文章目录
机器学习简介
有监督学习
- 核心目标:建立一个模型(函数),来描述输入(X)和输出(Y)之间的映射关系
- 价值:对于新的输入,通过模型给出预测的输出
要点:
- 有一定数量的训练样本
- 输入 和 输出 之间有关联关系
- 输入 和 输出 可以数值化表示,机器学习本质上是在找规律找公式
- 任务需要有预测价值
应用
-
文本分类任务
- 输入:文本 输出:类别
- 关系:文本的内容决定了文本的类别
-
机器翻译任务
- 输入:A语种文本 输出:B语种文本
- 关系:A语种表达的意思,在B语种中有对应的方式
-
图像识别任务
-
输入: 图像 输出: 类别
-
关系: 图中的像素排列,决定了图像的内容
-
-
语音识别任务
- 输入:音频 输出:文本
- 关系:声音信号在特定语言中对应特定的文本
无监督学习
给予机器的数据没有经过数据的标注,通过算法对数据进行一定的自动分析处理,得到一些结论
应用 :
聚类,降维 (高维样本的低维表示),找特征值
一般流程
训练数据----数据处理---算法选择---建模/评估---算法调优---模型
常用概念
- 训练集
用于模型训练的训练数据集合
- 验证集
对于每种任务一般都有多种算法可以选择,一般会使用验证集验证用于对比不同算法的效果差异
3.测试集
最终用于评判算法模型效果的数据集合
- k折交叉验证 (不太懂)
初始采样分割成k个子样本,一个单独的子样本被保留作为验证模型的数据,其他k-1个样本用来训练,交叉验证重复k次,每个子样本验证一次,平均k次的结果
5. 过拟合
在训练集,验证集上表现好,但是在测试集上表现不好
- 欠拟合
模型没能建立起合理的输入输出之间的映射,输入输出关联不大
-
评价指标
不同任务有不同的评价指标
1)准确率
2)召回率 : 数据中筛选出来正样本的比例
3)F1值 : 判断模型的准确性和完整性
4)TopK : 经过某些操作并排序选取得分最高的多少个
5)BLEU : 评估机器翻译或文本生成质量的指标
深度学习简介
神经网络(NN) : 它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。
隐含层/中间层
神经网络模型输入层和输出层之间的部分
隐含层可以有不同的结构:
RNN
CNN
DNN
LSTM
Transformer
等等
它们本质上的区别只是不同的运算公式
例子and流程
- B随便猜一个数 ----模型随机初始化
模型函数 :Y = k * x (此样本x = 100)
此例子中B选择的初始k值为0.6
- A计算B的猜测与真正答案的差距 ----计算loss
损失函数 = sign(y_true -- y_pred)
- A告诉B偏大或偏小 ----得到loss值
- B调整了自己的"模型参数" ---反向传播
- 参数调整幅度依照B自定的策略 ---优化器&学习率
- 重复以上过程
- 最终B的猜测与A的答案一致 ----loss = 0
解释:
不同的公式对应不同的模型的名字,比如卷积神经网络,循环神经网络,本质就是不同的的公式
根据loss值,反向传播,直到去哪个方向
优化器的公式,决定一次走多远
如果想要猜测的又快又准,调整的方向有哪些?
- 随机初始化
NLP中的 预训练模型 就是对随机初始化 的技术的优化
- 优化 损失函数
loss = y_true-y_pred
- 调整 参数 的策略 (优化器环节)
比如说B 使用二分法
- 调整 模型结构
不同模型能够拟合不同的数据集
随机初始化
原因:
隐含层 中会含有很多的权重矩阵,这些矩阵需要有初始值,才能进行运算
初始值的选取会影响最终的结果
值的选取:
- 模型会采取随机初始化,但参数会在一定范围内
- 预训练模型 ---训练好的参数---> 随机初始值
损失函数
定义 : 损失函数(loss function或cost function)用来计算模型的预测值与真实值之间的误差。
目的 : 模型训练的目标一般是依靠训练数据来调整模型参数,使得损失函数到达最小值。
损失函数有很多,选择合理的损失函数是模型训练的必要条件。
比如:
L ( y ^ , y ) = m a x ( 0 , 1 − y ^ y ) L ( y ^ , y ) = − y l o g ( y ^ ) − ( 1 − y ) l o g ( 1 − y ^ ) L ( y ^ , y ) = e x p ( − y ^ y ) L(\hat{y},y) = max(0,1-\hat{y}y)\\ L(\hat{y},y) = -ylog(\hat{y}) - (1-y)log(1-\hat{y})\\ L(\hat{y},y) = exp(-\hat{y}y)\\ L(y^,y)=max(0,1−y^y)L(y^,y)=−ylog(y^)−(1−y)log(1−y^)L(y^,y)=exp(−y^y)
- Hinge Loss(合页损失)
L ( y ^ , y ) = m a x ( 0 , 1 − y ^ y ) L(\hat{y},y) = max(0,1-\hat{y}y) L(y^,y)=max(0,1−y^y)- 用途 :主要用于支持向量机(SVM)中的最大间隔分类,尤其适用于二分类问题(标签 y ∈ − 1 , 1 y \in {-1, 1} y∈−1,1)。
- 特点 :当样本分类正确( y ^ y ≥ 1 \hat{y}y \geq 1 y^y≥1)时损失为0,否则线性惩罚。
- Binary Cross-Entropy Loss(二元交叉熵损失)
L ( y ^ , y ) = − y l o g ( y ^ ) − ( 1 − y ) l o g ( 1 − y ^ ) L(\hat{y},y) = -ylog(\hat{y}) - (1-y)log(1-\hat{y}) L(y^,y)=−ylog(y^)−(1−y)log(1−y^)- 用途 :用于二分类问题(标签 y ∈ 0 , 1 y \in {0, 1} y∈0,1,预测值 y ^ ∈ 0 , 1 \hat{y} \in 0, 1 y^∈0,1)。
- 特点:衡量预测概率分布与真实标签的差异,是逻辑回归和神经网络的常用损失函数。
- Exponential Loss(指数损失)
L ( y ^ , y ) = e x p ( − y ^ y ) L(\hat{y},y) = exp(-\hat{y}y) L(y^,y)=exp(−y^y)- 用途 :经典用于AdaBoost算法(标签 y ∈ − 1 , 1 y \in {-1, 1} y∈−1,1)
- 特点:对误分类样本施加指数级增长的惩罚,增强模型对困难样本的关注。
注:
- 变量含义 :
- y ^ \hat{y} y^ 是模型的预测值(可能为原始输出或概率)。
- y y y 是真实标签,具体取值范围因损失函数而异(如 − 1 / 1 -1/1 −1/1或 0 / 1 0/1 0/1)。
- 应用场景差异 :
- Hinge Loss 强调间隔最大化,适合支持向量机。
- Cross-Entropy直接优化概率似然,适合概率模型。
- Exponential Loss用于集成方法(如AdaBoost)的逐步纠错。
大多无法训练到loss值为0,尤其是任务很复杂的时候
loss的结果可以小于0吗?
一般都是>=0
收敛和泛化的区别是什么?
损失函数不再下降,就认为收敛了
泛化指的是模型效果怎么样,有可能loss很低,在验证集上表现好,但是在测试集上表现差
导数与梯度
导数表示函数曲线上的切线斜率。 除了切线的斜率,导数还表示函数在该点的变化率
梯度下降
-
梯度告诉我们函数向哪个方向增长最快,那么他的反方向,就是下降最快的方向
-
梯度下降的目的是找到函数的极小值
-
为什么要找到函数的极小值?
因为我们最终的目标是损失函数值最小
优化器
知道走的方向,还需要知道走多远,
假如一步走太大,就可能错过最小值,如果一步走太小,又可能困在某个局部低点无法离开
学习率(learning rate),动量(Momentum)都是优化器相关的概念
Mini Batch epoch
- 一次训练数据集的一小部分,而不是整个训练集,或单条数据
- 它可以使内存较小、不能同时训练整个数据集的电脑也可以训练模型。
- 它是一个可调节的参数,会对最终结果造成影响
- 不能太大,因为太大了会速度很慢。 也不能太小,太小了以后可能算法永远不会收敛。
- 我们将遍历一次所有样本的行为叫做一个 epoch
流程
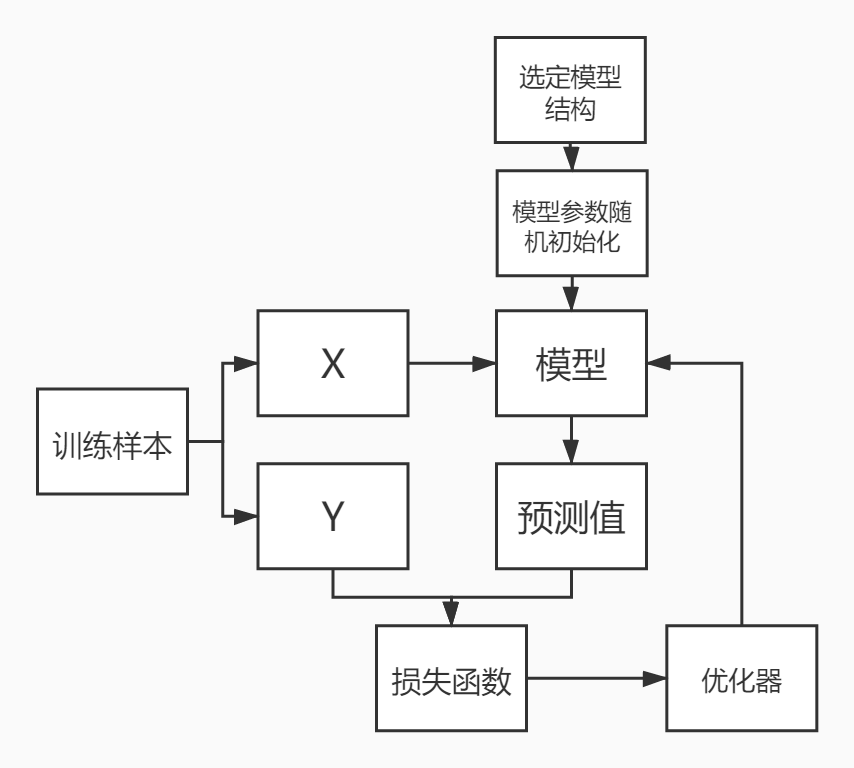
训练迭代进行
模型训练好后把参数保存 , 即可用于对新样本的预测
要点:
- 模型结构选择
- 初始化方式选择
- 损失函数选择
- 优化器选择
- 样本质量数量
深度学习的基本思想
选公式->参数随机初始化->标注数据算误差->根据误差调整参数
简而言之,"先猜后调"