目录
[二、Elasticsearch 全面概述](#二、Elasticsearch 全面概述)
[a. 分布式架构](#a. 分布式架构)
[b. 高性能原理](#b. 高性能原理)
[c. 数据模型创新](#c. 数据模型创新)
[a. 企业级搜索](#a. 企业级搜索)
[b. 可观测性](#b. 可观测性)
[c. 安全分析(SIEM)](#c. 安全分析(SIEM))
[7、性能基准(AWS c5.4xlarge 实测)](#7、性能基准(AWS c5.4xlarge 实测))
[三、Logstash 全面概述](#三、Logstash 全面概述)
[四、 Elasticsearch安装与配置](#四、 Elasticsearch安装与配置)
[五、 logstash安装与配置](#五、 logstash安装与配置)
[六、 kibana安装与配置](#六、 kibana安装与配置)
一.故事背景
在完成各种高可用配置之后,就要开始对Elasticsearch的研究,在安装过程中发现欧拉的系统没法直接yum安装,需要自己编译安装,所以换了一个系统来安装Elasticsearch,elkf分别指的是Elasticsearch+Logstash+Kibana+Filebeat,下面开始分开介绍
二、Elasticsearch 全面概述
1、核心定位
Elasticsearch(ES) 是开源的分布式搜索分析引擎,基于 Apache Lucene 构建,专为处理海量数据设计。核心能力包括:
实时数据分析(毫秒级响应)
全文检索(支持复杂相关性评分)
结构化/非结构化数据处理
水平扩展性(支持 PB 级数据)
核心定位 :解决传统数据库在全文检索 、复杂聚合 、实时分析场景下的性能瓶颈
2、核心特性
a. 分布式架构
| 概念 | 说明 |
|---|---|
| 节点(Node) | 独立运行实例,角色包括 Data/Master/Ingest/Coordinating |
| 集群(Cluster) | 多个节点组成的分布式系统 |
| 分片(Shard) | 数据最小单元(Primary Shard + Replica Shard) |
| 索引(Index) | 逻辑数据容器(类似数据库的表) |
b. 高性能原理
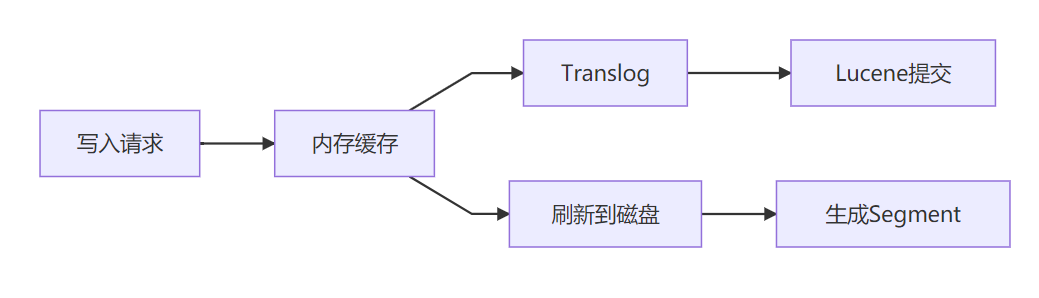
c. 数据模型创新
| 传统数据库 | Elasticsearch |
|---|---|
| 固定表结构 | Schema-free JSON文档 |
| SQL查询语言 | DSL(JSON格式查询) |
| ACID事务强一致 | 最终一致性 |
| 行存储 | 倒排索引+列存(Doc Values) |
3、核心技术组件
-
Lucene 引擎
-
倒排索引(词项→文档映射)
-
分词器(Tokenizer + Filter)
-
评分算法(TF-IDF/BM25)
-
-
分布式协调层
-
一致性协议:Raft(7.x+ 取代 Zen Discovery)
-
元数据管理:Cluster State(由 Master 节点维护)
-
-
跨组件整合
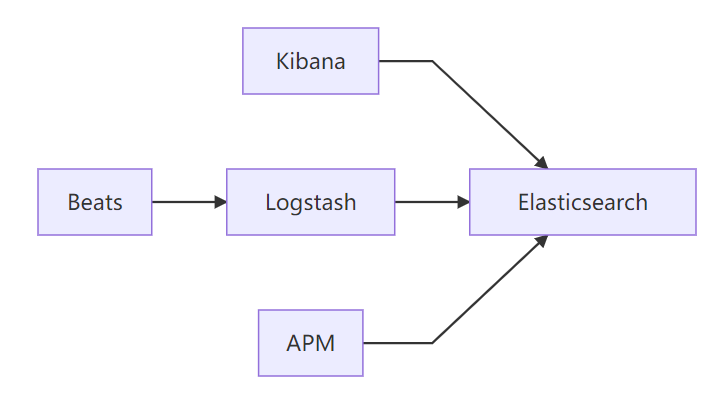
完整观测体系:日志(Logs)、指标(Metrics)、追踪(Traces)、APM(Application Performance Monitoring,应用性能监控)
4、核心应用场景
a. 企业级搜索
-
电商商品搜索(多属性过滤、相关性排序)
-
内容平台检索(标题/内容/标签联合搜索)
b. 可观测性
日志分析典型流程
filebeat → logstash(解析)→ ES → Kibana(可视化)
c. 安全分析(SIEM)
-
实时威胁检测(KQL语法)
-
异常行为模式识别
5、版本演进关键特性
| 版本 | 里程碑特性 | 影响 |
|---|---|---|
| 7.0 | 废除多 type 设计 | 简化数据模型 |
| 7.4 | 引入地理矢量搜索(GeoGrid) | GIS分析能力增强 |
| 7.8 | 内置机器学习(Data Frame) | 异常检测无需额外插件 |
| 7.12 | 可搜索快照(Searchable Snapshots) | 冷数据存储成本降低 70% |
6、核心优势对比
| 能力 | Elasticsearch | 传统关系型数据库 | Solr |
|---|---|---|---|
| 全文检索速度 | ⭐⭐⭐⭐⭐ | ⭐☆ | ⭐⭐⭐⭐ |
| 水平扩展能力 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| 聚合分析性能 | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| 数据实时性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| 事务支持 | ⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐ |
7、性能基准(AWS c5.4xlarge 实测)
| 场景 | 数据量 | QPS | 延迟(avg) |
|---|---|---|---|
| 日志写入 | 1TB/日 | 85,000 | 12ms |
| 关键词搜索 | 10亿条 | 4,200 | 35ms |
| 聚合分析 | 1PB | 120 | 1.8s |
8、适用行业
-
电商平台:商品搜索、推荐系统
-
金融科技:交易监控、风险分析
-
物联网:设备数据实时分析(50万+/秒数据点)
-
游戏行业:玩家行为分析、反作弊系统
总结 :Elasticsearch 通过创新的分布式架构和倒排索引机制,解决了传统数据库在实时搜索与分析场景的瓶颈。作为现代数据栈的核心引擎,其价值已从搜索工具演进为实时数据分析平台,成为企业数字化转型的关键基础设施。
三、Logstash 全面概述
1、Logstash概述
Logstash是一个开源的数据收集引擎,它具有强大的数据处理能力。主要功能是从多种数据源获取数据,对数据进行转换和过滤,然后将其输出到目标存储或分析系统。
作用
Logstash 是一个数据收集引擎,它可以从多个数据源(如文件、数据库、消息队列等)收集数据,对数据进行转换和过滤,然后将其发送到其他存储或分析工具(如 Elasticsearch)。例如,它可以从各种服务器上的日志文件中收集日志,对日志进行解析,提取出有用的信息(如时间戳、日志级别、消息内容等),还可以对数据进行清洗,去除不需要的信息或者对敏感信息进行脱敏处理
数据输入源的多样性:可以从文件(如系统日志文件、应用程序日志文件)、数据库(通过JDBC等方式)、消息队列(如Kafka、RabbitMQ)、网络协议(如HTTP、TCP、UDP)等多种渠道收集数据。例如,在一个微服务架构的系统中,Logstash可以从各个微服务产生的日志文件以及消息队列中的消息获取数据。
数据转换和过滤功能:它能够解析、修改和丰富收集到的数据。比如,可以将日志文件中的文本内容按照特定的格式(如JSON、CSV等)进行解析,提取关键信息;对敏感数据进行脱敏处理;根据某些条件过滤掉不需要的数据。
数据输出的灵活性:能够将处理后的数据输出到各种存储和分析工具,如Elasticsearch(用于存储和全文搜索)、Redis(用于缓存或简单的数据存储)、文件系统等。这样可以方便地将数据整合到现有的数据处理和分析流程中。
2、Logstash配置文件结构
Logstash的配置文件是基于JSON样式的配置语言编写的,主要由三个部分组成:input(输入)、filter(过滤)和output(输出)。
input部分:
定义了数据的来源。例如,从文件读取数据的配置如下:
input {
file {
path => "/var/log/messages"
start_position => "beginning"
}
}
这里file是输入插件类型,表示从文件读取数据。path参数指定了要读取的日志文件路径,start_position参数表示从文件的开头(beginning)还是结尾(end)开始读取。如果要从网络端口接收数据,可以使用tcp或udp输入插件,如:
input {
tcp {
port => 5000
codec => json_lines
}
}
此配置通过tcp插件监听5000端口,使用json_lines编解码器来解析接收到的JSON格式的数据行。
filter部分:
用于对输入的数据进行处理。例如,使用grok过滤器来解析日志中的内容。假设我们有一个常见的Nginx访问日志格式,配置可以是:
filter {
grok {
match => { "message" => '%{IPORHOST:clientip} - %{USERNAME:ident} - %{USERNAME:auth} \%{HTTPDATE:timestamp}\\ "%{WORD:verb} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:response} %{NUMBER:bytes} "%{GREEDYDATA:referrer}" "%{GREEDYDATA:agent}"' }
}
}
这个grok过滤器会根据指定的模式(match)来解析message字段(假设输入的数据中有这个字段),将其中的IP地址、用户名、时间戳、请求方法等信息提取出来,分别赋值给新的字段(如clientip、ident等)。
还可以使用mutate过滤器来修改字段,比如将字符串转换为整数:
filter {
mutate {
convert => {
"response" => "integer"
}
}
}
此配置会将response字段从字符串类型转换为整数类型。
output部分:
确定了数据的输出目标。例如,将数据输出到Elasticsearch的配置:
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "logstash-logs"
}
}
这里elasticsearch是输出插件类型。hosts参数指定了Elasticsearch的主机地址列表,index参数定义了数据要存储到Elasticsearch中的索引名称。如果要将数据输出到文件,可以使用file输出插件:
output {
file {
path => "/var/log/logstash/output.log"
}
}
这个配置会将处理后的数据写入到/var/log/logstash/output.log文件中。
3、常用插件详细介绍
输入插件
jdbc插件:
用于从数据库中读取数据。需要配置数据库连接信息,如jdbc_connection_string(数据库连接字符串)、jdbc_user(用户名)和jdbc_password(密码)等。例如:
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://localhost:3306/mydb"
jdbc_user => "user"
jdbc_password => "password"
statement => "SELECT * FROM mytable"
}
}
这个配置会通过JDBC连接到本地的MySQL数据库,执行SELECT * FROM mytable语句来获取数据。
file(文件输入插件)
-
功能:从文件系统中的文件读取数据。它会跟踪文件的变化,例如新行的添加,非常适合处理日志文件。可以配置为按行读取,并且能够处理多种文件编码。
-
示例配置:
input {
file {
path => "/var/log/messages"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
- 在这个示例中,Logstash会从
/var/log/messages文件读取数据。start_position => "beginning"表示从文件开头开始读取,sincedb_path => "/dev/null"用于忽略默认的记录文件读取位置的数据库,这样每次启动都从指定位置读取。
stdin(标准输入插件)
-
功能:允许从标准输入读取数据。这在测试Logstash管道或者需要手动输入数据进行处理时非常有用。
-
示例配置:
input {
stdin { }
}
- 配置很简单,启用后可以在Logstash运行时通过命令行手动输入数据,这些数据会按照Logstash的管道配置进行处理。
syslog(系统日志输入插件)
-
功能:用于接收通过syslog协议发送的系统日志消息。它可以监听指定的UDP或TCP端口,支持RFC3164和RFC5424格式的syslog消息。
-
示例配置:
input {
syslog {
port => 514
type => "syslog"
}
}
- 此配置会让Logstash在端口514上监听syslog消息,并且为这些消息设置一个
type为syslog的标签,方便后续在过滤器和输出阶段进行处理。
beats(Beats输入插件)
-
功能:用于接收来自Elastic Beats(如Filebeat、Metricbeat等)发送的数据。Beats是轻量级的数据采集器,它们可以将数据发送到Logstash进行进一步的处理和转发。
-
示例配置:
input {
beats {
port => 5044
}
}
- 这个配置会让Logstash在端口5044上监听来自Beats的数据。
http(HTTP输入插件)
-
功能:允许通过HTTP协议接收数据。可以设置端点来接收POST请求等,用于接收来自Web应用程序或其他能够通过HTTP发送数据的源的数据。
-
示例配置:
input {
http {
host => "0.0.0.0"
port => 8080
codec => "json"
}
}
- 这里配置Logstash在
0.0.0.0:8080上监听HTTP请求,并且期望接收的数据是JSON格式,接收到的数据会根据Logstash的管道流程进行后续处理。
过滤插件
grok插件:
是Logstash中非常强大的文本解析插件。它使用一种类似于正则表达式的语法来匹配和提取数据。除了前面的示例,还可以自定义模式。例如,如果有一个自定义的日志格式,其中包含一个以KEY:VALUE形式的字段,可以定义一个新的模式:
grok {
add_pattern => {
"CUSTOM_PATTERN" => "\%{WORD:key}:%{GREEDYDATA:value}\\"
}
match => { "message" => '%{CUSTOM_PATTERN}' }
}
这里先添加了一个名为CUSTOM_PATTERN的模式,然后使用这个模式来解析message字段。
date插件:
用于解析日期时间字段,并将其转换为Logstash内部的时间格式。例如:
这个配置会将timestamp字段按照dd/MMM/yyyy:HH:mm:ss Z的格式解析为日期时间,然后将结果存储到新的log_date字段中。
输出插件
elasticsearch插件:
除了基本的hosts和index参数,还有document_type参数(在较新的Elasticsearch版本中可能不再常用,但在某些旧版本或特定场景下仍有作用)。例如:
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "logstash-logs"
document_type => "log"
}
}
此配置将数据存储到logstash - logs索引中,文档类型为log。另外,还可以配置批量发送数据的参数,如batch_size(每次批量发送的数据量)和worker_threads(用于发送数据的线程数),以提高数据发送效率。
stdout插件:
用于将数据输出到控制台,方便调试。可以配置输出的格式,如codec(编解码器)。例如:
output {
stdout {
codec => rubydebug
}
}
这个配置会使用rubydebug格式将数据输出到控制台,这种格式会详细地显示数据的结构和内容。
4、logstash中的条件判断
1.条件判断语句类型
if语句
作用:if语句是最常用的条件判断语句。它根据给定的条件决定是否执行代码块中的操作。如果条件为真,则执行if语句块内的操作;如果条件为假,则跳过该语句块。
语法示例:
if field_name == "value" {
#操作,如mutate、drop等操作
}
应用场景:例如,在处理日志数据时,若只想处理日志级别为INFO的日志,可以使用if语句判断log_level == "INFO",然后在语句块中对这些日志进行字段添加、数据转换等操作。
unless语句
作用:unless语句与if语句逻辑相反。当条件为假时,执行unless语句块内的操作;当条件为真时,跳过该语句块。
语法示例:
unless field_name == "value" {
#操作,如mutate、drop等操作
}
应用场景:假设不想处理来自某个特定IP地址的日志,就可以使用unless语句。例如,unless client_ip == "192.168.1.1",在语句块中对非该IP地址的日志进行处理。
case语句(在mutate插件中)
作用:case语句用于多分支条件判断。它根据一个字段的不同取值来执行不同的操作,类似于编程语言中的switch语句。
语法示例:
mutate {
case field_name {
"value1" => {
#操作1
}
"value2" => {
#操作2
}
default => {
#当字段值不匹配前面任何一个分支时执行的操作
}
}
}
应用场景:当日志中有一个表示事件类型的字段,如event_type,可以根据不同的事件类型(如"login"、"logout"等)执行不同的字段添加或修改操作。
2.条件表达式中的操作符
比较操作符
相等(==)和不等(!=)
解释:用于判断两个值是否相等或不相等。在Logstash中,可以用于比较字段值与常量,或者两个字段值之间的比较。
示例:
if log_level == "ERROR":判断log_level字段的值是否等于ERROR。
if field1!= field2:判断field1和field2两个字段的值是否不相等。
大小比较操作符(>、>=、<、<=)
解释:用于比较数值型字段的值大小关系。这些操作符在比较日志中的时间戳、计数等数值型数据时很有用。
示例:
if count > 10:判断count字段的值是否大于10。
if response_time <= 500:判断response_time字段的值是否小于等于500(单位可能是毫秒等)。
正则表达式匹配操作符(=~和!~)
解释:=~用于判断一个字段的值是否匹配给定的正则表达式,!~则用于判断一个字段的值是否不匹配给定的正则表达式。正则表达式在处理文本格式的日志数据时非常强大,可以用于匹配特定的模式。
示例:
if message =~ /error/:判断message字段的值是否包含error这个单词(简单的正则表达式示例)。
if user_agent!~ /^Mozilla/:判断user_agent字段的值是否不以Mozilla开头。
逻辑操作符
与(&&)和或(||)
解释:用于组合多个条件。&&表示只有当所有条件都为真时,整个表达式才为真;||表示只要有一个条件为真,整个表达式就为真。
示例:
if (log_level == "WARN" && count > 5):判断log_level是否为WARN并且count是否大于5。
if (source_ip == "192.168.1.1" || source_ip == "10.0.0.1"):判断source_ip是否为192.168.1.1或者是否为10.0.0.1。
包含和不包含操作符(in和not in)
解释:用于判断一个值是否在一个数组或者集合类型的字段中,或者不在其中。在Logstash中,一些插件可能会生成包含多个标签(tags)的字段,这些操作符就可以用于判断某个标签是否存在。
示例:
if "error" in tags:判断tags字段中是否包含error这个标签。
i
f "debug" not in tags:判断tags字段中是否不包含debug这个标签。
四、 Elasticsearch安装与配置
(使用Rocky8系统)
修改主机名

将elasticsearch软件包拷贝至elk主机执行安装
对时
检查java版本

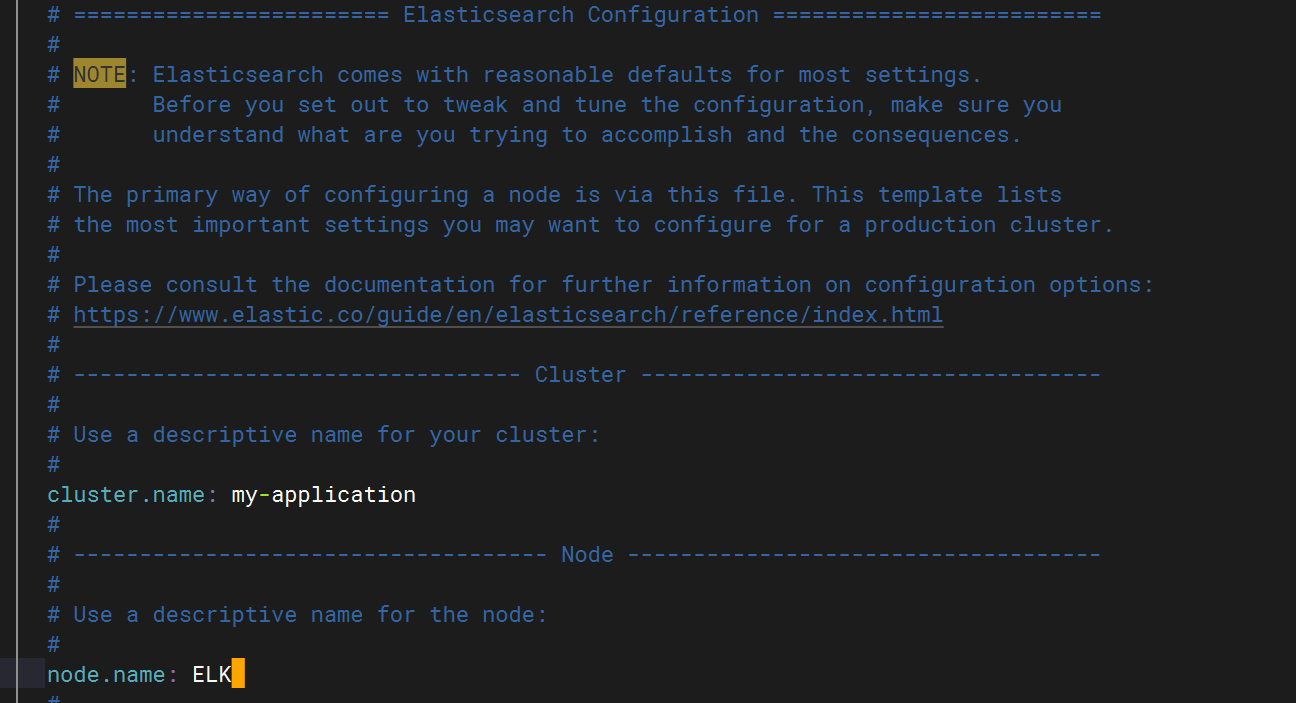
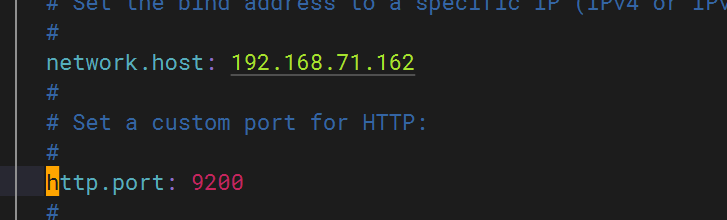
配置elasticsearch 文件

 配置主机名解析
配置主机名解析

启动elasticsearch服务 并验证启动结果

五、 logstash安装与配置
将logstash软件包拷贝至elk主机执行安装
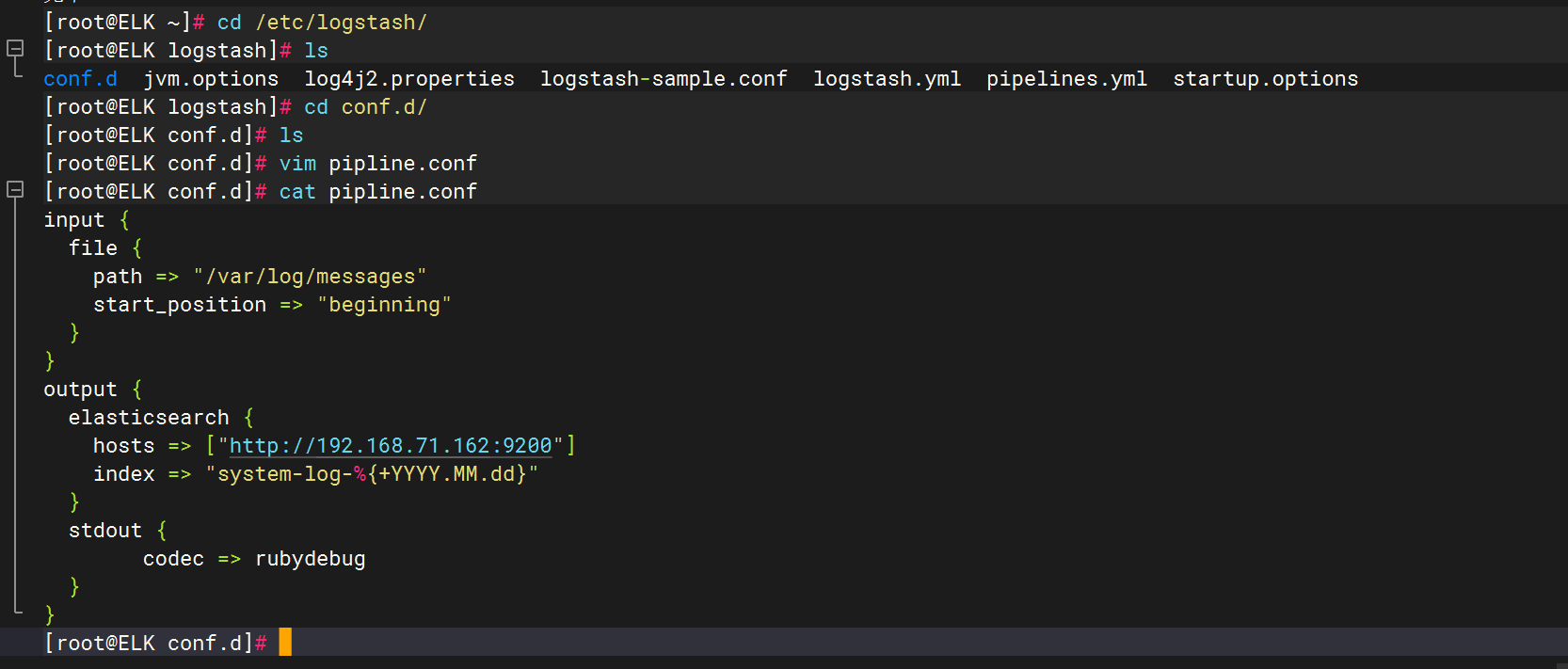
创建配置文件
input {
file {
path => "/var/log/messages"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["http://192.168.71.162:9200"]
index => "system-log-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
优化logstash命令

测试logstash服务的数据传输
标准输入与输出
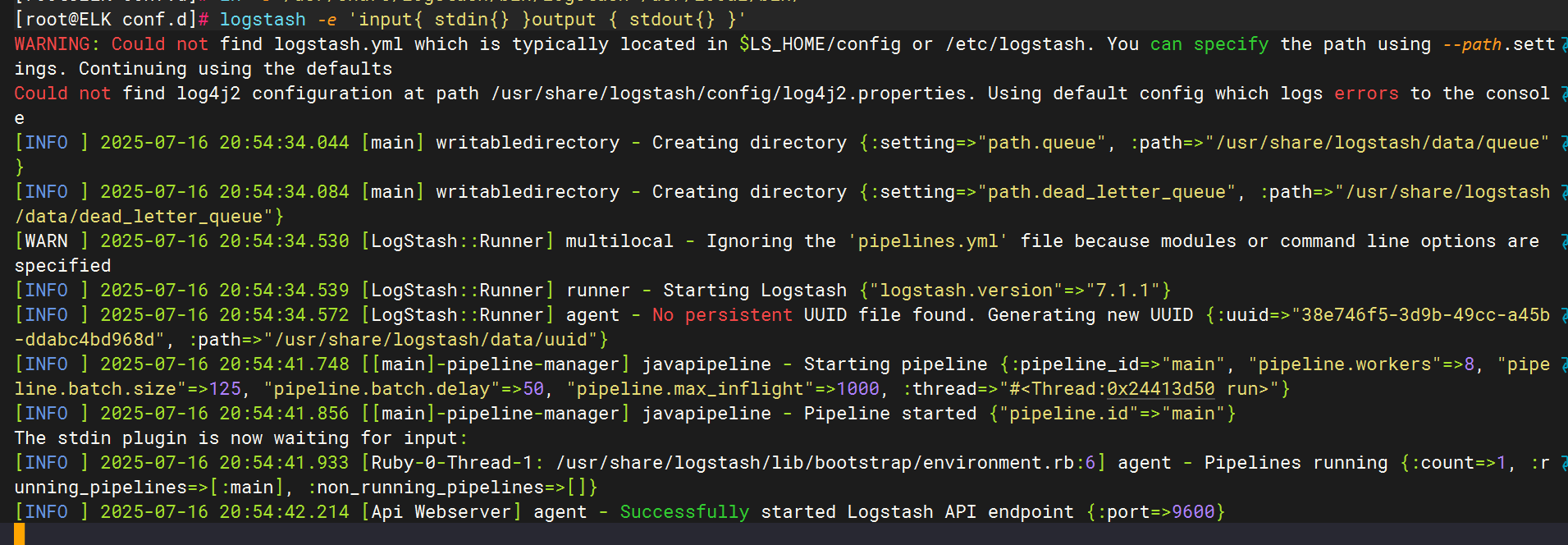
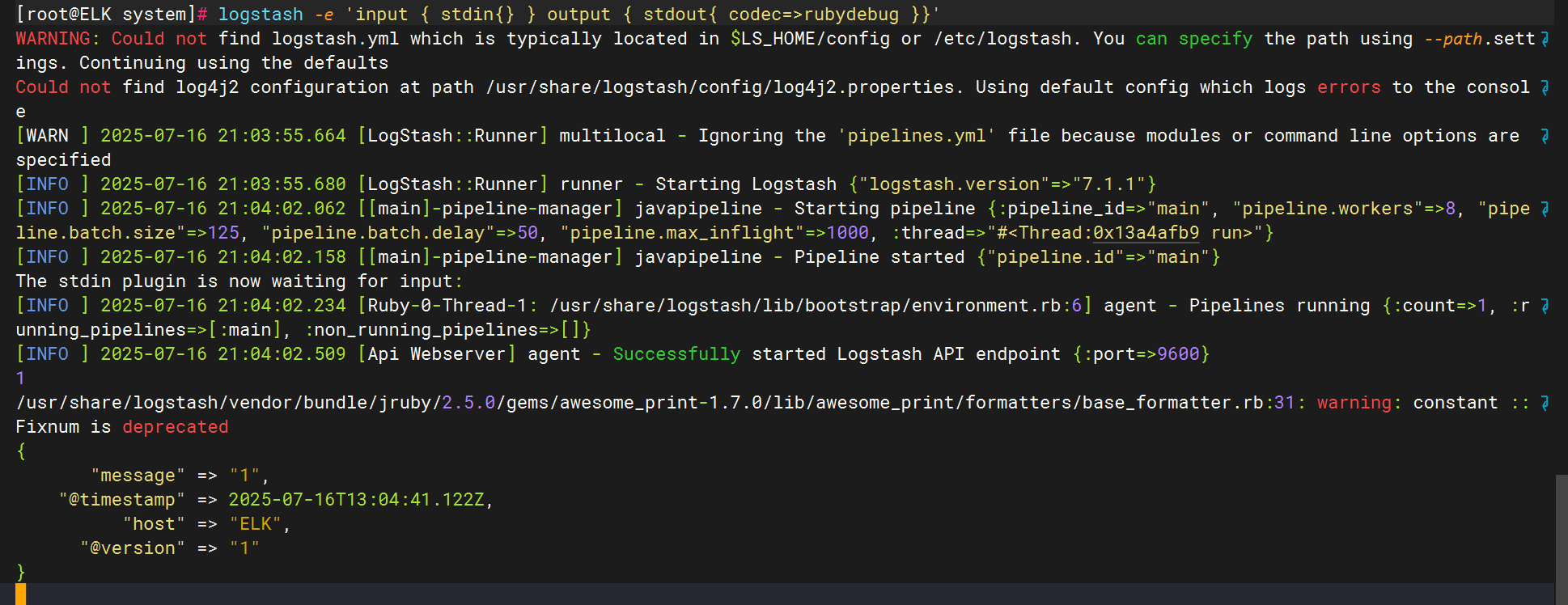
使用rubydebug解码
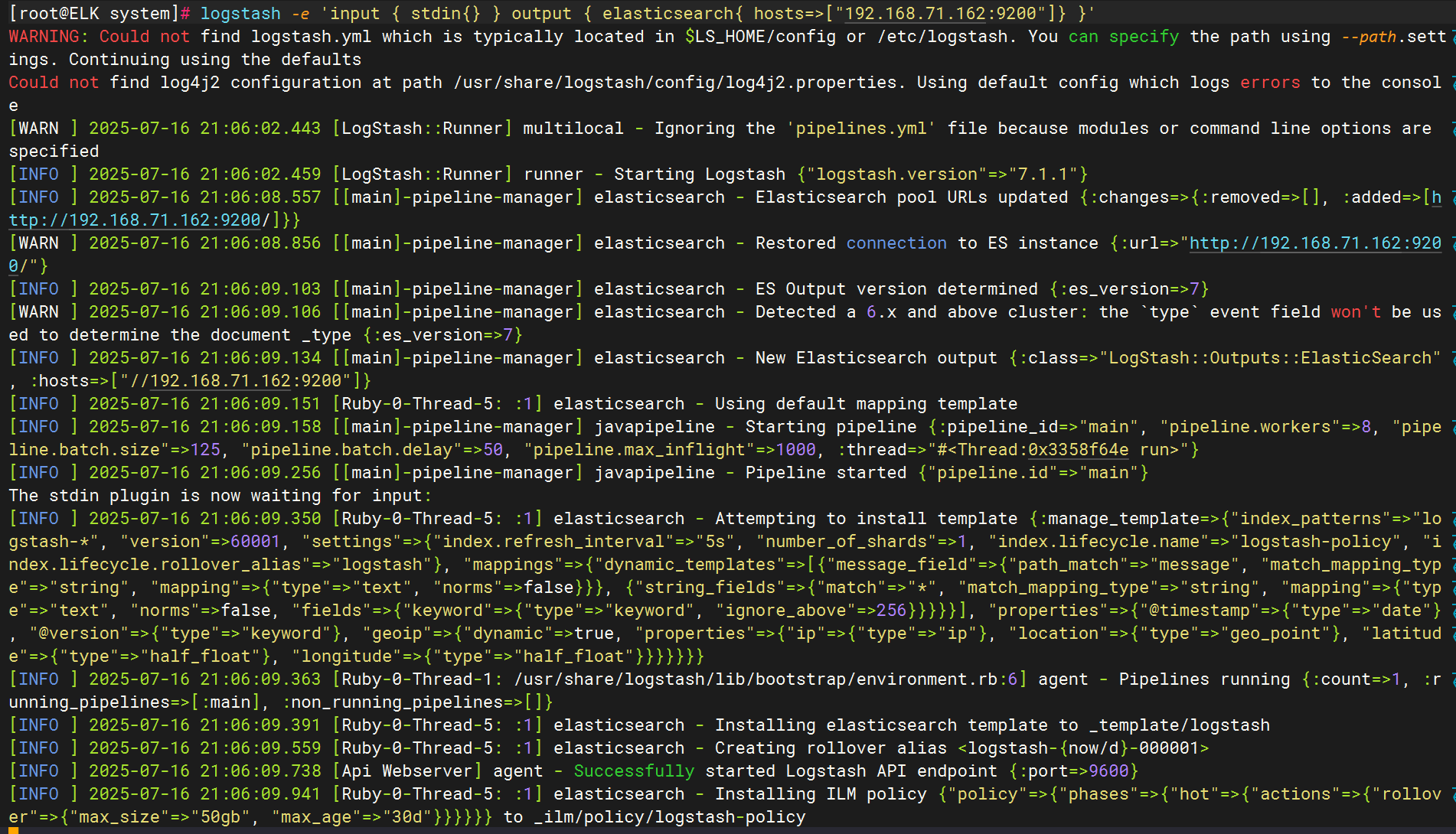
输出到elasticsearch
登录到9200端口
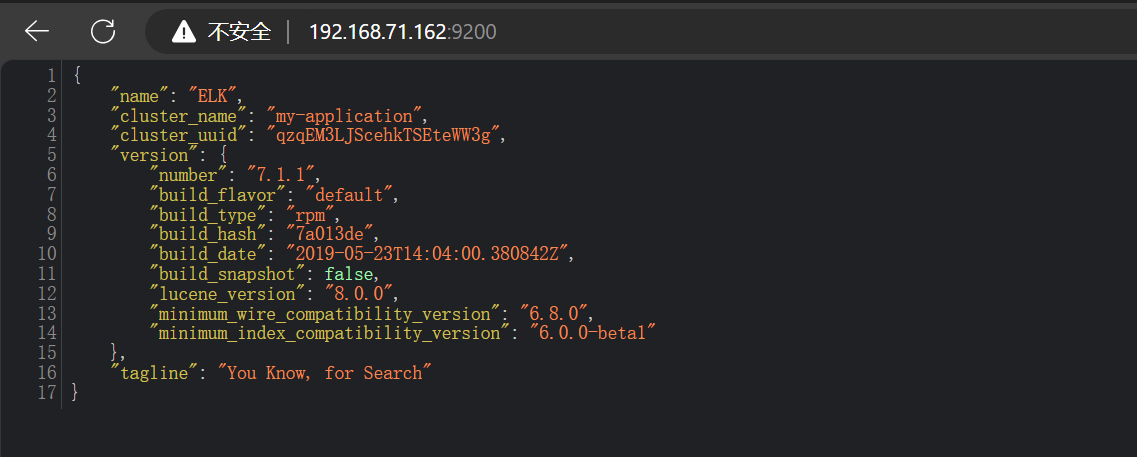
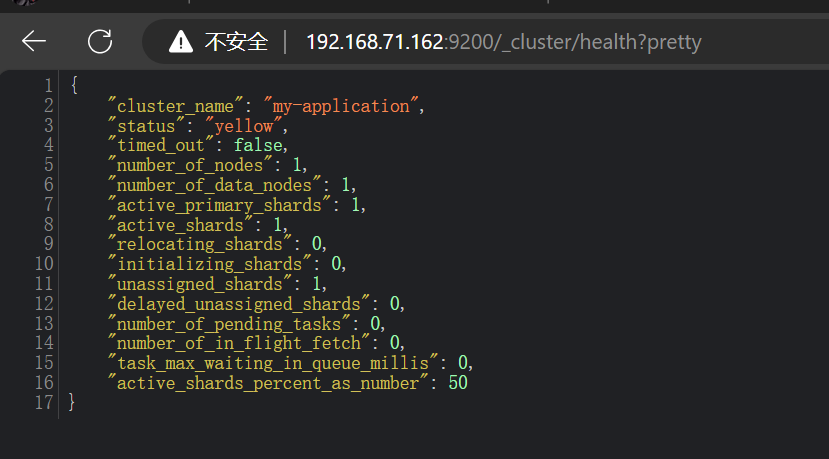
查看集群健康状态
六、 kibana安装与配置
将kibana软件包拷贝至elk主机执行安装
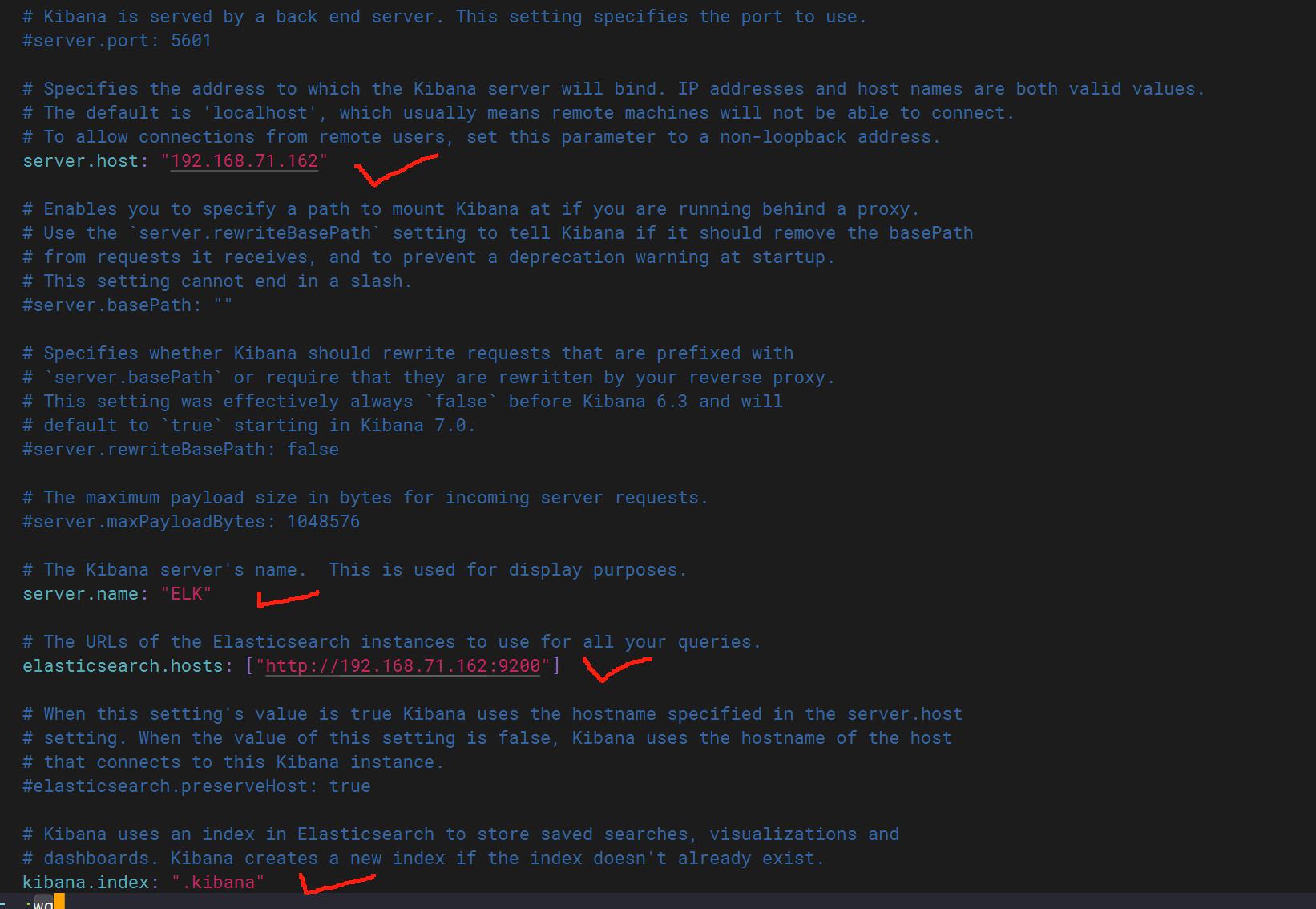
配置kibana 文件

启动kibana并查看状态

正常后,登录5601端口进入kibana页面
从配置文件最后一行中修改为中文方便查看

重启服务并刷新界面

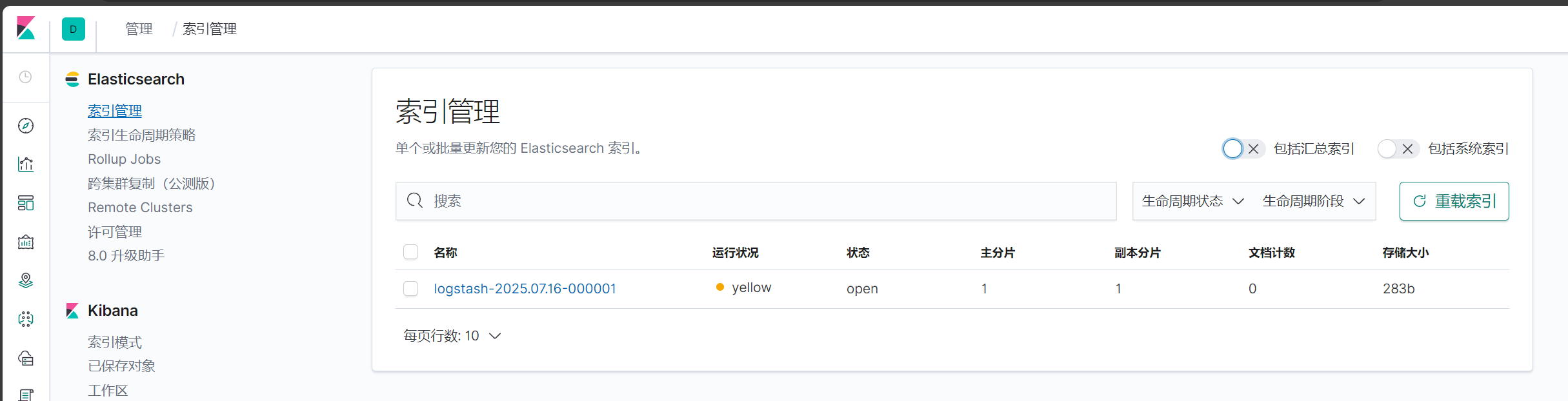
点击自己浏览后点击索引管理
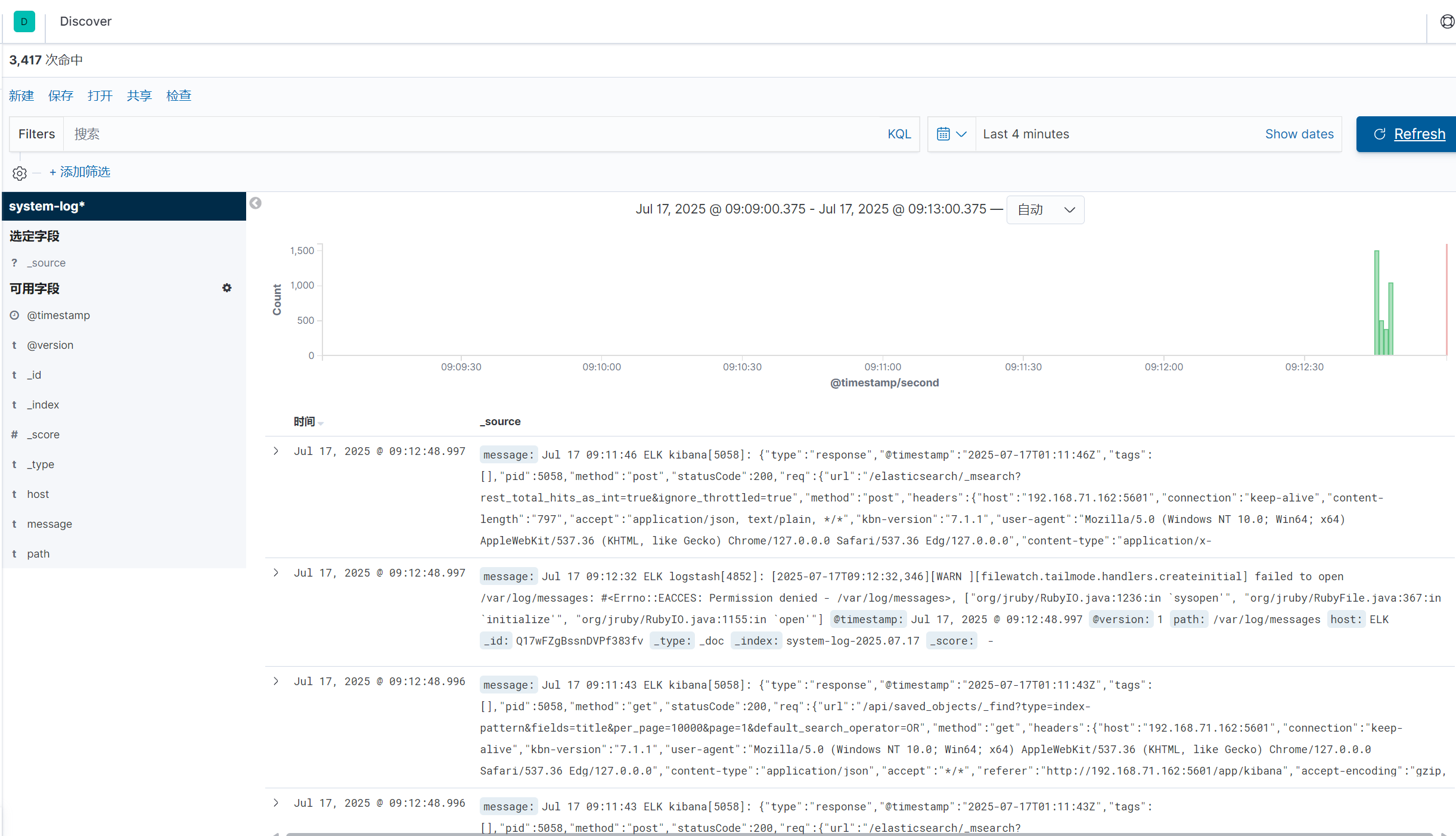
使用logstash -f /etc/logstash/conf.d/pipline.conf 命令监控日志信息
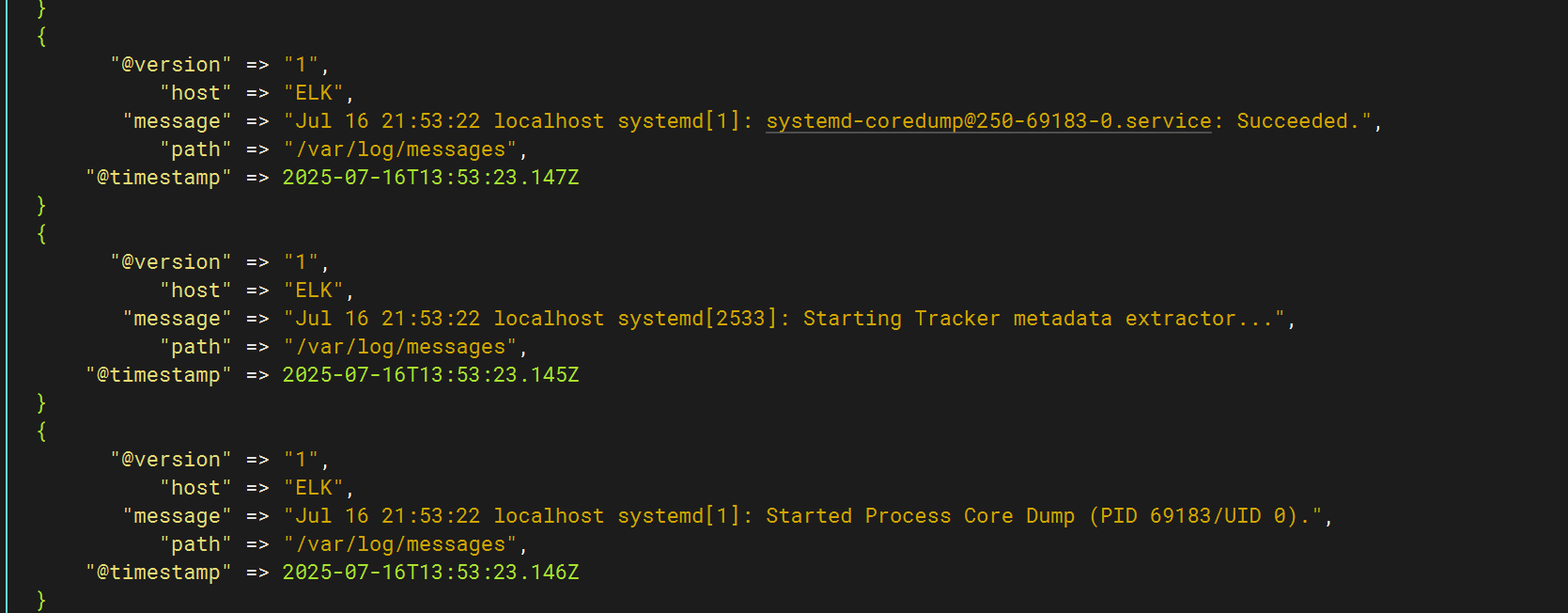
与此同时kibana页面同步出日志内容
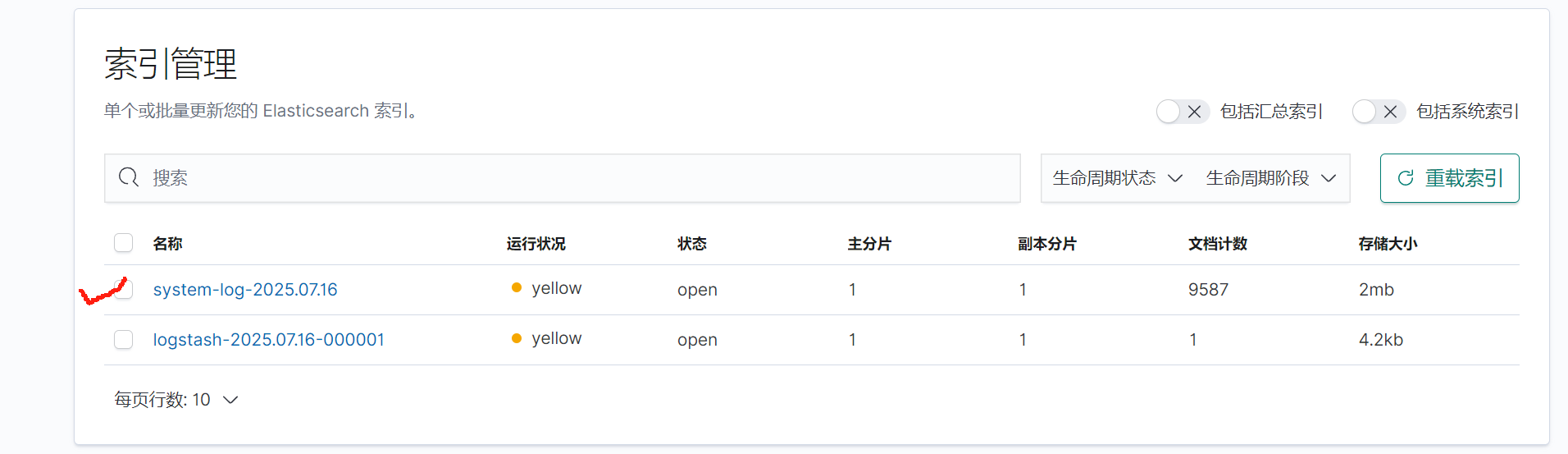
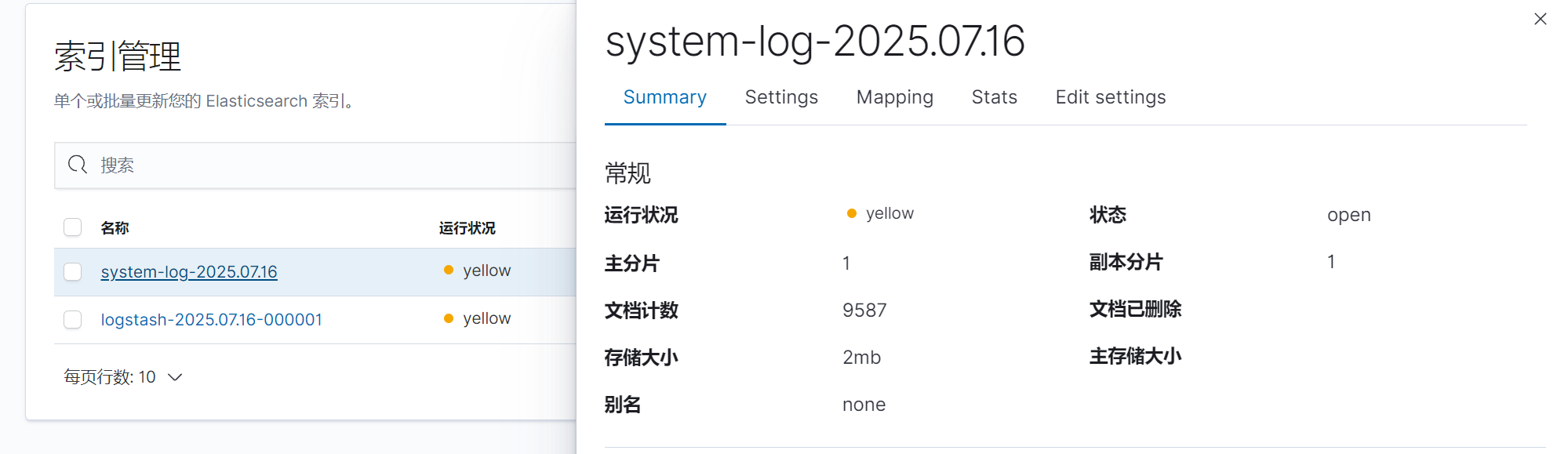
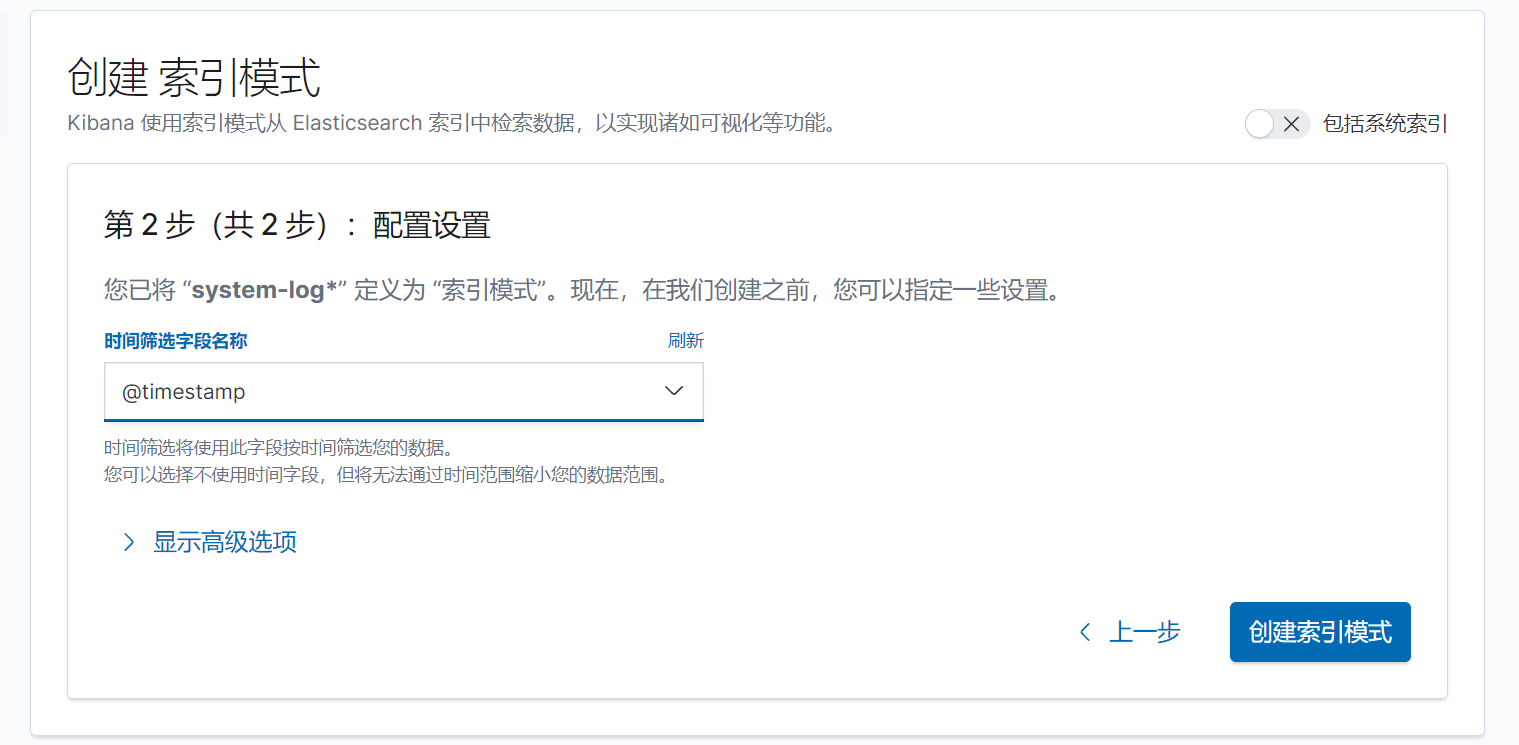
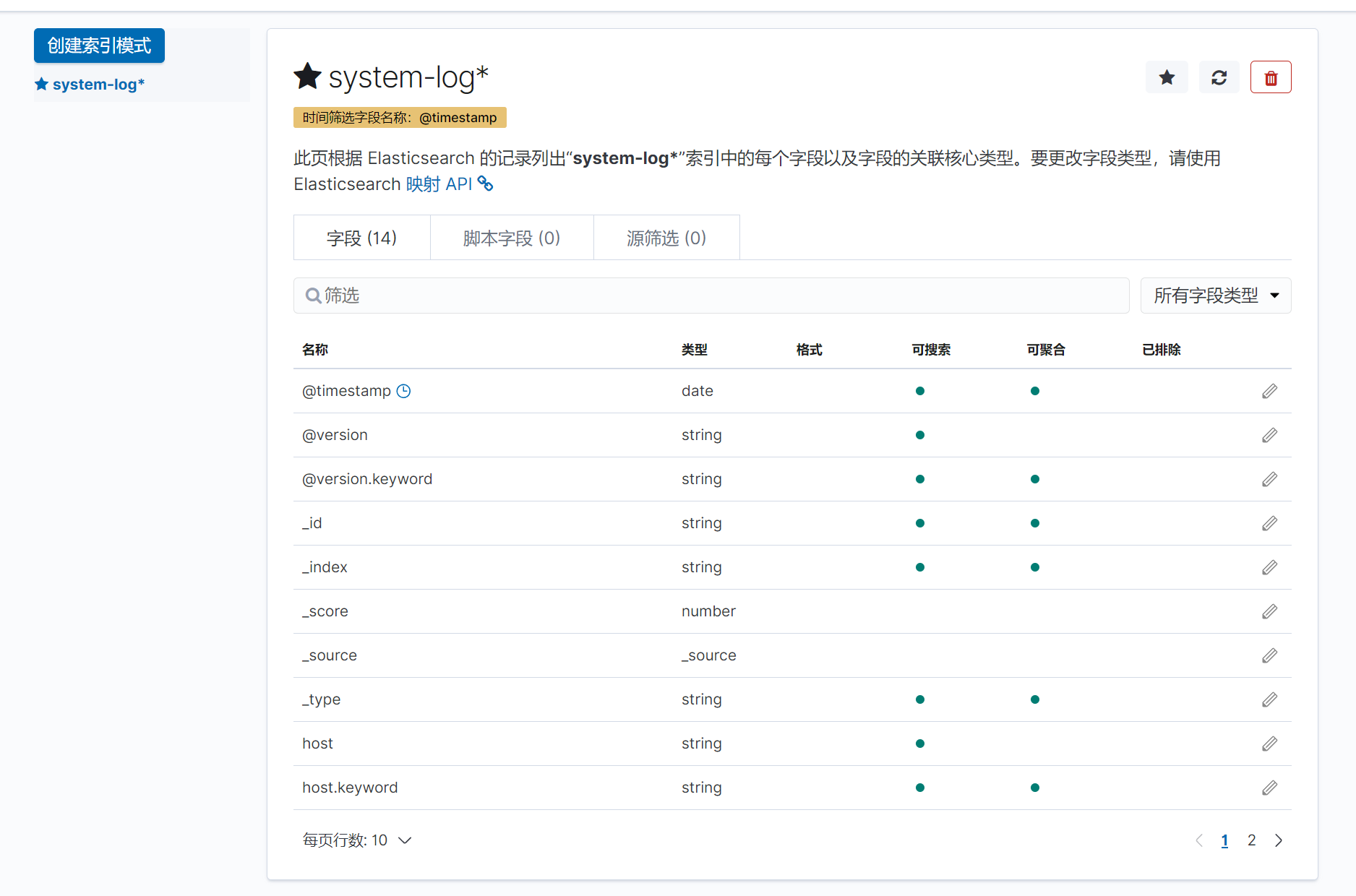
创建索引
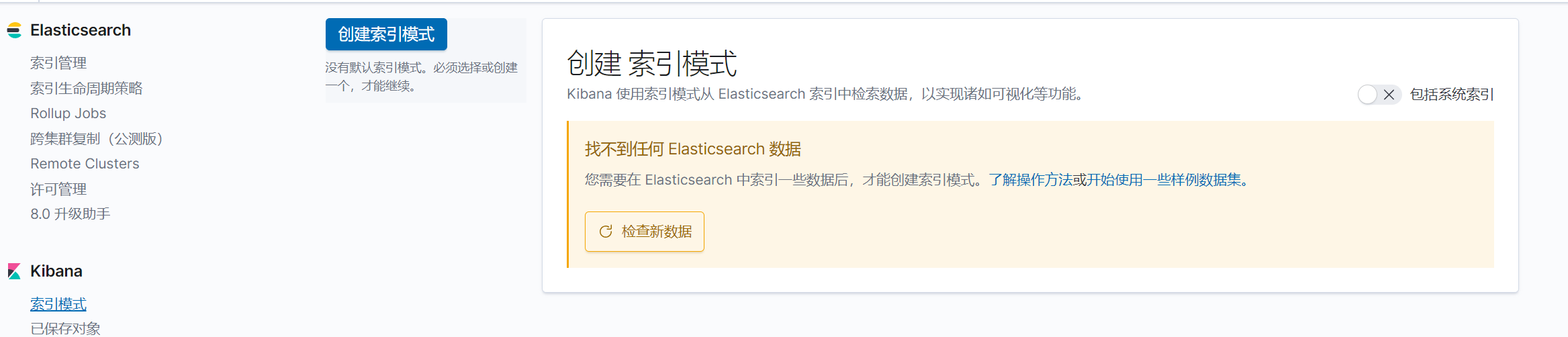
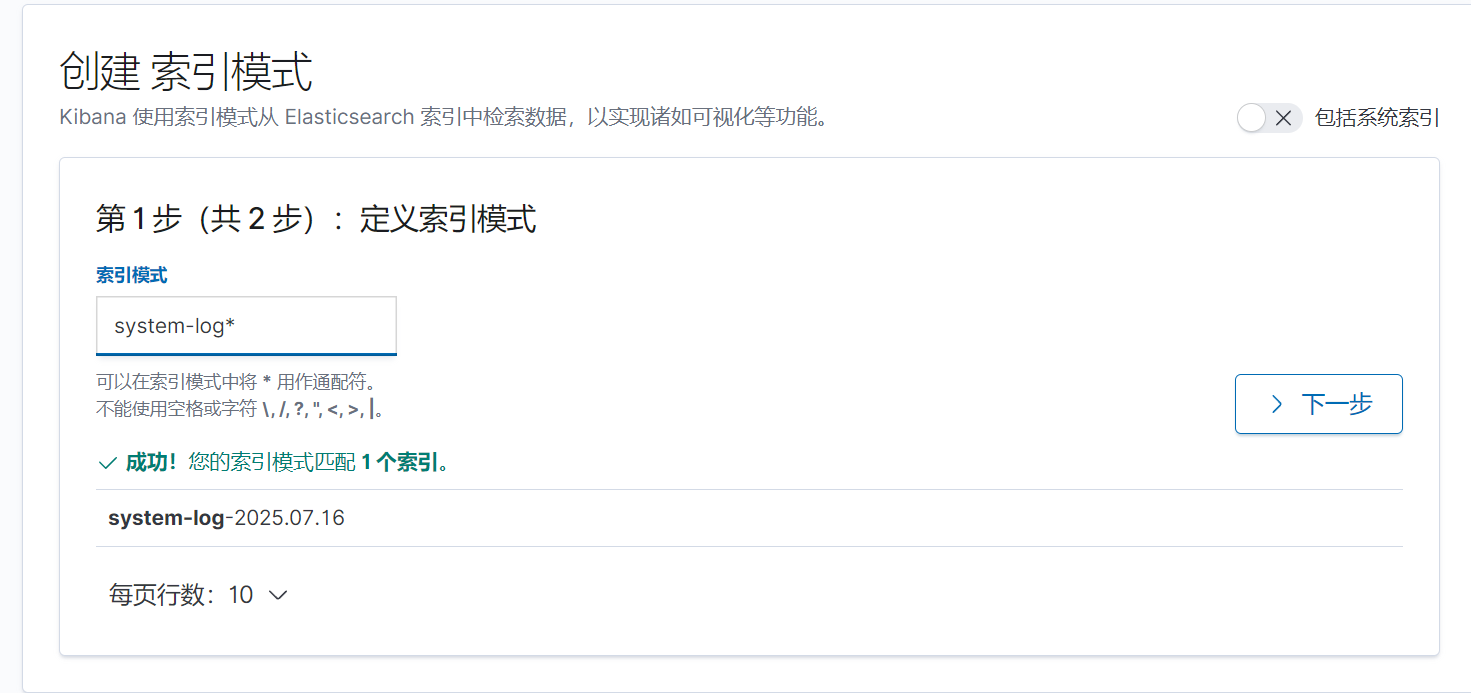
下一步,按时间戳进行筛选
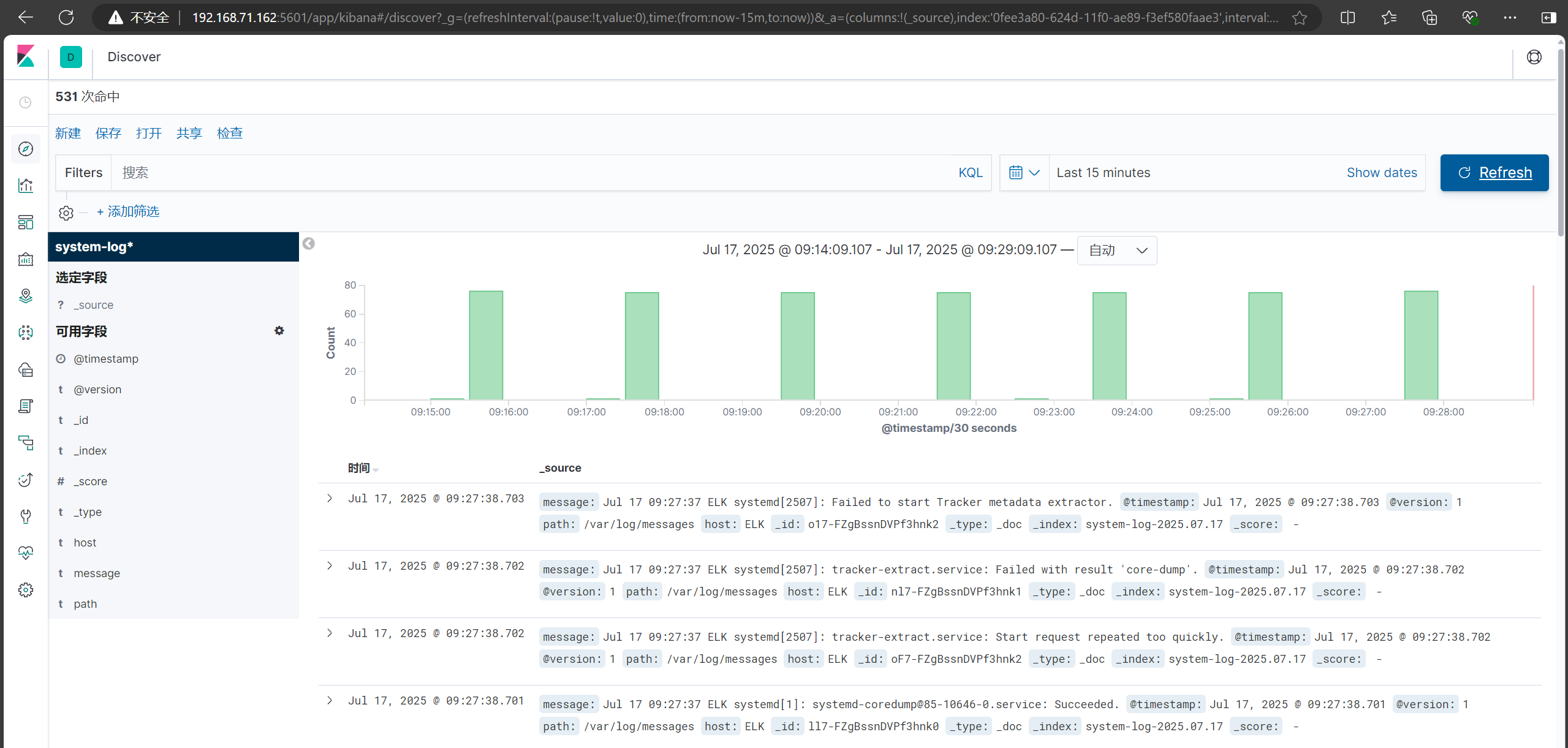
添加仪表盘 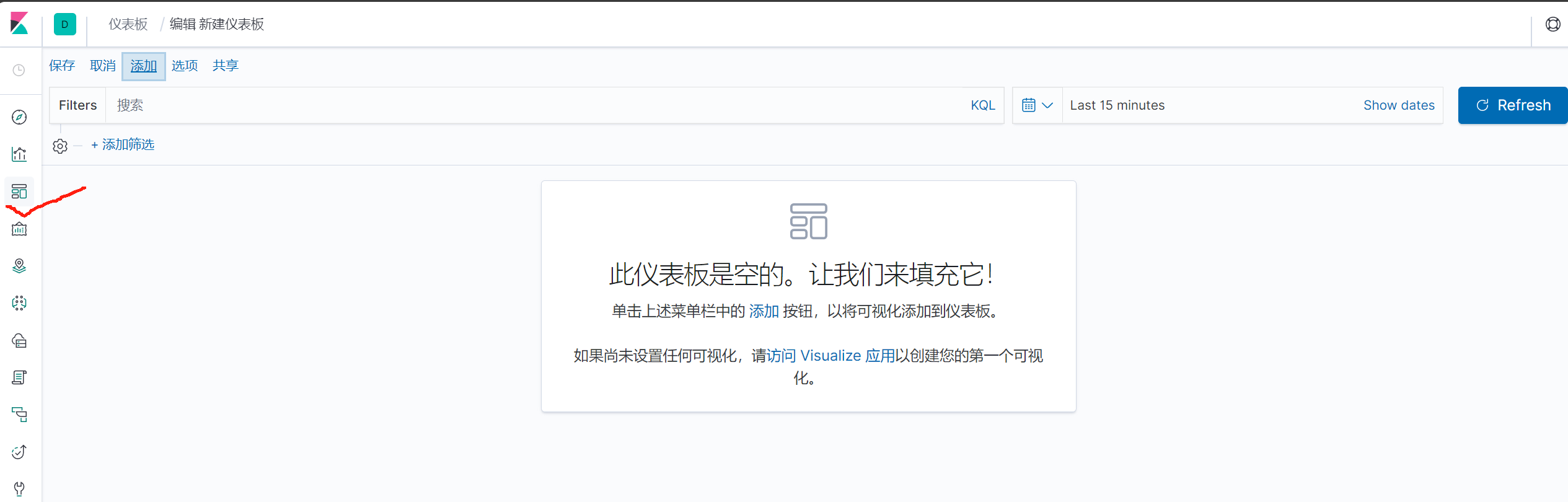
点击左上角添加,点击右边添加可视化
回到主页有可视化和文字说明
七.总结
本节内容大致了解了Elasticsearch,logstash和kibana的相关内容,明白了ELK各个字母的含义以及下载安装使用了对应的软件,之后就可以使用这些来收集各个应用的日志来分析日志信息。