AI 的浪潮席卷而来,各行各业都在积极探索 AI 的落地应用,无论是为了提升工作效率,还是为了在同事和领导面前展现技术实力,技术先行者们都跃跃欲试。在众多 AI 落地场景中,**知识库(Retrieval Augmented Generation, RAG)**因其技术成熟且能快速发挥 AI 价值的特点,成为企业优先考虑的方案。
什么是 RAG 知识库?
简单来说,RAG 知识库就是让 AI 针对用户提出的特定知识问题,给出准确的回答。其应用场景广泛,例如:
- 内部员工问答:解答企业规章制度、工作流程等问题。
- 智能客服:为客户提供产品或服务咨询。
- 产品文档助手:帮助用户快速查找产品使用说明、常见问题等。
- ...
市面上有许多关于如何搭建 RAG 知识库的技术方案,本文将不赘述具体实现细节。今天,我们重点讨论 RAG 实践中一个最令人头疼的问题:如何设计切片方案才能最大限度地提升问题回答的准确率? 我将免费分享一个我们团队在实践中探索出的高效技术设计方案,它几乎可以申请专利!
为什么传统知识库方案回答不够准确?
目前主流的知识库切片方案是将帮助文档切分成多个小块,然后将这些小块内容输入给 AI 进行学习,再由 AI 根据学习到的内容回答用户问题。这种方式存在诸多问题,影响回答的准确性:
- 版本管理难题:文档往往有多个版本。新旧版本用户可能期望 AI 基于不同版本的文档进行回答。如果所有版本都进行切片,不仅存储成本高,更容易导致 AI 混淆,给出不准确的答案。例如,老版本的客户需要老文档的答案,而新版本的客户则需要新文档的答案,一旦版本错误,回答的准确性就会大打折扣。
- 跨页知识点割裂:当一个知识点的内容恰好位于切片边界时,比如跨越第 10 页和第 11 页,就会被分割到两个不同的切片中。这种割裂会导致 AI 无法完整地理解该知识点,从而给出不准确的答案。例如,AI 单次读取内容有限(假设只能一次存储 10 页内容),一个关键知识点被拆分到两个切片后,AI 难以将其关联起来,导致回答不准确。
解决方案:告别文档切片,直接存储"问答对"
我们的解决方案颠覆了主流做法:不要直接对文档进行切片,而是将知识库中的内容直接存储为"问答对"!
设想一下,用户使用知识库的方式就是提问。如果我们向量数据库中存储的内容本身就是经过提炼的问答对,AI 在进行语义匹配时将更容易找到相关信息。
这种方案有以下显著优势:
- 更高的匹配度:用户提问时,直接与预设的"问答对"进行匹配,极大提升了匹配的精准度。
- 避免内容割裂:一个问答对通常不会长到需要被分割成多个切片,从而避免了传统切片方案中跨页知识点被割裂的问题。
- 完美的版本管理 :我们可以为每个问答对设置版本号,从而完美解决了文档版本管理的问题。当用户指定版本时,AI 可以精准地调用对应版本的问答对进行回答,显著提升回答准确率。
RAG 落地实践中的"坑"与我们的解决方案
尽管问答对切片方案显著提升了问题回复的准确率,但在实际落地 RAG 项目中,我们仍然遇到了一些常见难题。下面将分享这些潜在的"坑"以及我们的具体解决方案:
- 图片和附件如何保存?
这可能是许多人容易忽视的问题。传统文档切片方案中,图片和附件都随文档一并处理。但当我们转为存储"问答对"时,这些非文本资料应该如何安放呢?
答案非常简单:在存储问答对到向量数据库时,可以利用其备注字段来保存这些图片、附件等资料的链接或标识。
为什么不要直接存到问答对中?
- 保证回答质量和准确度:问答对是 RAG 回答质量和准确度的核心。我们的所有设计都应尽量避免"污染"问答对,保证其相对独立和精炼。
- 方便后期维护:将截图、附件等内容与问答对本身分离,后续更新图片或附件时会非常方便,只需更新备注字段,而无需 AI 重新学习或更新问答对内容。
- 如何让大语言模型帮你生成问答对?
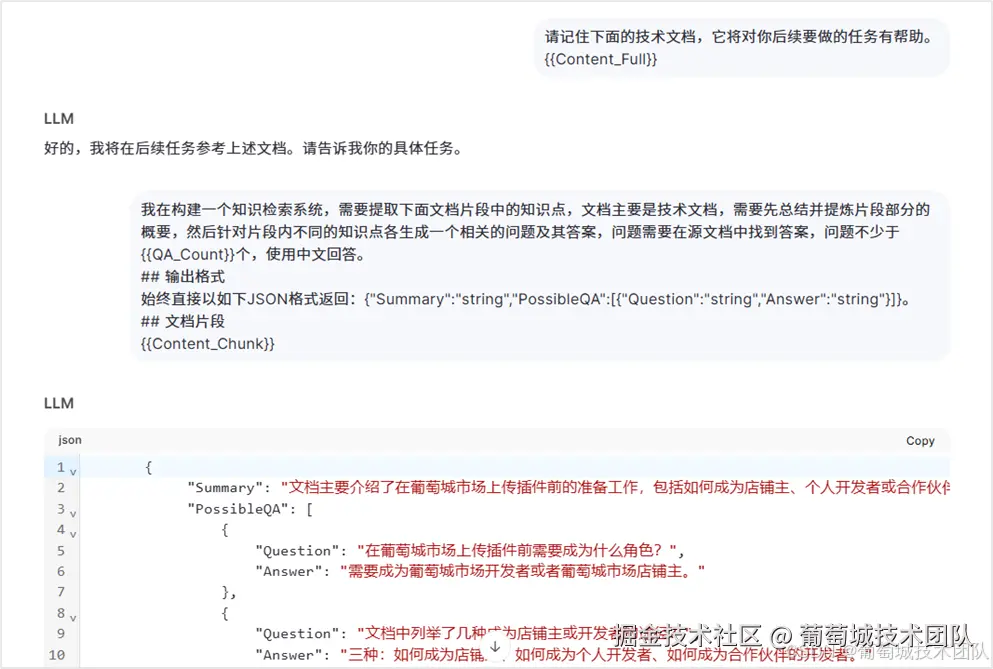
这是一个关键步骤。我们的做法是:
首先,向大语言模型清晰地说明你提供的技术文档内容。然后,指示它根据这些文档内容,为你生成问答对。
| 不传之秘: 节省 50% 成本的对话优化技巧 在实际操作中,你可能会觉得需要和大语言模型进行多次对话才能完成问答对的生成。然而,我们发现一个技巧可以立省 50% 的成本 :如图所示,对话看似进行了两次,但实际上我们只进行了一次对话。这是怎么做到的呢?秘密在于,我们可以伪造与大语言模型的对话历史记录 。例如,截图中大语言模型回答的"好的,我将在后续任务参考上述文档。请告诉我你的具体任务",这其实是我们自己伪造的历史记录。这让大语言模型误以为这是第二次对话,但实际上,这仍是与大模型进行的第一次有效对话,从而避免了重复的上下文传输成本。 注意看大模型回答的 Summary 信息! 在生成问答对时,我们故意让大模型也创建了 Summary 信息。这个 Summary 非常有用,它能让大模型在最终给用户回复时,更快更好地理解和回答问题,提高响应效率和准确性。 |
|---|
- 问答对的保存结构
一个问答对我们保存的内容大致如下,涵盖了问答的核心信息以及有助于检索和理解的元数据: 
我们的实践经验与技术架构
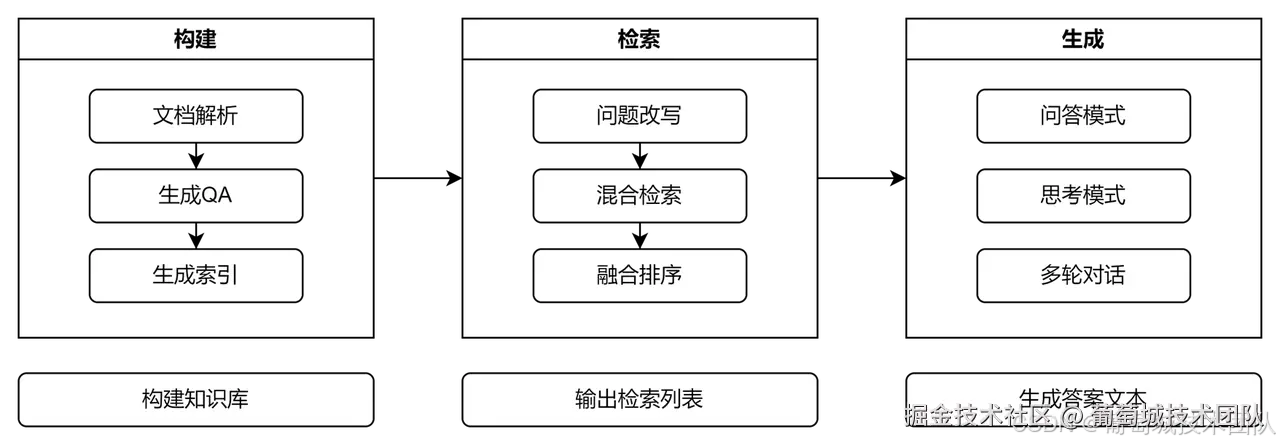
技术架构
在技术架构层面,我们的 RAG 方案围绕以下三个核心环节构建:
- 构建 - ETL(数据提取、切片、向量化)
- 检索 - Retrieval(混合检索 + RRF排序)
- 生成 - Generation(问答模式 + 思考模式)
部署方案
我们的知识库部署方案采用了以下数据库:
- Qdrant 向量数据库:用于存储和检索向量化的问答对。
- MySQL 数据库:用于存储问答对的元数据以及其他结构化信息。
部署方案概览如下图所示: 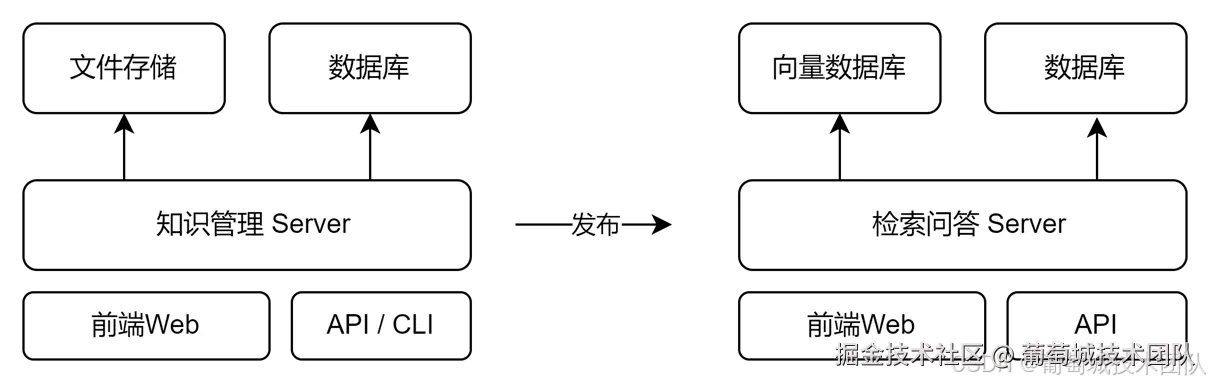
效果评估与总结
可能有人会觉得"回答准确率从 60% 飙至 95%!AI 知识库救命方案"这个标题有些标题党嫌疑。但事实上,这是我们方案落地后,通过我们以及客户评估得出的真实效果。虽然具体的产品对比视频涉及我们独有的知识,不便直接公开展示,但我相信通过上述详细的方案分享,内行的朋友们自然能够理解其价值和效果。
我们的经验证明,通过将知识库切片方案从传统文档切片转变为问答对存储,并结合上述优化技巧,能够显著提升 AI 知识库的回答准确率,真正发挥 AI 在知识管理中的巨大潜力。