适合读者:有一定Python基础,想学习数据分析的读者。
一、工具准备
- Python 3.x
- Jupyter Notebook(推荐用于交互式分析)
- Pandas:数据处理与分析
- Matplotlib 、Seaborn:数据可视化
安装方法:
bash
pip install jupyter pandas matplotlib seaborn二、实战案例
案例1:销售数据趋势分析(Pandas分组统计)
目标:分析某产品每月销售额趋势。
示例数据:
python
import pandas as pd
# 直接用字典模拟数据
sales_data = {
'date': ['2023-01-05', '2023-01-15', '2023-02-10', '2023-02-20', '2023-03-05'],
'product': ['A', 'A', 'A', 'A', 'A'],
'sales': [120, 150, 200, 180, 210]
}
sales = pd.DataFrame(sales_data)
sales['date'] = pd.to_datetime(sales['date'])
sales['month'] = sales['date'].dt.to_period('M')
monthly_sales = sales.groupby('month')['sales'].sum().reset_index()
print(monthly_sales)结果解读:
- 输出每月总销售额,可用于趋势分析和后续可视化。

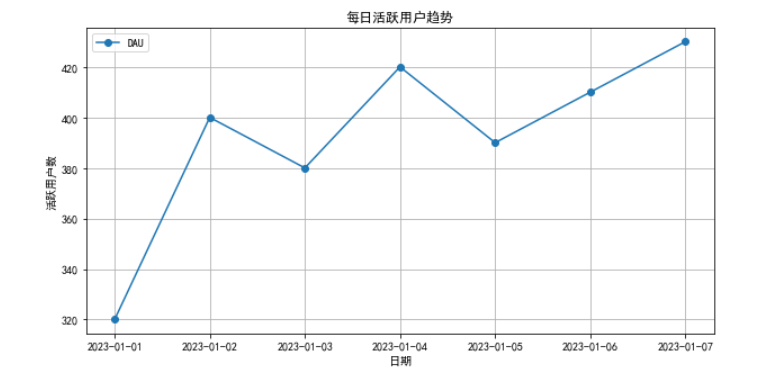
案例2:用户行为数据可视化(Matplotlib绘制折线图/柱状图)
目标:展示网站每日活跃用户(DAU)变化。
示例数据:
python
import pandas as pd
import matplotlib.pyplot as plt
# 设置中文字体(替换为你的系统支持的字体名)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows
# plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # Mac
# plt.rcParams['font.sans-serif'] = ['WenQuanYi Zen Hei'] # Linux
# 解决负号显示问题
plt.rcParams['axes.unicode_minus'] = False
# 用字典模拟数据
user_data = pd.DataFrame({
'date': pd.date_range('2023-01-01', periods=7),
'dau': [320, 400, 380, 420, 390, 410, 430]
})
plt.figure(figsize=(10, 5))
plt.plot(user_data['date'], user_data['dau'], marker='o', label='DAU')
plt.title('每日活跃用户趋势')
plt.xlabel('日期')
plt.ylabel('活跃用户数')
plt.legend()
plt.grid(True)
plt.show()结果解读:
- 折线图直观展示了活跃用户的波动和趋势,便于发现高峰和低谷。
案例3:电影评分数据探索(Seaborn热力图分析相关性)
目标:探索不同电影特征(如评分、时长、票房)之间的相关性。
示例数据:
python
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 用字典模拟数据
movies = pd.DataFrame({
'title': ['Movie A', 'Movie B', 'Movie C', 'Movie D'],
'rating': [8.2, 7.5, 6.8, 8.0],
'duration': [120, 95, 110, 130],
'box_office': [1.5e8, 8.0e7, 6.5e7, 2.0e8]
})
correlation = movies[['rating', 'duration', 'box_office']].corr()
plt.figure(figsize=(6, 4))
sns.heatmap(correlation, annot=True, cmap='YlGnBu')
plt.title('电影特征相关性热力图')
plt.show()结果解读:
- 热力图展示了各特征之间的相关性(如评分与票房、时长与票房等),有助于发现潜在的影响关系。

案例4:社交媒体文本情感分析(简单NLP示例)
目标:对社交媒体评论进行情感极性分类(正面/负面)。
示例数据:
python
import pandas as pd
from textblob import TextBlob
# 用字典模拟数据
comments = pd.DataFrame({
'comment': [
'I love this product!',
'Terrible experience...',
'Not bad, could be better.',
'Absolutely fantastic!',
'Worst service ever.'
]
})
def get_sentiment(text):
return TextBlob(str(text)).sentiment.polarity
comments['sentiment'] = comments['comment'].apply(get_sentiment)
print(comments[['comment', 'sentiment']])结果解读:
sentiment值大于0为正面,小于0为负面,等于0为中性。可据此统计正负面评论比例。
案例5:预测模型入门(线性回归预测房价)
目标:用线性回归模型预测房价。
示例数据:
python
import pandas as pd
from sklearn.linear_model import LinearRegression
# 用字典模拟数据
house = pd.DataFrame({
'area': [80, 120, 100, 90, 110],
'bedrooms': [2, 3, 2, 1, 3],
'price': [500, 800, 650, 480, 780]
})
X = house[['area', 'bedrooms']]
y = house['price']
model = LinearRegression()
model.fit(X, y)
pred = model.predict([[100, 2]])
print(f"预测100平米2居室房价:{pred[0]:.2f}")结果解读:
- 通过输入面积和卧室数,模型可预测房价,实现数据驱动的房产估价。

总结:Python在数据分析中的优势
- 生态丰富,工具链完善(Pandas、Matplotlib、Seaborn、Scikit-learn等)。
- 代码简洁,易于上手,适合快速原型开发和数据探索。
- 社区活跃,资料丰富,适合自学和进阶。
以上5个案例涵盖了数据分析的常见场景,建议读者动手实践、结合自己的数据进行深入探索。