之前做个几个大模型的应用,都是使用Python语言,后来有一个项目使用了Java,并使用了Spring AI框架。随着Spring AI不断地完善,最近它发布了1.0正式版,意味着它已经能很好的作为企业级生产环境的使用。对于Java开发者来说真是一个福音,其功能已经能满足基于大模型开发企业级应用。借着这次机会,给大家分享一下Spring AI框架。
注意 :由于框架不同版本改造会有些使用的不同,因此本次系列中使用基本框架是 Spring AI-1.0.0,JDK版本使用的是19 。
代码参考: https://github.com/forever1986/springai-study
目录
- [1 Transformers说明](#1 Transformers说明)
- [2 Transformers示例演示](#2 Transformers示例演示)
-
- [2.1 TokenTextSplitter](#2.1 TokenTextSplitter)
- [2.2 ContentFormatTransformer](#2.2 ContentFormatTransformer)
- [2.3 KeywordMetadataEnricher](#2.3 KeywordMetadataEnricher)
- [2.4 SummaryMetadataEnricher](#2.4 SummaryMetadataEnricher)
上一章讲了Spring AI的ETL中的DocumentReaders,接下来继续讲解ETL部分的Transformers。
1 Transformers说明
Transformers对一批文档进行转换处理。目前Spring AI的实现如下:
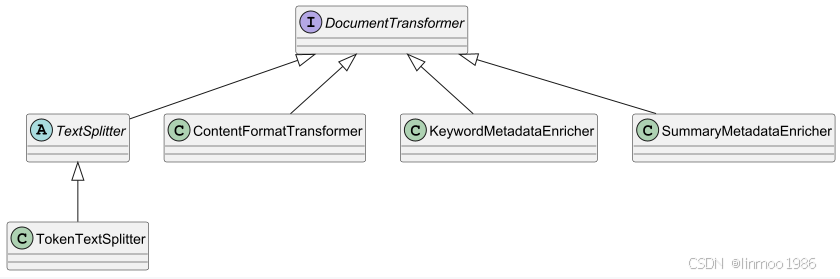
- DocumentTransformer:所有文档的转换,都是实现了该接口,主要实现其transform方法,将一组Document转换为另外一组Document。
- TextSplitter:是一个抽象基类,它有助于将文档进行分割,以适应人工智能模型的上下文窗口。
- TokenTextSplitter:是"TextSplitter"的一种实现方式,它根据词的数量将文本分割成多个部分,并使用"CL100K_BASE"编码进行处理。
- ContentFormatTransformer:可以将文档中的元数据内容变成键值对字符串,从而确保所有文档中的内容格式保持统一。
- KeywordMetadataEnricher:它利用生成式人工智能模型从文档内容中提取关键词,并向Metadata中添加一个keywords字段,该字段包含了文档的关键词信息。
- SummaryMetadataEnricher:它利用生成式人工智能模型为文档生成摘要,并将其作为Metadata添加到文档中。它能够为当前文档生成摘要,也能为相邻文档(即前文和后文的文档)生成摘要。
2 Transformers示例演示
以下代码参考lesson13的com.demo.lesson13.transformers包下面
2.1 TokenTextSplitter
1)pom中引入commons插件
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-commons</artifactId>
</dependency>2)测试文件内容:
text
Spring AI该项目旨在简化包含人工智能功能的应用程序的开发,而不会产生不必要的复杂性。
该项目从著名的 Python 项目(如 LangChain 和 LlamaIndex)中汲取灵感,但 Spring AI 并不是这些项目的直接移植。 该项目的成立理念是,下一波生成式 AI 应用程序将不仅适用于 Python 开发人员,而且将在许多编程语言中无处不在。
Spring AI 解决了人工智能整合方面的核心难题:将您企业的数据和 API 与人工智能模型相连接。
Spring AI 提供了抽象,作为开发 AI 应用程序的基础。 这些抽象具有多种实现,支持以最少的代码更改轻松交换组件。
Spring AI 提供以下功能:
跨 AI 提供商的可移植 API 支持,用于聊天、文本到图像和嵌入模型。支持同步和流式处理 API 选项。此外,还可以访问特定于模型的特征。
支持所有主要的 AI 模型提供商,例如 Anthropic、OpenAI、Microsoft、Amazon、Google 和 Ollama。支持的模型类型包括:
聊天完成
嵌入
文本到图像
音频转录
文本到语音
适度3)代码
java
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;
import java.util.List;
public class TokenTextSplitterTest {
public static void main(String[] args) {
List<Document> documents = loadDocument();
TokenTextSplitter splitter = TokenTextSplitter.builder()
.withChunkSize(50) // 每个文本分块所包含的token数量的目标值(默认值:800)
.withMinChunkSizeChars(10) //每个文本块的最小字符数(默认值:350)
.withMinChunkLengthToEmbed(1) //要包含的分块的最小长度(默认值:5)
.withMaxNumChunks(3) //从文本中生成的分块的最大数量(默认值:10000);实际数量比设置多1个
.withKeepSeparator(true) //保留分隔符:是否在分块中保留分隔符(如换行符)(默认值:true)
.build();
List<Document> splitDocuments = splitter.apply(documents);
int i = 0;
for (Document doc : splitDocuments) {
System.out.println("--------"+(++i)+"--------");
System.out.println("Chunk: " + doc.getText());
System.out.println("Metadata: " + doc.getMetadata());
}
}
// 加载文本
private static List<Document> loadDocument(){
String fileName = "data/tokentextsplitterdata.txt";
Resource resource = new ClassPathResource(fileName);
TextReader textReader = new TextReader(resource);
textReader.getCustomMetadata().put("filename", fileName);
return textReader.get();
}
}4)演示效果

TokenTextSplitter的分块逻辑 :
1)使用 CL100K_BASE 编码将输入文本编码为 token
2)根据 defaultChunkSize 对编码后的token进行分块
3)对于分块:
- ① 将块再解码为文本字符串
- ② 尝试从后向前找到一个合适的截断点(句号、问号、感叹号或换行符)。
- ③ 如果找到合适的截断点,并且截断点所在的index大于minChunkSizeChars,则将在该点截断该块
- ④ 对分块去除两边的空白字符,并根据 keepSeparator 设置,可选地移除换行符
- ⑤ 如果处理后的分块长度大于 minChunkLengthToEmbed,则将其添加到分块列表中
4)持续执行第2步和第3步,直到所有 token 都被处理完或达到 maxNumChunks
5)如果还有剩余的token没有处理,并且剩余的token进行编码和转换处理后,长度大于 minChunkLengthToEmbed,则将其作为最终块添加
说明 :从上图以及分块逻辑可以看到,其自动化根据某些标点进行断句,但是整体做的不是很好,第二个文档就是没有在标点下断句,会导致原本整体的句子被断开,这样会导致RAG最终回答的效果不准确。之前在《检索增强生成RAG系列3--RAG优化之文档处理》中讲过一些实践经验,如果想复用,可以引入并使用Langchain4j的文档解析器进行解析。
2.2 ContentFormatTransformer
1)引入的pom和测试文件内容与TokenTextSplitter一致,这里就不列出来
2)代码
java
import org.springframework.ai.document.DefaultContentFormatter;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.MetadataMode;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.transformer.ContentFormatTransformer;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;
import java.util.List;
public class ContentFormatTransformerTest {
public static void main(String[] args) {
// 加载文档
List<Document> documents = loadDocument();
// 文档分块
TokenTextSplitter splitter = TokenTextSplitter.builder()
.withChunkSize(50) // 每个文本分块所包含的token数量的目标值(默认值:800)
.withMinChunkSizeChars(10) //每个文本块的最小字符数(默认值:350)
.withMinChunkLengthToEmbed(1) //要包含的分块的最小长度(默认值:5)
.withMaxNumChunks(3) //从文本中生成的分块的最大数量(默认值:10000);实际数量比设置多1个
.withKeepSeparator(true) //保留分隔符:是否在分块中保留分隔符(如换行符)(默认值:true)
.build();
List<Document> splitDocuments = splitter.apply(documents);
// 增加ContentFormatTransformer,过来掉元数据的filename标签
DefaultContentFormatter formatter = DefaultContentFormatter.builder()
.withExcludedInferenceMetadataKeys("filename")
.build();
ContentFormatTransformer contentFormatTransformer = new ContentFormatTransformer(formatter);
List<Document> formatDocuments = contentFormatTransformer.apply(splitDocuments);
// 打印
int i = 0;
for (Document doc : formatDocuments) {
System.out.println("--------"+(++i)+"--------");
// 获取过滤filename标签的数据
String format = doc.getFormattedContent(MetadataMode.INFERENCE);
System.out.println(format);
}
}
// 加载文本
private static List<Document> loadDocument(){
String fileName = "data/tokentextsplitterdata.txt";
Resource resource = new ClassPathResource(fileName);
TextReader textReader = new TextReader(resource);
textReader.getCustomMetadata().put("filename", fileName);
return textReader.get();
}
}3)演示效果

说明:可以看到,其返回的数据filename标签已经被过滤了
2.3 KeywordMetadataEnricher
1)其pom引入智谱模型
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-zhipuai</artifactId>
</dependency>2)代码
java
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.model.transformer.KeywordMetadataEnricher;
import org.springframework.ai.zhipuai.ZhiPuAiChatModel;
import org.springframework.ai.zhipuai.ZhiPuAiChatOptions;
import org.springframework.ai.zhipuai.api.ZhiPuAiApi;
import java.util.List;
import java.util.Map;
public class KeywordMetadataEnricherTest {
public static void main(String[] args) {
// 创建模型,直接使用ChatModel,而非ChatClient;关于ChatModel后续章节会细讲,这里就是创建一个大语言模型
var zhiPuAiApi = new ZhiPuAiApi("你的智谱模型的API KEY");
var chatModel = new ZhiPuAiChatModel(zhiPuAiApi, ZhiPuAiChatOptions.builder()
.model("GLM-4-Flash-250414")
.temperature(0.7)
.build());
// 初始化KeywordMetadataEnricher
KeywordMetadataEnricher enricher = new ZhKeywordMetadataEnricher(chatModel, 5); // 总结5个关键字
// 初始化文档
Document doc = new Document("""
据中国国家海洋环境预报中心官网消息,当地时间7月16日中午时分,美国阿拉斯加半岛海域发生7.3级地震,震源深度为20千米。
自然资源部海啸预警中心根据最新监测分析结果,此次地震已在震源附近引发局地海啸,不会对我国沿岸造成影响。
地震发生后,美国国家气象局针对阿拉斯加州南部、阿拉斯加半岛以及临近的太平洋沿岸地区发布了海啸预警,但在一个小时后取消。
当地警方表示,位于海啸警报范围内的城市都听到了警报声,指示人们转移到高处去。警察局还在社交媒体上发布消息,告知居民,如有需要,当地学校将作为紧急避难所开放。
数千民众通过警报声和短信通知收到了警报,并按照指示转移到高处或内陆地区避难。沿海地区的渔业、旅游业等经济活动临时暂停。截至发稿,当地还没有出现关于重大损失的报告。
""");
// 执行获取关键字
List<Document> enrichedDocs = enricher.apply(List.of(doc));
// 打印
Document enrichedDoc = enrichedDocs.get(0);
String keywords = (String) enrichedDoc.getMetadata().get("excerpt_keywords");
System.out.println("提前的关键字: " + keywords);
}
/**
* 由于KeywordMetadataEnricher的默认提示语是英文,因此得到的答案有可能也是英文,因此这里重写一下KeywordMetadataEnricher的提示语
*/
static class ZhKeywordMetadataEnricher extends KeywordMetadataEnricher{
private final ChatModel chatModel;
private final int keywordCount;
public static final String KEYWORDS_TEMPLATE = """
{context_str}. 为这份文档提供%s个独特的关键词。格式为以逗号分隔的列表。关键词:""";
public ZhKeywordMetadataEnricher(ChatModel chatModel, int keywordCount) {
super(chatModel, keywordCount);
this.chatModel = chatModel;
this.keywordCount = keywordCount;
}
@Override
public List<Document> apply(List<Document> documents) {
for (Document document : documents) {
var template = new PromptTemplate(String.format(KEYWORDS_TEMPLATE, this.keywordCount));
Prompt prompt = template.create(Map.of(CONTEXT_STR_PLACEHOLDER, document.getText()));
String keywords = this.chatModel.call(prompt).getResult().getOutput().getText();
document.getMetadata().putAll(Map.of("excerpt_keywords", keywords));
}
return documents;
}
}
}3)演示效果

2.4 SummaryMetadataEnricher
1)其pom引入智谱模型
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-zhipuai</artifactId>
</dependency>2)代码
java
import org.springframework.ai.document.Document;
import org.springframework.ai.document.MetadataMode;
import org.springframework.ai.model.transformer.SummaryMetadataEnricher;
import org.springframework.ai.zhipuai.ZhiPuAiChatModel;
import org.springframework.ai.zhipuai.ZhiPuAiChatOptions;
import org.springframework.ai.zhipuai.api.ZhiPuAiApi;
import org.springframework.ai.model.transformer.SummaryMetadataEnricher.SummaryType;
import java.util.List;
public class SummaryMetadataEnricherTest {
public static void main(String[] args) {
// 创建模型,直接使用ChatModel,而非ChatClient;关于ChatModel后续章节会细讲,这里就是创建一个大语言模型
var zhiPuAiApi = new ZhiPuAiApi("你的智谱模型API KEY");
var chatModel = new ZhiPuAiChatModel(zhiPuAiApi, ZhiPuAiChatOptions.builder()
.model("GLM-4-Flash-250414")
.temperature(0.7)
.build());
// 初始化SummaryMetadataEnricher
SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(chatModel,
List.of(SummaryType.PREVIOUS, SummaryType.CURRENT, SummaryType.NEXT),
"""
以下是该部分的内容:
{context_str}
概述该部分的主要主题和相关实体。
摘要:""", //提示词改为中文的
MetadataMode.ALL);
// 初始化文档
Document doc1 = new Document("""
据中国国家海洋环境预报中心官网消息,当地时间7月16日中午时分,美国阿拉斯加半岛海域发生7.3级地震,震源深度为20千米。
自然资源部海啸预警中心根据最新监测分析结果,此次地震已在震源附近引发局地海啸,不会对我国沿岸造成影响。""");
Document doc2 = new Document("""
当地时间6月12日下午,一架从印度飞往英国的印度航空公司波音787-8型客机在印度古吉拉特邦艾哈迈达巴德机场起飞后不久坠毁,造成机上和地面共270余人遇难。
飞机上的两个黑匣子均已被找到。这是波音787机型首次发生致命空难,多国已派团队协助调查。""");
// 执行摘要总结
List<Document> enrichedDocs = enricher.apply(List.of(doc1,doc2));
// 打印
int i = 0;
for (Document doc : enrichedDocs) {
System.out.println("--------"+(++i)+"--------");
System.out.println("当前文档总结: " + doc.getMetadata().get("section_summary"));
System.out.println("前一份文档总结: " + doc.getMetadata().get("prev_section_summary"));
System.out.println("下一份文档总结: " + doc.getMetadata().get("next_section_summary"));
}
}
}3)演示效果

结语:本章针对Spring AI的ETL中Transformers模块的讲解和演示,整体来说,其文档分块功能还是有待提升,不像Langchain4j 那样继承了Langchain的多种文档分块的算法,不过相信后面慢慢会补充完善,当然,你也可以自定义文档分块来实现Langchain4j 中的一些算法。下一章将继续讲解Spring AI中ETL最后一块功能Writers。
Spring AI系列上一章:《Spring AI 系列之十三 - RAG-加载本地嵌入模型》
Spring AI系列下一章:《Spring AI 系列之十五 - RAG-ETL之二》