
由于我们用户在使用题库的时候,会用到使用关键词去搜索题目
我们需要根据用户给的关键词去进行搜索,我们如果沿用之前的mysql进行数据库查询,那样的话效率太慢了(系统管理员那里可以用,因为那里不太要求效率),那如果使用redis呢?
使用redis的话,如果使用redis原生逻辑来解决的话,很明显,redis并不具有(或者不好实现)这种搜索功能,如果使用后端处理reids返回的值,然后使用for循环进行筛选的话,这样效率也太低,所以我们引出组件-----ElasticSearch
Elasticsearch(ES)是一款基于 Lucene 的分布式搜索引擎,它在提升搜索效率方面表现卓越,这与其底层架构设计、数据处理机制及功能特性密切相关。
ElasticSearch
官⽹:https://www.elastic.co/cn/elasticsearch
官⽅学习⽂档:https://www.elastic.co/guide/en/elasticsearch/reference/8.5/getting
started.html
ES解决什么问题
全⽂检索(全部字段)、模糊查询(搜索)、数据分析(提供分析语法,例如聚合)
搜索原理
ES 的核心优势源于 Lucene 的倒排索引(Inverted Index) 结构,这是区别于传统数据库 "正向索引" 的关键设计:
-
正向索引:以文档为单位存储内容(如数据库表),查询时需遍历所有文档,效率低下。
-
倒排索引 :将 "词项(Term)" 与 "文档 ID" 映射,例如:
词项"云计算" → 关联文档ID:[101, 205, 312] 词项"大数据" → 关联文档ID:[205, 431, 502] -
检索逻辑:查询时直接定位词项对应的文档集合,通过集合运算(交集、并集等)快速筛选目标文档,时间复杂度从 O (n) 降至 O (log n)。
- 压缩优化:ES 使用 FST(Finite State Transducer)压缩索引,减少内存占用,提升词项查找速度。
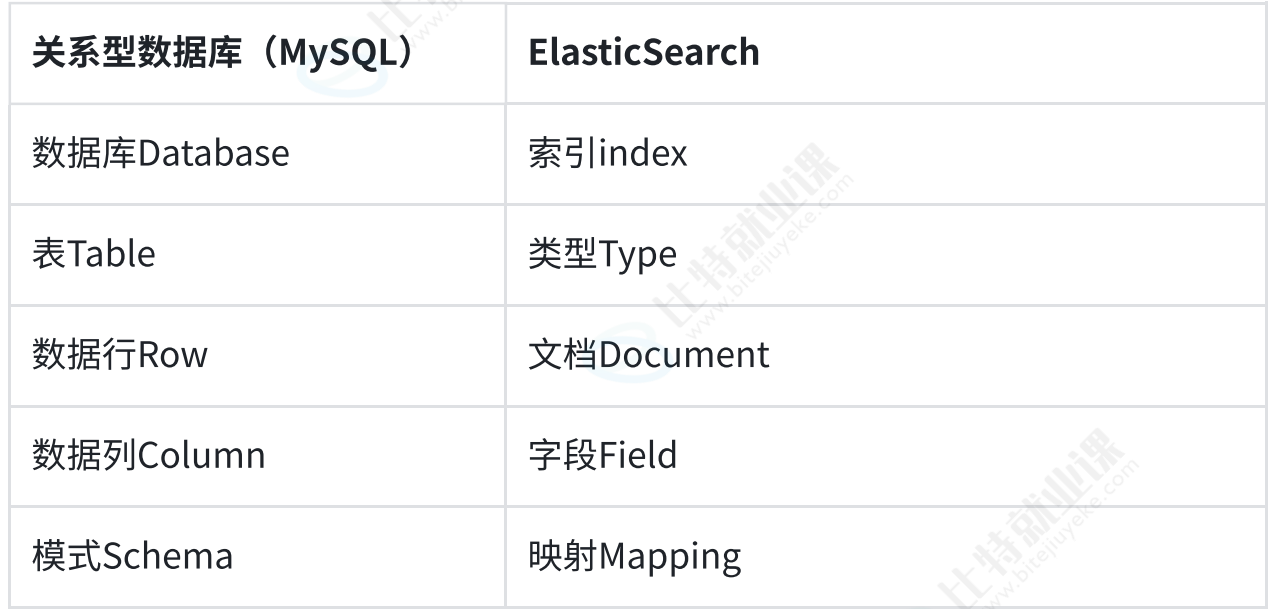
⼀个表格将ES和mysql 相关的基本概念进⾏对⽐:
基本使⽤
拉取es镜像:
docker network create oj-network创建网络
docker network create oj-network创建目录:
启动es:
docker run -d --name oj-es-dev -e "ES_JAVA_OPTS=-Xms256m -Xmx256m" -e "discovery.type=single-node" -v D:\后端代码\springcloud\bite-oj\deploy\dev\elasticSearch\es-plugins:/usr/share/elasticsearch/plugins -e "xpack.security.enabled=false" --privileged --network oj-network -p 9200:9200 -p 9300:9300 elasticsearch:8.5.3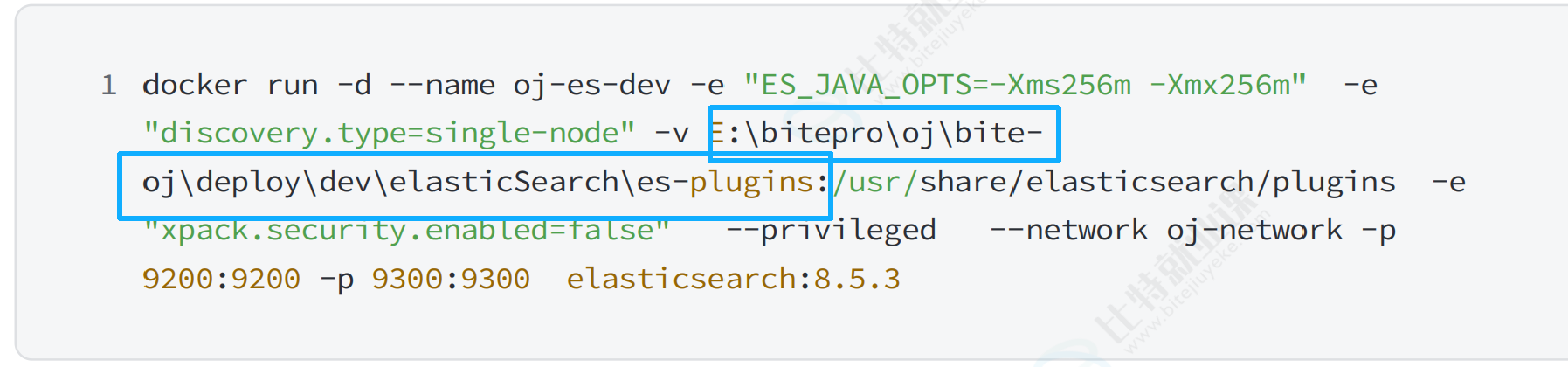
这里按需求改成自己的
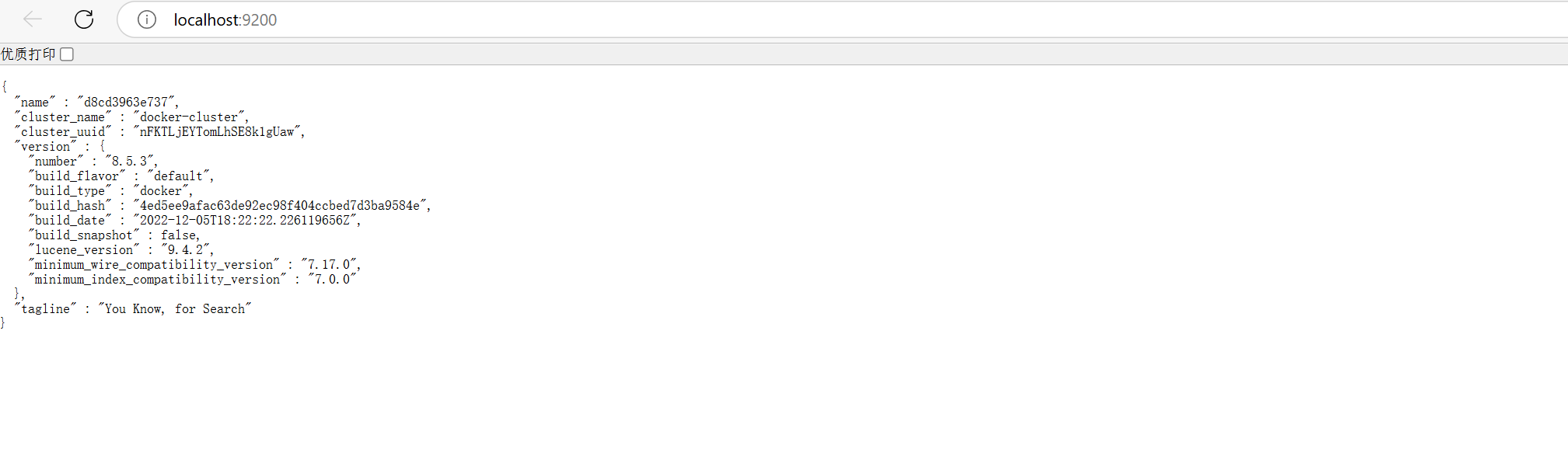
访问:http://localhost:9200/,验证启动成功
安装Kibana
Kibana是ElasticSearch的数据可视化和实时分析的⼯具。通过Kibana,⽤⼾可以搜索、查看和与存储 在Elasticsearch索引中的数据进⾏交互,执⾏⾼级数据分析,并通过各种图表、表格和地图将数据可视化。
拉取kibana镜像
docker pull kibana:8.5.3启动kibana容器
docker run -d --name oj-kibana-dev -e "ELASTICSEARCH_HOSTS=http://oj-esdev:9200" -e "I18N_LOCALE=zh-CN" -p15601:5601 --net=oj-network kibana:8.5.3这里面可能会有个-被吃,注意
修改配置/usr/share/kibana/config/kibana.yml,并启动kibana
1 # 2 # ** THIS IS AN AUTO-GENERATED FILE **
3 # 45 # Default Kibana configuration for docker target
6 server.host: "0.0.0.0"
7 server.shutdownTimeout: "5s"
8 elasticsearch.hosts: [ "http://oj-es-dev:9200" ]
9 monitoring.ui.container.elasticsearch.enabled: true
10 i18n.locale: "zh-CN"
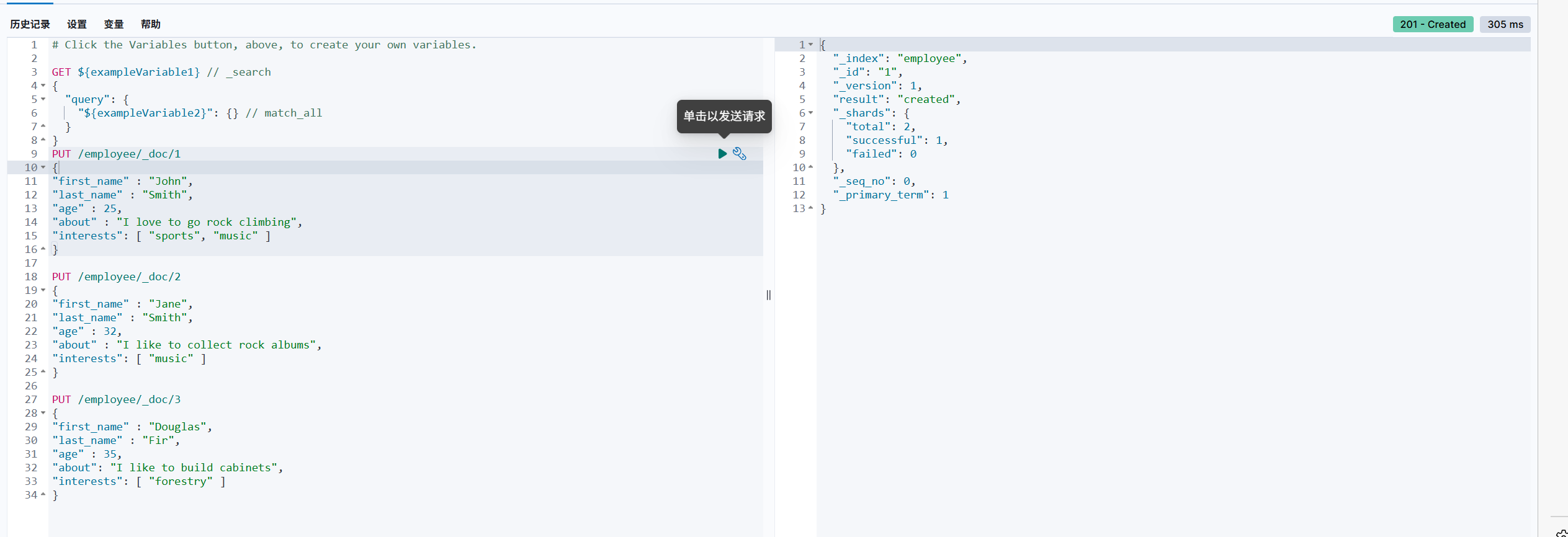
进⼊开发者⼯具⻚⾯如下图,我们将在左侧编写相应的命令对es当中的数据进⾏操作,结果会呈现在右侧。
增加
查询
查询所有数据:
GET /employee/_search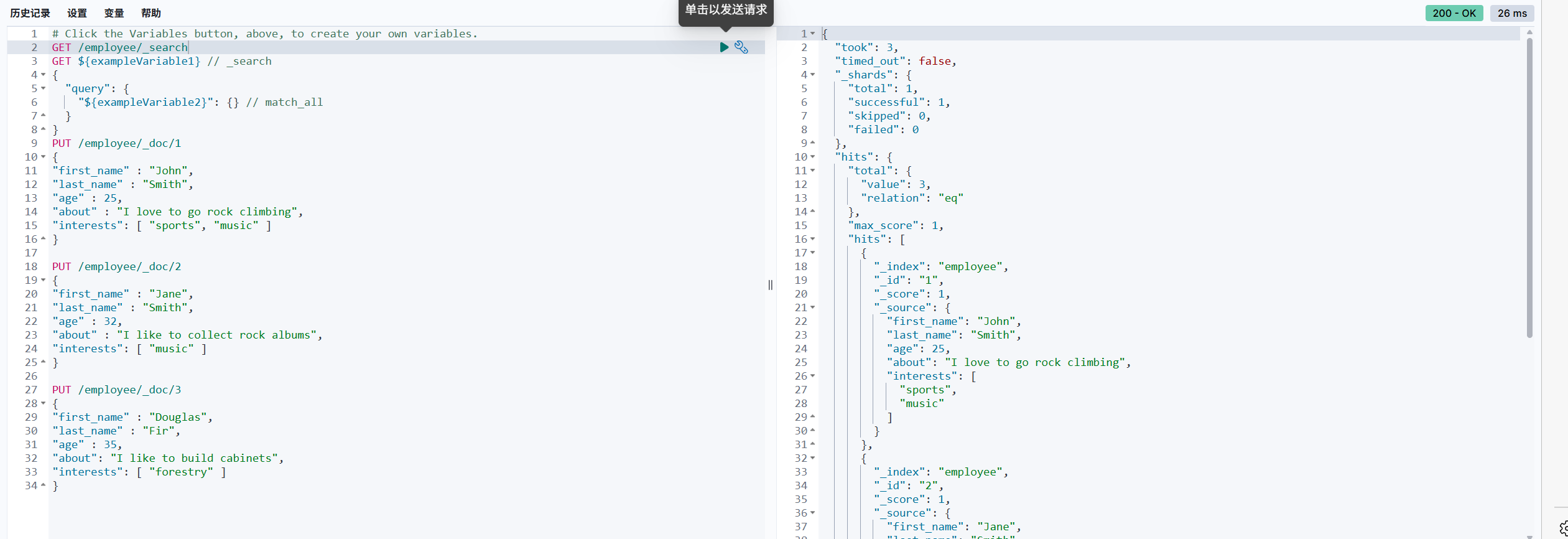
根据id查询
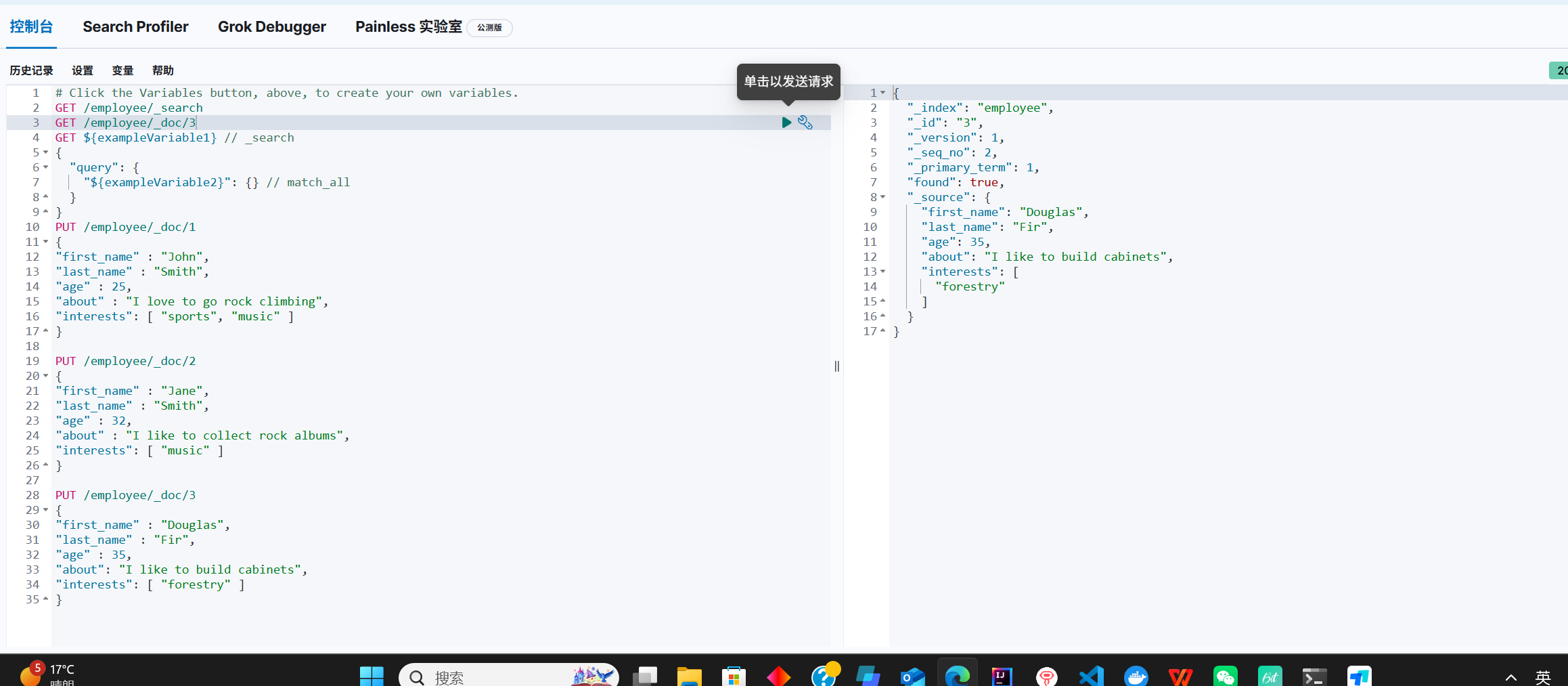
删除
删除某个数据
DELETE /employee/_doc/1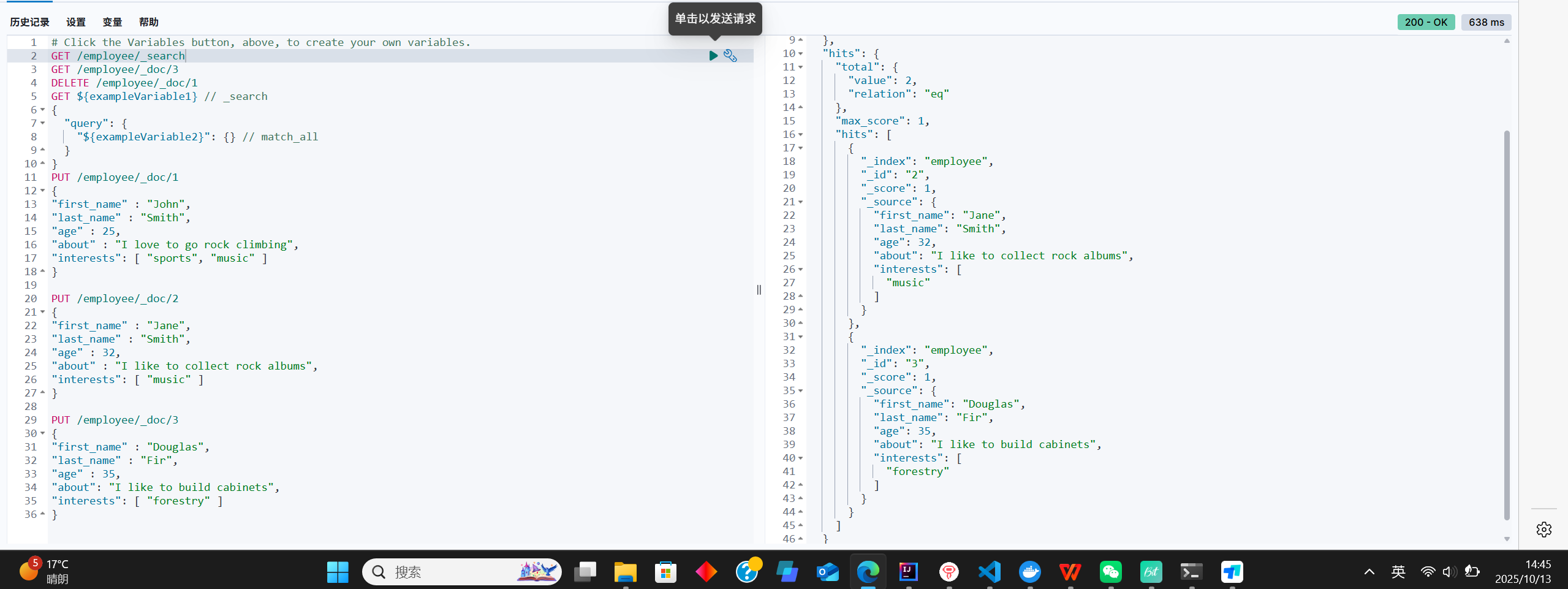
删除索引
DELETE /employee

修改
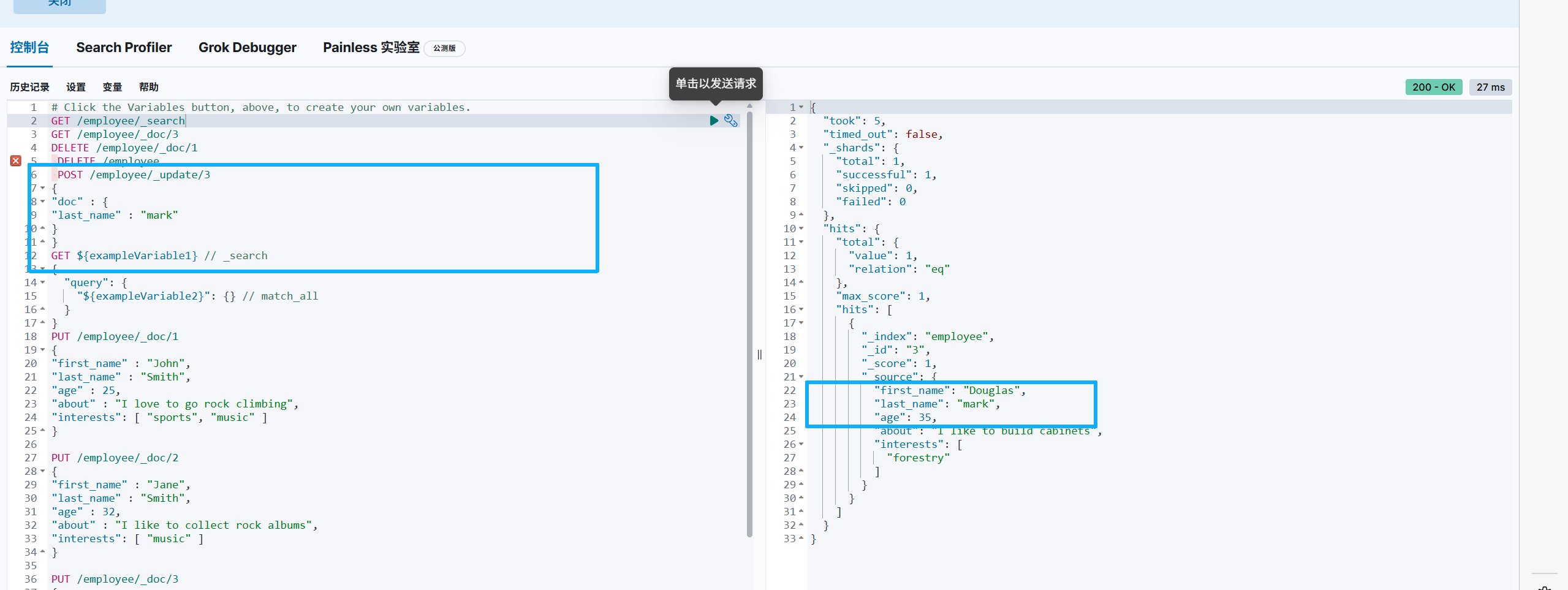
分词器
根据前⾯学习的倒排索引的概念。倒排索引是按照⽂档中的词汇(关键词)来组织的,索引的键
**是⽂档集合中出现过的每个独特词汇或关键词。那es是怎么将这些关键词提取出来的呢?**这其实就是es中的分词器在起着作⽤,它负责将⽂本切分成⼀个个有意义的词语,以建⽴索引或进⾏搜索和分析。
我们的业务中通常使⽤的是中⽂分词,es的中⽂分词默认会将中⽂词每个字看成⼀个词⽐
如:"我想吃⾁夹馍"会被分为"我","想","吃","⾁" ,"夹","馍" 这显然是不太符合⽤⼾的使⽤习惯,所以我们需要安装中⽂分词器ik,来讲中⽂内容分解成更加符合⽤⼾使⽤的关键字
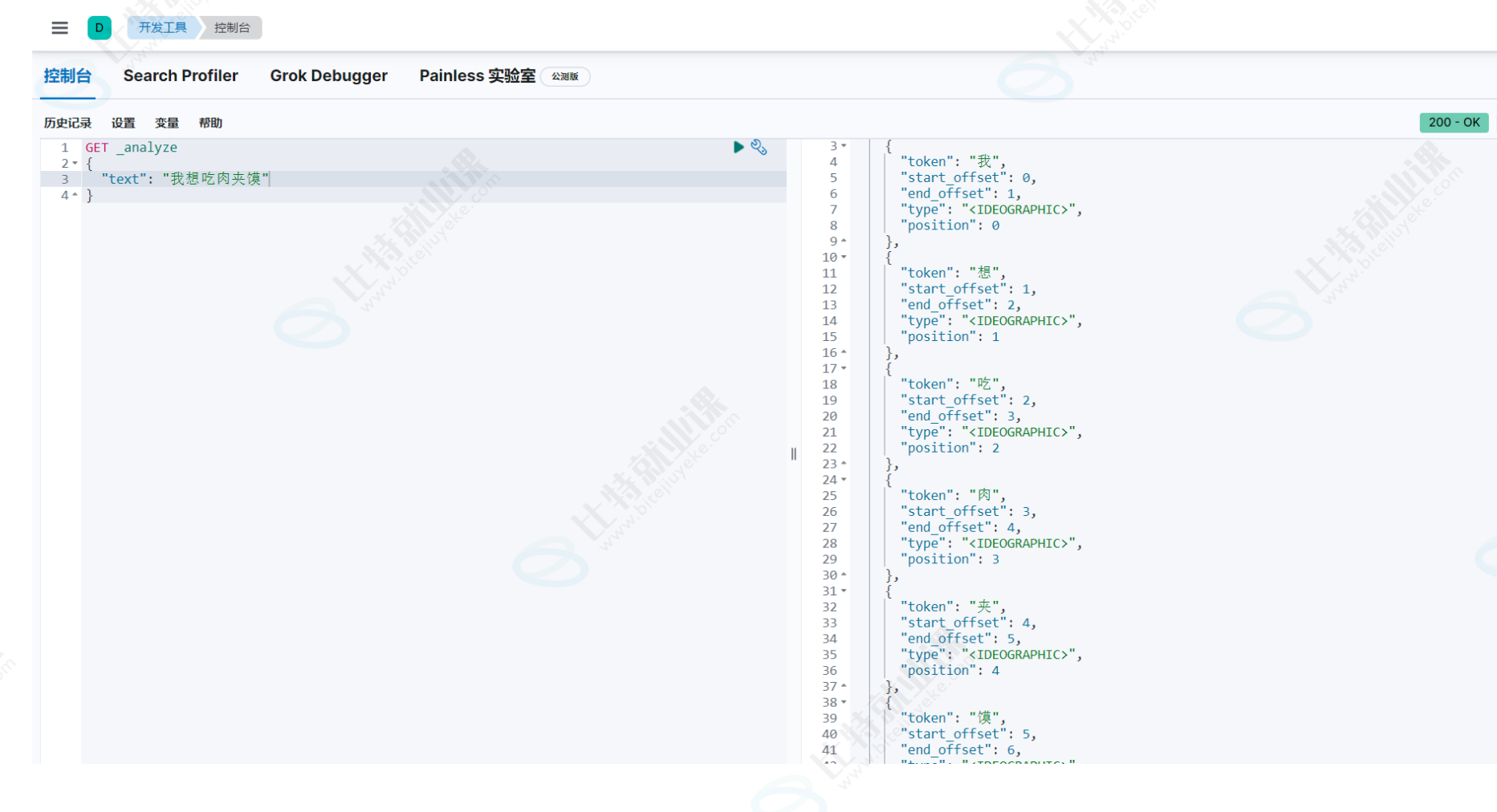
ik分词器
步骤⼀:下载
其实我们应该下载和es版本相同的8.5.3版本的分词器,但是官⽅未提供8.5.3版本的,所以我们下载8.5.2版本的。
下载地址:https://github.com/infinilabs/analysis-ik/releases?page=3
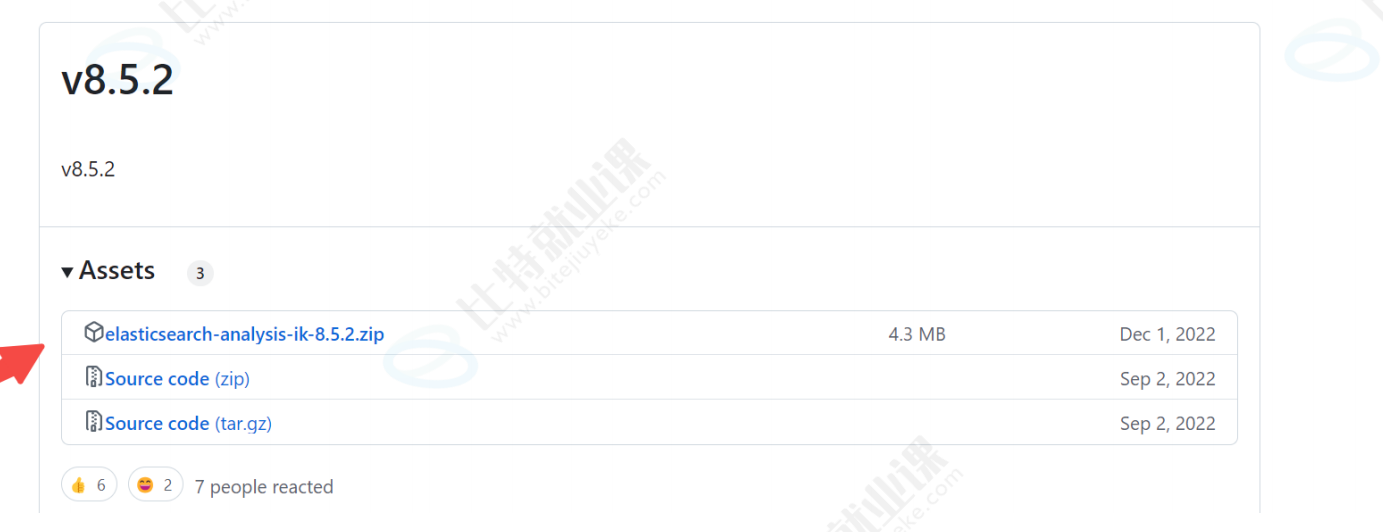
步骤⼆:
下载完成后将其压随后放置在:es容器内/usr/share/elasticsearch/plugins⽬录下,也可以通过配置 挂载⽬录的⽅式将插件放在挂载⽬录下。
步骤三:
修改分词器插件命名,将8.5.2改成8.5.3。
编辑插件配置⽂件:plugin-descriptor.properties⽂件修改版本号,修改成和es版本号⼀致