一、介绍
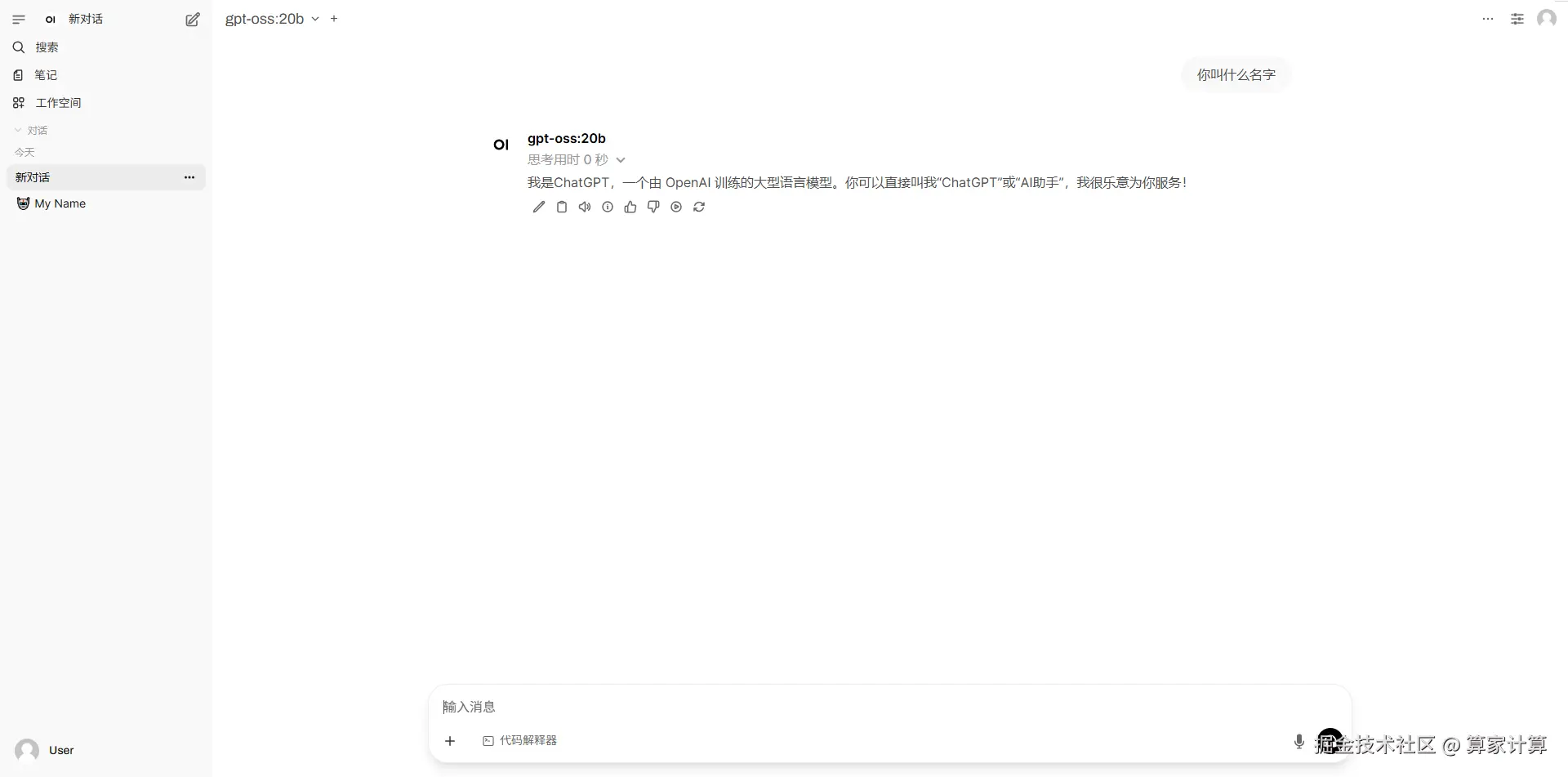
8 月 5 日,OpenAI 重磅发布了自 GPT-2 以来的首批开源权重语言模型 gpt-oss-120b 和 gpt-oss-20b,标志着 OpenAI 在开源领域迈出了重要一步,为开发者和企业带来了全新的机遇。
gpt-oss-20b 专为资源受限环境设计,总参数为 210 亿,每个词元有 36 亿个活跃参数。它采用具有 24 层和 32 个专家的混合专家(MoE)架构,能在内存仅为 16GB 的设备上运行,适用于消费级硬件和边缘设备,如 MacBook Pro、新款安卓手机等,极大地拓展了模型的应用场景。
技术亮点:
高效架构:混合专家(MoE)架构的运用,显著降低了计算需求,实现高效推理。在处理任务时,模型可根据需求灵活调用专家模块,提升运行效率。
长上下文支持:支持长达 131,072 个词元的上下文长度,能够处理复杂长文本任务,如长文档分析、复杂故事生成等。
先进注意力机制:使用分组多查询注意力机制(分组大小为 8)和旋转位置嵌入(RoPE),优化了注意力计算过程,提升了模型对位置信息的处理能力,使文本理解和生成更加准确。
性能表现:
在常见基准测试中, gpt-oss-20b 与 OpenAI o3-mini 表现相当,且在竞赛数学和医疗相关查询方面超越 o3-mini。
二、部署过程
基础环境最低要求说明:
| 环境名称 | 版本信息1 |
|---|---|
| Ubuntu | 22.04.4 LTS |
| Cuda | V12.4.105 |
| Python | 3.12 |
| NVIDIA Corporation | RTX 4090 |
1. 更新基础软件包
查看系统版本信息
bash
# 查看系统版本信息,包括ID(如ubuntu、centos等)、版本号、名称、版本号ID等
cat /etc/os-release
配置 apt 国内源
csharp
# 更新软件包列表
apt-get update这个命令用于更新本地软件包索引。它会从所有配置的源中检索最新的软件包列表信息,但不会安装或升级任何软件包。这是安装新软件包或进行软件包升级之前的推荐步骤,因为它确保了您获取的是最新版本的软件包。
csharp
# 安装 Vim 编辑器
apt-get install -y vim这个命令用于安装 Vim 文本编辑器。-y 选项表示自动回答所有的提示为"是",这样在安装过程中就不需要手动确认。Vim 是一个非常强大的文本编辑器,广泛用于编程和配置文件的编辑。
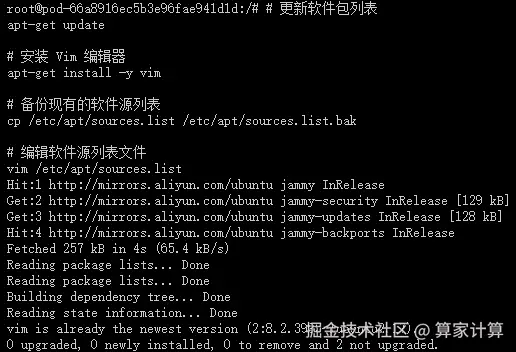
为了安全起见,先备份当前的 sources.list 文件之后,再进行修改:
bash
# 备份现有的软件源列表
cp /etc/apt/sources.list /etc/apt/sources.list.bak这个命令将当前的 sources.list 文件复制为一个名为 sources.list.bak 的备份文件。这是一个好习惯,因为编辑 sources.list 文件时可能会出错,导致无法安装或更新软件包。有了备份,如果出现问题,您可以轻松地恢复原始的文件。
bash
# 编辑软件源列表文件
vim /etc/apt/sources.list这个命令使用 Vim 编辑器打开 sources.list 文件,以便您可以编辑它。这个文件包含了 APT(Advanced Package Tool)用于安装和更新软件包的软件源列表。通过编辑这个文件,您可以添加新的软件源、更改现有软件源的优先级或禁用某些软件源。
在 Vim 中,您可以使用方向键来移动光标,i 键进入插入模式(可以开始编辑文本),Esc 键退出插入模式,:wq 命令保存更改并退出 Vim,或 :q! 命令不保存更改并退出 Vim。
编辑 sources.list 文件时,请确保您了解自己在做什么,特别是如果您正在添加新的软件源。错误的源可能会导致软件包安装失败或系统安全问题。如果您不确定,最好先搜索并找到可靠的源信息,或者咨询有经验的 Linux 用户。
使用 Vim 编辑器打开 sources.list 文件,复制以下代码替换 sources.list里面的全部代码,配置 apt 国内阿里源。
arduino
deb http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse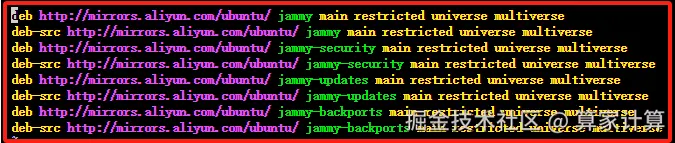
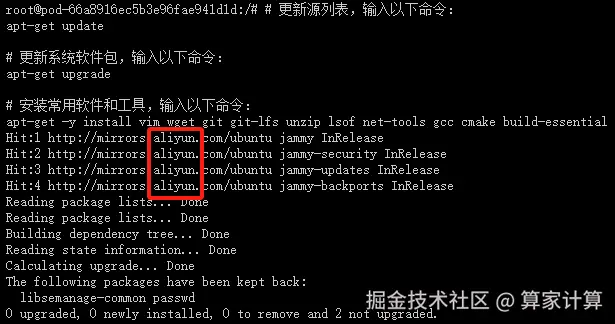
安装常用软件和工具
csharp
# 更新源列表,输入以下命令
apt-get update
# 更新系统软件包,输入以下命令
apt-get upgrade
# 安装常用软件和工具,输入以下命令
apt-get -y install vim wget git git-lfs unzip lsof net-tools gcc cmake build-essential出现以下页面,说明国内apt源已替换成功,且能正常安装apt软件和工具
2. 安装 NVIDIA CUDA Toolkit 12.1
- 下载 CUDA Keyring :
bash
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.0-1_all.deb这个命令用于下载 CUDA 的 GPG 密钥环,它用于验证 CUDA 软件包的签名。这是确保软件包安全性的一个重要步骤。
- 安装 CUDA Keyring :
css
dpkg -i cuda-keyring_1.0-1_all.deb使用 dpkg 安装下载的密钥环。这是必要的,以便 apt 能够验证从 NVIDIA 仓库下载的软件包的签名。
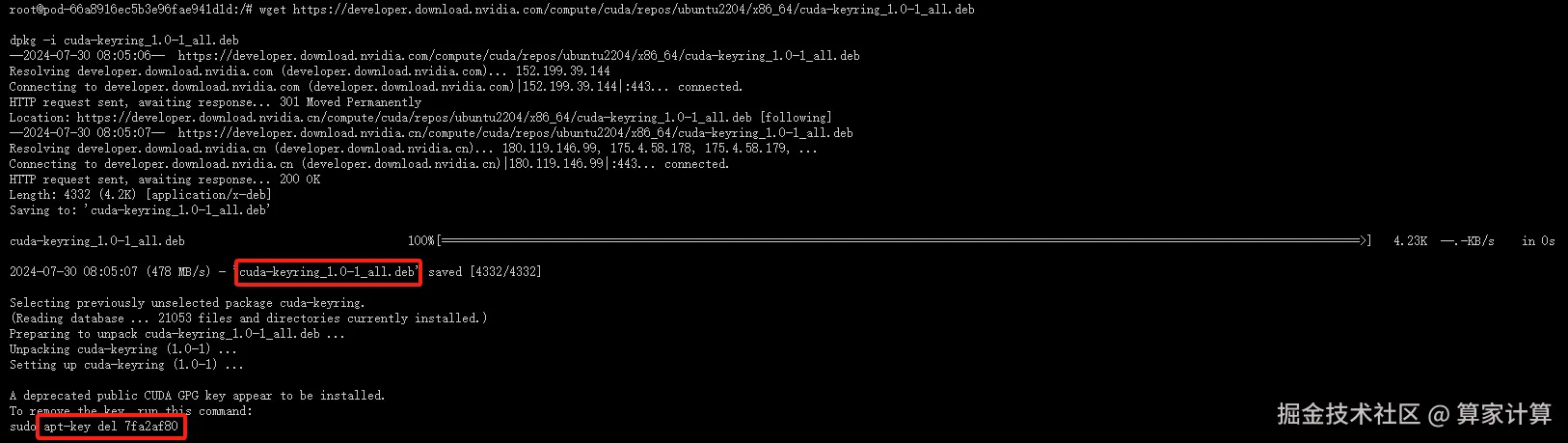
- 删除旧的 apt 密钥(如果必要) :
css
apt-key del 7fa2af80这一步可能不是必需的,除非您知道 7fa2af80 是与 CUDA 相关的旧密钥,并且您想从系统中删除它以避免混淆。通常情况下,如果您只是安装 CUDA 并使用 NVIDIA 提供的最新密钥环,这一步可以跳过。
- 更新 apt 包列表 :
sql
apt-get update更新 apt 的软件包列表,以便包括刚刚通过 cuda-keyring 添加的 NVIDIA 仓库中的软件包。
- 安装 CUDA Toolkit :
arduino
apt-get -y install cuda-toolkit-12-1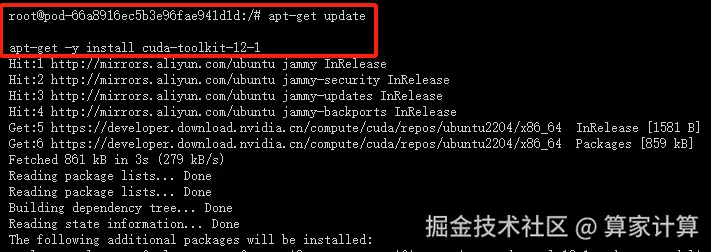
出现以下页面,说明 NVIDIA CUDA Toolkit 12.1 安装成功
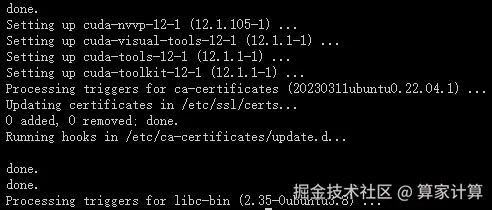
注意:这里可能有一个问题。NVIDIA 官方 Ubuntu 仓库中可能不包含直接名为 cuda-toolkit-12-1 的包。通常,您会安装一个名为 cuda 或 cuda-12-1 的元包,它会作为依赖项拉入 CUDA Toolkit 的所有组件。请检查 NVIDIA 的官方文档或仓库,以确认正确的包名。
如果您正在寻找安装特定版本的 CUDA Toolkit,您可能需要安装类似 cuda-12-1 的包(如果可用),或者从 NVIDIA 的官方网站下载 CUDA Toolkit 的 .run 安装程序进行手动安装。
请确保您查看 NVIDIA 的官方文档或 Ubuntu 的 NVIDIA CUDA 仓库以获取最准确的包名和安装指令。

- 出现以上情况,需要配置 NVIDIA CUDA Toolkit 12.1 系统环境变量
编辑 ~/.bashrc 文件
bash
# 编辑 ~/.bashrc 文件
vim ~/.bashrc插入以下环境变量
bash
# 插入以下环境变量
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
激活 ~/.bashrc 文件
bash
# 激活 ~/.bashrc 文件
source ~/.bashrc查看cuda系统环境变量
bash
which nvcc
nvcc -V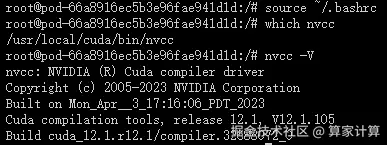
3. 安装 Miniconda
-
下载 Miniconda 安装脚本 :
- 使用
wget命令从 Anaconda 的官方仓库下载 Miniconda 的安装脚本。Miniconda 是一个更小的 Anaconda 发行版,包含了 Anaconda 的核心组件,用于安装和管理 Python 包。
- 使用
-
运行 Miniconda 安装脚本 :
- 使用
bash命令运行下载的 Miniconda 安装脚本。这将启动 Miniconda 的安装过程。
- 使用
bash
# 下载 Miniconda 安装脚本
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 运行 Miniconda 安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
# 初次安装需要激活 base 环境
source ~/.bashrc按下回车键(enter)
输入yes
输入yes
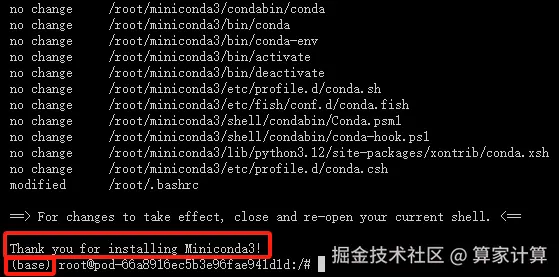
安装成功如下图所示
pip配置清华源加速
bash
# 编辑 /etc/pip.conf 文件
vim /etc/pip.conf加入以下代码
ini
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple注意事项:
- 请确保您的系统是 Linux x86_64 架构,因为下载的 Miniconda 版本是为该架构设计的。
- 在运行安装脚本之前,您可能需要使用
chmod +x Miniconda3-latest-Linux-x86_64.sh命令给予脚本执行权限。 - 安装过程中,您将被提示是否同意许可协议,以及是否将 Miniconda 初始化。通常选择 "yes" 以完成安装和初始化。
- 安装完成后,您可以使用
conda命令来管理 Python 环境和包。 - 如果链接无法访问或解析失败,可能是因为网络问题或链接本身的问题。请检查网络连接,并确保链接是最新的和有效的。如果问题依旧,请访问 Anaconda 的官方网站获取最新的下载链接。
4. 从 github 仓库 克隆项目
- 克隆存储库:
bash
# 克隆项目
git clone https://github.com/openai/gpt-oss.git5. 创建虚拟环境
ini
# 创建一个名为 openwebui 的新虚拟环境,并指定 Python 版本为 3.12
conda create --name openwebui python=3.12 -y6. 安装模型依赖库
- 切换到项目目录、激活虚拟环境、安装依赖
ini
# 切换到项目工作目录
cd /gpt-oss
# 激活虚拟环境
conda activate openwebui
# 升级 pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 安装 ollama
curl -fsSL https://ollama.com/install.sh | sh
pip install transformers==4.48.2
pip install accelerate==1.3.0
pip install modelscope==1.22.3
pip install streamlit==1.41.1
pip install open-webui7. 下载预训练模型
- 下载预训练权重
bash
# 下载预训练权重
git lfs install
git clone https://huggingface.co/openai/gpt-oss-20b8. 启动 ollama、OpenWebUI 服务
ini
# 切换到项目目录
cd /gpt-oss
# 激活虚拟环境
conda activate openwebui
# 启动 ollama 服务到后台
nohup ollama serve > ollama.log 2>&1 &
# 设置环境变量并启动OpenWebUI到后台
export HF_ENDPOINT=https://hf-mirror.com
export OLLAMA_HOST=0.0.0.0
export OLLAMA_BASE_URL=http://127.0.0.1:11434
export WEBUI_AUTH=False
export ENABLE_OPENAI_API=False
export ENABLE_EVALUATION_ARENA_MODELS=False
nohup open-webui serve --port 8080 > webui.log 2>&1 &
# 检查进程
ps aux | grep -E 'vllm|open-webui'
# 在一个终端窗口中同时跟踪两个日志文件
tail -f ollama.log webui.log
# 检查端口
netstat -tulnp | grep 8080三、网页演示
出现以下页面,即是模型已搭建完成。