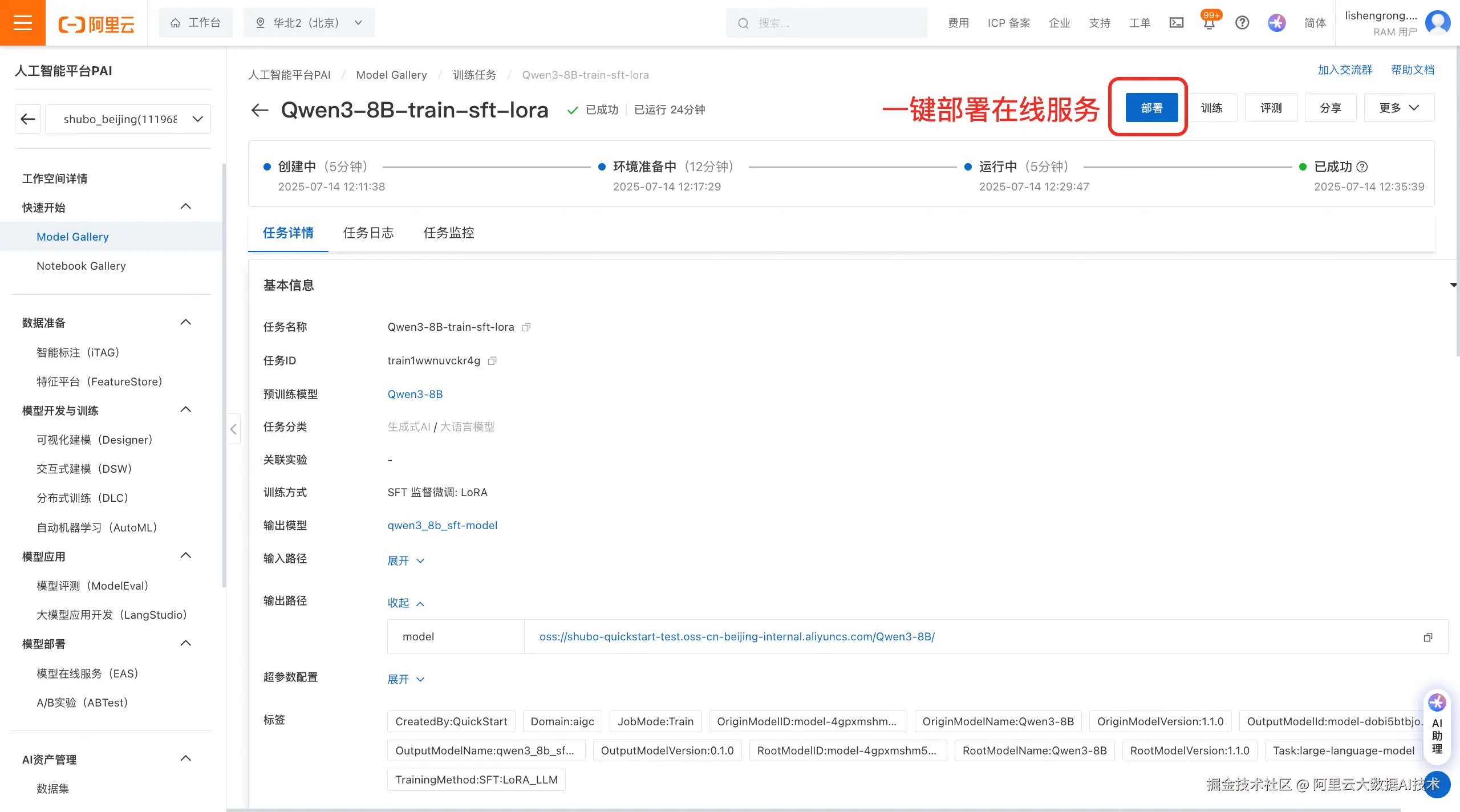
(可选)在线部署微调后的模型。在训练任务详情页右上角,您可以选择把微调后的模型直接进行一键部署,将模型部署为在线服务,可通过API或其他方式实现调用。
PAI-DSW
PAI-DSW是为AI开发者量身定制的云端机器学习交互式开发IDE,随时随地开启Notebook快速读取数据、开发算法、训练及部署模型。对于熟悉python、Notebook等环境的AI开发者,可以使用PAI-DSW进行代码形式的交互式模型微调。
下面以使用PAI自研大模型全链路训练工具库Pai-Megatron-Patch + PAI灵骏智算资源微调Qwen2.5-7b模型为例,介绍如何在PAI-DSW中微调模型。
- 在PAI上启动一个DSW实例,选择专属镜像 dsw-registry.cn-wulanchabu.cr.aliyuncs.com/pai/pai-megatron-patch:25.01
具体资源配置信息如下: 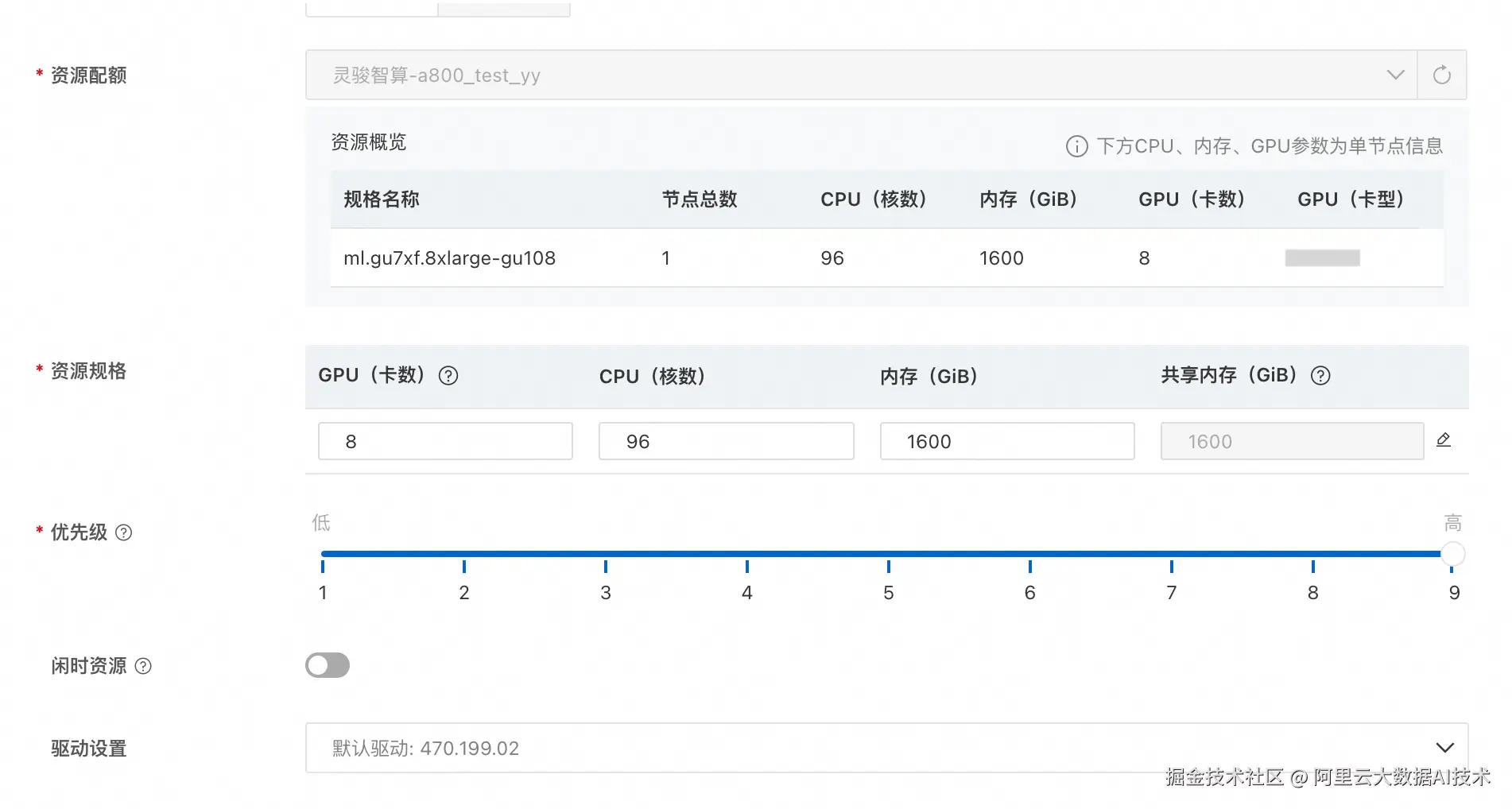
资源规格:8卡GPU,96核,1600G
挂载数据集:建议挂载CPFS数据集,用来存放模型、代码、数据等,方便后续开启多机训练(本文以CPFS数据集挂载到/mnt/data 为例)
- 下载Pai-Megatron-Patch包
cd
mkdir qwen25_sft
cd qwen25_sft
#(Option 1)直接从github上下载Pai-Megatron-Patch
git clone --recurse-submodules https://github.com/alibaba/Pai-Megatron-
Patch.git- 准备模型Qwen2.5-7B模型的checkpoints(建议提前准备好模型文件)
cd
mkdir qwen-ckpts
cd qwen-ckpts
mkdir Qwen2.5-7B
cd Qwen2.5-7B
pip install modelscope
modelscope download --model Qwen/Qwen2.5-7B --local_dir ./- 数据集准备:自制数据集准备过程可以参照示例:github.com/alibaba/Pai...
cd
mkdir qwen-datasets
cd qwen-datasets
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/qwen-datasets/mmap_qwen2_sft_datasets_text_document.bin
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/qwen-datasets/mmap_qwen2_sft_datasets_text_document.idx此时目录结构为:Pai-Megatron-Patch 中是训练所需要的代码;qwen-ckpts 是原始模型文件;qwen-datasets 是训练数据集存放地址 
- 将原始模型的checkpoint转化为megatron 格式(Pai-Megatron-Patch提供了各类丰富的格式转换工具)
cd
bash scripts/qwen2_5/run_8xH20.sh \
7B \
/mnt/data/yy/qwen25_sft/qwen-ckpts/Qwen2.5-7B \
/mnt/data/yy/qwen25_sft/qwen-ckpts/Qwen2.5-7B-to-mcore \
false \
true \
bf16- 执行SFT全参微调命令。
参数说明:
ENV=$1
MODEL_SIZE=$2 # 模型结构参数量级: 0.5B/1.5B/3B/7B/14B/32B/72B
BATCH_SIZE=$3 # 一次迭代一个数据并行内的样本数
GLOBAL_BATCH_SIZE=$4 # 一次迭代多个数据并行的总样本数
LR=$5 # 学习率
MIN_LR=$6 # 最小学习率
SEQ_LEN=$7 # 序列长度
PAD_LEN=$8 # Padding长度
PR=${9} # 训练精度: fp16, bf16, fp8
TP=${10} # 模型并行度
PP=${11} # 流水并行度
CP=${12} # 上下文并行度
SP=${13} # 是否使用序列并行: true, false
DO=${14} # 是否使用Megatron版Zero-1降显存优化器: true, false
FL=${15} # 是否优先使用Flash Attention: true, false
SFT=${16} # 是否执行微调训练: true, false
AC=${17} # 激活检查点模式: sel, full, offload, false
OPTIMIZER_OFFLOAD=${18} # 是否启用Offload optimizer: false, static, auto
SAVE_INTERVAL=${19} # 保存ckpt的间隔
DATASET_PATH=${20} # 训练数据集路径
VALID_DATASET_PATH=${21} # 验证数据集路径
PRETRAIN_CHECKPOINT_PATH=${22} # 预训练模型路径
TRAIN_TOKENS_OR_ITERS=${23} # 训练TOKEN或者Iter数
WARMUP_TOKENS_OR_ITERS=${24} # 预热TOKEN或者Iter数
OUTPUT_BASEPATH=${25} # 训练输出日志文件路径执行命令:
cd
sh run_mcore_qwen.sh \
dsw \
7B \
1 \
8 \
1e-5 \
1e-6 \
128 \
128 \
bf16 \
1 \
1 \
1 \
true \
true \
true \
true \
false \
false \
100 \
/mnt/workspace/yy/qwen25_sft/qwen-datasets/mmap_qwen2_sft_datasets_text_document \
/mnt/workspace/yy/qwen25_sft/qwen-datasets/mmap_qwen2_sft_datasets_text_document \
/mnt/workspace/yy/qwen25_sft/qwen-ckpts/Qwen2.5-7B-to-mcore \
1000 \
100 \
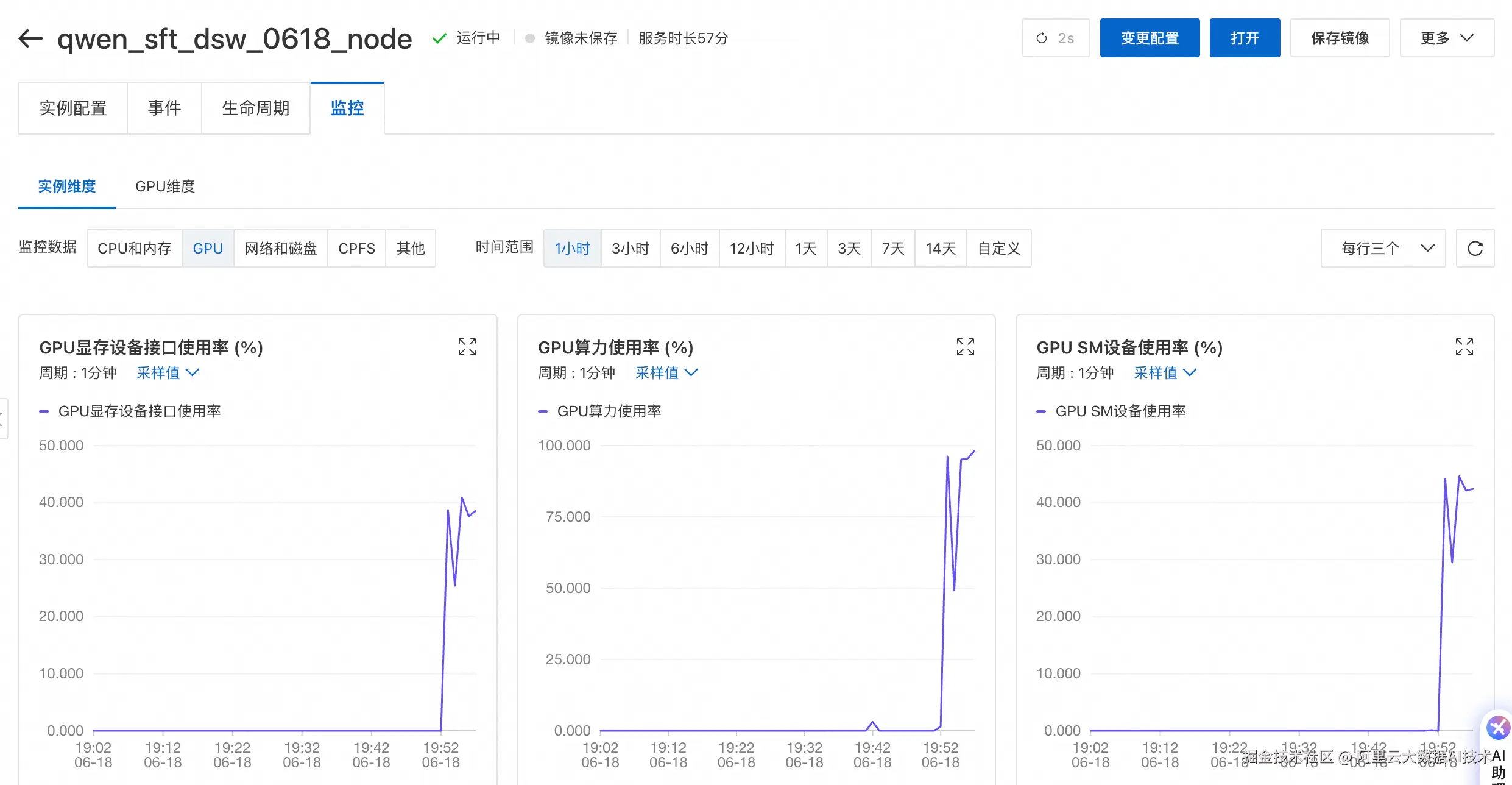
/mnt/workspace/yy/qwen25_sft/qwen-ckpts/output_mcore_qwen2.5_finetune- 查看执行过程及结果。在DSW中可以查看训练过程的日志,也可以通过查看资源监控来观察任务运行状态。
模型训练好后,在qwen-ckpts中可以看到如下目录: 