TF-IDF(Term Frequency - Inverse Document Frequency)是一种在信息检索与文本挖掘中非常常用的关键词提取方法,用于衡量一个词在文档集合中的重要性。它的核心思想是:
如果一个词在某个文档中出现得频繁,同时在其他文档中很少出现,那么这个词对该文档具有较强的区分性,应当被赋予较高的权重。
一、TF-IDF 的基本组成
1. TF(Term Frequency)------词频
表示词语在当前文档中出现的频率。常见定义如下:

用于衡量词对当前文档的重要性。
2. IDF(Inverse Document Frequency)------逆文档频率
表示某个词在整个语料库中出现的"稀有程度":
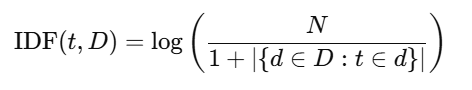
其中:
-
NNN:语料库中的文档总数
-
∣{d∈D:t∈d}:包含词 t 的文档数量
-
加 1 是为了避免除以 0
IDF 越大,说明词越"稀有",对区分性越重要。
3. TF-IDF 计算公式
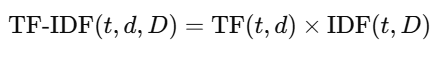
即:某词在某文档中的词频 × 该词在整个语料库中的逆文档频率。
二、TF-IDF 的直观理解
-
一个词在文档中频繁出现 → TF 高 → 可能重要
-
但如果这个词在所有文档中都频繁出现(比如 "的""是""and") → IDF 低 → 权重应该降低
-
所以 TF-IDF 是一种平衡词频与泛用性的机制
三、使用场景
-
关键词提取:找出一篇文章中最重要的词语
-
文本分类:将文档向量化后用于机器学习模型
-
信息检索:计算查询和文档之间的相关性(如搜索引擎)
四、TF-IDF 的特点
优点:
-
简单高效,无需训练模型
-
能过滤掉高频但无意义的词(如停用词)
-
常用于传统机器学习方法(SVM、朴素贝叶斯等)中的文本特征表示
缺点:
-
无法捕捉语义("漂亮"和"美丽"是不同的词)
-
对词的顺序不敏感(bag-of-words 特性)
-
对长文档可能存在偏差(词频偏大)
五、TF-IDF 在 Python 中的使用示例(基于 scikit-learn)
python
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
"我喜欢自然语言处理",
"语言模型是人工智能的核心",
"我正在学习文本挖掘"
]
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(corpus)
# 输出词汇表
print(vectorizer.get_feature_names_out())
# 查看第一个句子的TF-IDF向量
print(tfidf_matrix[0].toarray())