传统的AI聊天系统往往局限于预训练数据的知识范围,无法获取实时信息。本文将详细阐述如何构建一个基于LangGraph的智能代理系统,该系统能够智能判断何时需要进行网络搜索、有效维护对话上下文,并具备将对话内容导出为PDF文档的功能。
本系统的核心特性包括:基于智能判断机制的自动网络搜索触发、跨多轮对话的上下文状态管理、多策略搜索机制与智能回退、透明的信息源追溯体系,以及专业级PDF文档生成功能。
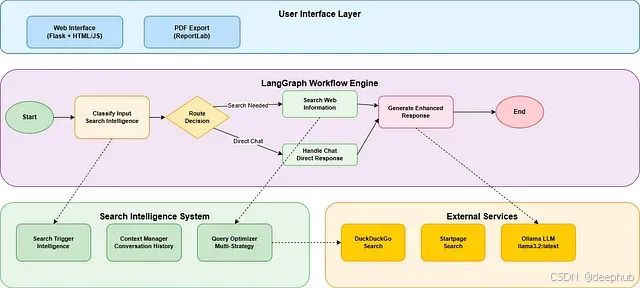
LangGraph技术架构
LangGraph是专为构建有状态多角色应用程序而设计的框架,特别适用于与大型语言模型的集成开发。相较于传统的聊天接口,LangGraph提供了更为复杂的工作流管理能力。
该框架的核心优势体现在四个方面:其一是跨对话轮次的状态管理机制,确保系统能够记忆和利用历史交互信息;其二是基于用户输入或上下文的条件路由功能,使系统能够根据不同情况采取相应的处理策略;其三是支持决策点的多步骤工作流,允许复杂的业务逻辑实现;其四是人机协作交互模式,在必要时引入人工干预。
从架构设计角度,LangGraph可以视为AI应用程序的状态机实现,其中每个节点代表特定的功能模块(如输入分类、信息搜索、响应生成),而节点间的连接边则定义了数据流和控制流。
本智能搜索代理系统采用模块化架构设计,由六个核心组件协同工作:
┌─────────────────────────────────────────────────────────────┐
│ 增强搜索代理 │
├─────────────────────────────────────────────────────────────┤
│ ┌─────────────────┐ ┌─────────────────┐ ┌──────────────┐ │
│ │ 搜索触发 │ │ 搜索策略 │ │ 结果 │ │
│ │ 智能 │ │ 管理器 │ │ 处理器 │ │
│ └─────────────────┘ └─────────────────┘ └──────────────┘ │
├─────────────────────────────────────────────────────────────┤
│ ┌─────────────────┐ ┌─────────────────┐ ┌──────────────┐ │
│ │ 上下文 │ │ 多来源 │ │ PDF │ │
│ │ 管理器 │ │ 搜索引擎 │ │ 生成器 │ │
│ └─────────────────┘ └─────────────────┘ └──────────────┘ │
├─────────────────────────────────────────────────────────────┤
│ LangGraph 工作流引擎 │
└─────────────────────────────────────────────────────────────┘基础模块
搜索触发智能模块
搜索触发智能模块是系统的核心决策组件,负责自动识别何时需要进行网络搜索。该模块采用基于模式识别的智能分析方法,而非简单的关键词匹配机制。
class SearchTriggerIntelligence:
def __init__(self):
# 时间敏感关键词定义,用于识别对当前信息的需求
self.temporal_keywords = {
'immediate': ['now', 'currently', 'today', 'this week'],
'recent': ['latest', 'recent', 'new', 'fresh', 'updated'],
'trending': ['trending', 'popular', 'viral', 'breaking'],
'temporal_markers': ['2025', '2024', 'this year'],
'news_indicators': ['news', 'developments', 'updates']
}
# 需要实时信息更新的主题类别定义
self.current_info_topics = {
'technology': ['ai', 'artificial intelligence', 'tech', 'software'],
'finance': ['market', 'stock', 'crypto', 'bitcoin', 'economy'],
'news': ['politics', 'election', 'government', 'policy'],
'science': ['research', 'study', 'discovery', 'breakthrough']
}该模块通过多维度分析用户输入来做出搜索决策。时间指示器分析识别诸如"latest"、"current"、"2024"等表示时效性需求的词汇。主题类别分析涵盖技术、金融、新闻、科学等需要实时信息更新的领域。书籍模式检测专门用于识别关于特定出版物的查询请求。不确定性信号检测则在AI系统表达知识局限性时触发搜索机制。
上下文感知对话管理
对话AI系统面临的主要技术挑战之一是在多轮交互中保持上下文连贯性。本系统通过智能上下文解析机制有效解决了这一问题。
def _resolve_contextual_references(self, user_input: str, context: Dict = None) -> str:
"""
通过分析对话历史解析用户输入中的上下文引用
"""
# 定义后续对话模式的正则表达式
follow_up_patterns = [
r'^(give me|provide|write|create)\s+(a\s+)?(summary|overview|analysis)',
r'^(tell me more|more about|elaborate|expand)',
r'^(summarize|analyze|explain)\s+(it|this|that)',
r'^\d+\s+word\s+(summary|analysis|overview)'
]
is_follow_up = any(re.match(pattern, user_input.lower()) for pattern in follow_up_patterns)
if is_follow_up:
# 从对话历史中提取最近讨论的主题
recent_topic = self._extract_recent_topic(context.get('messages', []))
if recent_topic:
return f"Provide a summary of {recent_topic}"
return user_input该机制的核心在于理解用户请求的语义关联性。当用户在讨论特定书籍后提出"给我一个500字的总结"这样的请求时,系统能够准确识别其指向性,理解用户需要的是该特定书籍的总结,而非通用性摘要。
LangGraph工作流构建
系统的工作流基于LangGraph框架构建,采用状态图模式管理整个对话流程。
from langgraph.graph import StateGraph, START, END
from typing import TypedDict, Annotated, List, Dict
class ConversationState(TypedDict):
messages: Annotated[list, add_messages]
user_input: str
conversation_type: str
context: dict
session_id: str
needs_web_search: bool
search_results: List[Dict]
search_queries: List[str]
sources: List[str]
def create_workflow():
workflow = StateGraph(ConversationState)
# 注册功能节点
workflow.add_node("classify_input", classify_input)
workflow.add_node("search_web_information", search_web_information)
workflow.add_node("generate_search_enhanced_response", generate_search_enhanced_response)
workflow.add_node("handle_chat", handle_chat)
# 定义节点间的连接关系
workflow.add_edge(START, "classify_input")
workflow.add_conditional_edges(
"classify_input",
route_conversation,
{
"search_web_information": "search_web_information",
"handle_chat": "handle_chat"
}
)
return workflow.compile()智能输入分类机制
输入分类功能是整个系统的决策起点,负责分析用户输入并确定后续处理策略。
def classify_input(state: ConversationState) -> ConversationState:
"""用户输入分类与搜索需求判断"""
# 构建上下文信息
context = {
'messages': state.get('messages', []),
'session_id': state.get('session_id', ''),
'conversation_history': state.get('context', {})
}
# 调用搜索智能判断机制
search_decision = search_intelligence.should_trigger_search(
state['user_input'], context
)
# 使用大型语言模型进行对话类型分类
prompt = f"""
请将以下用户输入归类到相应类别:
输入内容: "{state['user_input']}"
可选类别:
- chat: 日常对话、一般性问题、闲聊交流
- research: 用户请求针对特定主题的研究分析
- task: 用户寻求特定任务或问题的解决方案
- help: 用户需要理解或学习特定概念
请仅返回类别名称。
"""
response = llm.invoke([HumanMessage(content=prompt)])
conversation_type = response.content.strip().lower()
return {
**state,
"conversation_type": conversation_type,
"needs_web_search": search_decision.should_search,
"search_queries": search_decision.suggested_queries,
"context": {
**state.get("context", {}),
"search_decision": {
"confidence": search_decision.confidence,
"reasoning": search_decision.reasoning,
"topic_category": search_decision.topic_category,
"urgency_level": search_decision.urgency_level
}
}
}多策略网络搜索实现
当系统确定需要进行网络搜索时,采用多层次策略确保搜索的成功率和结果质量。
def search_web_information(state: ConversationState) -> ConversationState:
"""多策略网络搜索执行"""
search_attempts = 0
max_attempts = 3
all_search_results = []
# 第一策略:使用智能推荐的搜索查询
suggested_queries = state.get('search_queries', [])
for query in suggested_queries[:2]:
search_attempts += 1
try:
results = search_tool.search(query, max_results=6)
if results:
all_search_results.extend(results)
break
except Exception as e:
continue
# 第二策略:在无搜索结果时使用增强查询
if not all_search_results and search_attempts < max_attempts:
enhanced_queries = _generate_enhanced_queries(
state['user_input'],
topic_category
)
for query in enhanced_queries[:2]:
search_attempts += 1
try:
results = search_tool.search(query, max_results=5)
if results:
all_search_results.extend(results)
break
except Exception as e:
continue
# 第三策略:简化回退查询机制
if not all_search_results:
simplified_query = _create_simplified_query(state['user_input'])
try:
results = search_tool.search(simplified_query, max_results=5)
all_search_results.extend(results)
except Exception as e:
pass
return {
**state,
"search_results": all_search_results,
"sources": [r.get('url', '') for r in all_search_results]
}上下文感知响应生成
响应生成模块负责整合搜索结果与对话上下文,生成连贯且相关的回复。
def generate_search_enhanced_response(state: ConversationState) -> ConversationState:
"""基于搜索结果和对话上下文生成响应"""
# 构建对话上下文信息
conversation_context = ""
recent_messages = state.get('messages', [])[-6:]
if recent_messages:
conversation_context = "\n\n**对话上下文信息:**\n"
for msg in recent_messages:
if hasattr(msg, 'content') and not msg.content.startswith('🔍'):
role = "用户" if "HumanMessage" in str(type(msg)) else "助手"
conversation_context += f"{role}: {msg.content[:200]}...\n"
# 格式化搜索结果信息
search_context = ""
if state.get('search_results'):
search_context = f"\n\n🔍 **网络搜索结果**:\n"
for i, result in enumerate(state['search_results'][:10], 1):
search_context += f"{i}. **{result.get('title', 'No title')}**\n"
search_context += f" {result.get('snippet', 'No description')}\n"
search_context += f" 来源: {result.get('url', 'No URL')}\n\n"
prompt = f"""
基于以下信息回答用户问题: "{state['user_input']}"
{conversation_context}
{search_context}
响应生成准则:
1. **上下文连贯性**: 充分考虑之前的对话内容
2. **信息时效性**: 优先使用搜索结果中的最新数据
3. **来源透明性**: 明确标注信息来源
4. **信息优先级**: 最新来源信息优于训练数据
5. **回答针对性**: 确保回答直接针对用户问题
"""
response = llm.invoke([HumanMessage(content=prompt)])
return {
**state,
"messages": state["messages"] + [
HumanMessage(content=state["user_input"]),
AIMessage(content=response.content)
]
}高级功能模块
PDF文档生成系统
系统的一个独特功能是能够将任何对话内容导出为专业格式的PDF文档。该功能基于ReportLab库实现,提供了完整的文档格式化和样式控制。
def generate_pdf_from_markdown(content: str, title: str, session_id: str) -> str:
"""基于Markdown内容生成专业PDF文档"""
# 创建具有专业样式的PDF文档
doc = SimpleDocTemplate(filepath, pagesize=A4)
# 定义专业文档样式
title_style = ParagraphStyle(
'CustomTitle',
fontSize=24,
spaceAfter=30,
alignment=1, # 居中对齐
textColor=HexColor('#2c3e50')
)
# 处理Markdown内容并转换为PDF元素
story = []
story.append(Paragraph(title, title_style))
# 解析Markdown并转换为PDF元素
lines = content.split('\n')
for line in lines:
if line.startswith('# '):
story.append(Paragraph(line[2:], heading_style))
elif line.startswith('## '):
story.append(Paragraph(line[3:], subheading_style))
else:
story.append(Paragraph(line, body_style))
doc.build(story)
return filename错误处理与降级机制
系统实现了完善的错误处理和优雅降级机制,确保在外部服务故障时仍能提供有价值的响应。
def handle_search_errors(self, error: Exception, query: str) -> SearchResults:
"""搜索错误处理与优雅降级"""
if "rate limit" in str(error).lower():
return self._create_rate_limit_response(query)
elif "network" in str(error).lower():
return self._create_network_error_response(query)
else:
return self._create_knowledge_based_fallback(query)Web界面集成
系统提供了基于Flask的现代化Web界面,支持实时聊天和PDF导出功能。
@app.route('/chat', methods=['POST'])
def chat():
"""主要聊天端点,支持PDF生成功能"""
data = request.get_json()
user_message = data.get('message', '')
session_id = session.get('session_id', str(uuid.uuid4()))
# 执行LangGraph工作流
result = workflow_app.invoke(initial_state)
# 对超过10词的响应生成PDF
word_count = len(last_response.split())
if word_count > 10:
pdf_filename = generate_pdf_from_markdown(
last_response,
f"Chat Export: {user_message[:50]}...",
session_id
)
if pdf_filename:
response_data['pdf_available'] = True
response_data['pdf_filename'] = pdf_filename
return jsonify(response_data)性能优化与扩展性
缓存策略实现
通过缓存近期搜索结果,系统能够减少API调用次数,提高响应速度。
# 缓存近期搜索结果以减少API调用
@lru_cache(maxsize=100)
def cached_search(query: str, max_results: int) -> List[Dict]:
return search_tool.search(query, max_results)异步处理机制
在生产环境部署中,建议对搜索操作采用异步处理机制。
import asyncio
import aiohttp
async def async_search(queries: List[str]) -> List[Dict]:
"""并发执行多个搜索查询"""
tasks = [search_single_query(query) for query in queries]
results = await asyncio.gather(*tasks, return_exceptions=True)
return [r for r in results if not isinstance(r, Exception)]系统测试与验证
单元测试设计
def test_book_pattern_detection():
intelligence = SearchTriggerIntelligence()
decision = intelligence.should_trigger_search(
"Tell me about the book Nexus by Yuval Noah Harari"
)
assert decision.should_search == True
assert decision.topic_category == "books"
assert decision.urgency_level == "high"集成测试实现
def test_end_to_end_workflow():
workflow = create_workflow()
initial_state = {
"user_input": "Latest AI developments 2024",
"messages": [],
"session_id": "test_session"
}
result = workflow.invoke(initial_state)
assert result["needs_web_search"] == True
assert len(result["search_results"]) > 0部署配置与运维
环境配置
# 安装必要依赖
pip install langgraph langchain-ollama flask reportlab beautifulsoup4
# 启动Ollama服务器
ollama serve
ollama pull llama3.2:latest
# 运行应用程序
python web_chatbot_with_pdf.py生产环境清单
生产环境部署需要考虑以下关键要素:建立完善的日志记录和监控体系;实施搜索API的速率限制机制;配置身份验证和会话管理系统;启用HTTPS和安全标头配置;设置数据库以持久化对话记录;建立备份和恢复程序。
总结
构建智能LangGraph代理需要的不仅仅是将大型语言模型连接到搜索API,更需要深思熟虑的架构设计、健壮的错误处理机制,以及对用户体验的深度考虑。
本文所构建的系统体现了几个关键设计原则:智能化决策优于自动化执行,系统不应对所有请求都进行搜索,而应智能判断搜索的价值;上下文保持机制确保多轮对话的连贯性;优雅降级保证即使外部服务失效,系统仍能提供价值;透明度原则明确信息来源和限制;用户体验导向关注用户实际需求而非技术可行性。
这种LangGraph代理代表了对话式AI的新范式,它将大型语言模型的推理能力与实时信息获取和复杂工作流管理相结合。
https://avoid.overfit.cn/post/626374804cac4f6fbee7641f774ad9fc
作者:Swarnava Ganguly