最近由于cusror的运营策略反复横跳,翻脸比翻书还快,付费用户的请求次数从原来的unlimited变成了三四百次claude请求以后,汪凝我真的生气了!现在考虑用claude code,但是claude code价钱有点点高,在降低价钱且稍微降低体验要求的情况下,先尝试能不能用trae作为平替。
试用过程中发现同样是claude模型,trae的输出有很多废话,然后答案也有些不那么精准,表现就跟实际对接的是ds一样 ------------------ 你能不能别那么多废话呀~
text
我需要了解xxxx,先查看项目中xxxx相关文件来获取信息。
我需要继续查看xxx的剩余部分,以及查看其他相关的xxx文件,以便全面了xxx。
现在我需要查看xxx和xxx文件,以了解更多关于xxx细节。
我需要继续查看xxx的剩余部分,以及xxx文件,以全面了解xxx的实现方式。
.......
.......
.......
等待中...
.......
30 minutes later...
.......
模型响应失败,请重新尝试
拜托,我又没有通过 # 去引用文件,你罗里吧嗦那么一大堆干什么呢,对字节来说不是浪费资源吗,对我来说不是浪费时间吗,还浪费我的ask空间。
于是我找到了这样一个方法,在这里添加规则,输入一些你给它的要求,比如我就用了一些通用的规则:
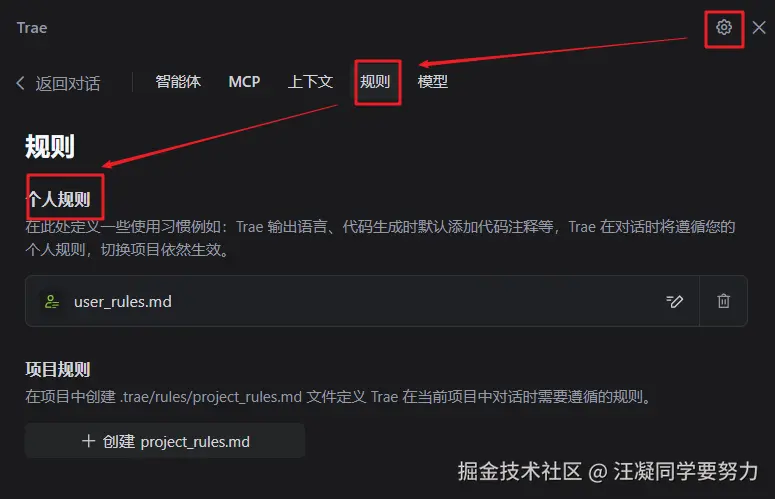
text
# Cursor项目规范
## 基本设置
- 使用中文回答所有问题
- 按照Sequential Thinking方法进行代码设计和实现
- 我没有手动指定需要引用的文件时,不要去读取我项目中的文件,直接回答我的问题
- 当且仅当我引用了文件时,你才去读取我引用的这些文件
## 项目结构和命名规范
- 组件命名:PascalCase
- 函数命名:camelCase
- 常量命名:UPPER_CASE
- 文件夹结构遵循:/src/components, /src/services, /src/utils, /docs
- 接口命名:使用I前缀,如IUserService
- 类型定义:使用T前缀,如TUserData
## 代码风格
- 使用TypeScript类型定义
- 统一代码缩进和格式
- 使用ESLint和Prettier规则
## 开发流程规则
1. 问题分析:明确任务目标和约束条件
2. 设计方案:设计数据结构和算法
3. 实现步骤:自顶向下实现功能
4. 测试验证:编写单元测试和集成测试
## 代码审查标准
- 代码必须符合既定规范
- 关键函数和组件必须有注释
- 复杂算法需要解释思路
## 提交规范
- 遵循语义化提交信息格式:feat:, fix:, docs:等
- 主分支只接受经过测试的代码
## 文档要求
- API接口必须有清晰文档
- 更新README文件反映最新项目状态
## 代码稳定性保障
- 修改已完成功能前必须先理解其完整设计意图
- 所有API更改必须向下兼容
- 使用单元测试保护核心功能逻辑
- 重构代码时必须保持功能等价性
- 在修改前创建功能快照或临时分支
- 每次更改后必须验证不破坏现有功能
- 使用TODO或FIXME标签清晰标记未完成修改
## 版本控制规则
- 使用语义化版本管理
- 关键功能更改必须通过代码审查
- 维护变更日志记录所有修改
- 为已稳定功能模块添加"锁定注释"标记:/* @stable - 请勿修改 */
## UI设计规范
- 遵循现代设计趋势和最佳实践
- 使用设计系统确保一致性(如Material Design、Ant Design或自定义设计系统)
- 实现响应式设计,确保在不同设备上显示良好
- 使用CSS变量统一管理颜色、字体、间距等设计标记
- 优先采用Flexbox或Grid布局系统
- 确保适当的留白和视觉层次
- 实现无障碍访问标准(WCAG 2.1)
## UI组件标准
- 使用组件库作为基础(如MUI、Chakra UI、Tailwind UI等)
- 自定义组件需符合现代设计审美
- 设计组件应包含默认、悬停、聚焦、禁用等状态
- 使用适当的动画和过渡效果增强用户体验
- 确保设计一致性:同类元素使用相同样式
- 使用主题系统支持亮色/暗色模式切换
- 根据用户操作提供视觉反馈
## 设计资源
- 维护设计风格指南和UI组件库
- 使用标准化图标库(如Heroicons、Material Icons等)
- 图片和插图需保持一致的风格
- 颜色选择须符合品牌标识并确保足够对比度
## 依赖管理规范
- 优先使用国内镜像站点安装依赖
- npm包使用淘宝镜像:https://registry.npmmirror.com/
- yarn设置:yarn config set registry https://registry.npmmirror.com
- pnpm设置:pnpm config set registry https://registry.npmmirror.com
- pip包使用清华镜像:https://pypi.tuna.tsinghua.edu.cn/simple
- Docker镜像使用阿里云:https://cr.console.aliyun.com/
- Maven依赖使用阿里云:https://maven.aliyun.com/repository/public
- Gradle依赖使用阿里云:https://developer.aliyun.com/mvn/guide
- 安装新依赖前先验证其在国内是否可访问
- 如确实需使用国外资源,应提供备选方案或离线安装包
- package.json中添加镜像设置脚本便于团队统一配置
- 记录所有依赖的具体版本和来源以便追踪
## 测试自动化规范
- 编写单元测试覆盖所有关键功能
- 实现端到端测试验证用户流程
- 使用测试驱动开发(TDD)方法
- 每次提交前运行自动化测试
- 维护测试数据与生产环境隔离
## 调试与日志规范
- 统一使用日志级别(error, warn, info, debug)
- 日志信息需包含上下文和时间戳
- 生产环境禁用调试代码和console语句
- 关键流程增加日志记录点便于问题追踪
- 使用结构化日志格式便于分析
## 代码复杂度控制
- 函数不超过50行,单个文件不超过300行
- 每个函数只做一件事情,保持单一职责
- 嵌套不超过3层,避免过深条件嵌套
- 控制圈复杂度不超过10
- 复杂逻辑应拆分为多个小函数
## 状态管理规范
- 明确状态管理方案(如Redux、MobX或Context API)
- 区分本地状态和全局状态
- 避免状态冗余和重复存储
- 实现不可变状态更新模式
- 为复杂状态提供初始值和验证机制
## 异步操作规范
- 统一使用async/await或Promise
- 实现请求超时和重试机制
- 处理并发请求限制
- 取消不必要的请求以节省资源
- 使用Loading状态指示异步操作进行中
## 代码重用策略
- 提取通用逻辑为Hooks或工具函数
- 使用组合而非继承实现代码复用
- 避免复制粘贴代码,而应重构为共享组件
- 通用功能应考虑发布为内部npm包
- 明确区分业务逻辑和技术实现
## 项目文档体系
- 维护项目架构图和关键流程图
- 记录技术选型理由和限制条件
- 为API和数据模型提供详细文档
- 记录已知问题和解决方案
- 提供新开发者入门指南
## 构建与发布流程
- 使用CI/CD实现自动化构建和部署
- 区分开发、测试、预发布和生产环境
- 实现回滚机制应对紧急问题
- 使用版本化静态资源避免缓存问题
- 配置文件应随环境变化而不需修改代码
## 可访问性和兼容性规范
- 确保键盘可访问性
- 使用ARIA标签增强屏幕阅读器支持
- 确保适当的颜色对比度
- 响应式设计支持从移动到桌面的所有设备
- 针对低带宽和弱网络场景优化
## 问题追踪与修复流程
- 使用标准化的问题报告模板
- 问题修复前先编写复现步骤
- 每个bug修复应包含相应测试避免回归
- 重大问题需进行根本原因分析
- 定期审查常见错误类型并改进开发流程
## 代码注释最佳实践
- 写清楚为什么这样做,而不仅是做了什么
- 用注释标记未来需要优化的地方
- 所有公共API必须有注释文档
- 复杂业务逻辑需要解释业务规则
- 避免废弃或过时的注释
## 数据处理与安全
- 敏感数据传输必须加密
- 用户输入必须验证和清洗
- 实现数据备份和恢复策略
- 遵循数据最小化原则,只收集必要信息
- 实现适当的数据过期和销毁机制
## 性能优化指南
- 实现资源懒加载和按需加载
- 优化关键渲染路径提高首屏加载速度
- 使用适当的缓存策略减少网络请求
- 批量处理DOM操作避免重排和重绘
- 定期进行性能审计和优化
## 可维护性原则
- 优先考虑代码可理解性而非简洁性
- 避免过早优化和不必要的抽象
- 关键决策需在代码中记录理由
- 避免使用黑魔法和难以理解的技巧
- 团队培训和知识共享机制
## 技术债务管理
- 使用TODO和FIXME标记需要改进的地方
- 定期安排时间清理技术债务
- 新功能实现前评估现有代码质量
- 记录所有已知问题和临时解决方案
- 使用代码质量工具定期评估项目健康度
## 用户体验设计规范
- 所有操作必须提供用户反馈
- 错误信息应该清晰并提供解决方案
- 降低操作复杂度,减少用户认知负担
- 界面风格保持一致性
- 考虑边缘情况和用户出错恢复路径
## 开发计划与进度管理规范
- 开发任务开始前必须制定详细的开发计划文档(devplan.md)
- 开发计划必须包含:项目目标、功能模块清单、技术方案、任务分解、时间节点和风险评估
- 任务分解应细化到工作单元,便于进度跟踪
- 设置明确的里程碑和检查点,实现阶段性目标确认
- 开始工作前,复查开发计划并调整任务优先级
- 结束工作时,更新任务完成状态并记录进度偏差
- 根据实际进度,定期调整开发计划
- 当出现阻塞问题时,应立即记录并调整后续任务安排
- 使用任务看板或项目管理工具可视化呈现开发进度
- 将开发计划与版本控制系统集成,确保代码提交与计划任务对应
- 将已完成与未完成的任务清晰区分,并记录转移原因
- 每个版本发布前进行开发计划复盘,总结经验教训
- 根据历史开发计划的执行情况不断优化估算方法和任务分解粒度当然了这只是一种表面级的"优化",相同模型 trae 的精准度肯定不如 cursor 的,涉及到的文件越多、代码越多,这个现象越明显。本质上还是因为 trae 为了节约,把上下文控制的比较小。举个简单的例子就是它容易读了几百行代码,经过你的一翻处理后,它就忘记了一开始的几百行代码,需要重读,重读结束,又会不得已忘记一些之前处理过的代码。
这也没办法,毕竟 trae 是 unlimited 的,价钱预算有限的情况下,不能指望他完全替代甚至超过 cursor。目前先继续使用,如果可以再继续反馈;如果有继续优化的地方,也会继续告诉大家。
