目录
那此时你可能有疑问,为什么不能直接使用hashcode()?
[为什么 HashMap 的数组长度要取 2 的整数幂?](#为什么 HashMap 的数组长度要取 2 的整数幂?)
对应的Java源码中,对于哈希索引冲突提供了什么样的解决方案
哈希表是怎么来的?
哈希表的存在是为了解决能通过O(1)时间复杂度直接索引到指定元素。
这是什么意思呢?
我们使用数组存放元素,都是按照顺序存放的,当需要获取某个元素的时候,则需要对数组进行遍历比较ai与key的值是否相等,直到相等才返回索引i,时间复杂度是On;
在有序表中查找时,我们经常使用的是二分查找,通过比较key与ai的大小来折半查找,直到相等时才返回索引i,最终通过索引找到我们要找的元素,时间复杂度是O(logn)。
所以我们有了一种想法,可以不经过比较,直接通过计算key得到我们要的结果,这就有了哈希表。
哈希表的数据结构
我们通过对一个 Key 值计算它的哈希并与长度为2的n次幂的数组减一做与运算,计算出槽位对应的索引,将数据存放到索引下。那么这样就解决了当获取指定数据时,只需要根据存放时计算索引ID的方式再计算一次,就可以把槽位上对应的数据获取处理,以此达到时间复杂度为O(1)的情况,如图所示
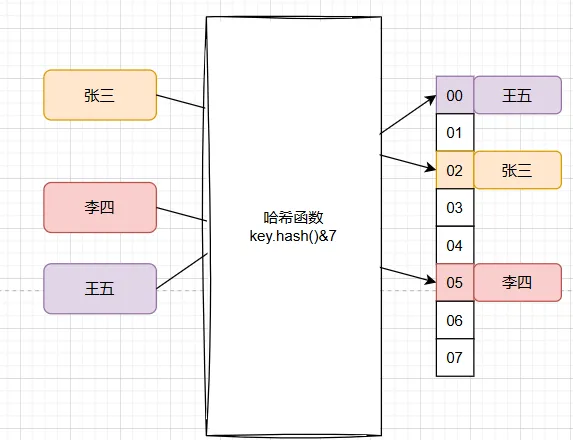
哈希散列虽然解决了获取元素的时间复杂度问题,但大多数时候这只是理想情况。因为随着元素的增多,很可能发生哈希冲突,或者哈希值波动不大导致索引计算相同,也就是一个索引位置出现多个元素情况。如图所示;
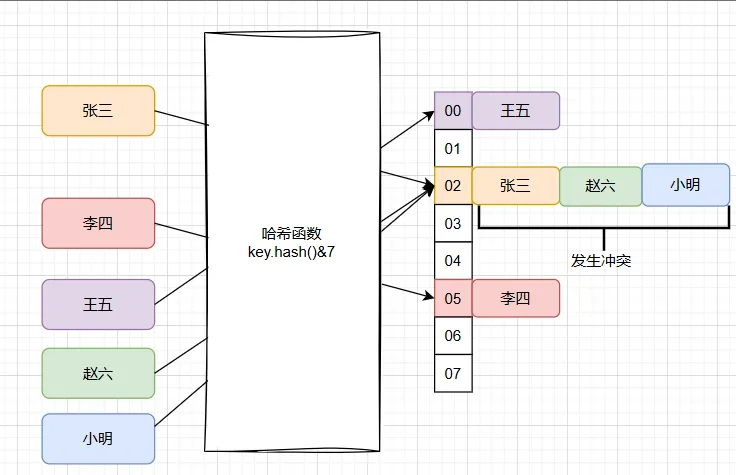
当赵六和小明都映射到下标索引为02的位置时就发生了冲突,情况就糟糕了,因为不能满足O(1)的时间复杂度获取元素的诉求了。
那么此时就出现了一系列解决方案,包括;HashMap 中的拉链寻址 + 红黑树、扰动函数、负载因子、ThreadLocal 的开放寻址、合并散列等各类数据结构设计。让元素在发生哈希冲突时,也可以存放到新的槽位,并尽可能保证索引的时间复杂度小于O(n)
哈希函数的设计
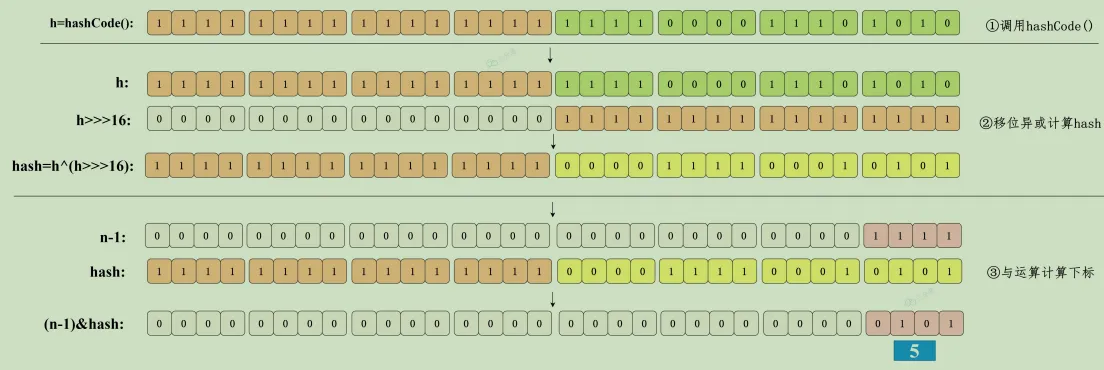
HashMap的哈希函数是先通过 hashCode() 获取到key的哈希值,哈希值是一个32位的int类型的数值,然后再将哈希值右移16位(高位),然后与哈希值本身异或,达到高位与低位混合的效果,得到一个更加散列的低 16 位的 Hash 值,增大随机性减少碰撞。
java
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}那此时你可能有疑问,为什么不能直接使用hashcode()?
首先,hashCode的取值范围是-2\^31, 2\^31-1,与 int 的取值范围一致,也就是-2147483648, 2147483647,有将近40亿的长度,不可能把数组初始化得这么大,内存也放不下。
所以,我们要将hashCode的值进行扰动计算,先通过 hashCode() 获取到key的哈希值,哈希值是一个32位的int类型的数值,然后再将哈希值右移16位(高位),相当于把高位移到了低位,然后与哈希值本身异或,达到高位与低位混合的效果,得到一个更加散列的低 16 位的 Hash 值,增大随机性减少碰撞。
为什么 HashMap 的数组长度要取 2 的整数幂?
因为这样(数组长度 - 1)正好相当于一个 "低位掩码"。 与 操作的结果就是散列值的高位全部归零,只保留低位值,用来做数组下标访问。以初始长度 16 为例,16-1=15。2进制表示是 0000 0000 0000 0000 0000 0000 0000 1111 。和某个散列值做与 操作如下,结果就是截取了最低的四位值。
除了以上的方便哈希取余的好处外,第二个好处是为了再扩容时,利用扩容后的大小也是2的倍数,将已经产生hash碰撞 的元素完美的转移到新的table中去。
一张图说明计算哈希下标索引全流程
手写实现简单的哈希散列
哈希碰撞
java
/**
* 不完美哈希
*/
public class HashMap01<K, V> implements Map<K, V>{
private Logger logger = LoggerFactory.getLogger(HashMap01.class);
private final Object[] table = new Object[8];
@Override
public void put(K key, V value) {
table[key.hashCode() % table.length] = value;
}
@Override
public V get(K key) {
return (V) table[key.hashCode() % table.length];
}
}HashMap01 的实现只是通过哈希计算出的下标,散列存放到固定的数组内。那么这样当发生元素下标碰撞时,原有的元素就会被新的元素替换掉。
测试程序
java
public class Test {
private static final Logger logger = LoggerFactory.getLogger(Test.class);
public static void main(String[] args) {
Map<String, String> map = new HashMap01<>();
map.put("01", "小明");
map.put("02", "小刚");
logger.info("碰撞前 key:{} value:{}", "01", map.get("01"));
// 下标碰撞
map.put("09", "小红");
map.put("12", "小娟");
logger.info("碰撞前 key:{} value:{}", "01", map.get("01"));
}
}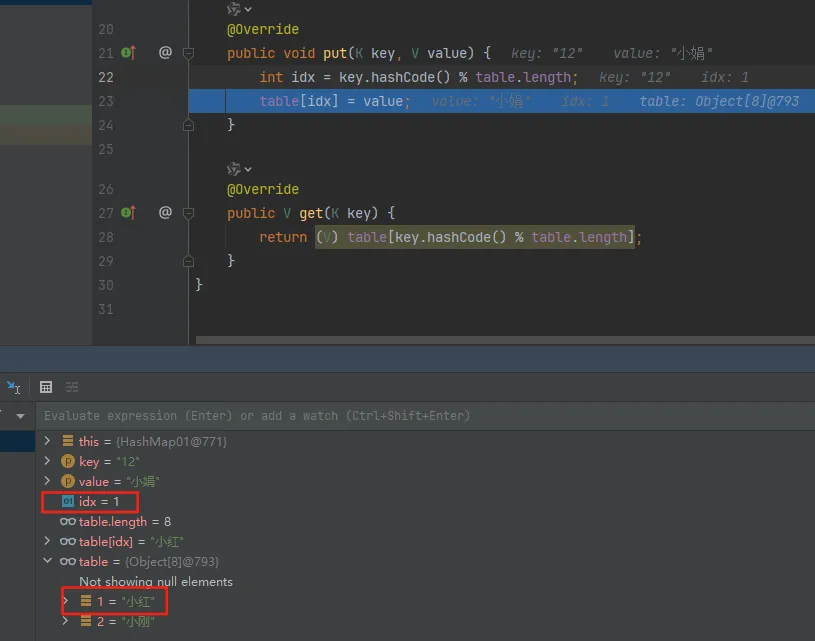

通过测试结果可以看到,碰撞前 map.get("01") 的值是小红,两次下标索引碰撞后存放的值则是小娟
这也就是使用哈希散列必须解决的一个问题,无论是在已知元素数量的情况下,通过扩容数组长度解决,还是把碰撞的元素通过链表存放,都是可以的
拉链寻址
java
public class HashMap02BySeparateChaining<K, V> implements Map<K, V> {
private Logger logger = LoggerFactory.getLogger(HashMap02BySeparateChaining.class);
private final LinkedList<Node<K, V>>[] tab = new LinkedList[8];
@Override
public void put(K key, V value) {
int idx = key.hashCode() & tab.length - 1;
if (tab[idx] == null) {
tab[idx] = new LinkedList<>();
tab[idx].add(new Node<K, V>(key, value));
} else {
tab[idx].add(new Node<K, V>(key, value));
}
}
@Override
public V get(K key) {
int idx = key.hashCode() & (tab.length - 1);
for (Node<K, V> kvNode : tab[idx]) {
if (key.equals(kvNode.getKey())) {
return kvNode.value;
}
}
return null;
}
static class Node<K, V> {
K key;
V value;
public Node(K key, V value) {
this.key = key;
this.value = value;
}
public K getKey() {
return key;
}
public void setKey(K key) {
this.key = key;
}
public V getValue() {
return value;
}
public void setValue(V value) {
this.value = value;
}
}
}因为元素在存放到哈希桶上时,可能发生下标索引膨胀,所以这里我们把每一个元素都设定成一个 Node 节点,这些节点通过 LinkedList 链表关联,当然你也可以通过 Node 节点构建出链表 next 元素即可。
测试程序
java
public class Test {
private static final Logger logger = LoggerFactory.getLogger(Test.class);
public static void main(String[] args) {
Map<String, String> map = new HashMap02BySeparateChaining<>();
map.put("01", "小明");
map.put("02", "小刚");
logger.info("碰撞前 key:{} value:{}", "01", map.get("01"));
// 下标碰撞
map.put("09", "小红");
map.put("12", "小娟");
logger.info("碰撞前 key:{} value:{}", "01", map.get("01"));
}
}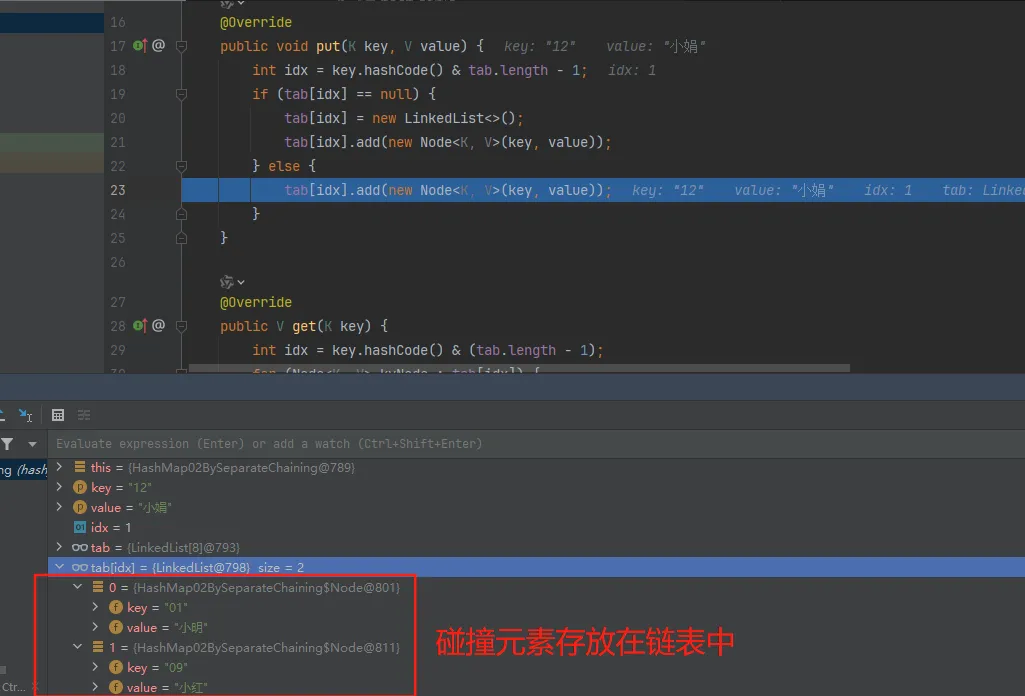
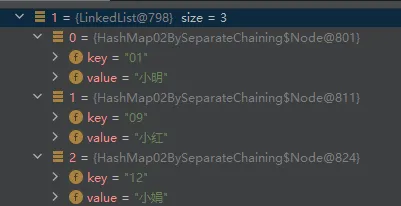
此时第一次和第二次获取01位置的元素没有被替代。因为此时的元素是被存放到链表上了。
常见问题
介绍一下散列表
散列表是将键(key)通过哈希函数计算出一个整数哈希值,然后通过对数组长度取模,得到要给数组下标,从而实现快速存储和查找 以此达到时间复杂度O(1)的情况
为什么使用散列表
为了实现高效的查找、插入和删除操作
通过哈希函数将key映射为数组的一个索引位置,查询的时候只需要再次计算哈希值并取模,就能直接定位到对应的位置,从而实现接近O(1)
拉链寻址和开放寻址的区别
区别在于冲突元素的存放方式不同
拉链寻址:当发生哈希冲突时,就将新元素插入到该位置的链表中
开放寻址:当发生哈希冲突时,根据探测去寻找下一个空闲位置
对应的Java源码中,对于哈希索引冲突提供了什么样的解决方案
使用的拉链寻址的方案
如果我的内容对你有帮助,请辛苦动动您的手指为我点赞,评论,收藏。感谢大家!!