本文翻译自:ARM 中内存序的介绍
文章中加入了一些自己的理解,读者如若觉得不合适,欢迎指出~
1、关于内存序
1.1 顺序执行模型
在计算机的"黄金年代",程序运行时的行为与开发者阅读源代码时的直觉预期高度一致:
- 程序的执行严格遵循源码设定的逻辑路径
- 操作顺序与代码书写顺序完全吻合
- 循环迭代次数精确对应编程时的指定次数(不多不少)
- 所有操作都以严格的串行方式执行
这种令人怀念的理想状态,在现代计算机体系结构中被称为"顺序执行模型"。即便在最先进的处理器架构中,为了保持既有程序的兼容性,系统仍会竭力维持这种顺序执行的假象------但请注意,这种假象仅对程序内部可见。在处理器外部,我们依然能清晰观察到底层那些无法隐藏的"魔法"正在悄然发生。
从程序内部的角度:
从程序员或软件的角度看,程序似乎是一条条指令按顺序执行的。比如在 C/C++/Java 中写的代码,如果你写:
c
a = 1;
b = a + 2;你预期 b 赋值发生在 a = 1 之后,且是基于 a = 1 的结果进行计算的。现代处理器会尽一切努力让你"看到"的执行顺序符合这种逻辑。
为了维持这种"错觉",处理器会采取:
- 指令重排序,但确保逻辑依赖不被破坏。
- 使用内存屏障(memory barriers)或其他机制,保持可观察的顺序。
- 保证每个单线程上下文看到的行为是一致的。
从处理器外部的角度(例如另一个核、另一个观察者):
- 指令实际上可能是乱序执行的(out-of-order execution),多个指令流水线、分支预测、缓存系统等都在运作。
- 多个核共享缓存时,缓存一致性协议(如 MESI)引发的延迟和状态变化,可能暴露出非顺序执行的行为。
- 外部观察者,比如另一个线程或另一个核,通过共享内存观察,会看到一些"并不顺序"的状态:
举个例子:
一个线程写入变量 x 和 y:
c
x = 1;
y = 1;另一个线程读取 y 后读取 x,可能会看到 y == 1 但 x == 0,这在顺序一致模型下是不允许的,但在弱内存模型中是可能的。
- 这也是为什么多线程编程中需要加锁、使用原子操作、内存屏障等技术,去显式控制跨线程可见的顺序。
1.2 现实
然而,现实情况是,为了提高性能(包括速度和功率),系统的许多不同层面都在进行大量优化。
2、编译器优化(Optimizing Compilers)
编译器优化可以深度重构程序员编写的软件代码,以隐藏流水线延迟或利用微架构优化。它可以决定将内存访问提前,以便在需要值之前有更多时间完成;或者,它可以将内存访问推迟,以平衡程序中的访问次数。在高度流水线化的处理器中,编译器实际上可能会重新排列所有类型的指令,以便在需要之前指令的结果时,能够获取其结果。
以下是一个常用来解释该问题的经典示例:
c
int flag = BUSY;
int data = 0;
int somefunc(void)
{
while (flag != DONE);
return data;
}
void otherfunc(void)
{
data = 42;
flag = DONE;
}假设上述代码在两个独立的线程中运行,线程 A 调用 otherfunc() 来更新值并指示操作已完成,线程 B 调用 somefunc() 等待完成信号到达后再返回变量 data 的值。C 语言规范中没有任何内容保证 somefunc() 不会在开始轮询 flag 值之前读取 data 的代码。这意味着 somefunc() 返回 0 或 42 是完全合法的。虽然有一些方法可以解决这个问题,但这仍然无法阻止硬件进行重新排序(见下文)。
3、多发射(Multi-issuing)
在现代处理器架构中(例如 ARM 处理器),多发射(multiple-issue)技术允许每个时钟周期同时发出并执行多条指令。这意味着,即使我们在汇编代码中将一条指令明确写在另一条之后,处理器也可能在硬件层面将它们并行调度和执行。ARM 架构中的超标量设计(例如 ARM Cortex-A 系列)使得多个执行单元可以同时处理来自不同流水线阶段的指令,从而大幅提升指令吞吐量和整体性能。
换句话说,指令的执行顺序并不完全由程序中代码的书写顺序决定,而是由处理器的调度器根据数据依赖、资源可用性以及指令类型等因素动态安排。这种机制使得即便是看似"顺序"的代码,也可能被并行执行,从而充分利用硬件资源。
想象一下下面的 ARM 汇编指令序列:

对于一个双发射(dual-issuing)的 CPU 来说,指令执行的顺序可能是这样:

在这个例子中,在 cycle2 时钟周期、Issue1 的 pipeline 中,因为接下来的指令执行需要 Issue0 中的 sub 指令的结果。接下来的指令(str)事实上在 cycle3 时钟周期发出,和子程序返回(bx)并行。
多发射架构通常依赖多个执行流水线(Execution Units),每个 CPU 核独享。可以简单理解为:
multi-issue(多发射) ≈ 多执行通道(pipeline / execution units)
3.1 关于处理器的 Multi-issuing
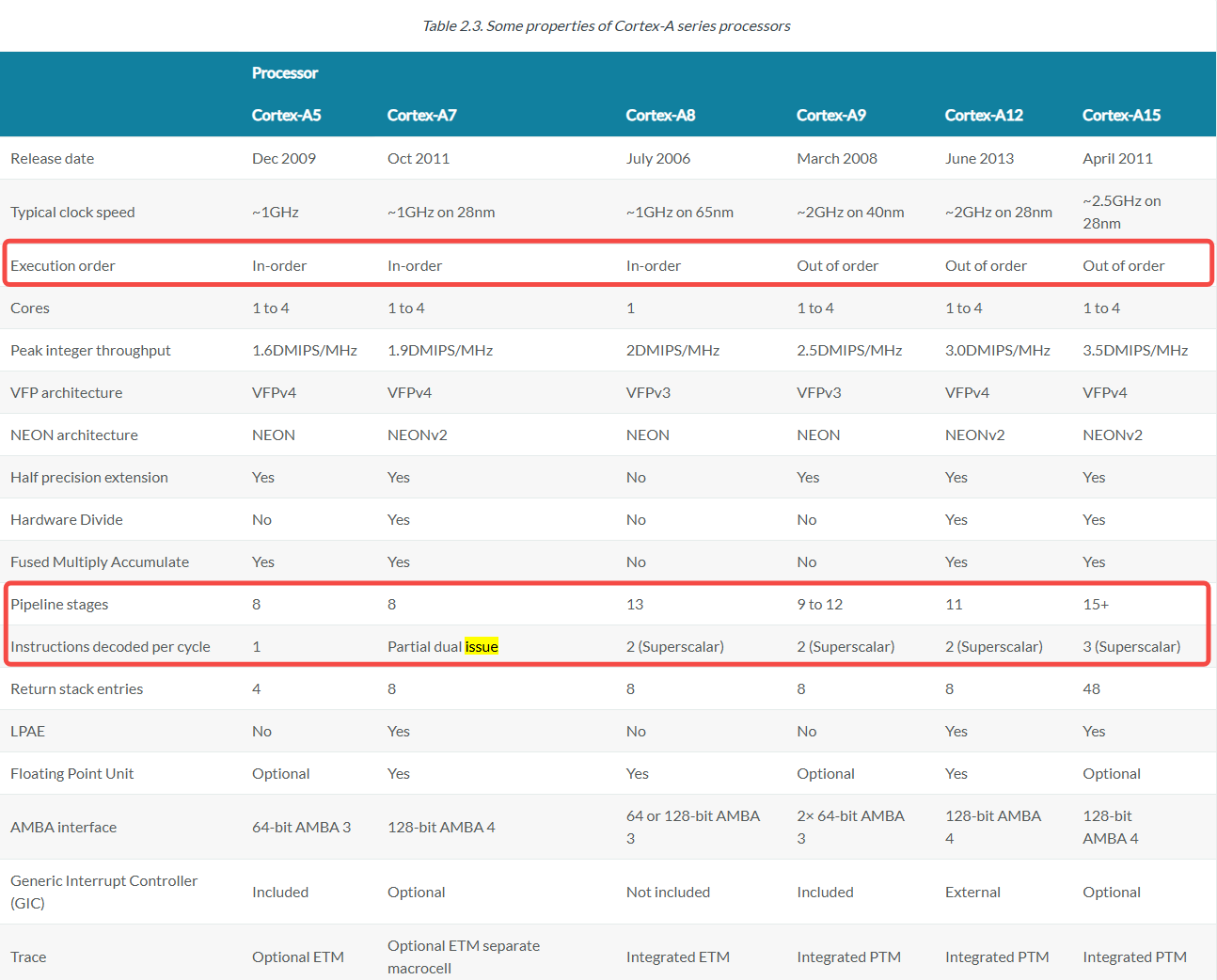
注:
- Partial dual issue:仅特定组合可以双发射
- 2 (Superscalar):更广泛的指令组合可并发执行
相关处理器的信息,ARM 官网都能查询到。
4、乱序执行(Out-of-order execution)
第一个支持乱序执行的 Arm 处理器是 Arm1136J(F)-S,它允许非依赖性的加载和存储操作以乱序方式完成。具体表现为:
- 若某次数据访问缓存未命中(Cache Miss),其他缓存命中(Hit)或未命中的访问可超越其执行,前提是两者无数据依赖性
- 同时支持加载-存储指令与数据处理指令的乱序完成(例如:当某次加载操作为后续加载/存储提供地址时,若不存在数据依赖,即可乱序执行)。
几年后出现的的 Cortex-A9,该处理器在许多情况下支持大多数非依赖指令的乱序执行。
- 当某条指令因等待前序指令结果而停顿时(Stall),核心可继续执行后续不依赖该结果的指令
典型场景:假设以下代码片段中的 mul(乘法)和 ldr(加载)指令均需 2 个周期才能产生结果,在乱序执行支持下,后续无关指令可提前执行以提升效率。
bash
add r0, r0, #4
mul r2, r2, r3
str r2, [r0]
ldr r4, [r1]
sub r1, r4, r2
bx lr如果我们在顺序处理器上执行此代码,则执行将类似于以下内容:

但如果我们在乱序处理器上执行它,我们可能会看到类似这样的结果:
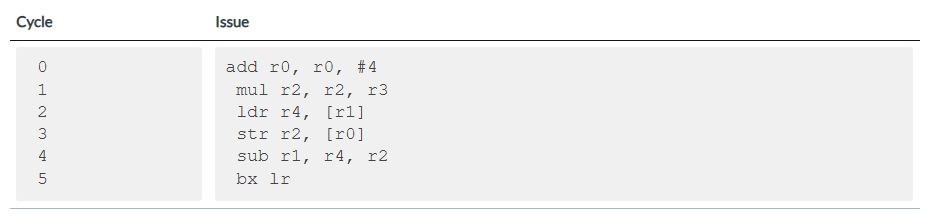
通过允许 ldr 执行------当我们等待 mul 完成以便 str 可以继续进行。当然,我们也为 ldr 提供了更多的时间来完成,直到需要它的值( sub r1, r4, r2)。
4.1 关于处理器是否支持乱序
Out-of-Order Execution 执行需要的硬件非常复杂,功耗也会增加。这几年比较火的 big.LITTLE 架构本质就是性能核 + 能效核的组合:
- A7/A53/A55 等小核是 In-order,因为能效优先;
- A9/A15/A75 等大核是 Out-of-order,因为性能优先;
4.2 注意事项
关注上面的红色字体,并不是所有场景下 CPU 都会去乱序执行指令的。只有指令之间不相互依赖,才有可能乱序执行。例如地址依赖、控制依赖。

ARM® Architecture Reference Manual ARMv7-A and ARMv7-R edition
- 数据依赖 (Data Dependency) :
add r0, r1, r2之后mul r3, r0, r4。第二条要等 r0 写完才能读 - 控制依赖 (Control Dependency) :分支未决------beq label,下一条语句要看分支结果。处理器只能猜路径;若分支预测失败,要回滚
5、推测性访问(Speculation)
简单来说,Speculative 可以分为三大类:
- Speculative Read
- Speculative Write
- Speculative Execution
推测执行(Speculative Execution) 可以简单理解为:处理器在尚未确定某条指令是否真正需要执行的情况下,就提前开始执行这条指令。这样做的好处是:一旦判断条件确认无误,处理器就已经提前准备好了执行结果,从而加快整体运行速度。
这类情况常见于使用 Arm 或 Thumb 指令集中的条件执行(conditional execution),或者遇到条件跳转指令(conditional branch)时。在这些场景中,处理器可能会提前执行这条条件指令,甚至继续执行条件跳转后的若干指令。如果最终发现推测错误,处理器必须彻底清除任何"曾经执行过"的痕迹,以确保程序状态不受影响。
在涉及加载指令(load)时,推测行为可能更加激进(Speculative Read)。
对于带 cache 的内存区域,处理器可以提前发起加载(load)操作,这可能导致该内存区域的数据被拉入 cache,从而替换掉(evict)现有的 cache line。许多现代处理器甚至会更进一步,监测内存访问模式,在判断出访问趋势后,提前将后续可能访问的数据加载进 cache ------ 即使对应的指令尚未进入处理器流水线。
当然,不带 cache 的内存区域,也有可能出现提前发起加载(load)的操作。有些场景下,例如一些外设寄存器(如 UART、SPI、NVIC),例如:
- 读寄存器某一位,就可以清除状态
- 写入特定寄存器启动某些硬件行为
如果 CPU 提前进行了访问(即使程序最后并没真正需要访问),会触发副作用,可能导致系统异常或者外设状态错乱。所以,在 ARM 学习笔记(三) 一文中,我们讲解了,几乎所有的外设寄存器,都会被设置成 Device 类型的内存,去禁止对这段内存的任何推测性访问。
5.1 Prefetching
ARM 手册中,Prefetch 这个名词也经常出现。
Prefetching
Prefetching refers to speculatively fetching instructions or data from the memory system. In particular, instruction
prefetching is the process of fetching instructions from memory before the instructions that precede them, in simple
sequential execution of the program, have finished executing. Prefetching an instruction does not mean that the
instruction has to be executed.
------------------《ARM Architecture Reference Manual ARMv7-A and ARMv7-R edition》
预取是指从内存系统中对指令或数据进行推测性获取的操作。具体而言,指令预取是指在前序指令尚未完成执行时(即程序按简单顺序执行流尚未到达该指令前),提前从内存中预加载后续指令的过程。需注意的是,预取某条指令并不保证该指令最终一定会被执行。
简单来说,prefetch 可以理解为 Speculative 一种。因为 Speculative 不仅仅包括 Speculative Read 、Speculative Write ,还包括 Speculative Execution。
5.2 拓展
上面只是笼统的介绍,真正的 Speculation,对应每个微架构的具体实现都有可能不同。例如:
Speculative writes are never made.
------------------《Arm Cortex-M7 Processor Technical Reference Manual r1p2》
在 Cortex-M7 微架构中,Speculative writes 是被禁止的。
The only stores by an observer that can be observed by another observer are those stores that have been Architecturally executed. Speculative writes by an observer cannot be observed by another observer
------------------《ARM Architecture Reference Manual ARMv7-A and ARMv7-R edition》
而对于 ARMv7 架构而言,Speculative writes 是被允许的。但是,一个观察者(observer)发出的写操作,只有在该写操作已经架构性地执行(即真实地对内存产生影响)之后,才能被另一个观察者观察到。任何仍处于推测状态的写操作,不能被其他观察者看到。这条规则是为了避免因 speculative writes 导致的不可预测行为、同步问题和设备错误。
关于 Architecturally Executed (架构上完成的) 一词的理解,一条 store 指令已经通过所有架构定义的执行阶段,产生了对系统状态(特别是对内存)的真实、可观察改变。
所以,如果涉及到非常底层的问题,最终还是要阅读、研究相应 CPU 微架构的手册。我们这里只是做一个简单的讲解。
6、Load-Store 优化
在一些高性能的系统中,外部内存访问延迟通常很大(几十个 bus cycles)。为降低此类延迟的影响,处理器会尽可能优化内存访问,其核心目标是通过减少事务(transaction )数量来提升效率,例如:
- 单次事务写入更多数据:采用突发传输(burst)模式,以单次事务的延迟完成长数据流的传输。
- 写操作合并:针对缓冲内存(buffered memory)的多次写入,可合并为单一事务。
| 特性 | Burst(突发传输) | 写合并(Write Combining) |
|---|---|---|
| 优化目标 | 提高总线带宽利用率 | 减少总线事务数量 |
| 触发条件 | 连续地址访问(硬件自动识别) | 对同一地址/对齐块的多次写(需缓冲区支持) |
| 硬件依赖 | 内存控制器/总线协议(如AXI Burst) | 存储缓冲区(Store Buffer) |
| 程序员可见性 | 通常透明 | 可能导致非原子性写入(需屏障干预) |
6.1 Store Buffer
以 Cortex-A7 微架构为例,我们可以看到,在 CPU 中,有一个 Store buffer(STB)。
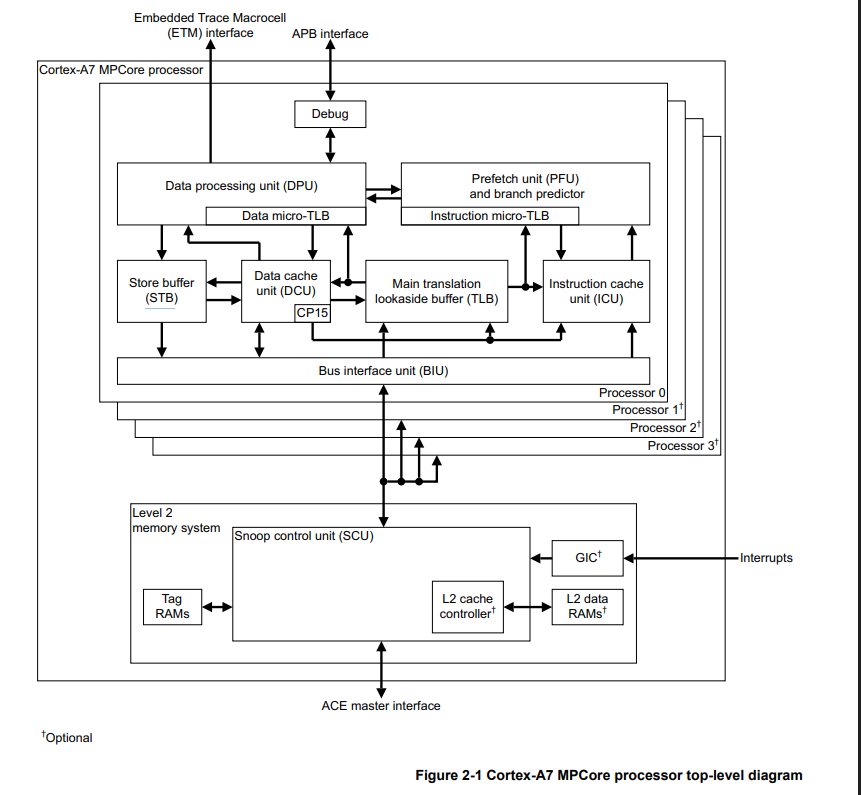
关于 STB 的作用,ARM Cortex-A7 手册中,也给了明确说明:
The Store Buffer (STB) holds store operations when they have left the load/store pipeline andhave been committed by the DPU.
STB 用于暂存已离开 load/store 流水线且被数据处理单元(DPU)提交的存储操作(store operations)。
The STB can merge:
- Several store transactions into a single transaction if they are to the same 64-bit aligned address. The STB is also used to queue up CP15 maintenance operations before they are broadcast to other processors in the multiprocessor device.
- Multiple writes into an AXI write burst
STB(存储事务缓冲区)可执行以下合并操作:
- 若多个存储事务针对同一 64 位对齐地址,则可将其合并为单一事务。该缓冲区还用于暂存 CP15 维护操作,待积累后再向多处理器设备中的其他处理器进行广播
- 所有写操作针对同一个 64 位对齐的地址块(即地址的高位相同,低3位为0b000)。示例:
- 可合并的 32 位写操作:
- 第一个写:地址 0x1000(64位对齐),写入 32 位数据(占用 0x1000~0x1003)
- 第二个写:地址 0x1004(非对齐,但属于同一 64 位块 0x1000~0x1007),写入 32 位数据(占用 0x1004~0x1007)
- 合并结果:一个 64 位写事务,覆盖 0x1000~0x1007
- 不可合并的情况:
- 若两个 32 位写分别指向 0x1000 和 0x1008(属于不同的64位块),则无法合并
- 可合并的 32 位写操作:
- 所有写操作针对同一个 64 位对齐的地址块(即地址的高位相同,低3位为0b000)。示例:
- 将多次写操作合并为AXI写突发传输
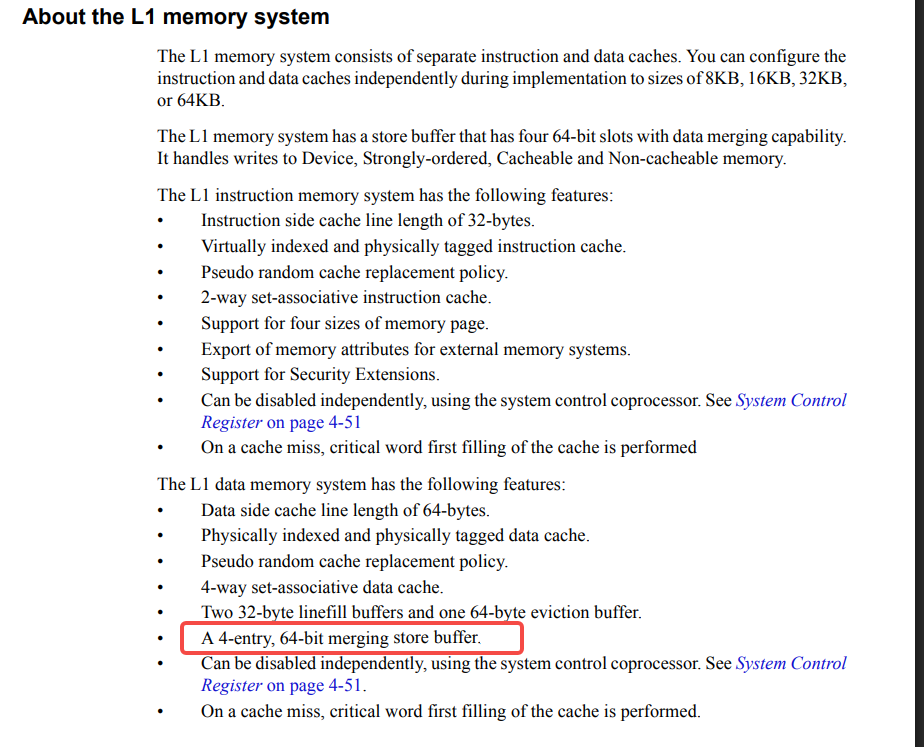
L1 存储系统配备了一个存储缓冲区(store buffer),该缓冲区提供 4 个 64 位槽位(slot),并支持数据合并功能。
7、多核之间的 Cache 一致性
在使用多核处理器时,基于硬件的缓存一致性管理(例如 MESI 协议)可以使缓存行在核心之间透明地迁移。这可能会导致不同核心以不同的顺序查看缓存内存位置的更新。
举一个具体的例子:上面的 somefunc() 和 otherfunc() 示例在多核 SMP 系统中执行时还存在另一个潜在影响。如果两个线程在不同的 CPU 核上执行,那么硬件缓存一致性管理、推测和乱序执行的结合意味着不同内核可能会看到不同的内存访问顺序。
简而言之,硬件缓存一致性管理意味着缓存行可以在不同内核之间移动,以便在任何访问位置都可用。由于具有乱序执行能力的处理器可以在等待另一个加载(或存储)结果完成的同时从缓存中加载一个内存位置,因此执行 somefunc() 的核心完全可以在 flag 的值实际更改为 DONE 之前推测性地加载数据的值 - 即使这不是指令在编译应用程序中的顺序。
8、总结
通读全文,我们应明确两点:
- 多数底层优化机制(如乱序执行、推测执行、多发射等)对软件开发者而言是透明的,无需显式关注;
- 然而,部分优化会对程序行为产生可观察影响。为保障正确性,体系结构也提供了如内存屏障等机制,使开发者可以显式控制这些影响。当然这里也包括 ARM 学习笔记(三) 中所讲的内存类型。
阅读到这里,建议再看一下 ARM 架构下 cache 一致性问题整理 一文,可能会有不一样的体会。