目录
[8.1 个体与集成](#8.1 个体与集成)
[8.2 Boosting](#8.2 Boosting)
[8.3 Bagging](#8.3 Bagging)
[8.4 随机森林](#8.4 随机森林)
[8.5 结合策略](#8.5 结合策略)
[8.5.1 平均法](#8.5.1 平均法)
[8.5.2 投票法](#8.5.2 投票法)
[8.5.3 学习法](#8.5.3 学习法)
[8.6 多样性](#8.6 多样性)
[8.6.1 误差-分歧分解 error-ambiguity](#8.6.1 误差-分歧分解 error-ambiguity)
[8.6.2 多样性度量](#8.6.2 多样性度量)
[8.6.3 多样性增强](#8.6.3 多样性增强)
8.1 个体与集成
同质 集成"基 学习器" 如决策树、神经网络;异质 集成中的个体学习器由不同的学习算法生成
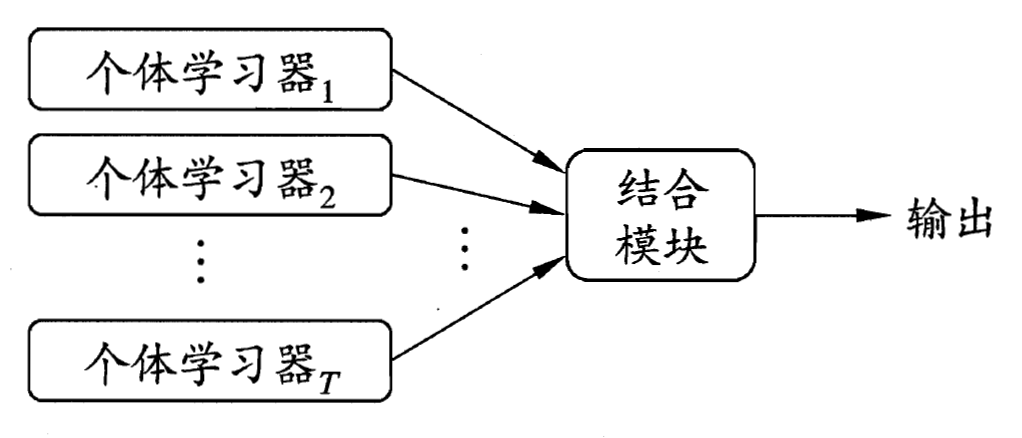
个体学习器的**"准确性"和"多样性"** 对"好而不同"的个体学习器 投票"少数服从多数"
T 个基分类器 错误率为€ 整体错误率为错半数以上 随着T增大收敛到0
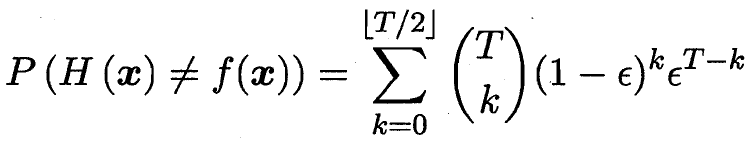
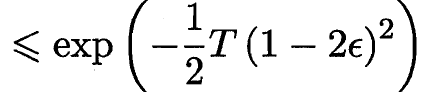
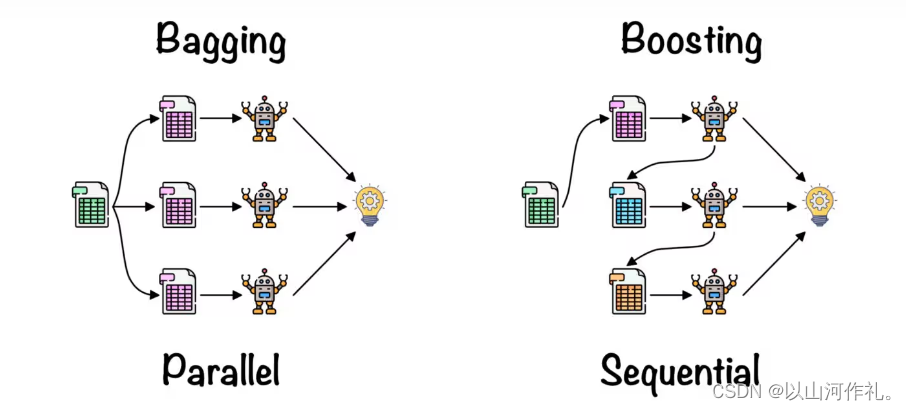
个体学习器间存在强依赖 关系、必须串行生成的序列化方法 Boosting
间不存在 强依赖关系、可同时生成的并行化方法 Bagging和"随机森林"
8.2 Boosting
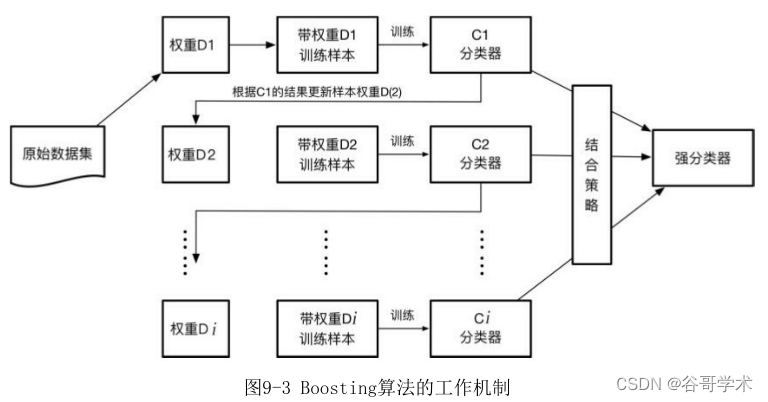
每轮样本的权重不同 上轮分类错误的样本 权重被调大 在下一次学习中被关注 进而调高准确度
Ada(Adaptive)Boost
伪代码如下 下方主要是对于样本分布 D_t+1 调整的数学推导
训练分类器h 算出误差ε 更新样本分布Dt+1和Dt 关系
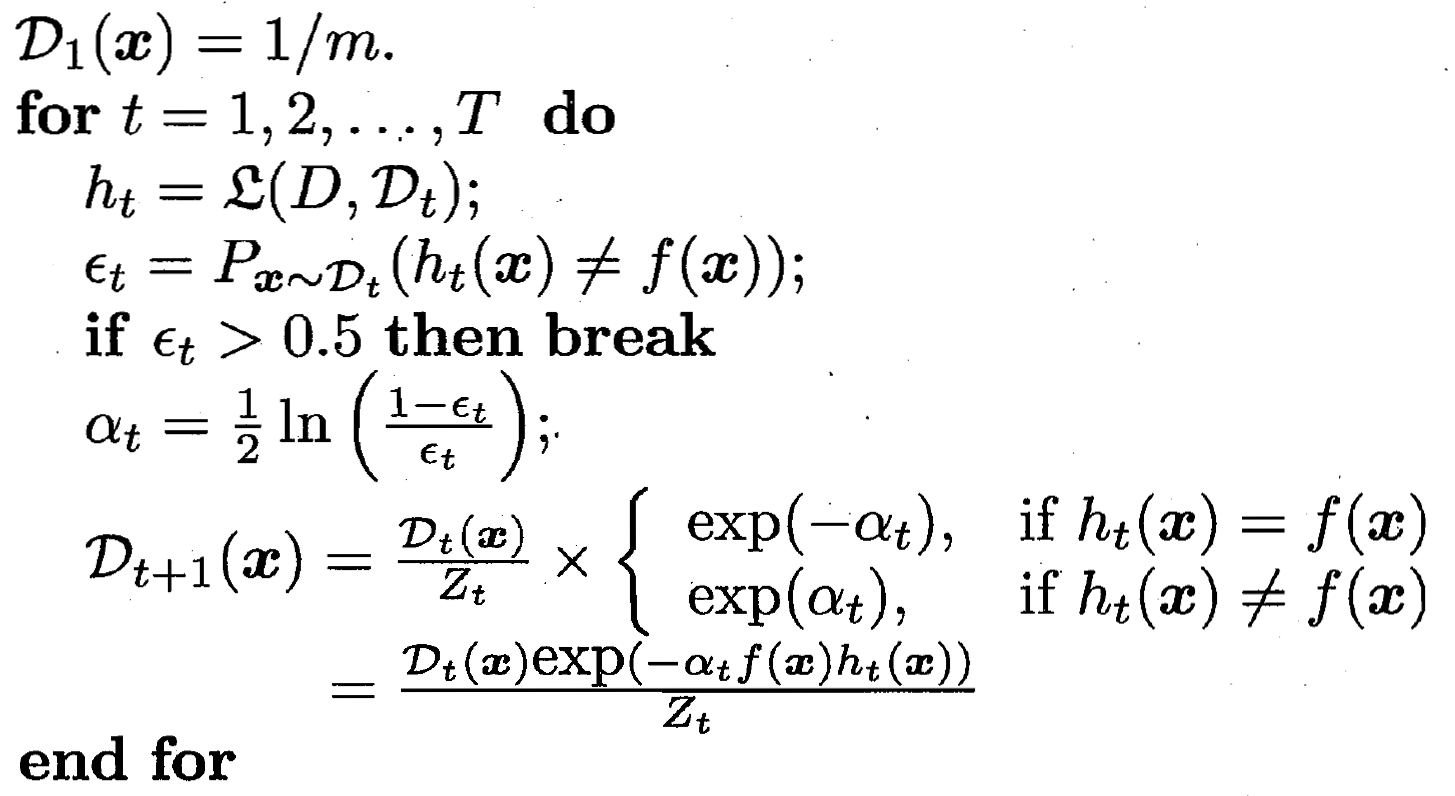
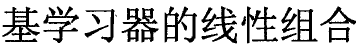
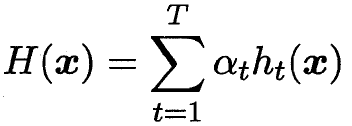
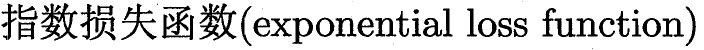
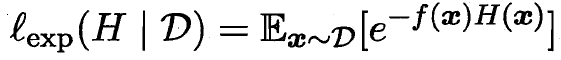

理想的基学习器 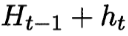 能纠正之前叠加形态分类器的所有错误
能纠正之前叠加形态分类器的所有错误
(但如果新的分类错误多到超过一半 那也不合适)

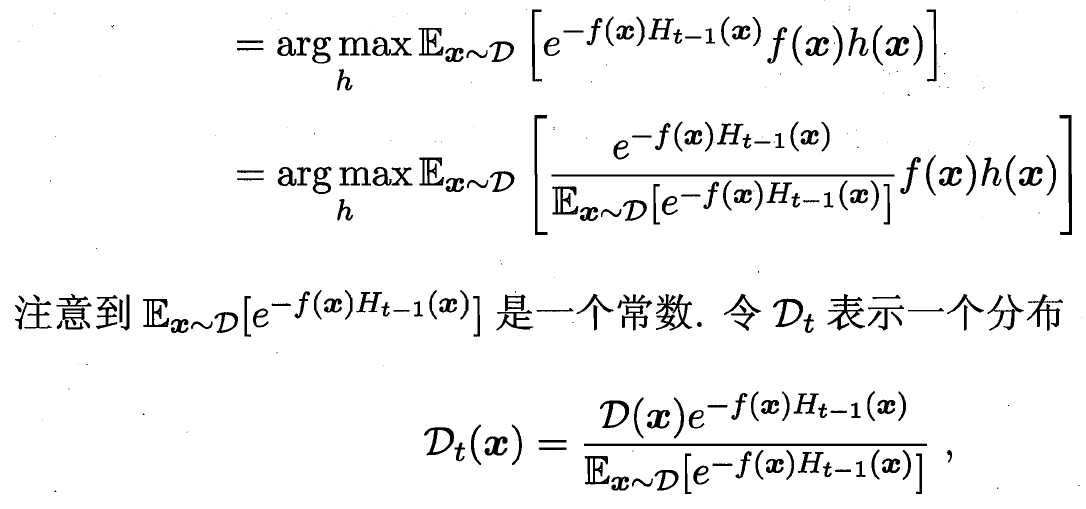
最后的分布调整 D_t+1 和 D_t的关系
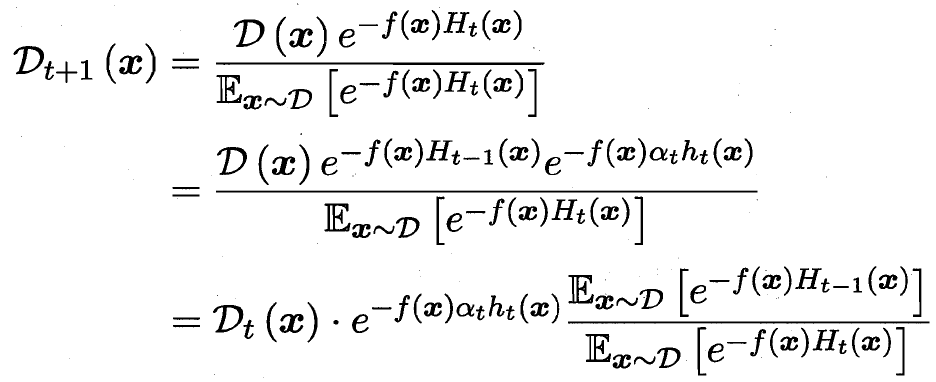
8.3 Bagging
重叠采样思想
基学习器尽可能具有较大的差异 可使得训练数据不同:
对训练样本进行采样 ,产生出若干个不同的子集,每个子集训练出一个基学习器.
希望个体学习器不能太差 使每个学习器使用更多数据 :使用相互有交叠的采样子集.
bootstrap sampling 自助采样法 m个样本采样m次 没被采样到的概率收敛为
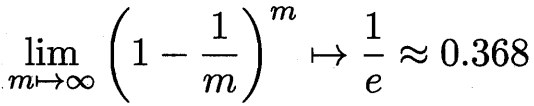
T轮采样 每轮采m个数据作为训练集 用基学习算法训练出模型
对这T个训练出来的集成模型 回归问题则把T个结果平均一下 分类问题则把T个结果投票一下
**包外估计:**把没被采样到的数据作为验证集
8.4 随机森林
以决策树为基学习器构建Bagging 在决策树的训练过程中
先随机选取一些特征 再选这几个中最优的几个 (数据随机+特征随机)
8.5 结合策略
相对单学习器的优势:
1.学习任务假设空间很大 若很多假设在训练集效果相近
但单学习器不能确定在总体空间做的好不好
2.学习算法陷入局部最优 解 泛化性不强 3.结合有利于扩大 原样本的假设空间
8.5.1 平均法
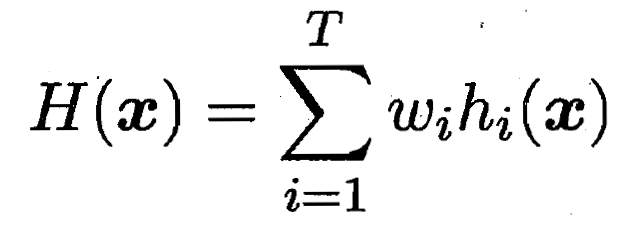
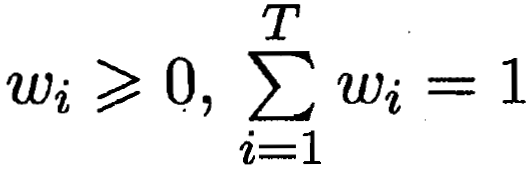
8.5.2 投票法
分类为N种中一种 1.超过半数则确定 2.选票最多的(票的权重 平均或加权)
8.5.3 学习法
Stacking 训练出的学习器 生成一些样本 与原样本混合 训练下一个学习器
8.6 多样性
8.6.1 误差-分歧分解 error-ambiguity
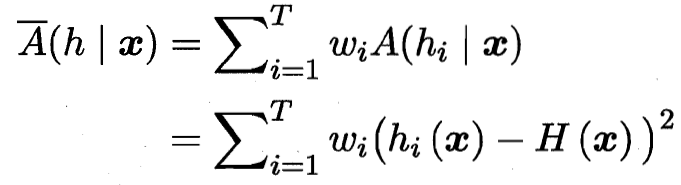 加权分歧
加权分歧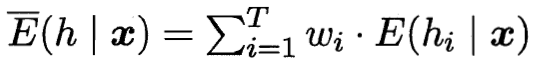 加权误差
加权误差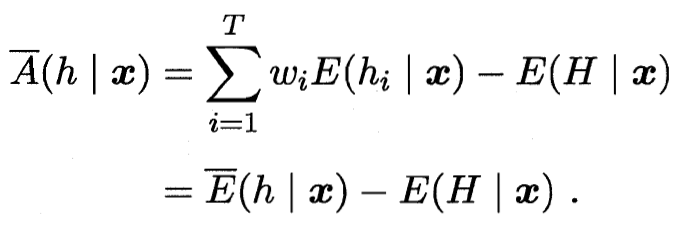 加权分歧=加权误差-总误差
加权分歧=加权误差-总误差
 总误差=加权误差-加权分歧
总误差=加权误差-加权分歧
误差越小 分歧(多样性)越大 总误差越小
8.6.2 多样性度量
两两的 相似/不相似性
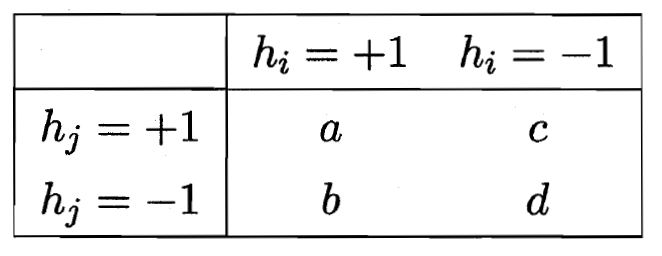
不合度量(b和c为结果不一样的) 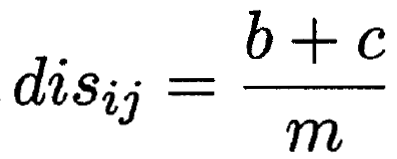
相关系数 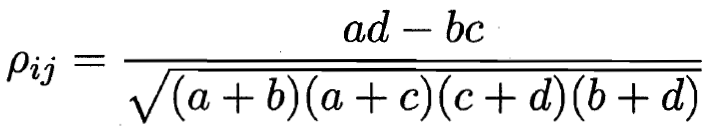


8.6.3 多样性增强
1.数据样本扰动(不同采样方式) 2.输入属性扰动(属性集中选取使用属性)
3.输出表示扰动(把分类问题转化为回归问题 拆解原问题) 4.算法参数改动(调参)