一、Tdengine接口开发文档
1、数据库
1.创建数据库
-
URL
/dp/createdb/
-
method
post
-
请求示例
json{ "db_name":"demo01" // 必填 } -
响应示例
json// 成功 { "code": 1, "data": { "成功创建数据库": "demo04" }, "error": null }json// 失败 { "code": 0, "data": null, "error": "创建数据库失败, 该数据库已存在!" }2.获取数据库
2.获取数据库
-
URL
/dp/createdb/
-
method
get
-
请求示例
/dp/createdb/?db_name=test
参数:db_name 数据库名称,非必填
未填数据库名称则查询所有数据库
填写数据库名称则查询数据库参数
-
响应示例
json// 查询所有数据库 { "code": 1, "data": [ "information_schema", "performance_schema", "demo01", "demo06", "test", "demo03", "demo02" ], "error": null }json// 查询数据库参数 { "code": 1, "data": { "name": "test", "create_time": "2024-02-21T10:33:32.727000", "vgroups": 2, "ntables": 2, "replica": 1, "strict": "on", "duration": "14400m", "keep": "5256000m,5256000m,5256000m", "buffer": 256, "pagesize": 4, "pages": 256, "minrows": 100, "maxrows": 4096, "comp": 2, "precision": "ms", "status": "ready", "retentions": null, "single_stable": false, "cachemodel": "last_row", "cachesize": 1, "wal_level": 1, "wal_fsync_period": 3000, "wal_retention_period": 0, "wal_retention_size": 0, "wal_roll_period": 0, "wal_segment_size": 0, "stt_trigger": 1, "table_prefix": 0, "table_suffix": 0, "tsdb_pagesize": 4 }, "error": null }
3.修改数据库参数
-
URL
/dp/createdb/
-
method
put
-
请求示例
json{ "db_name":"demo01", // 必填 "cachemodel":"none", "wal_level":"1" }- CACHEMODEL:表示是否在内存中缓存子表的最近数据。默认为 none。
- none:表示不缓存。
- last_row:表示缓存子表最近一行数据。这将显著改善 LAST_ROW 函数的性能表现。
- last_value:表示缓存子表每一列的最近的非 NULL 值。这将显著改善无特殊影响(WHERE、ORDER BY、GROUP BY、INTERVAL)下的 LAST 函数的性能表现。
- both:表示同时打开缓存最近行和列功能。 Note:CacheModel 值来回切换有可能导致 last/last_row 的查询结果不准确,请谨慎操作。推荐保持打开。
- CACHESIZE:表示每个 vnode 中用于缓存子表最近数据的内存大小。默认为 1 ,范围是1, 65536,单位是 MB。
- BUFFER: 一个 VNODE 写入内存池大小,单位为 MB,默认为 256,最小为 3,最大为 16384。
- PAGES:一个 VNODE 中元数据存储引擎的缓存页个数,默认为 256,最小 64。一个 VNODE 元数据存储占用 PAGESIZE * PAGES,默认情况下为 1MB 内存。
- PAGESIZE:一个 VNODE 中元数据存储引擎的页大小,单位为 KB,默认为 4 KB。范围为 1 到 16384,即 1 KB 到 16 MB。
- REPLICA:表示数据库副本数,取值为 1 或 3,默认为 1。在集群中使用,副本数必须小于或等于 DNODE 的数目。
- STT_TRIGGER:表示落盘文件触发文件合并的个数。默认为 1,范围 1 到 16。对于少表高频场景,此参数建议使用默认配置,或较小的值;而对于多表低频场景,此参数建议配置较大的值。
- WAL_LEVEL:WAL 级别,默认为 1。
- 1:写 WAL,但不执行 fsync。
- 2:写 WAL,而且执行 fsync。
- WAL_FSYNC_PERIOD:当 WAL_LEVEL 参数设置为 2 时,用于设置落盘的周期。默认为 3000,单位毫秒。最小为 0,表示每次写入立即落盘;最大为 180000,即三分钟。
- DURATION:数据文件存储数据的时间跨度。可以使用加单位的表示形式,如 DURATION 100h、DURATION 10d 等,支持 m(分钟)、h(小时)和 d(天)三个单位。不加时间单位时默认单位为天,如 DURATION 50 表示 50 天。
- KEEP:表示数据文件保存的天数,缺省值为 3650,取值范围 1, 365000,且必须大于或等于3倍的 DURATION 参数值。数据库会自动删除保存时间超过 KEEP 值的数据。KEEP 可以使用加单位的表示形式,如 KEEP 100h、KEEP 10d 等,支持 m(分钟)、h(小时)和 d(天)三个单位。也可以不写单位,如 KEEP 50,此时默认单位为天。企业版支持多级存储功能, 因此, 可以设置多个保存时间(多个以英文逗号分隔,最多 3 个,满足 keep 0 <= keep 1 <= keep 2,如 KEEP 100h,100d,3650d); 社区版不支持多级存储功能(即使配置了多个保存时间, 也不会生效, KEEP 会取最大的保存时间)。
- COMP:表示数据库文件压缩标志位,缺省值为 2,取值范围为0, 2。
- 0:表示不压缩。
- 1:表示一阶段压缩。
- 2:表示两阶段压缩。
- SINGLE_STABLE:表示此数据库中是否只可以创建一个超级表,用于超级表列非常多的情况。
- 0:表示可以创建多张超级表。
- 1:表示只可以创建一张超级表。
- MAXROWS:文件块中记录的最大条数,默认为 4096 条。
- MINROWS:文件块中记录的最小条数,默认为 100 条。
- TSDB_PAGESIZE:一个 VNODE 中时序数据存储引擎的页大小,单位为 KB,默认为 4 KB。范围为 1 到 16384,即 1 KB到 16 MB。
- WAL_RETENTION_PERIOD: 为了数据订阅消费,需要WAL日志文件额外保留的最大时长策略。WAL日志清理,不受订阅客户端消费状态影响。单位为 s。默认为 3600,表示在 WAL 保留最近 3600 秒的数据,请根据数据订阅的需要修改这个参数为适当值。
- WAL_RETENTION_SIZE:为了数据订阅消费,需要WAL日志文件额外保留的最大累计大小策略。单位为 KB。默认为 0,表示累计大小无上限。
- CACHEMODEL:表示是否在内存中缓存子表的最近数据。默认为 none。
-
响应示例
json{ "code": 1, "data": { "修改数据库参数成功": 0 }, "error": null }
4.删除数据库
-
URL
/dp/createdb/
-
method
delete
-
请求示例
json{ // 可以删除多个 "db_names":["demo04","demo03"] } -
响应示例
json{ "code": 1, "data": { "删除数据库成功": 2 }, "error": null }
2、超级表
1.创建超级表
-
URL
/dp/createstable/
-
method
post
-
请求示例
json{ "db_name": "demo06", // 必填 "stable_name": "st01", // 必填 "fields": { "ts": "TIMESTAMP", // 必填 "current": "FLOAT", // 最低选填一个 "voltage": "INT", "phase": "FLOAT" }, "tags":{ "point":"varchar(100)", // 最低选填一个 "status":"varchar(100)" } } -
响应示例
json{ "code": 1, "data": { "创建超级表成功": "st04" }, "error": null }
2.查询超级表
-
URL
/dp/createstable/
-
method
get
-
请求示例
/dp/createstable/?db_name=demo06&stable_name=st01
参数:db_name 数据库名称,必填
stable_name 超级表名称,非必填
未填超级表名称则查询该数据库下的所有超级表
填写超级表名称则查询该数据库下的超级表的结构信息
-
响应示例
json// 查询该库下的所有超级表 { "code": 1, "data": [ "st01", "st02", "st03", "st04", "demo06" ], "error": null }json// 查询该库下的该超级表的结构信息 { "code": 1, "data": [ { "field": "ts", "type": "TIMESTAMP", "length": 8, "note": "" }, { "field": "current", "type": "FLOAT", "length": 4, "note": "" }, { "field": "voltage", "type": "INT", "length": 4, "note": "" }, { "field": "phase", "type": "FLOAT", "length": 4, "note": "" }, { "field": "point", "type": "VARCHAR", "length": 100, "note": "TAG" }, { "field": "status", "type": "VARCHAR", "length": 100, "note": "TAG" } ], "error": null }
3.修改超级表
-
URL
/dp/createstable/
-
method
put
-
请求示例
json// 添加表注释 { "db_name":"demo06", "stable_name":"st01", "command":"COMMENT", "value": ["This is a table comment."] }json// 添加新列 { "db_name":"demo06", "stable_name":"st01", "command":"ADD COLUMN", "value": ["test","FLOAT"] }json// 删除列 { "db_name":"demo06", "stable_name":"st01", "command":"DROP COLUMN", "value": ["test"] }json// 重命名标签 { "db_name":"demo06", "stable_name":"st01", "command":"RENAME TAG", "value": ["test_tag01","test_tag001"] }- "command":"COMMENT"--添加表注释
- "command":"ADD COLUMN"--添加新列
- "command":"DROP COLUMN"--删除列
- "command":"ADD TAG"--添加标签
- "command":"DROP TAG"--删除标签
- "command":"RENAME TAG"--重命名标签
-
响应信息
json{ "code": 1, "data": { "修改超级表": "修改成功!" }, "error": null }
4.删除超级表
-
URL
/dp/createstable/
-
method
delete
-
请求示例
json// 可删除多个 { "db_name":"demo06", "stable_names":["st06","st05"] } -
响应示例
json{ "code": 1, "data": { "删除超级表成功": 2 }, "error": null }
3、子表
1.创建子表
-
URL
/dp/createtable/
-
method
post
-
请求示例
json// 可以创建多个 { "db_name":"demo06", "stable_name":"st01", "sub_tables":{ "sub01":["办公楼一层101","正常","1"], "sub02":["办公楼二层201","正常","2"] } } -
响应示例
json{ "code": 1, "data": { "创建子表成功": [ "sub03", "sub04" ] }, "error": null }
2.获取子表
-
URL
/dp/createtable/
-
method
get
-
请求示例
/dp/createtable/?db_name=demo06
参数:db_name 数据库名称,必填
sub_table_name 子表名称,非必填
未填子表名称则查询该数据库下的所有子表
填写子表名称则查询该数据库下的子表的结构信息
-
响应示例
json// 获取所有子表 { "code": 1, "data": [ "sub01", "sub02", "sub03", "sub04" ], "error": null }json// 获取子表的结构信息 { "code": 1, "data": [ { "field": "ts", "type": "TIMESTAMP", "length": 8, "note": "" }, { "field": "current", "type": "FLOAT", "length": 4, "note": "" }, { "field": "voltage", "type": "INT", "length": 4, "note": "" }, { "field": "phase", "type": "FLOAT", "length": 4, "note": "" }, { "field": "test", "type": "INT", "length": 4, "note": "" }, { "field": "point", "type": "VARCHAR", "length": 100, "note": "TAG" }, { "field": "status", "type": "VARCHAR", "length": 100, "note": "TAG" }, { "field": "test_tag001", "type": "FLOAT", "length": 4, "note": "TAG" } ], "error": null }
3.修改子表
-
URL
/dp/createtable/
-
method
put
-
请求示例
json// 只能修改子表标签值 { "db_name":"test", "sub_table_name":"meters_sub3", "tag_name": "location", "new_tag_value":"beijing" } -
响应示例
json{ "code": 1, "data": { "修改子表": "修改成功!" }, "error": null }
4.删除子表
-
URL
/dp/createtable/
-
method
delete
-
请求示例
json// 可以同时删除多个表 { "db_name":"test", "sub_table_names":["meters_sub7","meters_sub6"] } -
响应示例
json{ "code": 1, "data": { "删除子表成功": 2 }, "error": null }
4、向子表插入数据
1.插入数据
-
URL
/dp/insertdata/
-
method
post
-
请求示例
json// 可以向多个子表根据字段插入多条记录 { "db_name":"test", "table_data": { "d001":{ "fields": ["ts", "current", "voltage", "phase"], "values": [ ["2021-07-13 14:06:34.630", 10.2, 219, 0.32], ["2021-07-13 14:06:35.779", 10.15, 217, 0.33] ] }, "d1002": { "fields": ["ts", "current", "phase"], "values": [ ["2021-07-13 14:06:34.255", 10.27, 0.31] ] } } } -
响应示例
json{ "code": 1, "data": { "插入数据成功": "INSERT INTO d1001 (ts, current, voltage, phase) VALUES ('2021-07-13 14:06:34.630', '10.2', '219', '0.32') ('2021-07-13 14:06:35.779', '10.15', '217', '0.33') d1002 (ts, current, phase) VALUES ('2021-07-13 14:06:34.255', '10.27', '0.31') " }, "error": null }
2.修改数据
-
URL
/dp/insertdata/
-
method
put
-
请求示例
json// 根据时间戳修改数据 { "db_name":"test", "sub_table_name":"d1001", "ts_name":"ts", "ts_value":"2021-07-13 00:00:00.000", "fields":["current","voltage"], "value":["11","2"] } -
响应示例
json{ "code": 1, "data": { "修改数据成功": "INSERT INTO d1001 (ts,current, voltage) VALUES ('2021-07-13 00:00:00.000','11', '2')" }, "error": null }
3.删除数据
-
URL
/dp/insertdata/
-
method
delete
-
请求示例
json// 删除时间戳等于2021-07-13 00:00:00.000的数据 { "db_name":"test", "sub_table_name":"d1001", "ts_name":"ts", "ts_value":"2021-07-13 00:00:00.000", "operation":"EN" }- "operation":"GT" -- 大于(Greater Than)
- "operation":"GE" -- 大于等于(Greater Than or Equal)
- "operation":"LT" -- 小于(Less Than)
- "operation":"LE" -- 小于等于(Less Than or Equal)
- "operation":"EQ" -- 等于(Equal)
- "operation":"NE" -- 不等于(Not Equal)
-
响应示例
json{ "code": 1, "data": { "删除数据成功": "DELETE FROM d1001 WHERE ts = '2021-07-13 00:00:00.000'" }, "error": null }
二、EMQX断线重连
1、实现流程
- 设置客户端配置 :
- 配置持久化会话 (
clean_session=False,并配置唯一ID)。 - 设置重连策略,包括最大重试次数和重连间隔时间。
- 配置持久化会话 (
- 检测连接状态 :
- 在连接断开的回调函数中,记录断开的原因,并尝试重连。
- 重连处理 :
- 使用退避算法进行重连,并在重连成功后重新订阅主题。
2、断线重连逻辑
客户端断开连接后,自动调用on_disconnect方法,更改连接状态,尝试连接(调用reconnect重连方法)。
重连设置最大连接次数,以及使用退避算法,防止短时间内多次重连。
python
def on_disconnect(self, client, userdata, rc):
self.is_connected = False
if rc != 0:
print("客户端断开。尝试重新连接...")
self.reconnect()
def reconnect(self):
while not self.is_connected and self.reconnect_attempts < self.max_reconnect_attempts:
try:
wait_time = min(2 ** self.reconnect_attempts, 60) + random.uniform(0, 1)
print(f"尝试重新连接 {self.reconnect_attempts + 1}, 等待 {wait_time:.2f} 秒...")
time.sleep(wait_time)
self.client.reconnect() # 使用 reconnect 方法重新连接
self.is_connected = True # 如果成功连接,设置 is_connected 为 True
except Exception as e:
print(f"重连失败: {e}")
self.reconnect_attempts += 1
if self.reconnect_attempts >= self.max_reconnect_attempts:
print("已达到最大重新连接尝试次数,进入睡眠模式。")
# 在这里可以添加进入休眠模式的逻辑3、整体断线重连demo代码
python
import time
import random
import paho.mqtt.client as mqtt
# MQTT Broker 配置
BROKER_ADDRESS = "192.168.101.130" # 服务端
BROKER_PORT = 1883 # 端口
KEEP_ALIVE_INTERVAL = 60 # 保活时间(秒)
TOPIC = "test/topic" # 主题
MAX_RECONNECT_ATTEMPTS = 10 # 最大重连尝试次数
CLIENT_ID = "test_client_id" # client_id
USERNAME = 'test' # 用户名
PASSWORD = 'test' # 密码
QOS = 1
i = 1
class MQTTClient:
def __init__(self, broker_address, broker_port, topic, keep_alive=60, max_reconnect_attempts=10):
self.broker_address = broker_address
self.broker_port = broker_port
self.topic = topic
self.keep_alive = keep_alive
self.max_reconnect_attempts = max_reconnect_attempts
self.reconnect_attempts = 0
self.is_connected = False
# 创建 MQTT 客户端并启用持久会话
self.client = mqtt.Client(clean_session=False, client_id=CLIENT_ID)
# 设置用户名密码
self.client.username_pw_set(USERNAME, PASSWORD)
# 设置回调函数
self.client.on_connect = self.on_connect
self.client.on_message = self.on_message
self.client.on_disconnect = self.on_disconnect
def on_connect(self, client, userdata, flags, rc):
if rc == 0:
print("连接到 broker ")
self.is_connected = True
self.reconnect_attempts = 0
self.client.subscribe(self.topic, qos=QOS) # 重新订阅主题
else:
print(f"连接失败并返回代码 {rc}")
def on_message(self, client, userdata, msg):
print(f"在主题 '{msg.topic}' 收到的消息为: '{msg.payload.decode()}'")
def on_disconnect(self, client, userdata, rc):
self.is_connected = False
if rc != 0:
print("客户端断开。尝试重新连接...")
self.reconnect()
def reconnect(self):
while not self.is_connected and self.reconnect_attempts < self.max_reconnect_attempts:
try:
wait_time = min(2 ** self.reconnect_attempts, 60) + random.uniform(0, 1)
print(f"尝试重新连接 {self.reconnect_attempts + 1}, 等待 {wait_time:.2f} 秒...")
time.sleep(wait_time)
self.client.reconnect() # 使用 reconnect 方法重新连接
self.is_connected = True # 如果成功连接,设置 is_connected 为 True
except Exception as e:
print(f"重连失败: {e}")
self.reconnect_attempts += 1
if self.reconnect_attempts >= self.max_reconnect_attempts:
print("已达到最大重新连接尝试次数,进入睡眠模式。")
# 在这里可以添加进入休眠模式的逻辑
def start(self):
# 初始连接
try:
self.client.connect(self.broker_address, self.broker_port, self.keep_alive)
except Exception as e:
print(f"初始连接失败: {e} 。尝试重新连接...")
self.reconnect()
# 启动 MQTT 客户端的循环
self.client.loop_start()
def stop(self):
# 停止 MQTT 客户端的循环并断开连接
self.client.loop_stop()
self.client.disconnect()
def publish(self, message):
if self.is_connected:
self.client.publish(self.topic, message, qos=QOS)
if __name__ == "__main__":
# 创建并启动 MQTT 客户端
mqtt_client = MQTTClient(BROKER_ADDRESS, BROKER_PORT, TOPIC, KEEP_ALIVE_INTERVAL, MAX_RECONNECT_ATTEMPTS)
mqtt_client.start()
try:
while True:
message = f"Hello MQTT {i}"
mqtt_client.publish(message)
i = i + 1
time.sleep(1)
except KeyboardInterrupt:
print("Exiting...")
mqtt_client.stop()三、查看所有的mqtt topic
认证需要API秘钥
API接口:
http://192.168.101.130:18083/api/v5/topics代码:
python
import urllib.request
import json
import base64
username = 'ee26b0dd4af7e749'
password = 'ALsVuG69AjvFVVU1DoUKC3w0CeP1Nuajrd9CyI3brlCyN'
# url = 'http://192.168.101.130:18083/api/v5/nodes'
url = "http://192.168.101.130:18083/api/v5/topics"
req = urllib.request.Request(url)
req.add_header('Content-Type', 'application/json')
auth_header = "Basic " + base64.b64encode((username + ":" + password).encode()).decode()
req.add_header('Authorization', auth_header)
with urllib.request.urlopen(req) as response:
data = json.loads(response.read().decode())
print(data)输出结果:
{'data': [{'node': 'emqx@127.0.0.1', 'topic': 't/1'}, {'node': 'emqx@127.0.0.1', 'topic': '$share/c/t/1'}, {'node': 'emqx@127.0.0.1', 'topic': '$share/a/t/1'}, {'node': 'emqx@127.0.0.1', 'topic': '$share/b/t/1'}], 'meta': {'count': 4, 'limit': 100, 'page': 1, 'hasnext': False}}四、EMQX 到 Tdengine 数据导入性能测试报告**
测试环境:
-
EMQX 版本:5.5.0 (单体)
-
Tdengine 版本:3.2.2.0 (单体)
-
操作系统:centos7
-
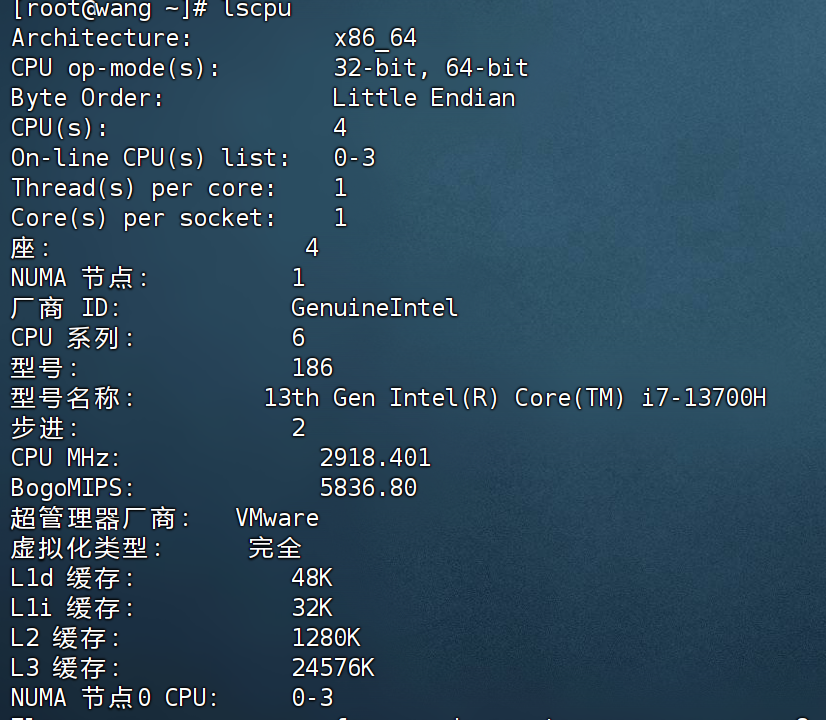
CPU:4核
-
内存:3G
测试步骤:
- 在 EMQX 中配置数据源或者编写程序连接TDengine,确保实时数据可以被发送到指定的 Tdengine 数据库中。
- 在 Tdengine 数据库中创建相应的表结构,确保能够正确接收和存储实时数据。
- 启动数据导入功能,让 EMQX 将实时数据发送到 Tdengine 数据库中。
- 使用监控工具监视系统的 CPU 利用率、内存使用情况以及数据导入速率。
测试一:EMQX直接存储到TDengine
使用EMQX订阅EMQX中的Topic,存入到TDengine中
场景一:单线程发布消息
- 一个客户端发送数据
- 每10毫秒发送一次
- 测试发送一万条数据
- 用时0:01:47.116768
测试结果
-
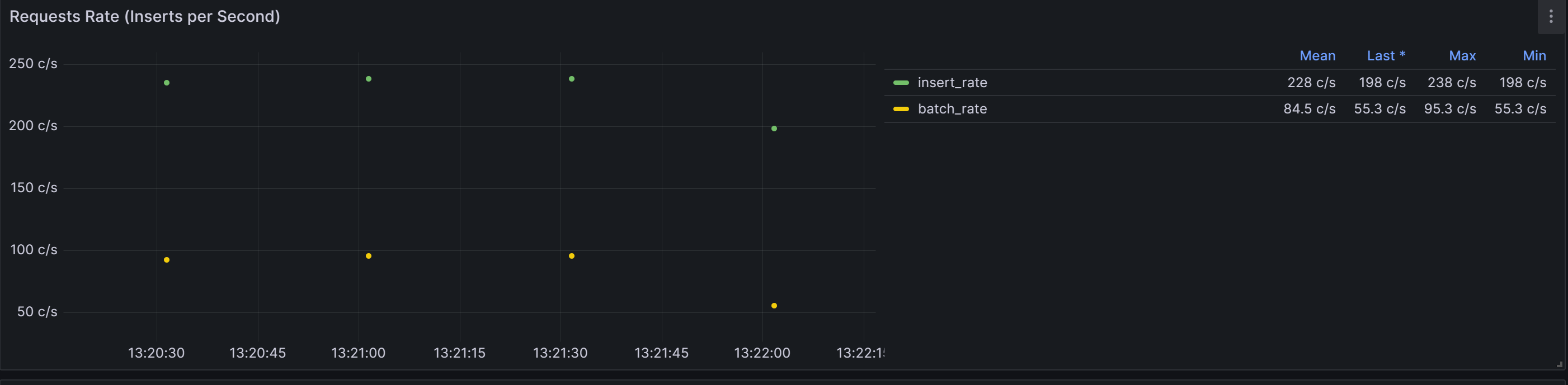
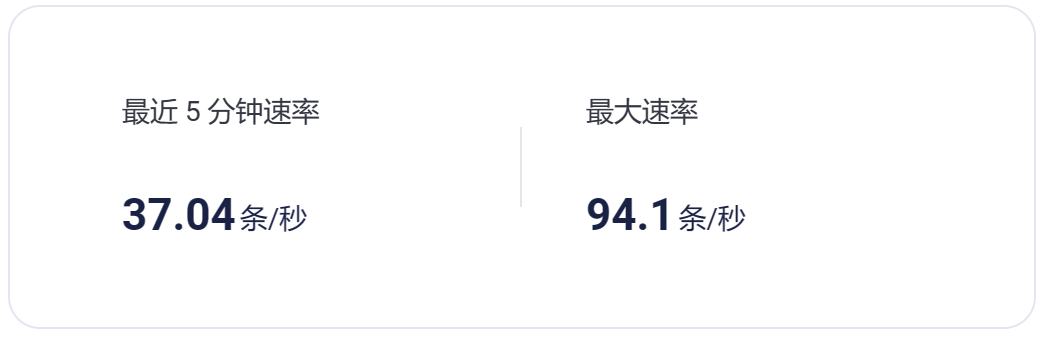
数据导入TDengine速率:
平均每秒处理84.5条数据。
最大处理95.3条数据
最小处理55.3条数据
-
EMQX CPU利用率、 内存使用情况:
CPU利用率最高26.3%,最低13.2%
内存使用平均1.66GB
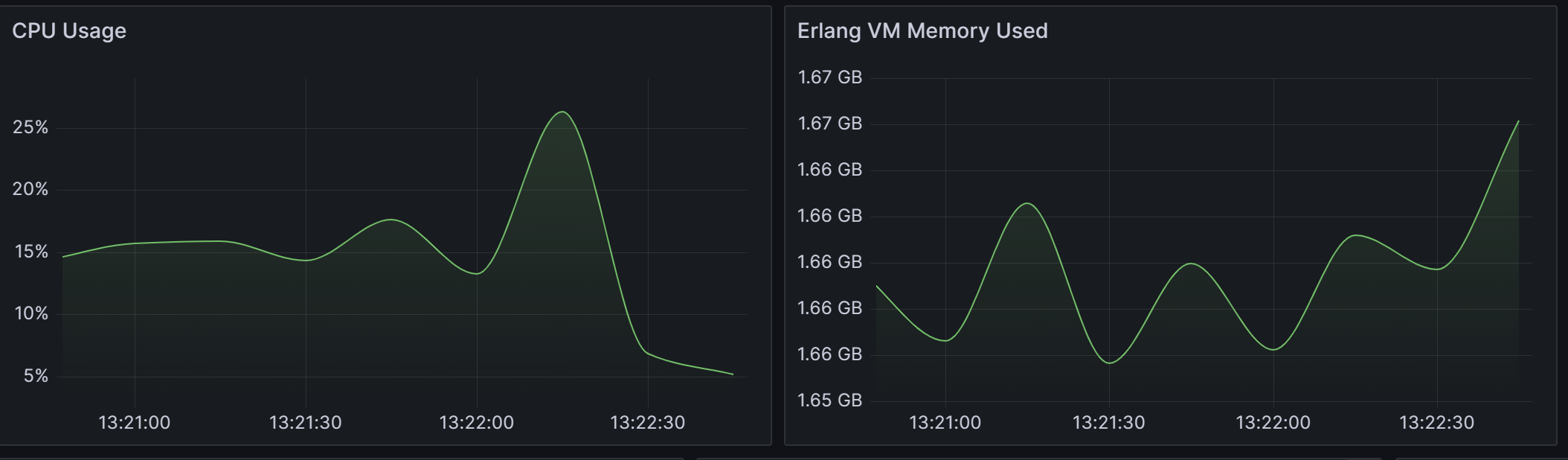
-
Tdengine CPU利用率、 内存使用情况:
CPU利用率最高7.67%,最低1.83%
内存平均668MB
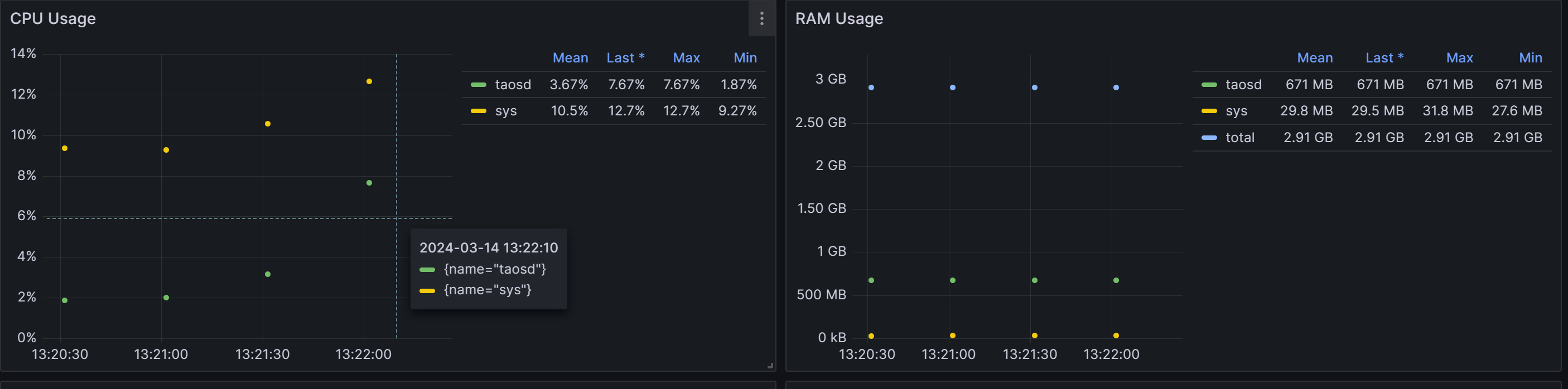
-
机器信息:
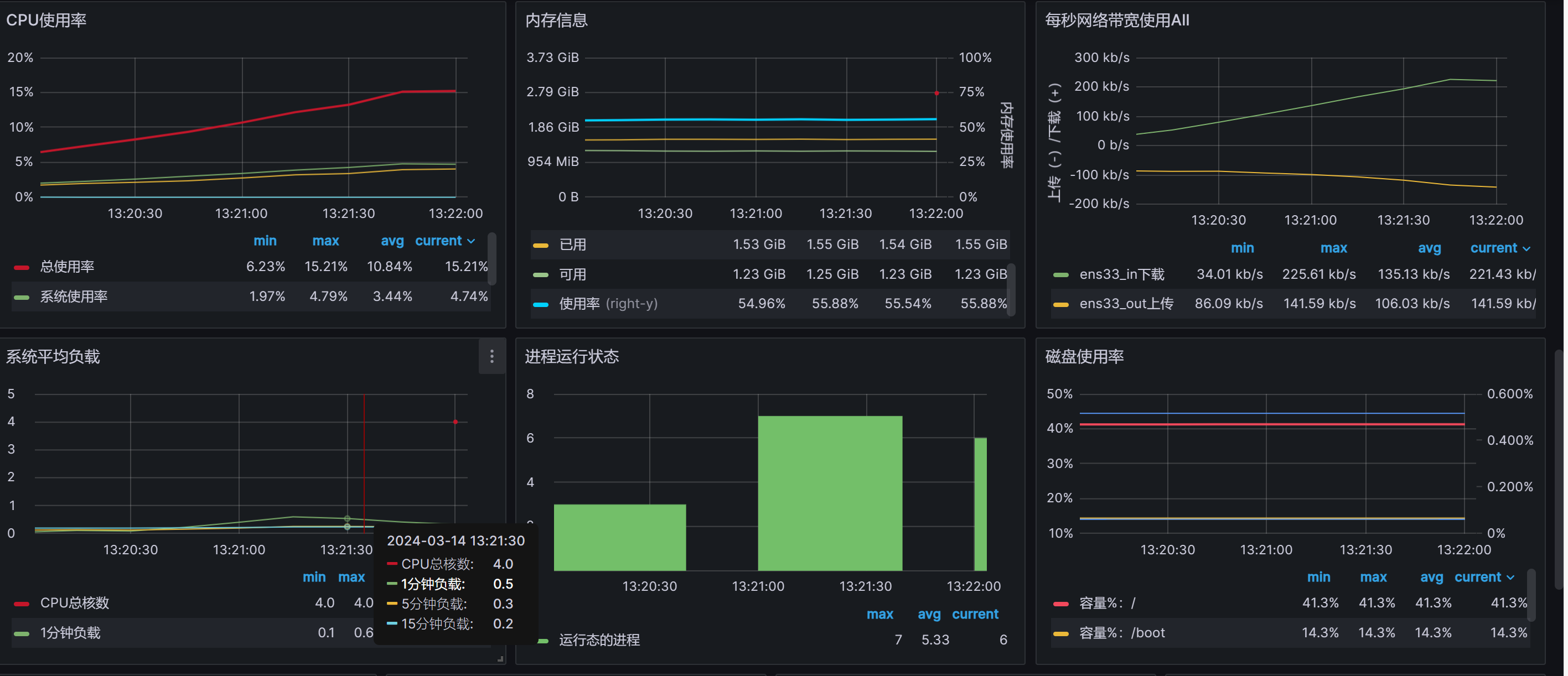
场景二:多线程发布消息
- 五个客户端发送数据
- 每10毫秒发送一次
- 测试发送五万条数据
- 用时0:01:49.660773
测试结果
-
数据导入TDengine速率:
平均每秒处理 360条数据。
最大处理460条数据
最小处理68.5条数据
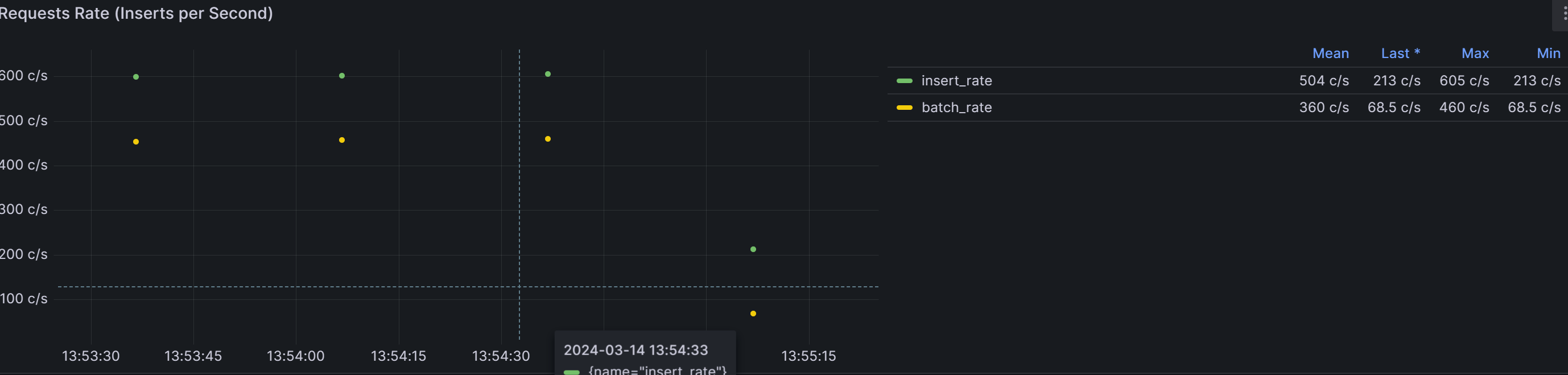
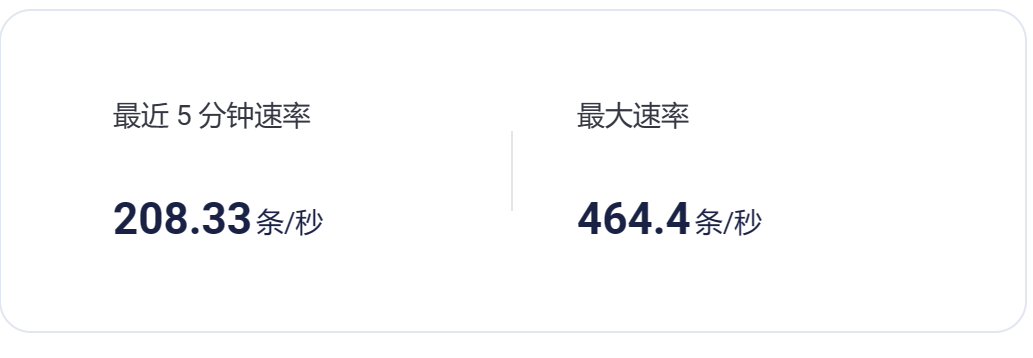
-
EMQX CPU利用率、 内存使用情况:
cpu最高百分之四十,最低百分之十
内存平均1.32G
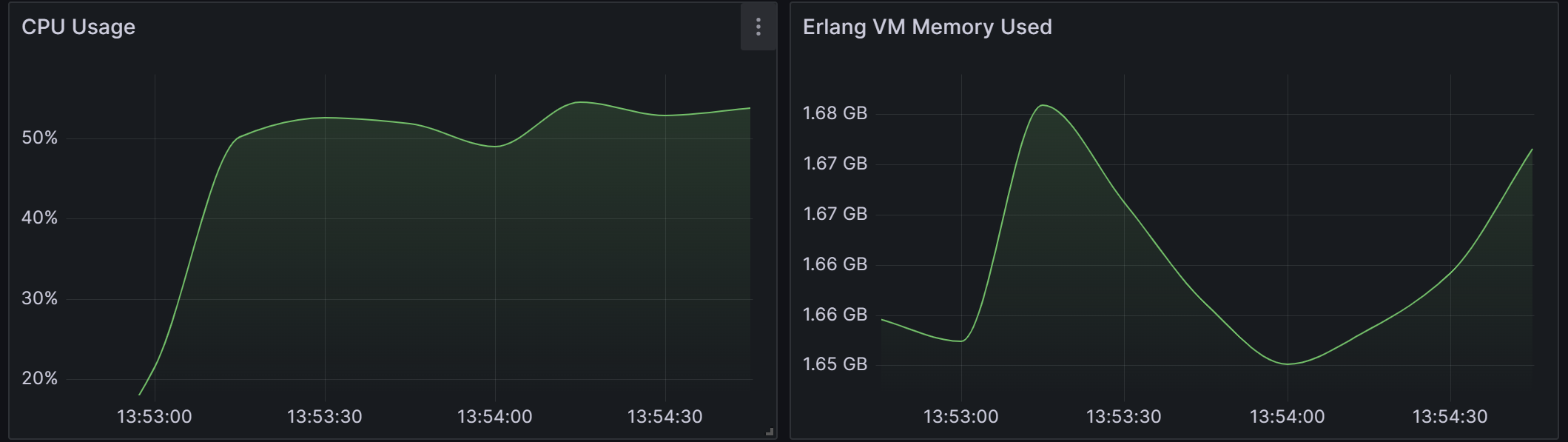
-
Tdengine CPU利用率、 内存使用情况:
cpu最高百分之十二
内存平均334M
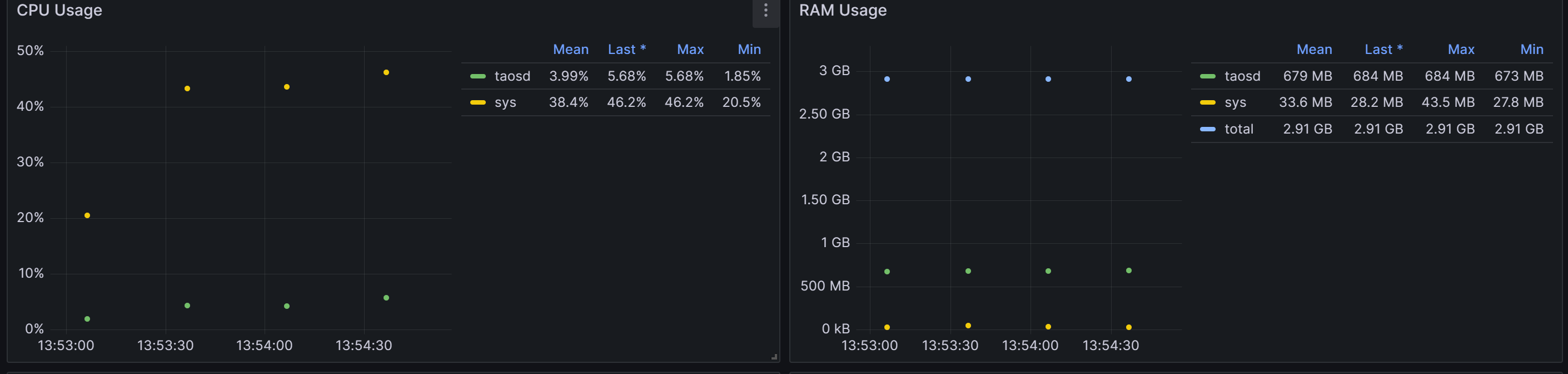
-
机器信息:
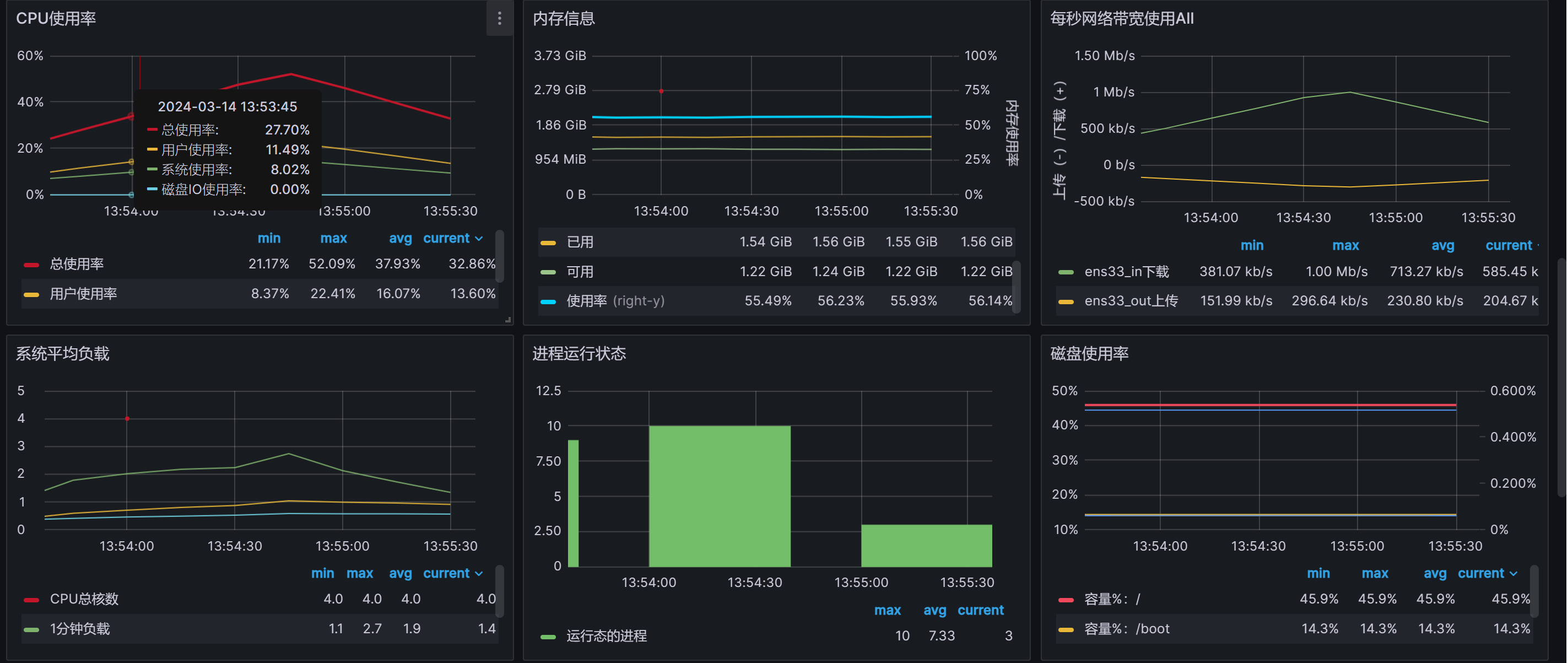
测试二:Python订阅消息存储到TDengine
通过Python程序订阅EMQX中的Topic,存入到TDengine中
场景一:单线程发布消息
- 一个客户端发送数据
- 每10毫秒发送一次
- 测试发送一万条数据
- 用时0:01:48.202740
测试结果:
-
数据导入TDengine速率:
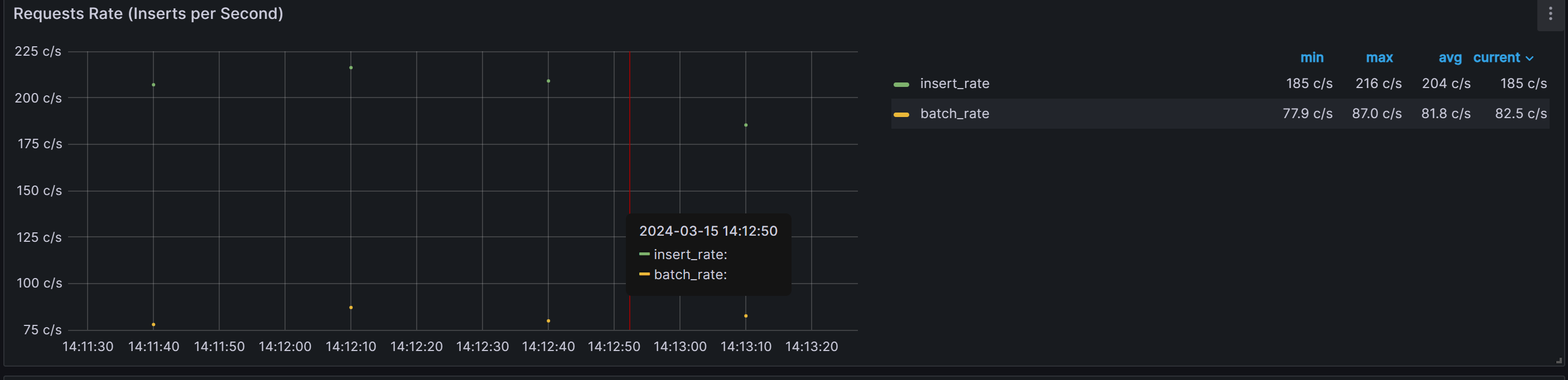
平均每秒处理 81.8条数据。
最大处理87.0条数据
最小处理77.9条数据
-
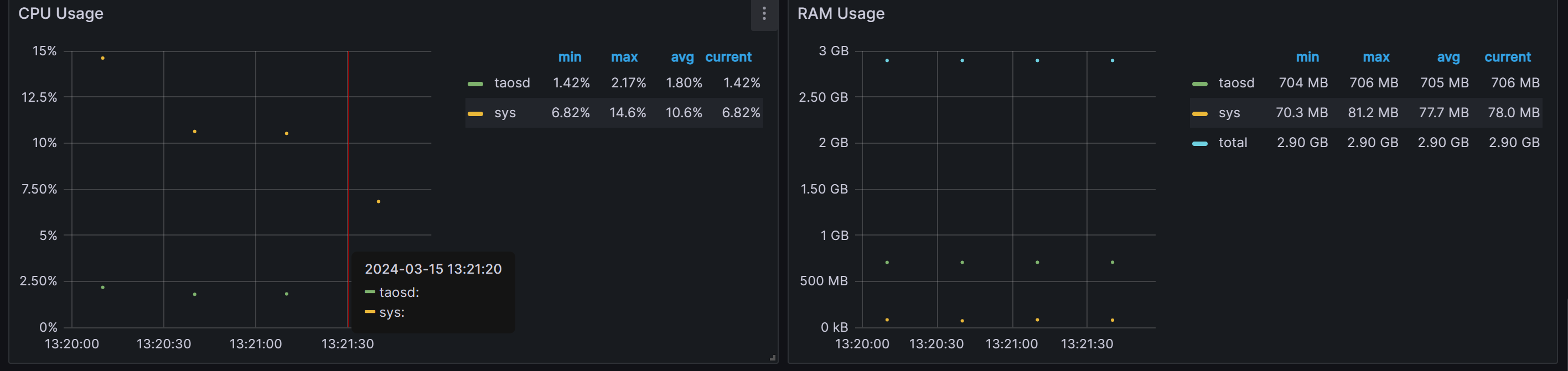
Tdengine CPU利用率、 内存使用情况:
cpu最高利用率2.17%,平均1.8%
内存平均M
-
机器信息:
场景二:多线程发布消息
- 五个客户端发送数据
- 每50毫秒发送一次
- 测试发送五万条数据
- 用时0:01:47.998246
测试结果
-
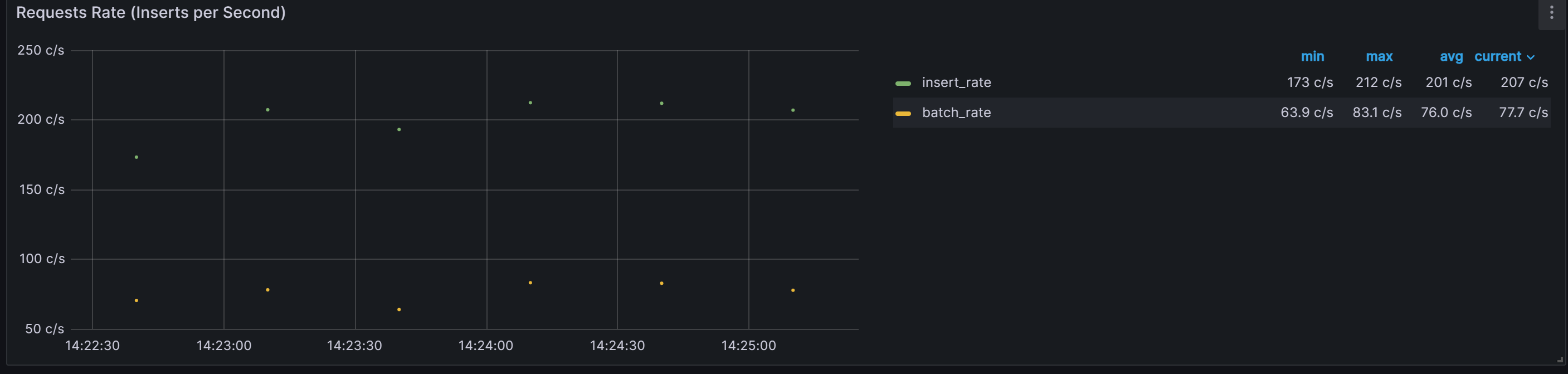
数据导入TDengine速率:
平均每秒处理76条数据。
最大处理83.1条数据
最小处理63.9条数据
-
Tdengine CPU利用率、 内存使用情况:
cpu最高利用率1.3%,平均1.14%
内存平均643M
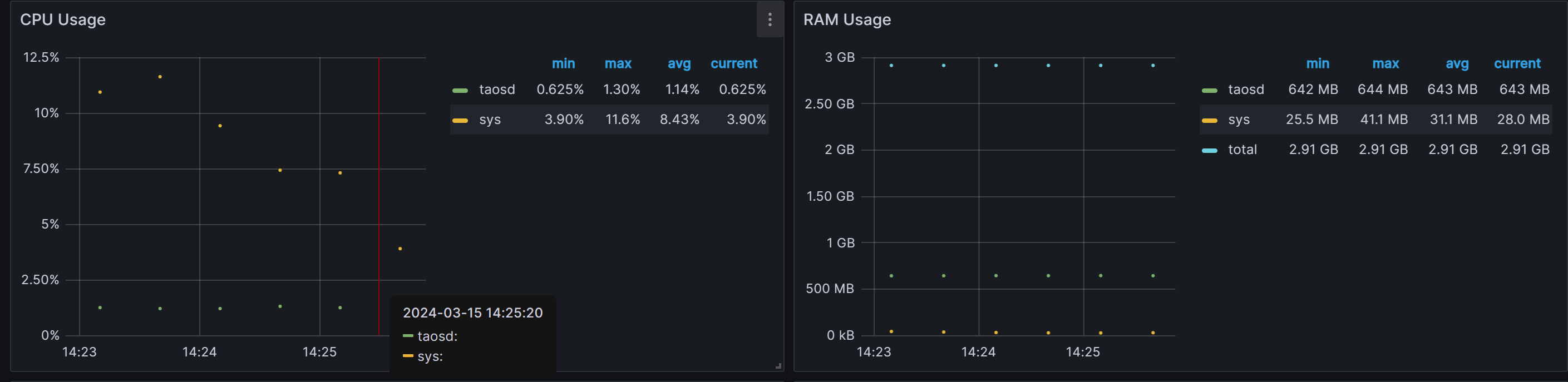
-
机器信息:
测试三:Java订阅消息存储到TDengine
场景一:单线程发布消息
- 一个客户端发送数据
- 每10毫秒发送一次
- 测试发送一万条数据
- 用时0:01:46.728102
测试结果
-
数据导入TDengine速率:
平均每秒处理 79.9条数据。
最大处理95.5条数据
最小处理41.8条数据
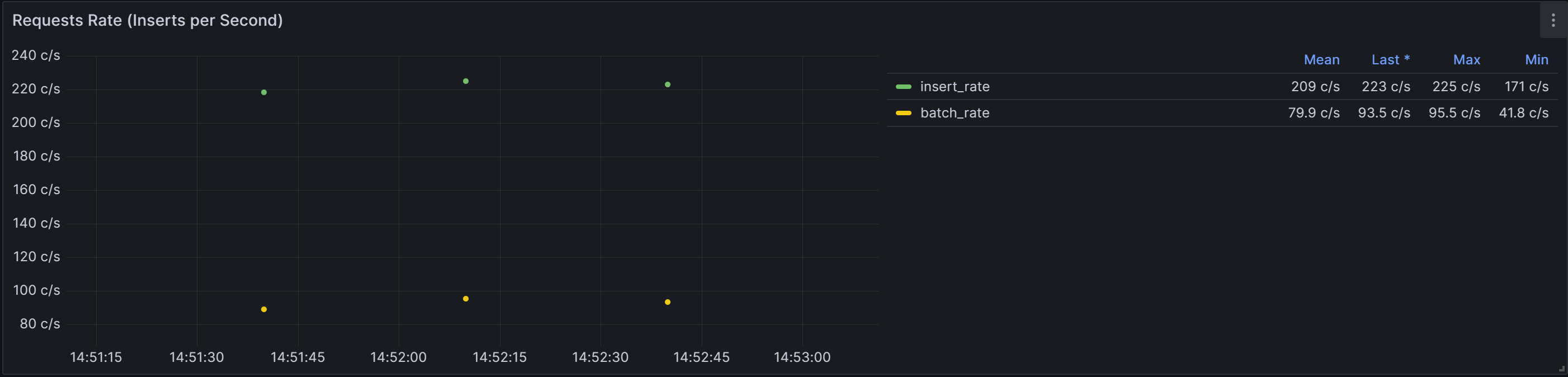
-
Tdengine CPU利用率、 内存使用情况:
cpu最高利用率3.50%,平均2.14%
内存平均646M
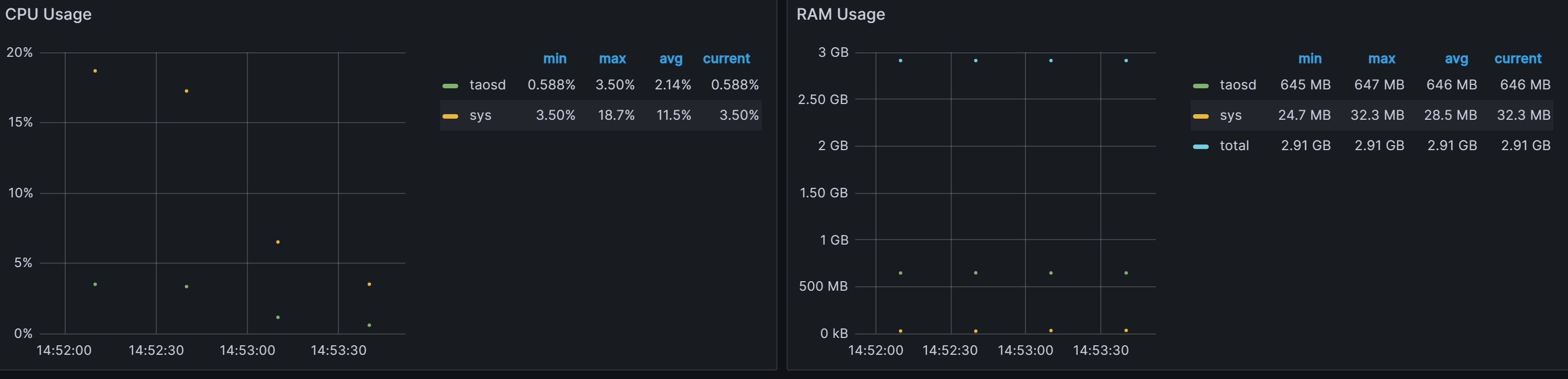
-
机器信息:
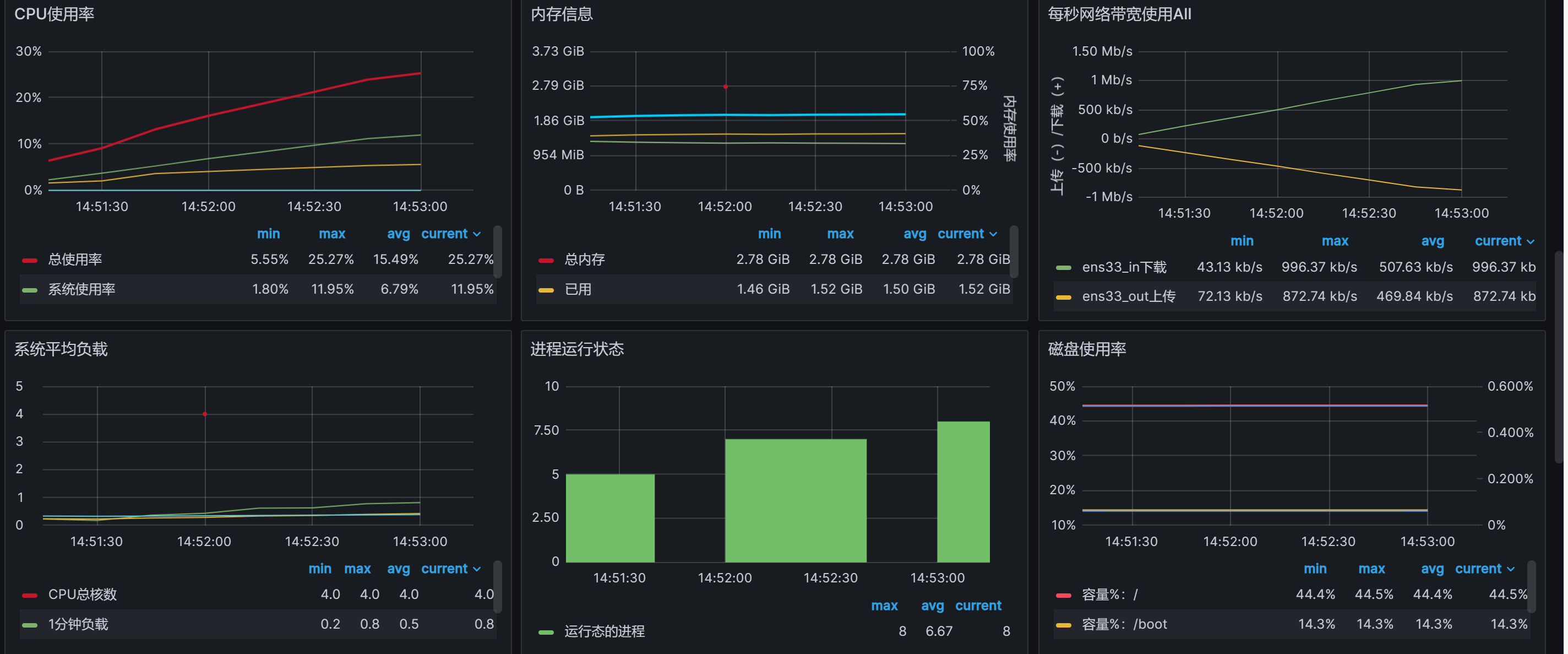
场景二:多线程发布消息
- 五个客户端发送数据
- 每10毫秒发送一次
- 测试发送五万条数据
- 用时0:01:46.728102
测试结果
-
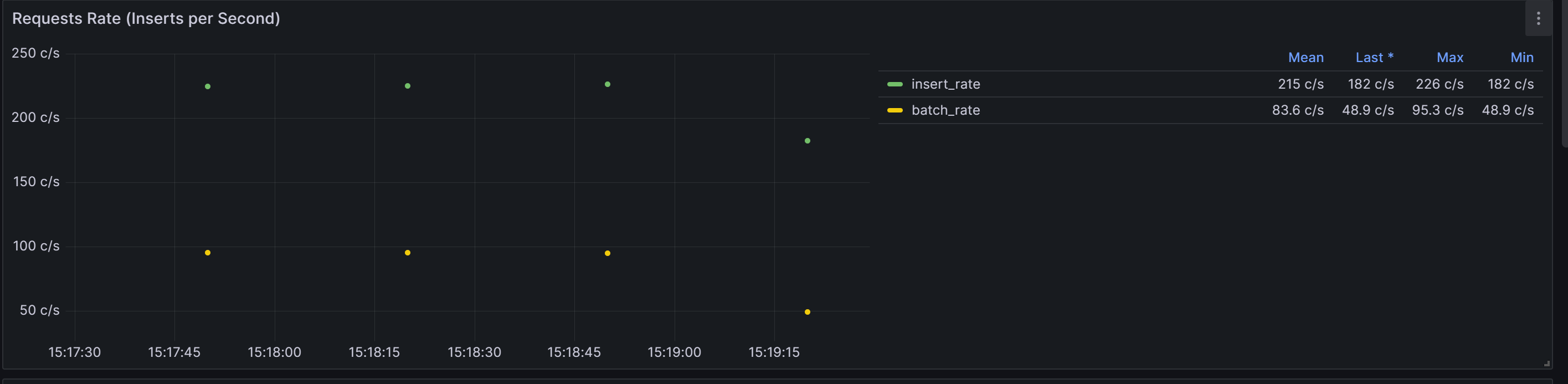
数据导入TDengine速率:
平均每秒处理 83.6条数据。
最大处理95.3条数据
最小处理48.9条数据
-
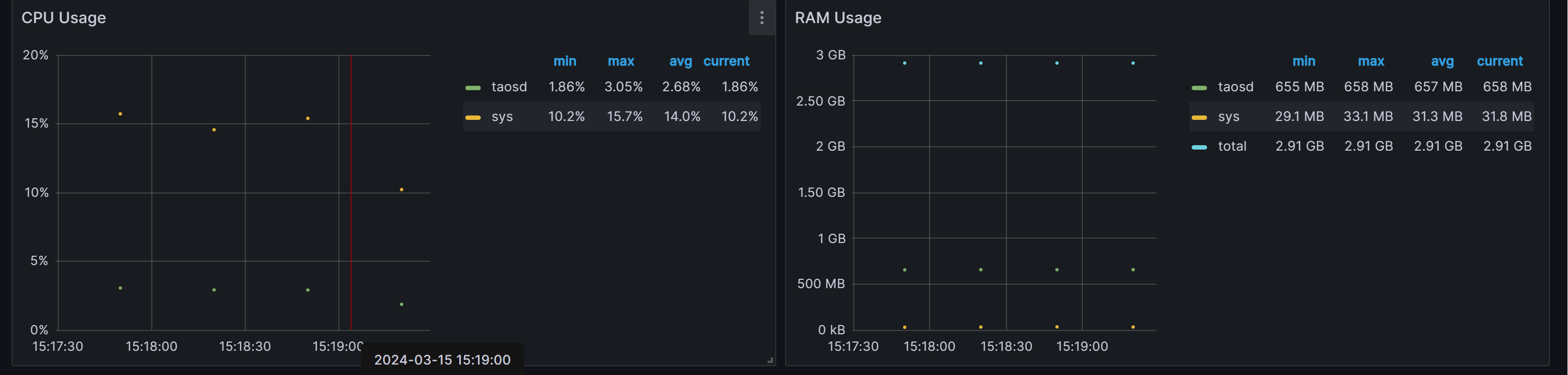
Tdengine CPU利用率、 内存使用情况:
cpu最高利用率3.05%,平均1.86%
内存平均657M
-
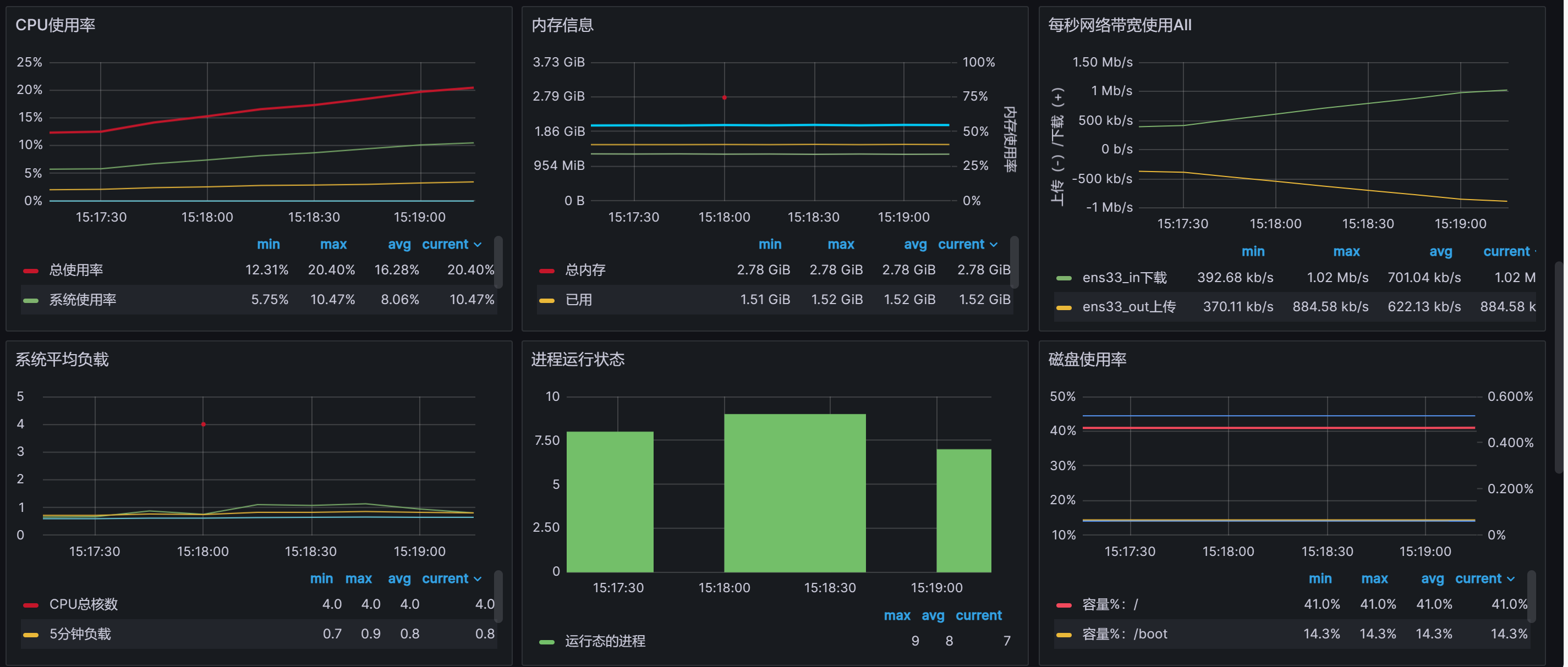
机器信息:
测试四:Go订阅消息存储到TDengine
场景一:单线程发布消息
- 一个客户端发送数据
- 每10毫秒发送一次
- 测试发送一万条数据
- 用时0:01:48.395355
测试结果
-
数据导入TDengine速率:
平均每秒处理 82.6条数据。
最大处理95.0条数据
最小处理50.2条数据
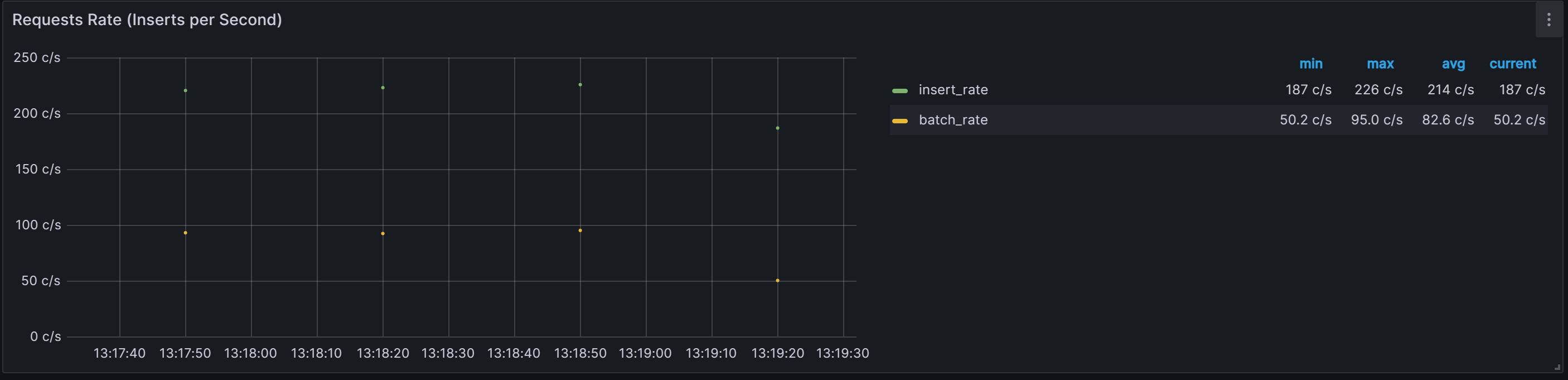
-
Tdengine CPU利用率、 内存使用情况:
cpu最高利用率12%,平均4.35%
内存平均399M
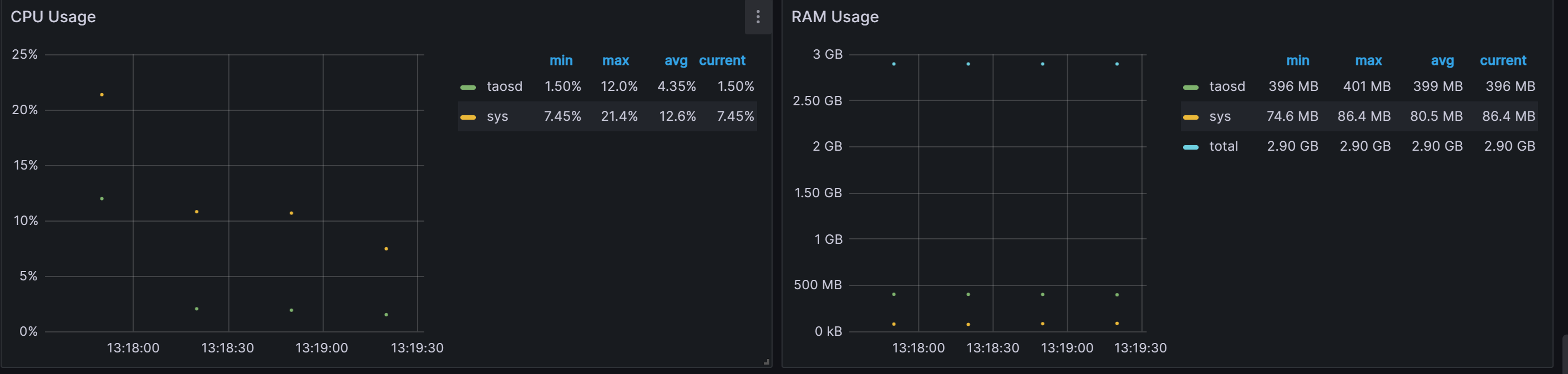
-
机器信息:
场景二:多线程发布消息
- 五个客户端发送数据
- 每10毫秒发送一次
- 测试发送五万条数据
- 用时0:01:46.728102
测试结果
-
数据导入TDengine速率:
平均每秒处理 237条数据。
最大处理239条数据
最小处理235条数据
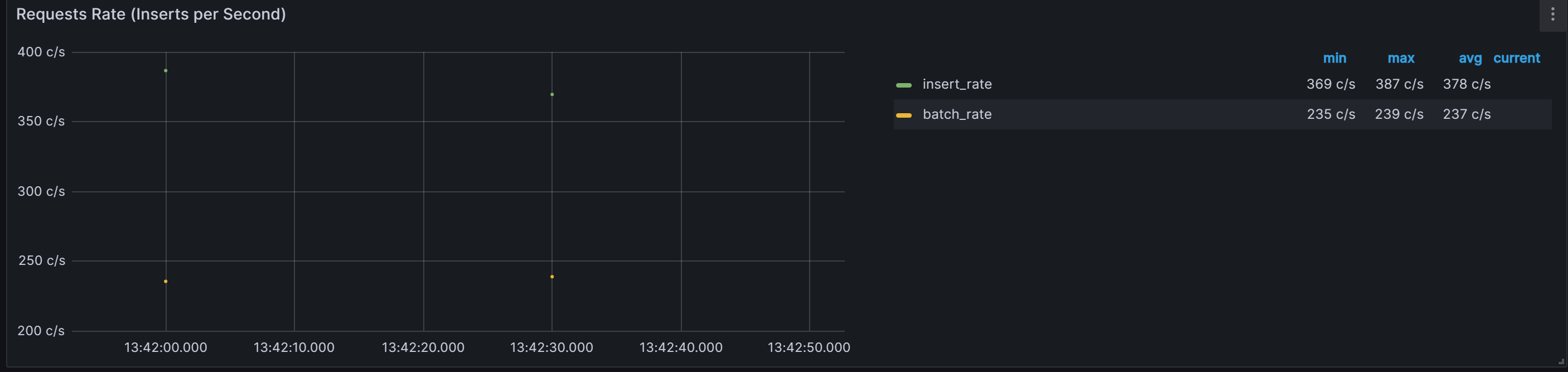
-
Tdengine CPU利用率、 内存使用情况:
cpu最高利用率3.43%,平均2.62%
内存平均423M
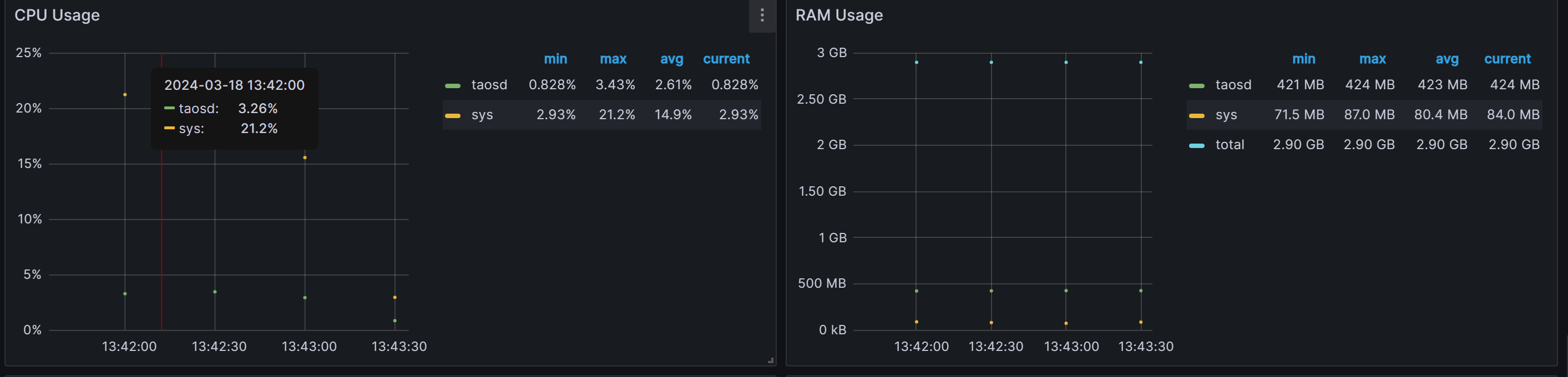
-
机器信息:
结果:
| emqx直接连接TDengine | python订阅消息存储到TDengine | Java订阅消息存储到TDengine | go订阅消息存储到TDengine | |
|---|---|---|---|---|
| 单线程发布消息 | 平均每秒84.5条,最大95.3条 | 平均每秒81.8条,最大87条 | 平均每秒79.9条,最大95.5条 | 平均每秒86.2条,最大95.0条 |
| 多线程发布消息 | 平均每秒 360条,最大460条 | 平均每秒76条,最大83.1条 | 平均每秒83.6条,最大95.3条 | 平均每秒237条,最大239条 |
结论:
存储到TDengine速率:emqx>go>java>python