在实际的数据库迁移工作中,异构库之间的迁移常常被视为一项"高风险、高工作量、高复杂度"的挑战任务。这不仅是一次数据库切换,更是对系统稳定性、数据一致性、业务连续性和技术团队耐力的全方位考验。
为解决企业在异构数据库迁移中的痛点,NineData 数据复制功能现已支持 SQL Server > MySQL 的结构、全量和增量同步链路,帮助企业以更低风险、更少投入、更短停机时间,完成数据库系统的平滑迁移与实时同步。
1. SQL Server > MySQL 迁移有多难?
- 语法与结构不兼容: SQL Server 与 MySQL 在语法、数据类型、约束定义等方面存在诸多差异,手动迁移不仅耗时耗力,出错率也高,迁移后的系统常因兼容性问题反复踩坑。
- 数据量大迁移缓慢: 企业数据库通常有数千万甚至上亿条数据,全量导出导入耗时长、易中断,不具备恢复机制,一旦失败,迁移进度将被严重拖慢。
- 增量同步机制缺失: 传统迁移方案多数无法处理实时变更,尤其是长周期运行场景中,源库与目标库的数据一致性难以保障。
- 业务中断风险高: 很多企业业务系统依赖 SQL Server,无法接受长时间停机或迁移期间数据丢失。
2. NineData 如何解决这些痛点?
NineData 在数据复制引擎层面深度优化,专为异构数据库之间的数据迁移与实时同步场景而设计:
2.1 表结构复制:自动识别字段、索引、外键,迁移更轻松
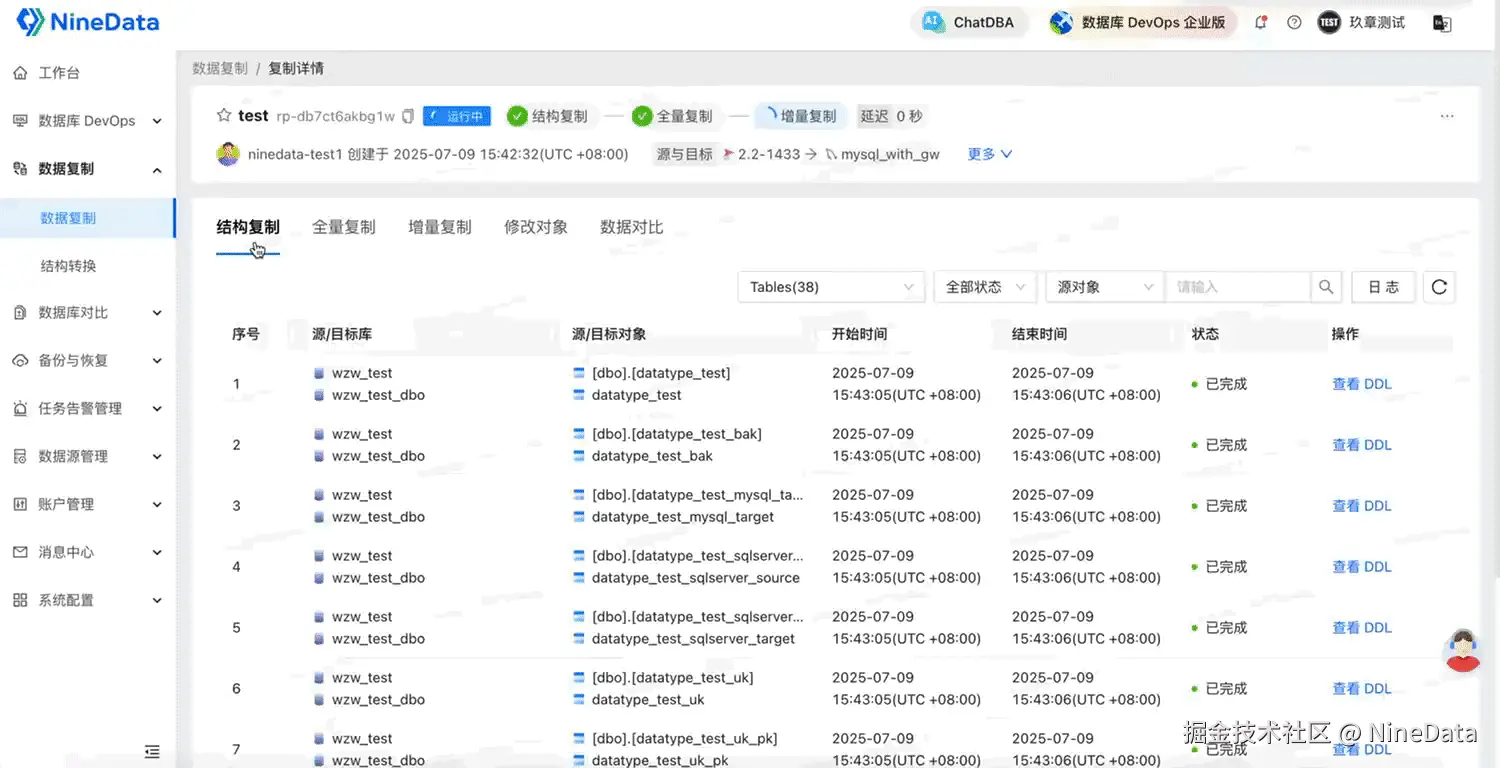
NineData 当前支持的结构复制,聚焦在最关键的对象类型:表。并不仅仅是建表语句的搬运,而是:
- 自动识别表字段、主键、唯一键、普通索引、外键等结构信息。
- 自动完成字段类型的映射与转换。
- 支持表名、字段名的映射。
- 避免手动建表、手动改字段,迁移过程更加结构化、自动化。
2.2 全量复制稳定高效,超大表/字段无压力
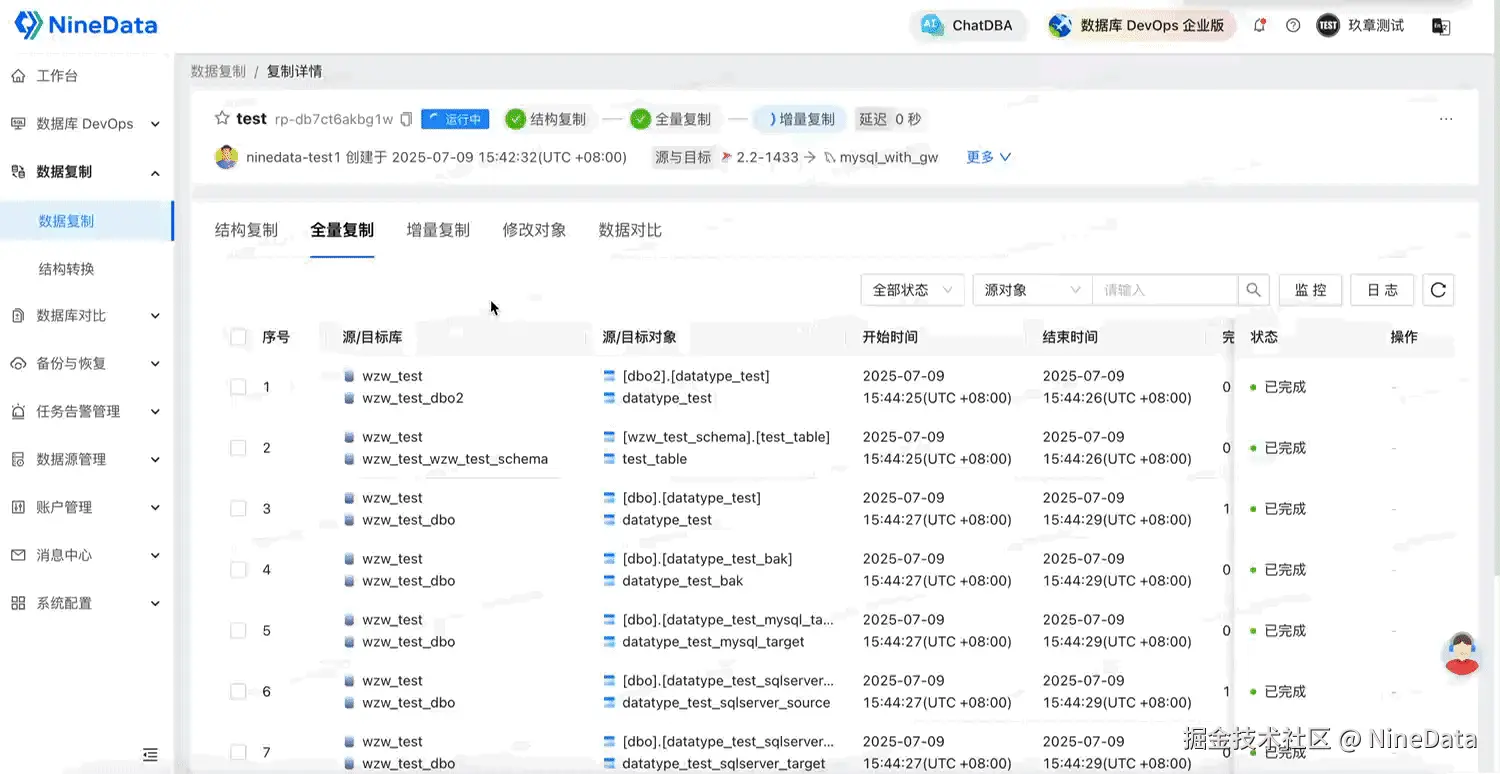
在全量复制场景中,NineData 经过实际测试验证,具备以下能力:
- 支持亿级大表迁移:单表数据超 1 亿条记录,复制过程稳定,性能表现优异;
- 支持超大字段迁移:单行数据记录超过 20MB 无异常;
- 全面支持所有主流数据类型:数值、日期时间、字符串、二进制、空间类型等均验证通过;
- 支持字符集、时区、中文、表情等特殊字符内容同步;
- 索引完整性同步:单列、多列主键/唯一键,普通索引等均已验证支持。
2.3 增量复制:CDC 实时捕获,数据同步秒级延迟
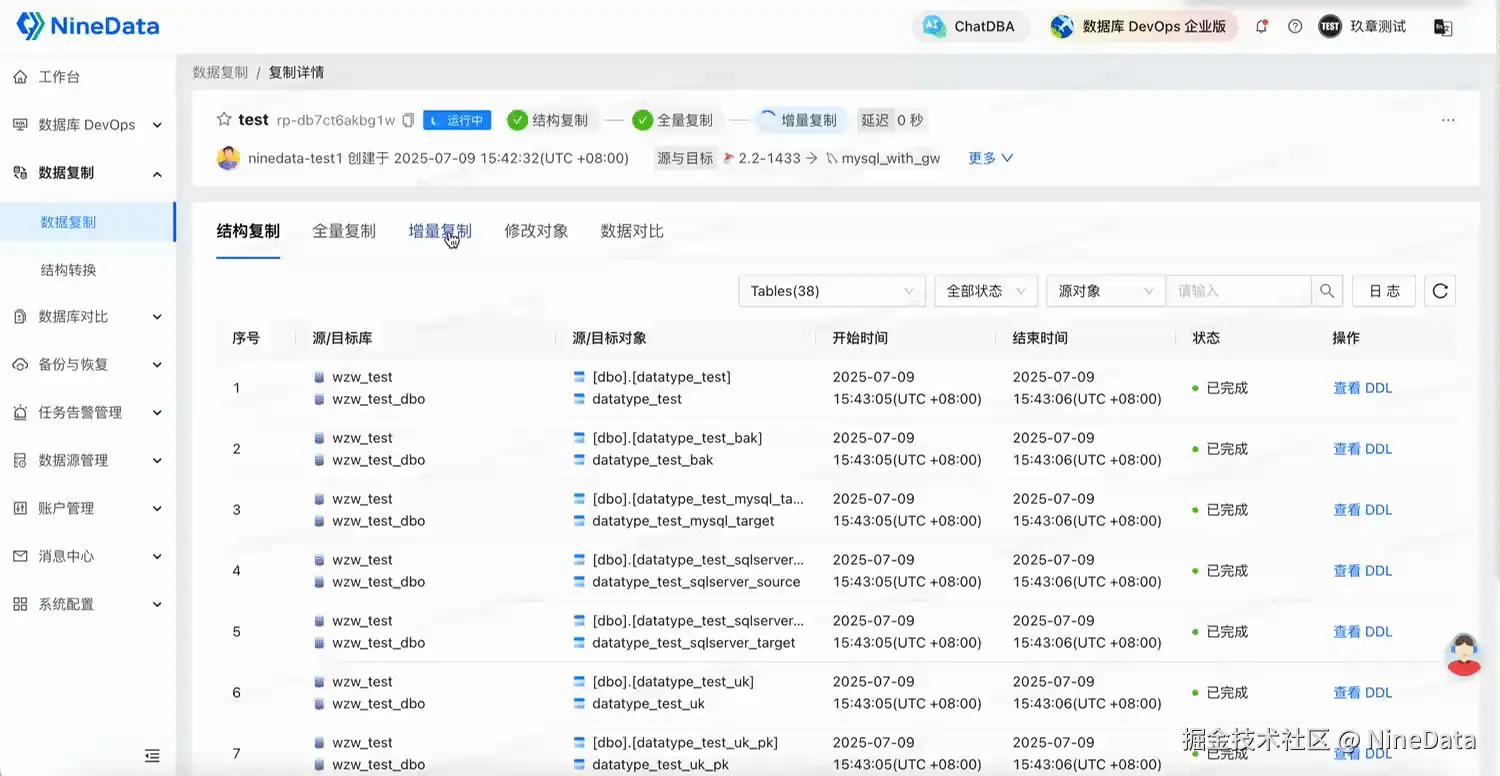
NineData 基于 SQL Server 的 CDC(Change Data Capture)机制,全面支持:
- DML 操作同步:INSERT、UPDATE、DELETE 全覆盖;
- DDL 兼容性测试中:常见 CREATE、ALTER、TRUNCATE 等操作已部分支持(个别指令仍在修复中,如 TRUNCATE、RENAME);
- 复杂数据类型与大事务同步:已验证支持含复杂结构的数据更新,以及单事务 10 万行级别变更;
- 断点续传与容灾能力:测试通过,迁移过程具备断点恢复机制,避免单点失败带来数据不一致风险;
- 支持全字符集、表情、特殊字符、跨时区等场景下的增量同步。
2.4 数据对比校验:确保迁移后目标库数据 100% 一致
NineData 提供内置数据比对机制,自动对源库与目标库数据进行一致性校验:
- 精确对比每一条记录。
- 自动识别字段精度差异、缺失记录、值不一致等问题。
- 生成可视化比对报告,支持差异数据导出与修复。
- 适配大表、高并发下的安全比对,确保数据质量和准确性。
3. 企业应用场景举例
- 替换高昂授权成本的 SQL Server,切换至开源 MySQL 方案。
- 实现 SQL Server 数据同步至 MySQL 数据仓库用于分析查询。
- 推动企业 IT 架构朝异构、多源系统演进,实现技术栈多样化与灵活部署。
4. 总结
通过此次 SQL Server > MySQL 复制链路的上线,NineData 不仅扩展了异构数据库支持边界,更为企业提供了一套 "零脚本、低停机、可控风险" 的标准化迁移路径。