写在前面
笔记本
windows系统环境:windows 11
显卡:NVIDIA GeForce RTX 5080Laptop GPU
CUDA version:12.8
安装CUDA version:12.8
安装cuDNN version:9.7.0
对应的PyTorch:cu128
1. 检查硬件要求
1.1 确认电脑中有Nvidia显卡
因为使用GPU进行Yolo模型训练需要GPU支持。首先需要确认下我们系统中是否存在英伟达显卡。
方法一
打开终端,输入命令行回车:
cmd
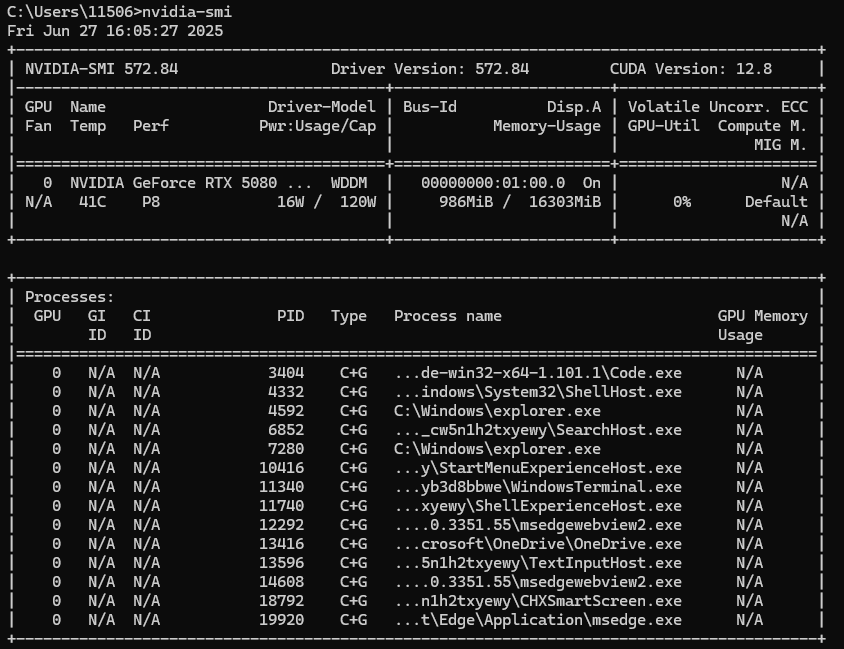
nvidia-smi如果电脑中有Nvidia显卡,会打印出相关信息,显示支持的CUDA版本和显卡型号,打印信息如下:
我这里CUDA Version是12.8,意味着CUDA Toolkit Archive版本最高支持12.8,如果需要更高版本先确认显卡是否支持,然后去升级驱动。
如果没有显卡,则一般无法识读该命令,显示信息如下

方法二
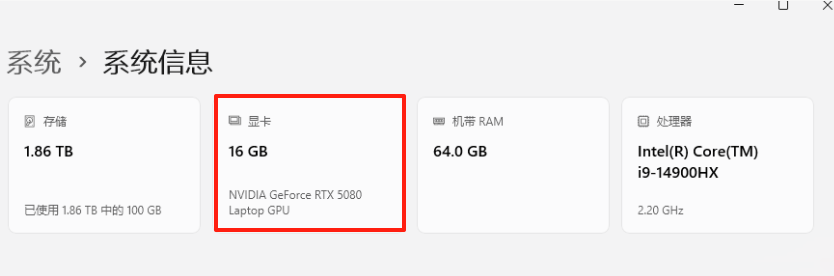
具体为点击【此电脑】-【属性】,可以查看电脑的CPU,显卡等信息,如下:
1.2 查询显卡算力情况,以确保其满足PyTorch的最低算力要求
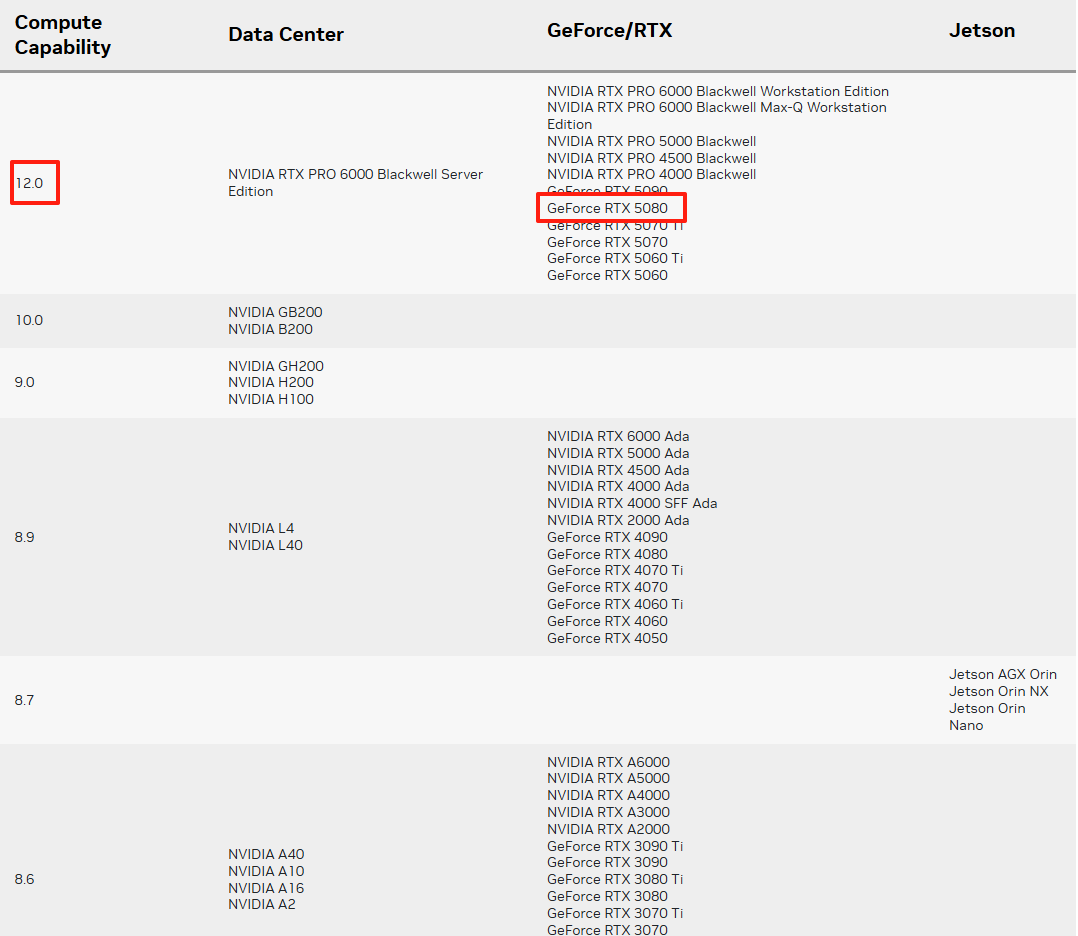
访问NVIDIA官网【计算能力】栏目或直接点击:CUDA GPUs - Compute Capability | NVIDIA Developer,下拉找到对应的GPU型号卡片,点击展开后可以看到该型号下各种GPU的算力情况。根据GPU算力看能不能跑起来Pytorch,Pytorch的最低算力要求表如下:
可以看到我的电脑对应的算力值是12.0
1.3 算力值对应的CUDA版本
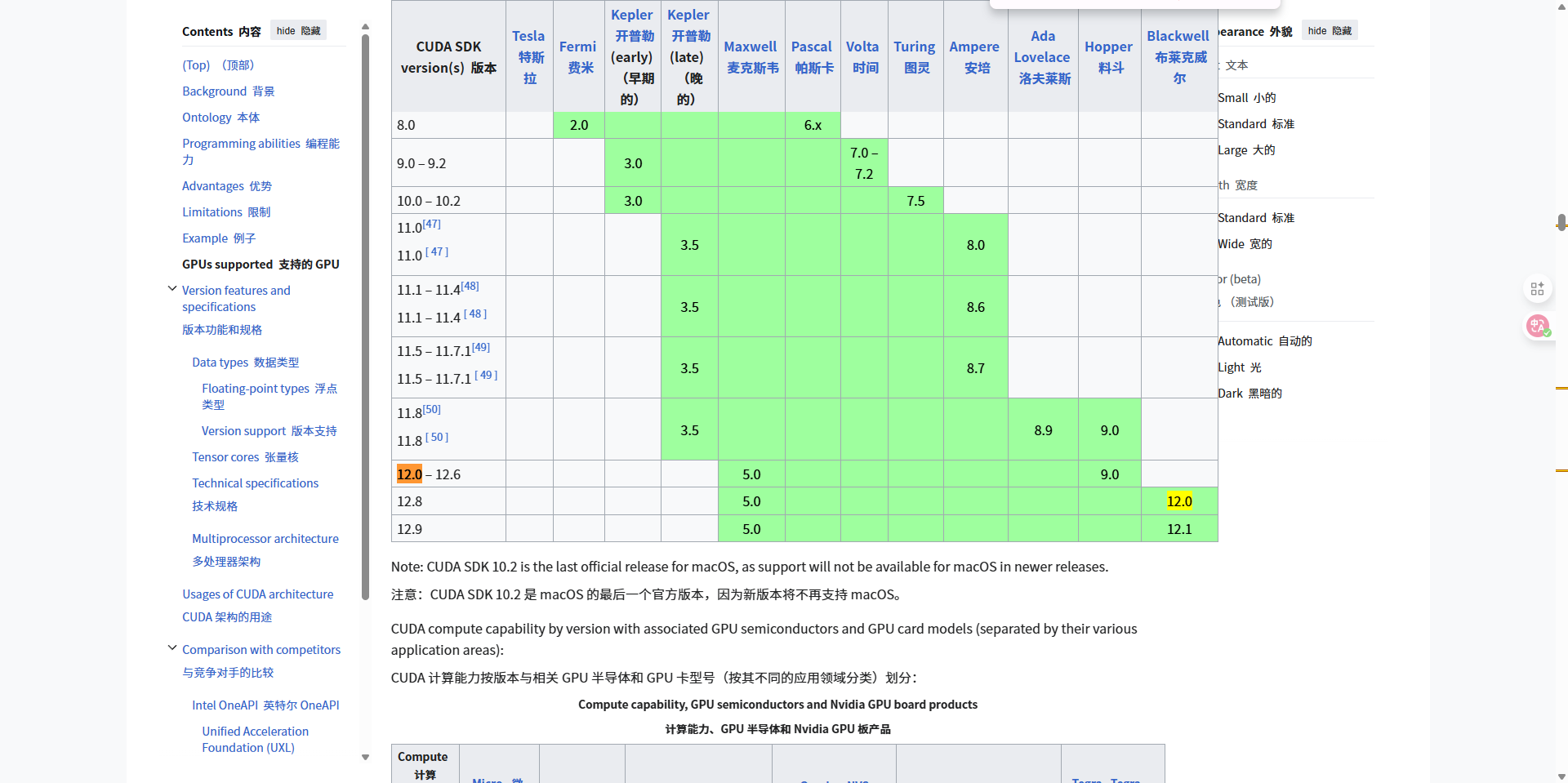
通过网站可以https://en.wikipedia.org/wiki/CUDA可以查看算力值对应的CUDA版本,访问需要魔法,可以参考下图:
看到12.0的算力最低是12.8的版本,咱也不知道装低了有没有啥问题,就按12.8的来吧。
有开源的模型暂不支持12.0算力的显卡,满满的都是泪。
2. 安装CUDA
访问CUDA下载官网:CUDA Toolkit Archive | NVIDIA Developer,根据第一步查看到的自己的显卡支持的CUDA版本,下载并安装。
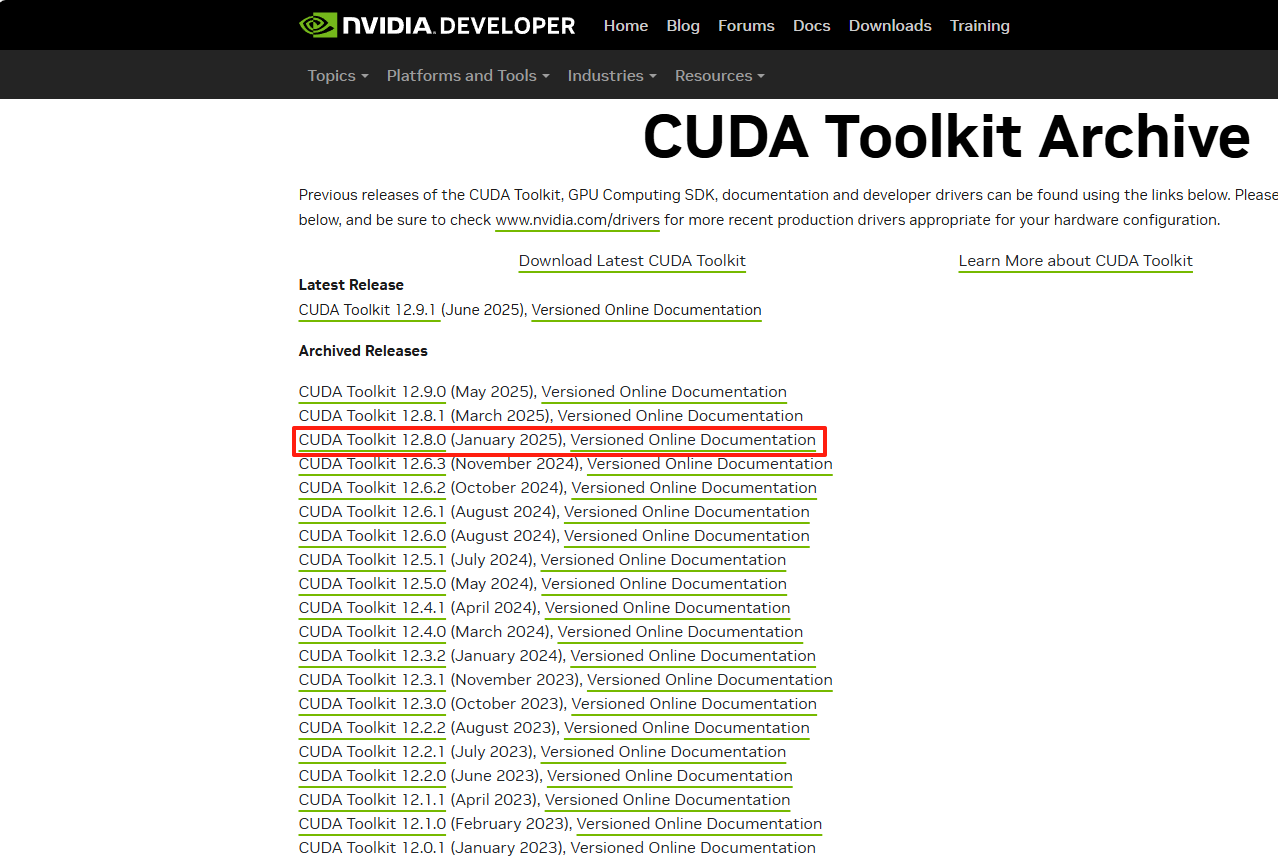
根据你的系统选择对应的版本,然后进行安装。其中安装方式,一种是本地安装,一种是在线安装,差距不大。我这里选择的在线安装【exe(network))】
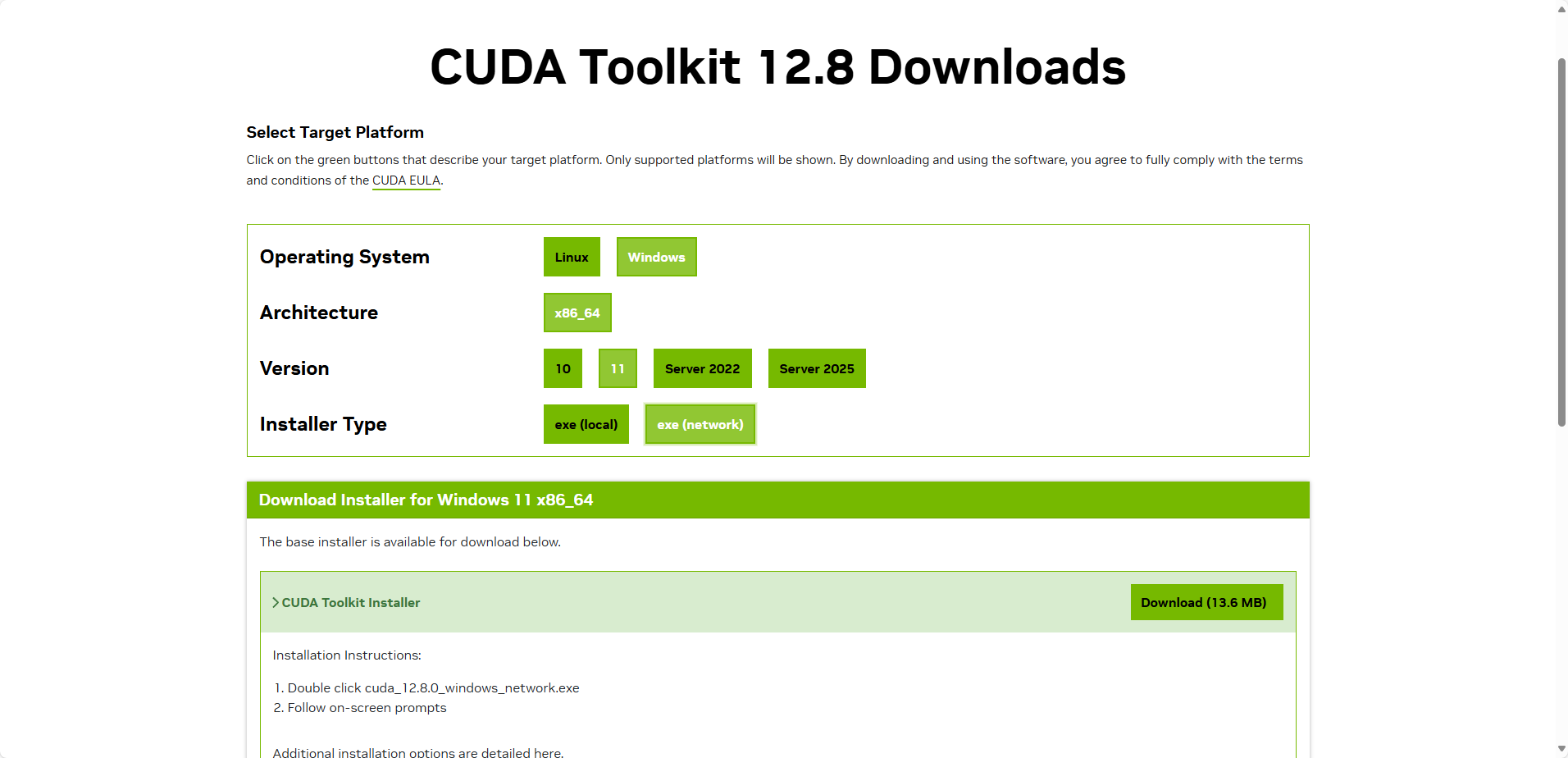
下载完成后按部就班安装完成即可,安装过程选择自定义,建议尽可能全部勾选,防止缺失内容导致后续出现麻烦。安装结束后会要求重启电脑,重启即可。
安装的过程中C盘空间够,建议默认路径就行了,虽然有点大,但是放在其它盘,可能会发生一些其它莫名其妙的问题。
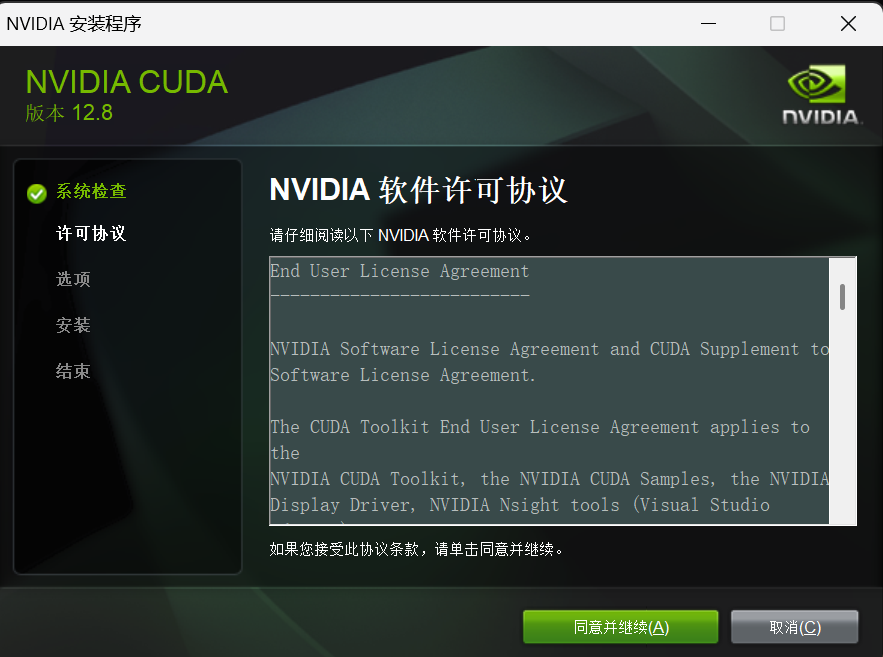
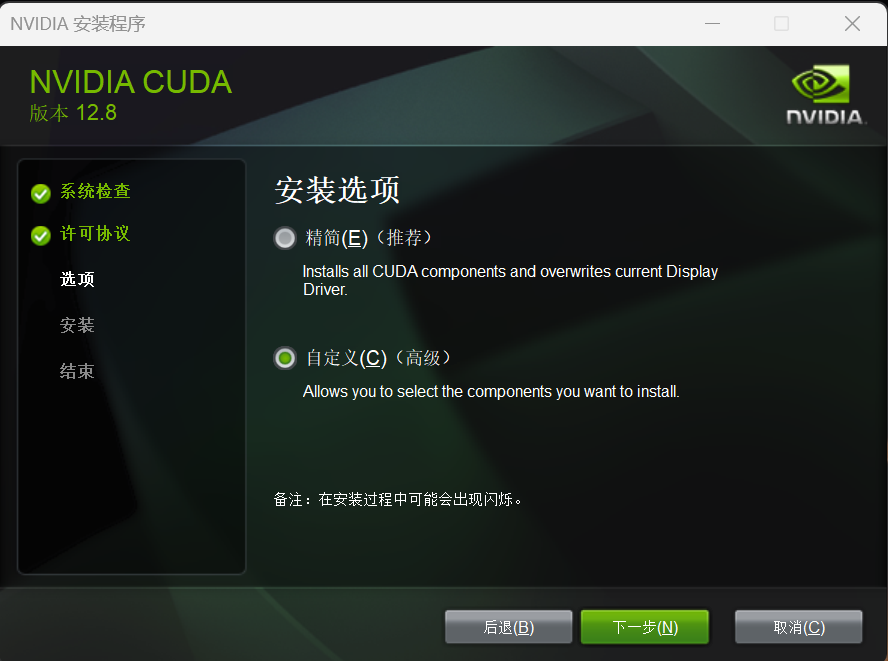
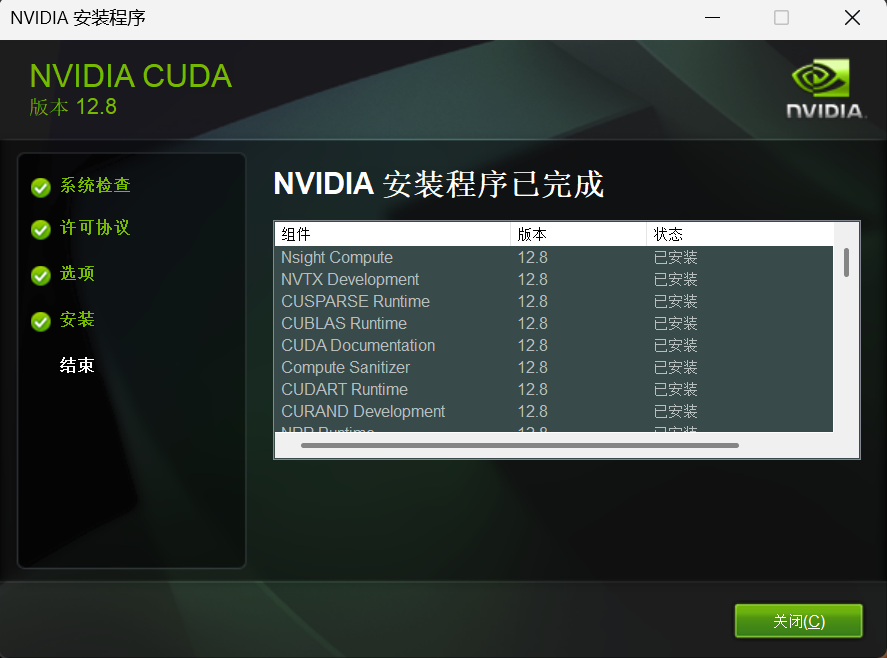
(注意:CUDA安装好后环境变量不需要配置,因为在安装之后就默认添加好了,9.0 版本之前(包括 9.0)还是需要配置环境变量的2)
安装后cmd输入命令,可以看到安装的CUDA版本信息。如图所示:
nvcc -V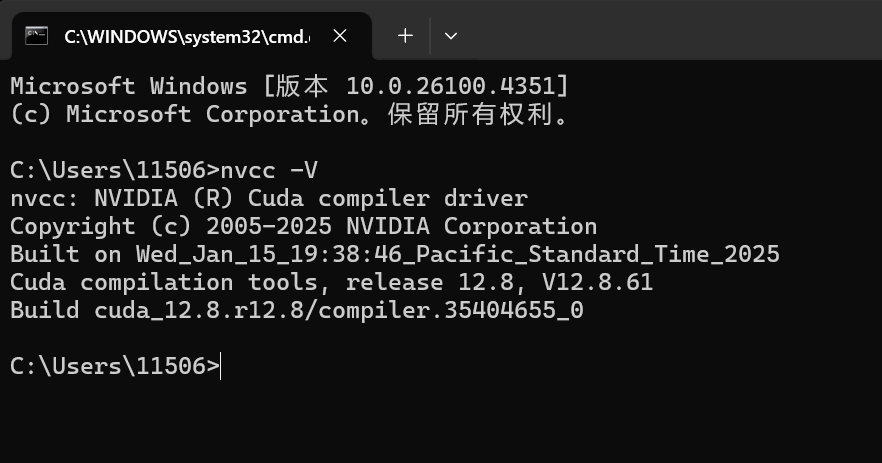
3. 安装cuDNN
安装与CUDA对应版本的cuDNN,以加速深度学习计算。
访问cuDNN官网:cuDNN Archive | NVIDIA Developer,找到对应的cuDNN版本(根据你的CUDA版本来进行选择)
老的版本还有具体的匹配关系
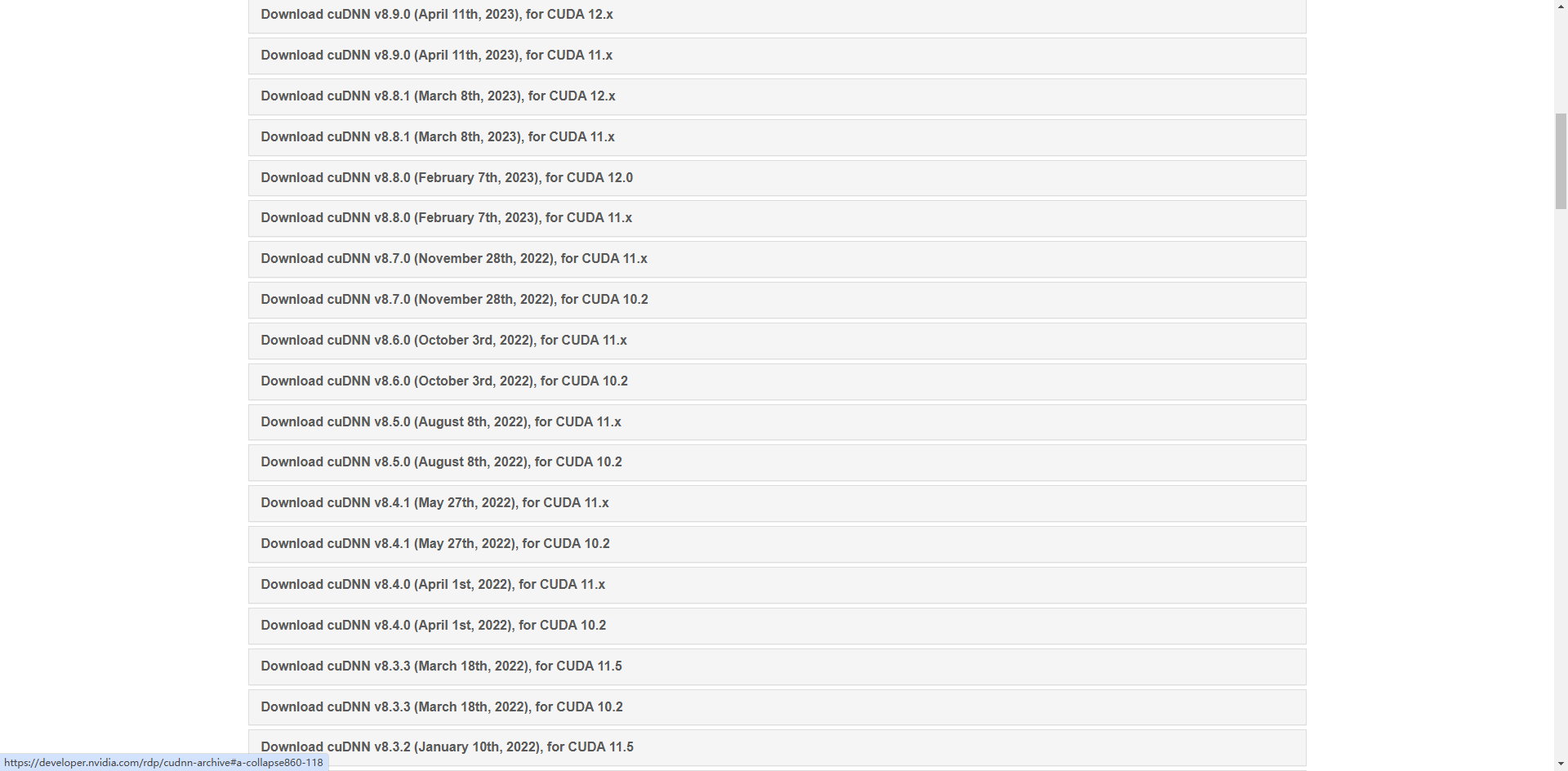
但新的版本都是11.x或12.x了,也不知道是不是全部兼容,还是咋回事。
9.0版本之后的索性不装了,直接都不标记了。初次搭建,我也是一脸懵逼。
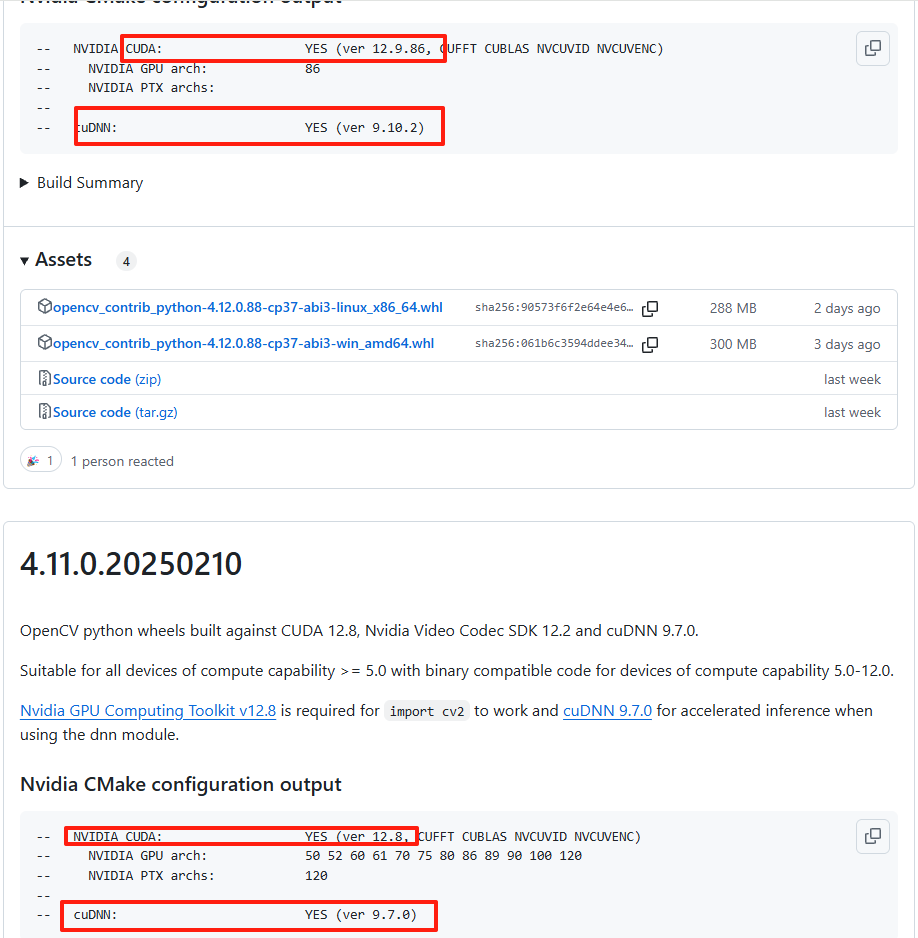
后来莫名其妙在github上发现了一个好东西。链接附上
https://github.com/cudawarped/opencv-python-cuda-wheels/releases
看图就行了,反正人家是这样搞的,我也先跟着抄吧。,于是乎,我下载了9.7.0的版本
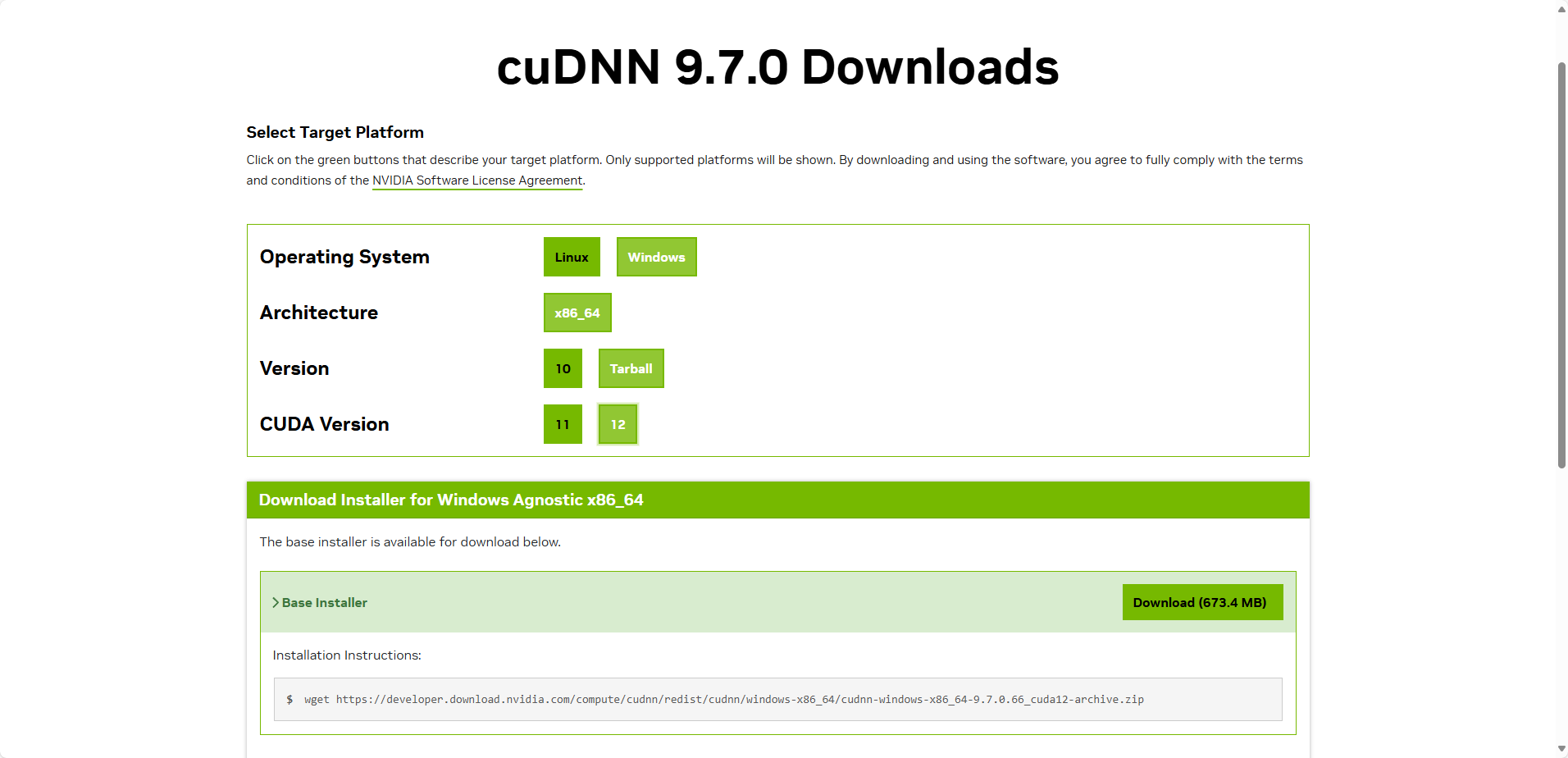
看网上搜的有人说建议是version选择10,然后选择执行安装的exe文件安装吧。由于系统是win11,又是一脸懵逼,这里选择了Tarball,然后将文件解压copy。下面详细讲解一下我的步骤吧。
下载cuDNN需要注册一个NVIDIA官网账号,使用邮箱注册,按照提示完成注册即可跳转下载cuDNN。下载完成后得到一个压缩文件,里面有三个文件夹:
将这三个文件夹拷贝到你的CUDA安装目录下,默然安装的CUDA一般路径为:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\vxx.x\
# vxx.x 为CUDA版本号,如v12.8,v12.6等自定义安装的根据实际情况选择。
实际就是替换这三个文件夹中的内容:
把 bin 目录的内容拷贝到:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\bin
把 include 目录的内容拷贝到:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\include
把 lib\x64 目录的内容拷贝到:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\lib\x644. 配置CUDA相关环境变量
将这三个路径添加到环境变量(即cuDNN的三个文件路径),如果存在不用重复添加了哈,安装CUDA的时候自动添加了一些:
具体作用,不是很清楚,有点尴尬,看见别人这样配的,照抄好用,真香~
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\lib\x64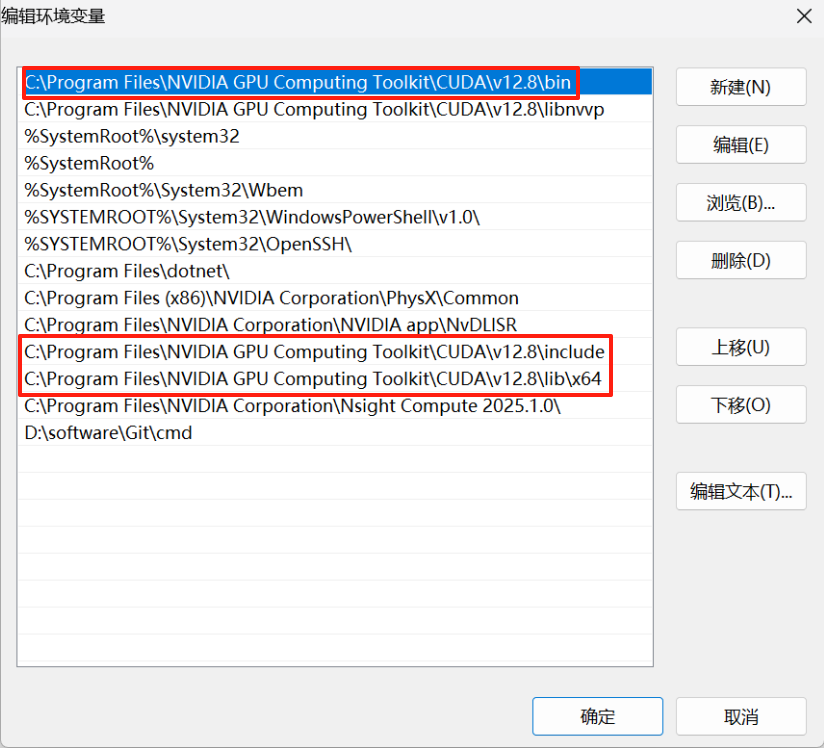
5. 检查CUDA和cuDNN是否可用
打开终端,键入 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\extras\demo_suite目录下,输入以下命令行运行检测:
(1)运行 bandwidthTest.exe
路径:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\extras\demo_suite\bandwidthTest.exe
根目录终端命令行键入回车:注意自己的目录
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\extras\demo_suite\bandwidthTest.exe显示如下: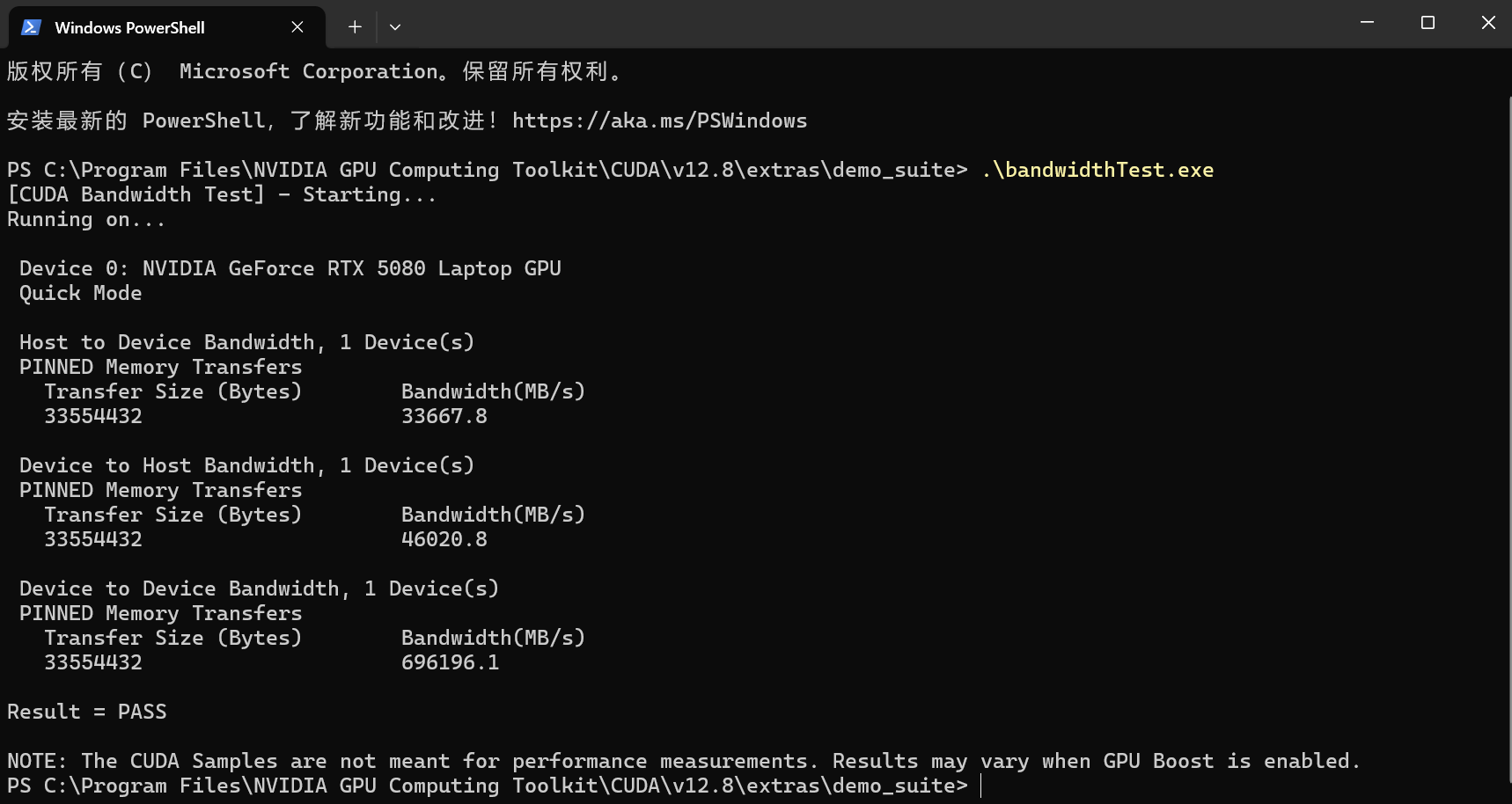
(2)运行 deviceQuery.exe
路径:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\extras\demo_suite\deviceQuery.exe
根目录终端命令行键入回车:注意自己的目录
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.8\extras\demo_suite\deviceQuery.exe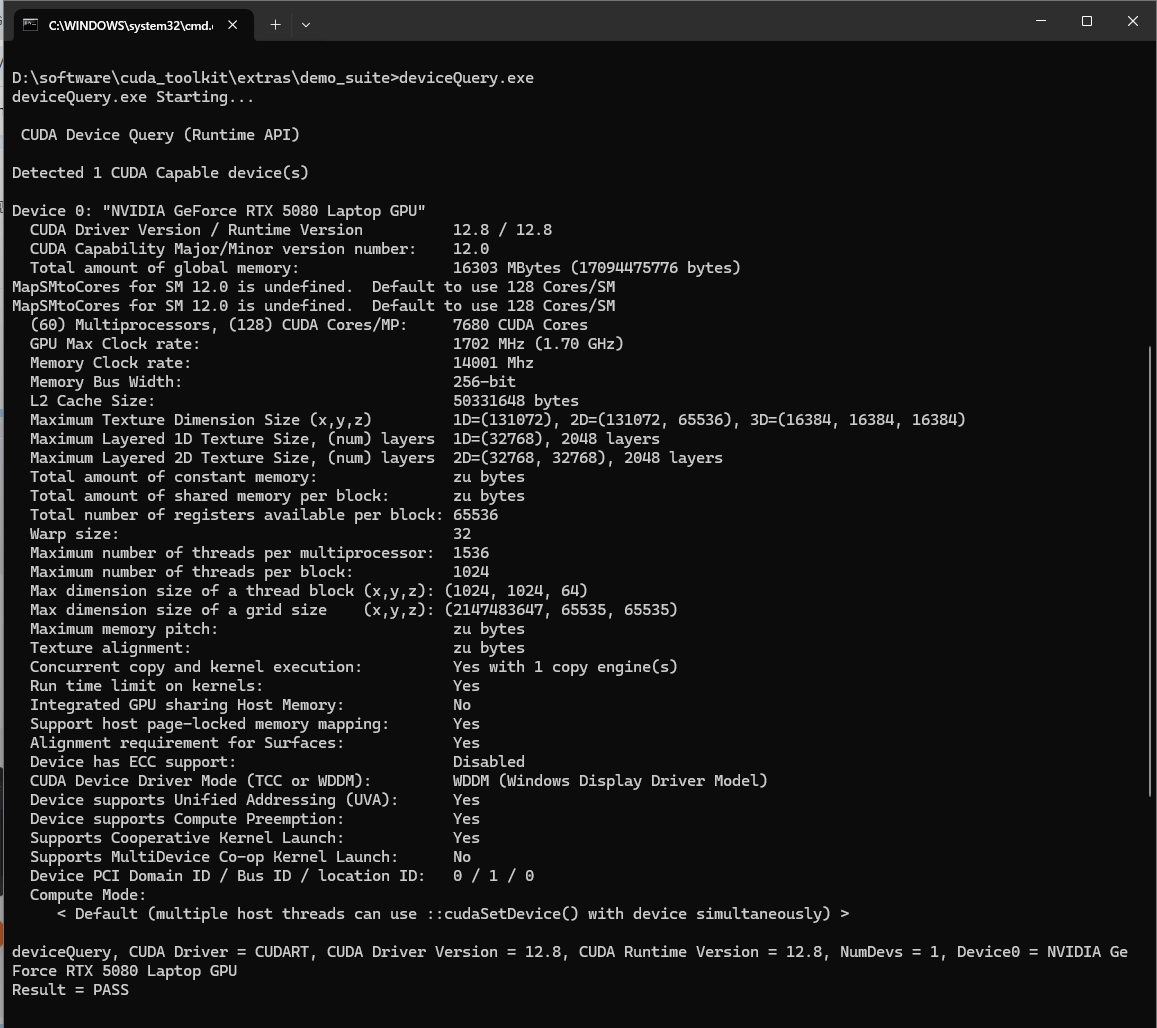
如果两个最后输出"Results=PASS",检查通过,至此,CUDA何cuDNN安装完毕!
6. 使用PyTorch
6.1 创建python环境
使用Anaconda3创建一个新的Python环境。
如果没有安装Anaconda3可以参考为文章:Anaconda3下载安装,管理Python环境,切换镜像源
6.2 安装GPU版的PyTorch
选择与CUDA版本兼容的PyTorch版本进行安装。选择与 cuda 对应的 pytorch 版本。如果安装的 cuda 版本大于 pytorch 支持的版本,请选择向下的版本。
访问PyTorch官网: Start Locally | PyTorch,根据电脑配置和CUDA版本,选择对应的PyTorch下载命令,以我为例,使用Pip下载,CUDA版本12.8,选择配置参数后将命令行进行复制。
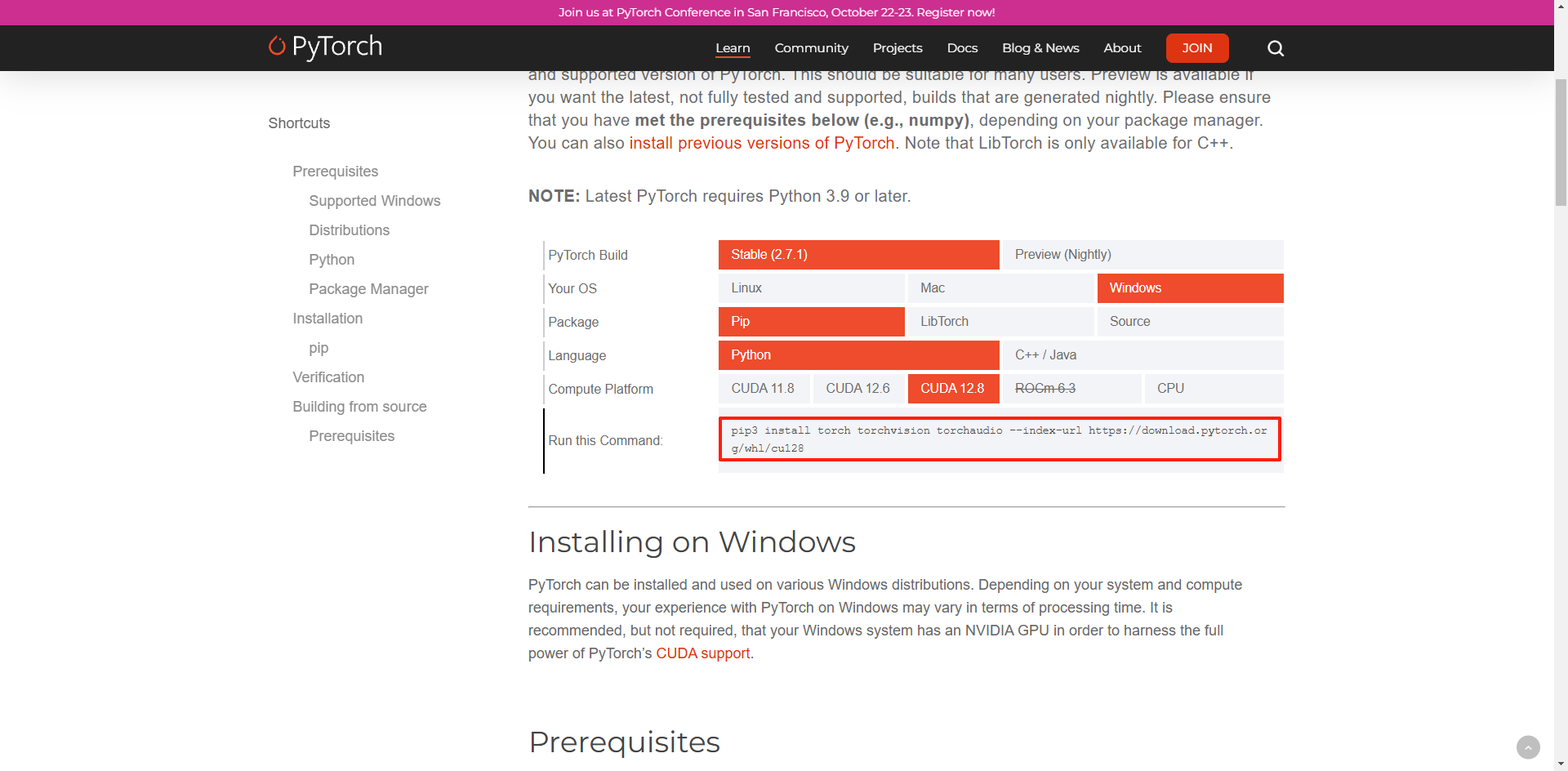
使用Anaconda Prompt,切换到我们创建的虚拟环境,粘贴复制的命令行回车安装。
由于GPU版本的Pytorch特别大,接近3个G,如果下载比较慢的话,建议使用国内镜像。
去你的ide里面,创建一个py文件,使用上面创建的环境,可以看到GPU是否可用了。接下来就可以使用GPU去愉快的进行模型训练了。
python
import torch
if torch.cuda.is_available():
print(f"GPU is available. Using GPU: {torch.cuda.get_device_name(0)}")
else:
print("GPU is not available.")7. 总结
之前一直没搞过模型训练,也是第一次使用GPU,网上很多文章,但版本大多相对较老。
本次的搭建过程可以说是磕磕绊绊,一边学习,一边整理资料,一边卸了装,装了卸。
整篇文章介绍了GPU的检测,安装CUDA,安装cuDNN,安装PyTorch,测试GPU等。
整体过程虽然磕绊,但总结下了许多宝贵的经验,希望可以帮助到需要的朋友。
数据标注、模型训练、模型使用等等,工作需要,磕磕绊绊吧,边使用,边学习,边输出。