我们将从一种大家都熟悉的简单RAG方法入手,然后测试更高级的技术,比如CRAG、Fusion、HyDE等等!
为了让一切保持简单,我没有使用LangChain或FAISS,而是只使用基础库,以Jupyter笔记本风格编写所有技术的代码,力求简单易懂。
代码库组织结构如下:
├── 1_simple_rag.ipynb
├── 2_semantic_chunking.ipynb
...
├── 9_rse.ipynb
├── 10_contextual_compression.ipynb
├── 11_feedback_loop_rag.ipynb
├── 12_adaptive_rag.ipynb
...
├── 17_graph_rag.ipynb
├── 18_hierarchy_rag.ipynb
├── 19_HyDE_rag.ipynb
├── 20_crag.ipynb
└── data/
└── val.json └── AI_information.pdf └── attention_is_all_you_need.pdf
目录
-
测试查询和大语言模型(LLMs)
-
效果最佳的技术!
-
导入库
-
简单RAG
-
语义分块
-
上下文增强检索
-
上下文分块标题
-
文档增强
-
查询转换
-
重排序器
-
RSE
-
上下文压缩
-
反馈循环
-
自适应RAG
-
自RAG(Self RAG)
-
知识图谱
-
分层索引
-
HyDE
-
Fusion
-
多模型
-
CRAG
-
结论
测试查询和大语言模型(LLMs)
为了测试每种技术,我们需要四样东西:
-
测试查询及其正确答案。
-
应用RAG的PDF文档。
-
嵌入生成模型。
-
响应和验证用的大语言模型(LLM)。
我使用Claude 3.5 Thinking模型创建了一份16多页的AI主题文档,作为RAG的参考文档,还使用了《Attention is all you need》论文来评估多模型RAG。该文档位于我的验证数据文件夹中,经过精心策划,用于测试我们将要使用的所有技术。
对于响应生成和验证,我们将使用LLaMA-3.2--3B Instruct,以测试小型LLM在RAG任务中的表现。
对于嵌入,我们将使用TaylorAI/gte-tiny模型。
我们的测试查询是一个复杂的问题,将在整篇文档中使用,其正确答案如下:
测试查询:
人工智能对海量数据集的依赖如何成为一把双刃剑?
正确答案:
它推动了快速学习和创新,但也存在放大固有偏见的风险,因此在数据量与公平性和质量之间取得平衡至关重要。(结论)效果最佳的技术!
与其放在最后,不如先写在这里。在对我们的测试查询测试了18种不同的RAG技术后:
Adaptive RAG以0.86的最高分成为明显的赢家。
通过智能分类查询并为每种问题类型选择最合适的检索策略,Adaptive RAG表现出优于其他方法的性能。它能够在事实型、分析型、观点型和上下文型策略之间动态切换,从而能够以极高的准确性满足多样化的信息需求。
尽管分层索引(0.84)、Fusion(0.83)和CRAG(0.824)等技术也表现出色,但Adaptive RAG的灵活性使其在实际应用中更具优势。
导入库
让我们先克隆代码仓库,以安装所需的依赖项并开始工作。
bash
# Cloning the repo
git clone https://github.com/FareedKhan-dev/all-rag-techniques.git
cd all-rag-techniques安装所需的依赖项。
bash
# Installing the required libraries
pip install -r requirements.txt简单RAG
让我们从最简单的RAG开始。首先,我们将了解它的工作原理,然后对其进行测试和评估。
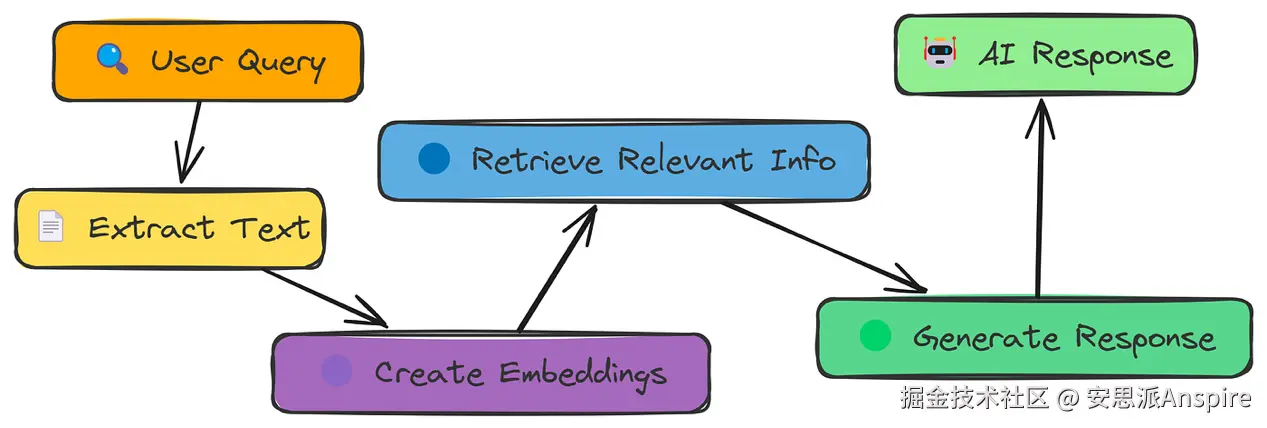
简单RAG工作流程
如图所示,简单RAG流程的工作原理如下:
-
从PDF中提取文本。
-
将文本分割成更小的块。
-
将这些块转换为数值嵌入。
-
根据查询搜索最相关的块。
-
使用检索到的块生成响应。
-
将响应与正确答案进行比较以评估准确性。
首先,让我们加载文档,提取文本,并将其分割成可管理的块:
ini
# 定义PDF文件的路径
pdf_path = "data/AI_information.pdf"
# 从PDF文件中提取文本,并创建较小的、重叠的块。
extracted_text = extract_text_from_pdf(pdf_path)
text_chunks = chunk_text(extracted_text, 1000, 200)
print("文本块数量:", len(text_chunks))
### 输出 ###
Number of text chunks: 42这段代码使用extract_text_from_pdf从我们的PDF文件中提取所有文本。然后,chunk_text将这一大块文本分割成更小的、重叠的片段,每个片段约1000个字符。
接下来,我们需要将这些文本块转换为数值表示(嵌入):
ini
# 为文本块创建嵌入
response = create_embeddings(text_chunks)这里,create_embeddings接收我们的文本块列表,并使用我们的嵌入模型为每个文本块生成数值嵌入。这些嵌入捕捉了文本的含义。
现在我们可以执行语义搜索,找到与我们的测试查询最相关的块:
ini
# 我们的测试查询,并执行语义搜索。
query = '''How does AI's reliance on massive data sets act
as a double-edged sword?'''
top_chunks = semantic_search(query, text_chunks, embeddings, k=2)然后,semantic_search将查询嵌入与块嵌入进行比较,返回最相似的块。
有了相关的块,让我们生成响应:
ini
# 定义AI助手的系统提示
system_prompt = "你是一个AI助手,严格根据给定的上下文回答问题。如果无法从提供的上下文中直接得出答案,请回复:'我没有足够的信息来回答这个问题。'"
# 基于顶级块创建用户提示,并生成AI响应。
user_prompt = "\n".join([f"上下文 {i + 1}:\n{chunk}\n========\n" for i, chunk in enumerate(top_chunks)])
user_prompt = f"{user_prompt}\n问题:{query}"
ai_response = generate_response(system_prompt, user_prompt)
print(ai_response.choices[0].message.content)这段代码将检索到的块格式化为大语言模型(LLM)的提示。generate_response函数将此提示发送给LLM,LLM仅根据提供的上下文生成答案。
最后,让我们看看简单RAG的表现如何:
ini
# 定义评估系统的系统提示
evaluate_system_prompt = "你是一个智能评估系统,负责评估AI助手的响应。如果AI助手的响应与真实响应非常接近,赋值1分。如果响应与真实响应不符或不令人满意,赋值0分。如果响应与真实响应部分一致,赋值0.5分。"
# 创建评估提示并生成评估响应
evaluation_prompt = f"用户查询:{query}\nAI响应:\n{ai_response.choices[0].message.content}\n真实响应:{data[0]['ideal_answer']}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出 ###
... 因此,得分为0.3,这与真实响应不太接近,也不完全一致。嗯......简单RAG的响应低于平均水平。
让我们继续下一种方法。
语义分块
在我们的简单RAG方法中,我们只是将文本切成固定大小的块。这种方式相当粗糙!它可能会把一个句子劈成两半,或者把不相关的句子归到一起。
语义分块旨在更智能一些。它不采用固定大小,而是尝试根据含义拆分文本,将语义相关的句子组合在一起。
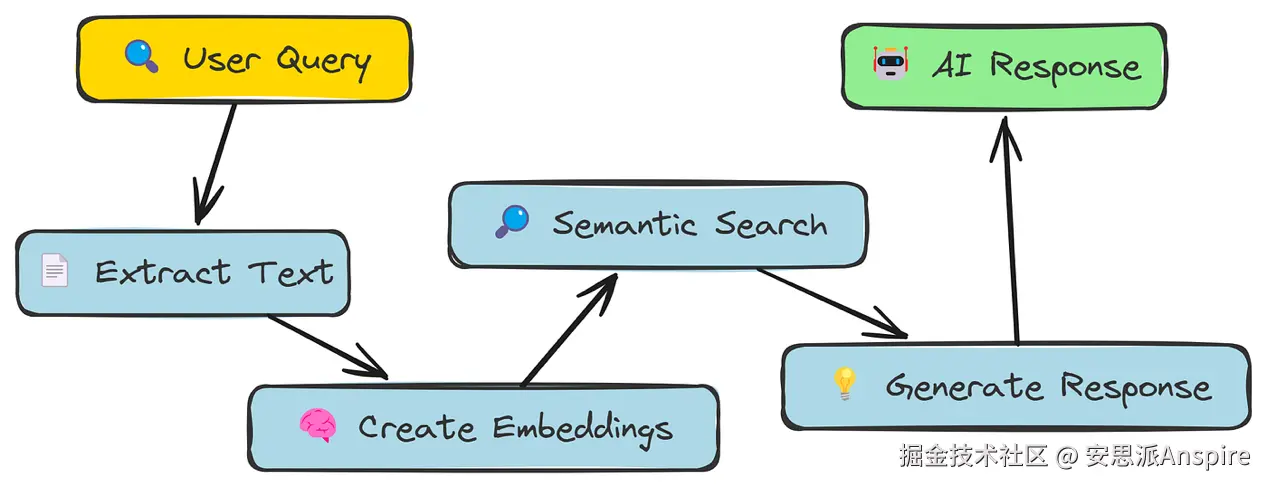
语义分块工作流程
核心思路是,如果句子讨论的是相似内容,就应该放在同一个块中。我们会使用同一个嵌入模型来判断句子之间的相似度。
ini
# 将文本拆分为句子(基础拆分)
sentences = extracted_text.split(". ")
# 为每个句子生成嵌入
embeddings = [get_embedding(sentence) for sentence in sentences]
print(f"已生成 {len(embeddings)} 个句子嵌入。")
### 输出 ###
233这段代码将我们提取的文本拆分成单个句子,然后为每个句子创建嵌入。
接下来,我们将计算连续句子之间的相似度:
less
# 计算连续句子之间的相似度
similarities = [cosine_similarity(embeddings[i], embeddings[i + 1]) for i in range(len(embeddings) - 1)]这个cosine_similarity函数(之前定义的)用于判断两个嵌入的相似程度。得分1表示非常相似,0表示完全不同。我们会为每对相邻句子计算这个得分。
语义分块的关键是确定在哪里将文本拆分成块。我们会使用"断点"方法。这里我们采用百分位法,寻找相似度的大幅下降点:
ini
# 使用百分位法计算断点,阈值设为90
breakpoints = compute_breakpoints(similarities, method="percentile", threshold=90)compute_breakpoints函数采用"percentile"方法,识别句子间相似度显著下降的点------这些就是我们的块边界。
现在我们可以创建语义块了:
python
# 使用split_into_chunks函数创建块
text_chunks = split_into_chunks(sentences, breakpoints)
print(f"语义块数量:{len(text_chunks)}")
### 输出 ###
Number of semantic chunks: 145split_into_chunks函数接收我们的句子列表和找到的断点,将句子分组为块。
接下来,我们需要为这些块创建嵌入:
ini
# 使用create_embeddings函数创建块嵌入
chunk_embeddings = create_embeddings(text_chunks)是时候生成响应了:
ini
# 基于顶级块创建用户提示
user_prompt = "\n".join([f"上下文 {i + 1}:\n{chunk}\n=====================================\n" for i, chunk in enumerate(top_chunks)])
user_prompt = f"{user_prompt}\n问题:{query}"
# 生成AI响应
ai_response = generate_response(system_prompt, user_prompt)
print(ai_response.choices[0].message.content)最后是评估:
python
# 组合用户查询、AI响应、真实响应和评估系统提示,创建评估提示
evaluation_prompt = f"User Query: {query}\nAI Response:\n{ai_response.choices[0].message.content}\nTrue Response: {data[0]['ideal_answer']}\n{evaluate_system_prompt}"
# 使用评估系统提示和评估提示生成评估响应
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
# 打印评估响应
print(evaluation_response.choices[0].message.content)
### 输出
根据评估标准,
我会给AI助手的响应打0.2分。评估者只给了0.2分。
虽然语义分块理论上听起来不错,但在这个案例中并没有帮到我们。事实上,与简单的固定大小分块相比,我们的得分反而下降了!
这表明,仅仅改变分块策略并不能保证效果提升。我们需要更复杂的方法。让我们在下一节尝试其他技术。
上下文增强检索
我们已经看到,语义分块虽然原理上是个好主意,但实际上并没有改善我们的结果。
其中一个问题是,即使是语义定义的块也可能过于聚焦。它们可能会缺失周围文本中的关键上下文。
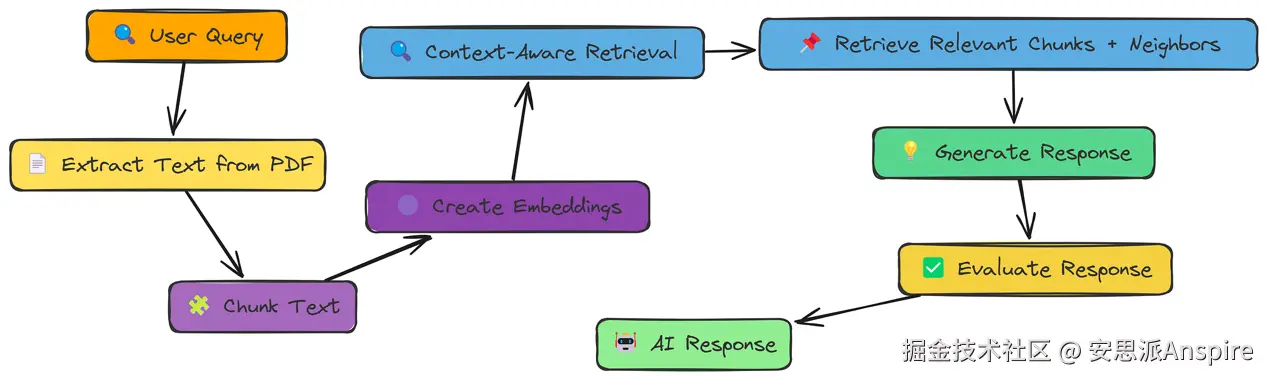
上下文增强工作流程
上下文增强检索通过不仅获取最匹配的块,还获取其相邻块来解决这个问题。
让我们看看代码中是如何实现的。我们需要一个新函数context_enriched_search来处理检索:
python
def context_enriched_search(query, text_chunks, embeddings, k=1, context_size=1):
"""
检索最相关的块及其相邻块。
"""
# 将查询转换为嵌入向量
query_embedding = create_embeddings(query).data[0].embedding
similarity_scores = []
# 计算查询与每个文本块嵌入之间的相似度得分
for i, chunk_embedding in enumerate(embeddings):
# 计算查询嵌入与当前块嵌入之间的余弦相似度
similarity_score = cosine_similarity(np.array(query_embedding), np.array(chunk_embedding.embedding))
# 将索引和相似度得分存储为元组
similarity_scores.append((i, similarity_score))
# 按相似度得分降序排序(相似度最高的在前)
similarity_scores.sort(key=lambda x: x[1], reverse=True)
# 获取最相关块的索引
top_index = similarity_scores[0][0]
# 定义上下文包含的范围
# 确保不会低于0或超出text_chunks的长度
start = max(0, top_index - context_size)
end = min(len(text_chunks), top_index + context_size + 1)
# 返回相关块及其相邻的上下文块
return [text_chunks[i] for i in range(start, end)]核心逻辑与我们之前的搜索类似,但不再只返回单个最佳块,而是获取其周围的"窗口"块。context_size控制我们在两侧包含多少个块。
让我们在RAG流程中使用这个函数。我们会跳过文本提取和分块步骤,因为这些与简单RAG中的步骤相同。
我们将使用固定大小的块,就像在简单RAG部分中所做的那样,保持块大小=1000,重叠=200。
现在像之前一样生成响应:
ini
# 基于顶级块创建用户提示
user_prompt = "\n".join([f"Context {i + 1}:\n{chunk}\n=====================================\n" for i, chunk in enumerate(top_chunks)])
user_prompt = f"{user_prompt}\nQuestion: {query}"
# 生成AI响应
ai_response = generate_response(system_prompt, user_prompt)
print(ai_response.choices[0].message.content)最后进行评估:
python
# 创建评估提示并生成评估响应
evaluation_prompt = f"User Query: {query}\nAI Response:\n{ai_response.choices[0].message.content}\nTrue Response: {data[0]['ideal_answer']}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### 输出 ###
根据评估标准,
我会给AI助手的响应打0.6分。这次,我们得到了0.6的评估分数!这比简单RAG和语义分块都有显著提升。
通过包含相邻块,我们为大语言模型提供了更多上下文,从而得到了更好的答案。
我们还没有达到完美,但显然在朝着正确的方向前进。这表明检索时上下文的重要性。
上下文分块标题
我们已经看到,通过包含相邻块来增加上下文是有帮助的。但如果块本身的内容缺少重要信息呢?
通常,文档都有清晰的结构------标题、标题、副标题,这些都提供了关键上下文。上下文分块标题(Contextual Chunk Headers,CCH)正是利用了这种结构。
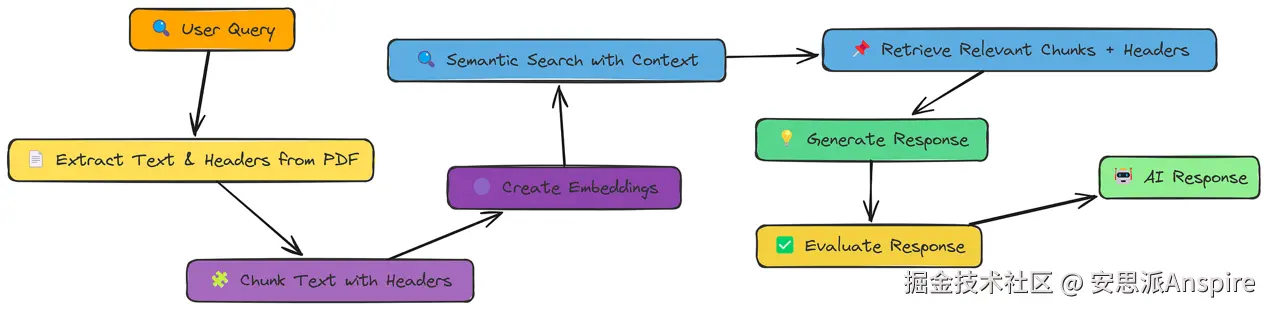
上下文分块标题
核心思想很简单:在我们创建嵌入之前,给每个块前置一个描述性标题。这个标题就像一个迷你摘要,为检索系统(以及LLM)提供更多可利用的信息。
generate_chunk_header函数会分析每个文本块,并生成一个简洁、有意义的标题来概括其内容。这有助于高效地组织和检索相关信息。
python
# 对提取的文本进行分块,这次会生成标题
text_chunks_with_headers = chunk_text_with_headers(extracted_text, 1000, 200)
# 打印一个样本看看效果
print("带标题的样本块:")
print("标题:", text_chunks_with_headers[0]['header'])
print("内容:", text_chunks_with_headers[0]['text'])
### 输出 ###
Sample Chunk with Header:
Header: A Description about AI Impact
Content: AI has been an important part of society since ...可以看到每个块现在都有一个标题和原始文本了吧?这就是我们要使用的增强数据。
接下来是嵌入部分。我们会为标题和文本都创建嵌入:
css
# 为每个块生成嵌入(包括标题和文本)
embeddings = []
for chunk in tqdm(text_chunks_with_headers, desc="Generating embeddings"):
text_embedding = create_embeddings(chunk["text"])
header_embedding = create_embeddings(chunk["header"])
embeddings.append({"header": chunk["header"], "text": chunk["text"], "embedding": text_embedding, "header_embedding": header_embedding})我们遍历所有块,为标题和文本都获取嵌入,并将所有信息存储在一起。这让检索系统有两种方式将块与查询匹配。
由于semantic_search已经可以处理嵌入,我们只需要确保标题和文本块都正确嵌入即可。这样,当我们执行搜索时,模型可以同时考虑高层摘要(标题)和详细内容(块文本)来找到最相关的信息。
现在,让我们修改检索步骤,不仅返回匹配的块,还返回它们的标题以提供更好的上下文,并生成响应:
ini
# 使用查询和新嵌入执行语义搜索
top_chunks = semantic_search(query, embeddings, k=2)
# 基于顶级块创建用户提示。注意:无需添加标题
# 因为上下文已经结合了标题和块内容
user_prompt = "\n".join([f"Context {i + 1}:\n{chunk['text']}\n=====================================\n" for i, chunk in enumerate(top_chunks)])
user_prompt = f"{user_prompt}\nQuestion: {query}"
# 生成AI响应
ai_response = generate_response(system_prompt, user_prompt)
print(ai_response.choices[0].message.content)
### 输出 ###
Evaluation Score: 0.5这次,我们的评估分数是0.5!
通过添加这些上下文标题,我们让系统更有可能找到正确的信息,也让LLM更有可能生成完整且准确的答案。
这展示了在数据进入检索系统之前对其进行增强的作用。我们没有改变核心的RAG流程,但让数据本身更具信息性。
今天的内容就先聊到这里。接下来,我们还会继续深入更多RAG 技术,一点点对比它们的优劣。感兴趣的小伙伴别忘了持续关注,咱们下期继续。