支持向量机SVM
一、支持向量机算法
支持向量机(Support Vector Machine,SVM)是一种用于分类和回归分析的机器学习算法。
- 分类场景举例(更容易理解)
假设现在有一个二维平面上散落着一些点,这些点分为两类,一类是红色的圆形点,另一类是蓝色的方形点。我们的任务就是找到一条直线,能够把这两类点尽可能准确地分开。支持向量机算法做的事情就和这个类似。
- 算法核心思想
它不是随便找一条能分开两类数据的直线(在高维空间可能是超平面),而是要找到一条特殊的直线。这条直线需要满足离它两边最近的那些点(这些点就叫做支持向量)的距离尽可能远。打个比方,这条直线就像一个 "缓冲带" 的中线,离两边支持向量越远,这个 "缓冲带" 就越宽,这样做的好处是能更好地对数据进行分类,即使有一些新的、之前没看过的数据点出现,也能有较高的分类准确率。
- 高维空间情况
不过现实中的数据往往不是这么简单地分布在二维或三维空间里,很多都是在高维空间中。这时候支持向量机就会利用一些数学技巧,把低维的数据映射到高维空间,在高维空间里找到那个能很好分隔数据的超平面。这就好比我们把一个很难用直线在二维平面上分开的东西,通过一些方式 "升维" 到三维空间,在三维空间里找到一个平面(超平面在三维空间就是平面,在更高维空间就更难直观理解了)来把它们分开。
二、生活中的应用场景
-
垃圾邮件分类
- 当你收到一封邮件时,邮件系统需要判断它是正常的邮件还是垃圾邮件。支持向量机算法可以对邮件的内容进行分析。
- 例如,它会把邮件中的词汇、发件人信息等特征提取出来。如果邮件中出现大量的 "中奖""免费赠送" 等词汇,就很可能被标记为垃圾邮件。通过训练支持向量机模型,把包含这些特征的垃圾邮件和正常邮件的数据作为训练样本,模型就能学会分辨新收到的邮件是垃圾邮件还是正常邮件。
-
手写体识别
- 在银行处理支票等业务时,需要对支票上的手写数字进行识别。支持向量机可以对手写数字的图像进行处理。
- 它把每个手写数字图像的像素值等信息作为特征,通过对大量手写数字样本(已经标注好是哪个数字)进行学习。当遇到一个新的手写数字图像时,就能根据模型判断它到底是 0 - 9 中的哪一个数字。
-
情感分析
- 比如在一个社交网络平台上,商家想要了解用户对自己产品的评价是正面的、负面的还是中性的。支持向量机可以分析用户发布的关于产品的评论文本。
- 它会关注文本中的词汇和语句结构等特征,像 "很棒""很喜欢" 通常代表正面情感,"很差""很失望" 则代表负面情感。通过训练模型,就能对新的评论进行情感分类。
-
生物信息学中的蛋白质分类
- 科学家在研究蛋白质功能时,需要对蛋白质进行分类。支持向量机可以根据蛋白质的氨基酸序列等特征来分类。
- 例如,区分一种蛋白质是参与代谢过程的还是参与信号传导的,对新发现的蛋白质序列进行快速准确的分类,有助于进一步的生物学研究。
三、代码案例
水果分类系统
这个代码示例模拟了一个水果分类系统,使用支持向量机(SVM)根据水果的重量和甜度来区分苹果和橙子。关键部分解释:
- 数据生成:通过高斯分布模拟苹果(轻且甜)和橙子(重且不太甜)的特征
- 模型训练:使用径向基函数(RBF)核的SVM分类器
- 可视化:绘制了决策边界和支持向量,帮助理解SVM的工作原理
- 预测功能:可以对新水果样本进行分类预测,并显示分类置信度
这个示例展示了SVM在二分类问题中的应用,通过调整特征和参数可以应用于更复杂的场景。
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 模拟生成水果数据集
def generate_fruit_data(n_samples=100, random_state=42):
"""
生成水果分类数据集,特征为重量(克)和甜度(0-10)
参数:
n_samples: 样本数量
random_state: 随机种子,保证结果可重现
返回:
X: 特征矩阵 (重量, 甜度)
y: 标签 (0=苹果, 1=橙子)
"""
np.random.seed(random_state)
# 生成苹果数据 (重量轻,甜度高)
apples_weight = np.random.normal(loc=150, scale=20, size=n_samples // 2)
apples_sweetness = np.random.normal(loc=8, scale=1, size=n_samples // 2)
# 生成橙子数据 (重量重,甜度中等)
oranges_weight = np.random.normal(loc=200, scale=25, size=n_samples // 2)
oranges_sweetness = np.random.normal(loc=6, scale=1.5, size=n_samples // 2)
# 合并数据
X_apples = np.column_stack((apples_weight, apples_sweetness))
X_oranges = np.column_stack((oranges_weight, oranges_sweetness))
X = np.vstack((X_apples, X_oranges))
# 创建标签 (0=苹果, 1=橙子)
y = np.hstack((np.zeros(n_samples // 2), np.ones(n_samples // 2)))
return X, y
# 生成数据集
X, y = generate_fruit_data(n_samples=100)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建SVM分类器
# 使用径向基函数(RBF)作为核函数
# C参数控制正则化强度,值越大对误分类的惩罚越大
clf = svm.SVC(kernel='rbf', C=1.0, gamma='scale')
# 训练模型
clf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.2f}")
# 可视化决策边界和数据点
def plot_decision_boundary(X, y, clf, title):
"""
绘制SVM的决策边界和数据点
参数:
X: 特征矩阵
y: 标签
clf: 训练好的SVM分类器
title: 图表标题
"""
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10, 6))
# 绘制数据点
plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], c='red', marker='o', label='苹果', s=50)
plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], c='orange', marker='^', label='橙子', s=50)
# 创建网格来绘制决策边界
h = 0.2 # 网格步长
x_min, x_max = X[:, 0].min() - 10, X[:, 0].max() + 10
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# 预测网格点的类别
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制决策边界和间隔边界
plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.coolwarm)
plt.contour(xx, yy, Z, levels=[0], linewidths=2, colors='k')
# 标记支持向量
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], s=100,
linewidth=1, facecolors='none', edgecolors='k', label='支持向量')
plt.xlabel('重量(克)')
plt.ylabel('甜度(0-10)')
plt.title(title)
plt.legend(loc='upper left')
plt.grid(True)
plt.show()
# 可视化训练集上的决策边界
plot_decision_boundary(X_train, y_train, clf, 'SVM水果分类决策边界 (训练集)')
# 预测新样本
def predict_fruit(weight, sweetness, model):
"""预测给定重量和甜度的水果类别"""
fruit_type = model.predict([[weight, sweetness]])[0]
fruit_name = "苹果" if fruit_type == 0 else "橙子"
confidence = model.decision_function([[weight, sweetness]])[0]
print(f"预测结果: 重量为{weight}克,甜度为{sweetness}的水果是{fruit_name}")
print(f"决策函数值: {confidence:.2f},值越大表示越确信是橙子,值越小表示越确信是苹果")
# 测试几个新样本
predict_fruit(160, 8.5, clf) # 可能是苹果
predict_fruit(210, 6.2, clf) # 可能是橙子
predict_fruit(180, 7.0, clf) # 接近边界的样本模型准确率: 0.87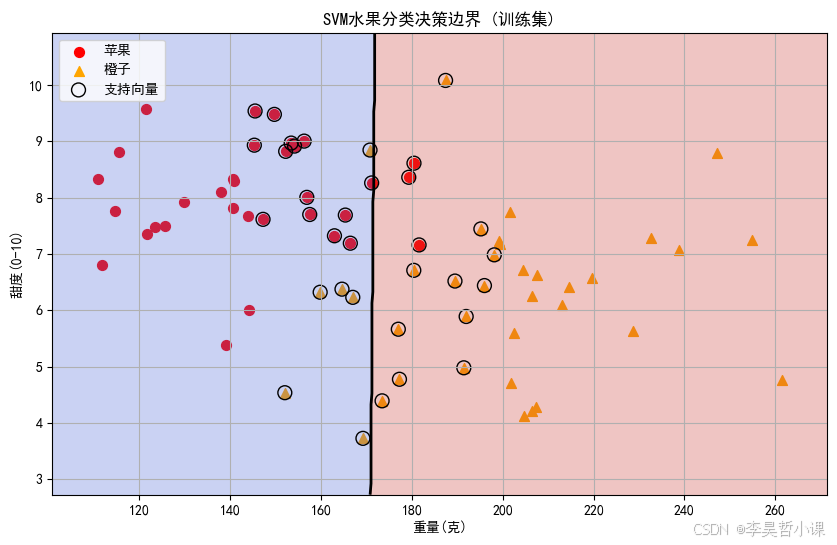
预测结果: 重量为160克,甜度为8.5的水果是苹果
决策函数值: -0.46,值越大表示越确信是橙子,值越小表示越确信是苹果
预测结果: 重量为210克,甜度为6.2的水果是橙子
决策函数值: 1.38,值越大表示越确信是橙子,值越小表示越确信是苹果
预测结果: 重量为180克,甜度为7.0的水果是橙子
决策函数值: 0.33,值越大表示越确信是橙子,值越小表示越确信是苹果垃圾邮件检测(基于邮件内容和发件人特征)
基于邮件长度、特殊字符比例和发件人可疑度等特征判断邮件是否为垃圾邮件。
python
import numpy as np
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 模拟垃圾邮件检测数据
def generate_spam_data(n_samples=200, random_state=42):
"""
生成垃圾邮件检测数据集
参数:
n_samples: 样本数量
random_state: 随机种子
返回:
X: 特征矩阵 (邮件长度, 特殊字符比例, 发件人可疑度)
y: 标签 (0=正常邮件, 1=垃圾邮件)
"""
np.random.seed(random_state)
# 正常邮件特征 (较短, 特殊字符少, 发件人可疑度低)
normal_length = np.random.normal(loc=200, scale=100, size=n_samples // 2)
normal_special_chars = np.random.normal(loc=0.05, scale=0.03, size=n_samples // 2)
normal_sender = np.random.normal(loc=0.1, scale=0.05, size=n_samples // 2)
# 垃圾邮件特征 (较长, 特殊字符多, 发件人可疑度高)
spam_length = np.random.normal(loc=500, scale=200, size=n_samples // 2)
spam_special_chars = np.random.normal(loc=0.2, scale=0.05, size=n_samples // 2)
spam_sender = np.random.normal(loc=0.8, scale=0.1, size=n_samples // 2)
# 合并数据
X_normal = np.column_stack((normal_length, normal_special_chars, normal_sender))
X_spam = np.column_stack((spam_length, spam_special_chars, spam_sender))
X = np.vstack((X_normal, X_spam))
# 创建标签 (0=正常邮件, 1=垃圾邮件)
y = np.hstack((np.zeros(n_samples // 2), np.ones(n_samples // 2)))
return X, y
# 生成数据集
X, y = generate_spam_data(n_samples=200)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建SVM分类器
clf = svm.SVC(kernel='rbf', C=10, gamma='scale')
# 训练模型
clf.fit(X_train, y_train)
# 预测并评估
y_pred = clf.predict(X_test)
print("垃圾邮件检测模型评估:")
print(classification_report(y_test, y_pred, target_names=['正常邮件', '垃圾邮件']))
# 预测新邮件
def predict_spam(email_length, special_char_ratio, sender_suspicion, model):
"""预测邮件是否为垃圾邮件"""
is_spam = model.predict([[email_length, special_char_ratio, sender_suspicion]])[0]
result = "垃圾邮件" if is_spam else "正常邮件"
confidence = model.decision_function([[email_length, special_char_ratio, sender_suspicion]])[0]
print(f"预测结果: 该邮件是{result}")
print(f"置信度得分: {confidence:.2f} (正值表示垃圾邮件,负值表示正常邮件)")
# 测试预测功能
predict_spam(300, 0.08, 0.2, clf) # 可能是正常邮件
predict_spam(600, 0.18, 0.7, clf) # 可能是垃圾邮件垃圾邮件检测模型评估:
precision recall f1-score support
正常邮件 0.90 0.90 0.90 31
垃圾邮件 0.90 0.90 0.90 29
accuracy 0.90 60
macro avg 0.90 0.90 0.90 60
weighted avg 0.90 0.90 0.90 60
预测结果: 该邮件是正常邮件
置信度得分: -0.33 (正值表示垃圾邮件,负值表示正常邮件)
预测结果: 该邮件是垃圾邮件
置信度得分: 3.42 (正值表示垃圾邮件,负值表示正常邮件)疾病诊断(基于症状和检查指标)
通过体温、血压、心率和白细胞计数等生理指标来判断患者是否患病。
python
import numpy as np
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 模拟疾病诊断数据
def generate_disease_data(n_samples=150, random_state=42):
"""
生成疾病诊断数据集
参数:
n_samples: 样本数量
random_state: 随机种子
返回:
X: 特征矩阵 (体温, 血压, 心率, 白细胞计数)
y: 标签 (0=健康, 1=患病)
"""
np.random.seed(random_state)
# 健康人群特征
healthy_temp = np.random.normal(loc=36.5, scale=0.5, size=n_samples // 2)
healthy_bp = np.random.normal(loc=120, scale=10, size=n_samples // 2)
healthy_hr = np.random.normal(loc=70, scale=10, size=n_samples // 2)
healthy_wbc = np.random.normal(loc=7.5, scale=1.5, size=n_samples // 2)
# 患病人群特征
sick_temp = np.random.normal(loc=38.5, scale=1.0, size=n_samples // 2)
sick_bp = np.random.normal(loc=140, scale=15, size=n_samples // 2)
sick_hr = np.random.normal(loc=90, scale=15, size=n_samples // 2)
sick_wbc = np.random.normal(loc=12.5, scale=3.0, size=n_samples // 2)
# 合并数据
X_healthy = np.column_stack((healthy_temp, healthy_bp, healthy_hr, healthy_wbc))
X_sick = np.column_stack((sick_temp, sick_bp, sick_hr, sick_wbc))
X = np.vstack((X_healthy, X_sick))
# 创建标签 (0=健康, 1=患病)
y = np.hstack((np.zeros(n_samples // 2), np.ones(n_samples // 2)))
return X, y
# 生成数据集
X, y = generate_disease_data(n_samples=150)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建SVM分类器
clf = svm.SVC(kernel='rbf', C=5, gamma='scale')
# 训练模型
clf.fit(X_train, y_train)
# 预测并评估
y_pred = clf.predict(X_test)
print("疾病诊断模型评估:")
print(classification_report(y_test, y_pred, target_names=['健康', '患病']))
# 预测新病例
def predict_disease(temperature, blood_pressure, heart_rate, wbc_count, model):
"""预测患者是否患病"""
is_sick = model.predict([[temperature, blood_pressure, heart_rate, wbc_count]])[0]
result = "患病" if is_sick else "健康"
confidence = model.decision_function([[temperature, blood_pressure, heart_rate, wbc_count]])[0]
print(f"预测结果: 该患者{result}")
print(f"置信度得分: {confidence:.2f} (正值表示患病,负值表示健康)")
# 测试预测功能
predict_disease(37.0, 125, 72, 8.0, clf) # 可能健康
predict_disease(39.2, 145, 95, 14.2, clf) # 可能患病疾病诊断模型评估:
precision recall f1-score support
健康 0.90 1.00 0.95 27
患病 1.00 0.83 0.91 18
accuracy 0.93 45
macro avg 0.95 0.92 0.93 45
weighted avg 0.94 0.93 0.93 45
预测结果: 该患者健康
置信度得分: -0.67 (正值表示患病,负值表示健康)
预测结果: 该患者患病
置信度得分: 2.18 (正值表示患病,负值表示健康)手写数字识别(区分0-9的数字)
使用 scikit-learn 自带的手写数字数据集,训练 SVM 模型识别 0-9 的数字。
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets, svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载手写数字数据集
digits = datasets.load_digits()
# 探索数据
print(f"数据集大小: {len(digits.data)}个样本")
print(f"每个样本特征数: {digits.data.shape[1]} (8x8像素图像)")
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 可视化一些样本
plt.figure(figsize=(10, 5))
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(digits.images[i], cmap=plt.cm.gray_r)
plt.title(f"数字: {digits.target[i]}")
plt.axis('off')
plt.tight_layout()
plt.show()
# 准备数据
X = digits.data # 特征矩阵 (1797x64)
y = digits.target # 标签 (0-9)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建SVM分类器
clf = svm.SVC(gamma=0.001, C=100)
# 训练模型
clf.fit(X_train, y_train)
# 预测并评估
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"手写数字识别准确率: {accuracy:.4f}")
# 可视化预测结果
plt.figure(figsize=(12, 6))
for i in range(12):
plt.subplot(3, 4, i + 1)
plt.imshow(X_test[i].reshape(8, 8), cmap=plt.cm.gray_r)
plt.title(f"预测: {y_pred[i]}, 实际: {y_test[i]}")
plt.axis('off')
plt.tight_layout()
plt.show()
# 测试单个样本预测
def predict_digit(sample_index, model):
"""预测单个手写数字"""
sample = X_test[sample_index].reshape(1, -1)
prediction = model.predict(sample)[0]
confidence = np.max(model.decision_function(sample))
print(f"预测结果: 数字 {prediction}")
print(f"置信度: {confidence:.2f}")
# 可视化预测的样本
plt.figure(figsize=(4, 4))
plt.imshow(X_test[sample_index].reshape(8, 8), cmap=plt.cm.gray_r)
plt.title(f"预测: {prediction}, 实际: {y_test[sample_index]}")
plt.axis('off')
plt.show()
# 测试预测功能
predict_digit(0, clf) # 预测测试集中第一个样本数据集大小: 1797个样本
每个样本特征数: 64 (8x8像素图像)
手写数字识别准确率: 0.9907
预测结果: 数字 6
置信度: 9.30
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets, svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import cv2
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 加载手写数字数据集
digits = datasets.load_digits()
# 探索数据
print(f"数据集大小: {len(digits.data)}个样本")
print(f"每个样本特征数: {digits.data.shape[1]} (8x8像素图像)")
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 可视化一些样本
plt.figure(figsize=(10, 5))
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(digits.images[i], cmap=plt.cm.gray_r)
plt.title(f"数字: {digits.target[i]}")
plt.axis('off')
plt.tight_layout()
plt.show()
# 准备数据
X = digits.data # 特征矩阵 (1797x64)
y = digits.target # 标签 (0-9)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建SVM分类器
clf = svm.SVC(gamma=0.001, C=100, probability=True)
# 训练模型
clf.fit(X_train, y_train)
# 预测并评估
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"手写数字识别准确率: {accuracy:.4f}")
# 可视化预测结果
plt.figure(figsize=(12, 6))
for i in range(12):
plt.subplot(3, 4, i + 1)
plt.imshow(X_test[i].reshape(8, 8), cmap=plt.cm.gray_r)
plt.title(f"预测: {y_pred[i]}, 实际: {y_test[i]}")
plt.axis('off')
plt.tight_layout()
plt.show()
# 测试单个样本预测
def predict_digit(sample_index, model):
"""预测单个手写数字"""
sample = X_test[sample_index].reshape(1, -1)
prediction = model.predict(sample)[0]
confidence = np.max(model.predict_proba(sample))
print(f"预测结果: 数字 {prediction}")
print(f"置信度: {confidence:.2%}")
# 可视化预测的样本
plt.figure(figsize=(4, 4))
plt.imshow(X_test[sample_index].reshape(8, 8), cmap=plt.cm.gray_r)
plt.title(f"预测: {prediction}, 实际: {y_test[sample_index]}")
plt.axis('off')
plt.show()
# 摄像头拍照预测功能
def predict_from_camera(model):
"""从摄像头捕获图像并进行数字预测"""
# 打开摄像头
cap = cv2.VideoCapture(3)
if not cap.isOpened():
print("无法打开摄像头")
return
print("按 's' 键拍照并预测,按 'q' 键退出")
while True:
# 读取一帧图像
ret, frame = cap.read()
if not ret:
print("无法获取图像")
break
# 显示当前帧
cv2.imshow('摄像头', frame)
# 等待按键事件
key = cv2.waitKey(1)
# 按 's' 键拍照并预测
if key == ord('s'):
# 转换为灰度图
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 调整图像大小为8x8
resized = cv2.resize(gray, (8, 8), interpolation=cv2.INTER_AREA)
# 反转颜色(因为MNIST数据集是白底黑字)
inverted = cv2.bitwise_not(resized)
# 归一化到0-16范围(与MNIST数据集匹配)
normalized = inverted.astype(np.float32) / 16.0
# 展平为一维数组
flattened = normalized.flatten().reshape(1, -1)
# 预测
prediction = model.predict(flattened)[0]
confidence = np.max(model.predict_proba(flattened))
# 显示预测结果
print(f"\n===== 预测结果 =====")
print(f"预测数字: {prediction}")
print(f"置信度: {confidence:.2%}")
# 可视化预测结果
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.imshow(frame)
plt.title('原始摄像头图像')
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(normalized, cmap=plt.cm.gray_r)
plt.title(f'处理后的图像 - 预测: {prediction}')
plt.axis('off')
plt.tight_layout()
plt.show()
# 按 'q' 键退出
elif key == ord('q'):
break
# 释放摄像头并关闭窗口
cap.release()
cv2.destroyAllWindows()
# 测试预测功能
predict_digit(0, clf) # 预测测试集中第一个样本
# 启动摄像头预测功能
predict_from_camera(clf)数据集大小: 1797个样本
每个样本特征数: 64 (8x8像素图像)
手写数字识别准确率: 0.9907
预测结果: 数字 6
置信度: 97.54%
按 's' 键拍照并预测,按 'q' 键退出
===== 预测结果 =====
预测数字: 9
置信度: 17.40%
金融风险评估(区分高风险和低风险客户)
根据客户收入、负债比率、信用历史长度和违约次数等特征评估客户的风险等级。
python
import numpy as np
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 模拟金融风险评估数据
def generate_risk_data(n_samples=300, random_state=42):
"""
生成金融风险评估数据集
参数:
n_samples: 样本数量
random_state: 随机种子
返回:
X: 特征矩阵 (收入, 负债比率, 信用历史长度, 违约次数)
y: 标签 (0=低风险, 1=高风险)
"""
np.random.seed(random_state)
# 低风险客户特征
low_income = np.random.normal(loc=8000, scale=2000, size=n_samples // 2)
low_debt_ratio = np.random.normal(loc=0.3, scale=0.1, size=n_samples // 2)
low_credit_history = np.random.normal(loc=120, scale=30, size=n_samples // 2)
low_defaults = np.random.poisson(lam=0.2, size=n_samples // 2)
# 高风险客户特征
high_income = np.random.normal(loc=5000, scale=1500, size=n_samples // 2)
high_debt_ratio = np.random.normal(loc=0.7, scale=0.15, size=n_samples // 2)
high_credit_history = np.random.normal(loc=60, scale=25, size=n_samples // 2)
high_defaults = np.random.poisson(lam=1.5, size=n_samples // 2)
# 合并数据
X_low_risk = np.column_stack((low_income, low_debt_ratio, low_credit_history, low_defaults))
X_high_risk = np.column_stack((high_income, high_debt_ratio, high_credit_history, high_defaults))
X = np.vstack((X_low_risk, X_high_risk))
# 创建标签 (0=低风险, 1=高风险)
y = np.hstack((np.zeros(n_samples // 2), np.ones(n_samples // 2)))
return X, y
# 生成数据集
X, y = generate_risk_data(n_samples=300)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建SVM分类器
clf = svm.SVC(kernel='rbf', C=10, gamma='scale')
# 训练模型
clf.fit(X_train, y_train)
# 预测并评估
y_pred = clf.predict(X_test)
print("金融风险评估模型评估:")
print(classification_report(y_test, y_pred, target_names=['低风险', '高风险']))
# 预测新客户风险
def predict_risk(income, debt_ratio, credit_history, defaults, model):
"""预测客户的风险等级"""
risk_level = model.predict([[income, debt_ratio, credit_history, defaults]])[0]
result = "高风险" if risk_level else "低风险"
confidence = model.decision_function([[income, debt_ratio, credit_history, defaults]])[0]
print(f"预测结果: 该客户是{result}客户")
print(f"置信度得分: {confidence:.2f} (正值表示高风险,负值表示低风险)")
# 测试预测功能
predict_risk(7500, 0.25, 100, 0, clf) # 可能是低风险
predict_risk(4000, 0.8, 40, 2, clf) # 可能是高风险金融风险评估模型评估:
precision recall f1-score support
低风险 0.90 0.79 0.84 48
高风险 0.79 0.90 0.84 42
accuracy 0.84 90
macro avg 0.85 0.85 0.84 90
weighted avg 0.85 0.84 0.84 90
预测结果: 该客户是低风险客户
置信度得分: -0.52 (正值表示高风险,负值表示低风险)
预测结果: 该客户是高风险客户
置信度得分: 1.21 (正值表示高风险,负值表示低风险)