在上一章中,我们了解了什么是RAG,以及如何结合大型语言模型(LLMs)实现一些简单的RAG流程示例。本章将聚焦于知识图谱的概念,以及图结构如何提升检索增强生成(RAG)的效果。我们将探讨如何构建知识图谱模型,并介绍Neo4j在此中的应用。具体来说,我们会了解Neo4j的数据建模和数据持久化方式如何助力构建更强大的知识图谱。同时,我们还将比较关系型数据库管理系统(RDBMS)与Neo4j知识图谱的数据存储方法,从而更好地理解不同数据模型下的数据特性。
我们将开启一段激动人心的旅程,探索RAG模型与Neo4j强大图数据库能力的融合,如何支持利用结构化知识库打造更智能、高效的应用。
本章主要内容包括:
- 理解图数据建模的重要性
- 结合RAG与Neo4j知识图谱的力量------GraphRAG
- 知识图谱的增强
技术需求
在深入实际构建用于RAG集成的知识图谱与Neo4j之前,必须先准备好必要的工具和环境。以下是本章的技术需求:
-
Neo4j数据库:可选用Neo4j Desktop实现本地搭建,或使用云端方案Neo4j Aura。
- Neo4j Desktop下载地址:neo4j.com/download/
- Neo4j Aura介绍:neo4j.com/product/neo...
Neo4j提供两种主要云服务: - AuraDB:面向开发者的全托管图数据库服务,支持灵活模式、原生关系存储及高效Cypher查询。AuraDB提供免费套餐,方便用户探索图数据。详情见:neo4j.com/product/aur...
- AuraDS:全托管的Neo4j图数据科学实例,用于构建数据科学应用。详情见:neo4j.com/docs/aura/g...
-
DB Browser for SQLite :便捷查询SQLite数据库的工具,网址:sqlitebrowser.org/
-
Cypher查询语言 :本章需要熟悉Neo4j的查询语言Cypher。Neo4j提供优质的Cypher教程。如果不熟悉,可访问GraphAcademy(graphacademy.neo4j.com/)学习基础课程,也可参考图书《Graph Data Processing with Cypher》(www.packtpub.com/en-us/produ...)深入了解。
-
Python环境 :推荐Python 3.8及以上版本,确保已安装。官方下载地址:www.python.org/downloads/
-
Neo4j Python驱动:用于Python与Neo4j数据库交互。安装命令:
pip install neo4j-driver -
GitHub代码仓库 :本章所有代码和资源均托管于该仓库:github.com/PacktPublis... ,具体内容请进入
ch3文件夹查看。
请确保以上工具和库均已安装配置完成,以便顺利跟进本章示例和练习。
理解图数据建模的重要性
在深入了解GraphRAG如何与Neo4j协同工作之前,先退一步,理解我们如何对知识图谱进行建模。我们将拿一些简单的数据,分别尝试在关系型数据库管理系统(RDBMS)和图数据库中如何建模。同时,我们也会看到,数据的建模方式会因我们观察数据的视角不同而有所差异。
图数据库促使我们以不同的方式思考问题,根据要解决的任务,从不同角度看待数据。虽然这看似一种挑战,但实际上为我们打开了许多新的可能。长期以来,我们习惯用实体-关系(ER)图的方式来理解和设计RDBMS的数据存储方式。这种方法在技术有限、存储成本高昂的时代非常有效。随着技术进步和硬件成本下降,出现了新的可能性,也使得更多样的数据建模方式成为可能。图数据库正好能够很好地利用这些新机遇。
为了尝试新的数据建模思路,我们可能需要"忘掉"一些过去用ER图表示数据的习惯。虽然听起来简单,但实际上可能有些困难。这个学习与遗忘的过程类似于神经可塑性"棱镜眼镜"实验,正如下图所示。
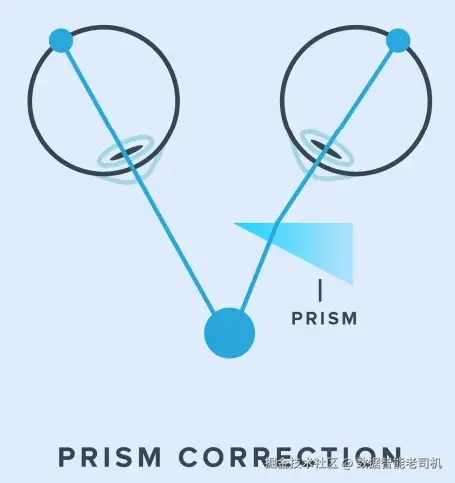
这个实验要求参与者佩戴棱镜眼镜来完成一个简单任务。由于视线发生了偏移,大脑需要一定时间来适应,才能正确完成任务。当参与者摘下眼镜后,也需要时间重新适应,才能再次完成相同任务。数据建模也是类似的道理------我们可能需要"忘掉"以前依赖的一些方法,才能建立更好的图数据模型。你可以在这里了解更多关于该实验的内容:sfa.cems.umn.edu/neural-plas...
接下来,我们来看现实生活中数据的使用方式,了解是否存在其他思路,有助于构建更好的图数据模型。
例如,考虑图书馆或书店,理解数据或信息的使用如何驱动图书的摆放。在图书馆中,书籍按类别和作者姓氏排列,这类似于我们利用索引查找数据。但图书馆入口处通常会有新书和畅销书专区,方便读者快速找到这些书。在关系型数据库中模拟这样的灵活布局较为困难,而Neo4j的图数据库通过多标签(multiple labels)功能,使这类需求变得轻松实现。这让图数据库能够帮助我们构建便于高效数据消费的数据模型。使用图时,我们可能需要调整思维,尝试不同的数据建模方法。初期方案可能并不完美,但通过不断调整,最终能够获得符合需求的可用数据模型。
传统RDBMS及其他技术中,数据模型较为固定,设计不当可能带来较大影响。而Neo4j的可选灵活模式(schema)则让我们能够从非最优模型开始,逐步调优,无需重头开始,这也是Neo4j的优势所在。
接下来,我们将用一些简单数据分别在RDBMS和图数据库中尝试建模。我们要建模的数据如下:
-
一个人,需包含以下必填信息:
- firstName(名字)
- lastName(姓氏)
-
该人住过的五个租住地址,格式为:
- Address line 1(地址第一行)
- City(城市)
- State(州)
- zipCode(邮编)
- fromTime(入住时间)
- tillTime(离开时间)
虽然数据看似简单,但足以帮助我们理解在RDBMS和图数据库中表达该数据的细节差异。
我们想用这份数据回答以下问题:
- 名叫John Doe的人最新居住在哪个地址?
- John Doe最早住过哪个地址?
- John Doe住过的第三个地址是哪个?
接下来,我们先看看如何在RDBMS中建模这些数据。
关系型数据库(RDBMS)数据建模
本节将探讨之前定义的示例数据在关系型数据库中的建模方法。下图展示了该数据模型的实体-关系(ER)图:
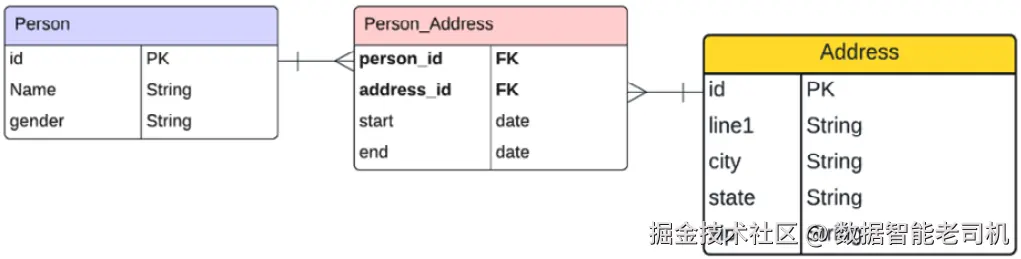
该数据模型包含三个表:
- Person 表存储人员详细信息;
- Address 表存储地址信息;
- Person_Address 表存储租住详情,并引用Person和Address表。
我们使用这个关联表来表示租住详情,避免重复存储Person或Address实体的数据。构建这些数据模型时,需要格外注意细节,因为修改模型可能非常耗时,尤其是涉及拆分表格时,数据迁移工作量巨大。
你可以参考这个教程创建SQLite数据库:datacarpentry.org/sql-socials...。我们将使用该SQLite数据库加载数据,并验证SQL查询以回答之前定义的问题。
下面是创建表的SQL脚本:
sql
-- Person表定义
CREATE TABLE IF NOT EXISTS person (
id INTEGER PRIMARY KEY,
name varchar(100) NOT NULL,
gender varchar(20),
UNIQUE(id)
);
-- Address表定义
CREATE TABLE IF NOT EXISTS address (
id INTEGER PRIMARY KEY,
line1 varchar(100) NOT NULL,
city varchar(20) NOT NULL,
state varchar(20) NOT NULL,
zip varchar(20) NOT NULL,
UNIQUE(id)
);
-- Person_Address表定义
CREATE TABLE IF NOT EXISTS person_address (
person_id INTEGER NOT NULL,
address_id INTEGER NOT NULL,
start varchar(20) NOT NULL,
end varchar(20),
FOREIGN KEY (person_id) REFERENCES person (id)
ON DELETE CASCADE ON UPDATE NO ACTION,
FOREIGN KEY (address_id) REFERENCES address (id)
ON DELETE CASCADE ON UPDATE NO ACTION
);下面是向表中插入数据的SQL脚本:
sql
-- 插入Person记录
INSERT INTO person (id, name, gender) VALUES (1, 'John Doe', 'Male');
-- 插入Address记录
INSERT INTO address (id, line1, city, state, zip) VALUES (1, '1 first ln', 'Edison', 'NJ', '11111');
INSERT INTO address (id, line1, city, state, zip) VALUES (2, '13 second ln', 'Edison', 'NJ', '11111');
INSERT INTO address (id, line1, city, state, zip) VALUES (3, '13 third ln', 'Edison', 'NJ', '11111');
INSERT INTO address (id, line1, city, state, zip) VALUES (4, '1 fourth ln', 'Edison', 'NJ', '11111');
INSERT INTO address (id, line1, city, state, zip) VALUES (5, '5 other ln', 'Edison', 'NJ', '11111');
-- 插入Person_Address(租住)记录
INSERT INTO person_address (person_id, address_id, start, end) VALUES (1, 1, '2001-01-01', '2003-12-31');
INSERT INTO person_address (person_id, address_id, start, end) VALUES (1, 2, '2004-01-01', '2008-12-31');
INSERT INTO person_address (person_id, address_id, start, end) VALUES (1, 3, '2009-01-01', '2015-12-31');
INSERT INTO person_address (person_id, address_id, start, end) VALUES (1, 4, '2016-01-01', '2020-12-31');
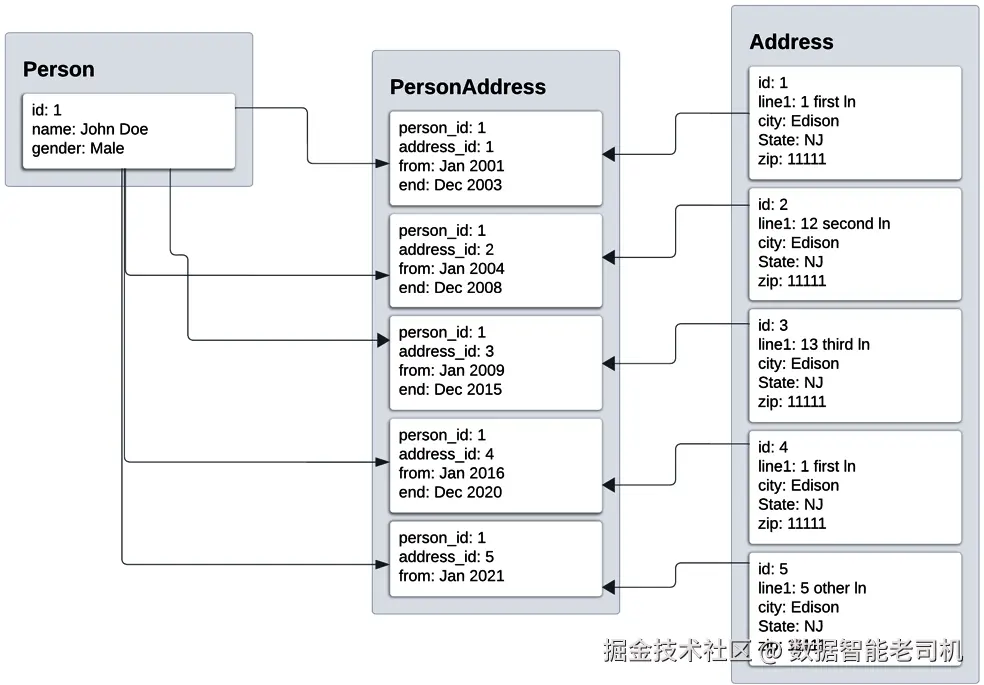
INSERT INTO person_address (person_id, address_id, start, end) VALUES (1, 5, '2021-01-01', NULL);加载数据后,表中的内容将如下所示。
现在我们来看如何从关系型数据库(RDBMS)中查询数据:
查询1 --- 获取最新地址
以下SQL查询用于回答第一个问题:
css
SELECT line1, city, state, zip
FROM person p, person_address pa, address a
WHERE p.name = 'John Doe'
AND pa.person_id = p.id
AND pa.address_id = a.id
AND pa.end IS NULL从查询中可以看出,我们依赖end字段为NULL来判断最新的地址。这是SQL查询中确定最新地址的逻辑。
查询2 --- 获取第一个地址
以下SQL查询用于回答第二个问题:
css
SELECT line1, city, state, zip
FROM person p, person_address pa, address a
WHERE p.name = 'John Doe'
AND pa.person_id = p.id
AND pa.address_id = a.id
ORDER BY pa.start ASC
LIMIT 1这里我们通过"搜索-排序-过滤"的模式,结合start字段升序排序,并取第一条记录,获取最早的地址。
查询3 --- 获取第三个地址
以下SQL查询用于回答第三个问题:
css
SELECT line1, city, state, zip
FROM person p, person_address pa, address a
WHERE p.name = 'John Doe'
AND pa.person_id = p.id
AND pa.address_id = a.id
ORDER BY pa.start ASC
LIMIT 2, 1同样,这条查询也遵循"搜索-排序-过滤"的模式,通过start字段排序,并跳过前两条,取第三条记录。
接下来,我们将看看如何用图数据库来建模这些数据。
图数据建模:基本方法
为了便于说明,我们将采用最常见且最简单的方式来对这些数据进行图形建模。

这与我们用英语表达信息的方式一致:
Person lives at Address
在这个句子中,名词被表示为节点,动词被表示为关系。这种数据建模方式非常简单,几乎类似于关系型数据库中ER图的表示。唯一不同的是,表示租住信息的关联表在这里被建模成了关系。
这种数据持久化方式的优势在于降低了索引查找的成本。在关系型数据库中,数据检索中最大开销通常来自关联表的索引查找。随着数据量的增加,这部分成本会持续上升。而采用图模型的这种方法,可以有效减少这一成本。
备注
如果你使用Neo4j Desktop,可以参考此教程创建Neo4j数据库:neo4j.com/docs/deskto...。 或者,你也可以使用云端数据库教程:neo4j.com/docs/aura/a...。该服务提供免费方案,适合不希望或无法在本地安装Neo4j Desktop的用户。Neo4j Aura是一个全托管的图数据库即服务解决方案。
下面通过示例的图查询来理解这一点。
以下Cypher脚本为加快数据加载和检索创建索引,可以看作是模式(schema)定义:
sql
CREATE CONSTRAINT person_id_idx FOR (n:Person) REQUIRE n.id IS UNIQUE;
CREATE CONSTRAINT address_id_idx FOR (n:Address) REQUIRE n.id IS UNIQUE;
CREATE INDEX person_name_idx FOR (n:Person) ON n.name;该脚本创建了两个唯一约束,确保不会出现重复的Person和Address节点。同时,增加了基于姓名的索引,加速人员查询。
模式设置完成后,可以用以下Cypher脚本将数据加载进Neo4j:
php
CREATE (p:Person {id:1, name:'John Doe', gender:'Male'})
CREATE (a1:Address {id:1, line1:'1 first ln', city:'Edison', state:'NJ', zip:'11111'})
CREATE (a2:Address {id:2, line1:'13 second ln', city:'Edison', state:'NJ', zip:'11111'})
CREATE (a3:Address {id:3, line1:'13 third ln', city:'Edison', state:'NJ', zip:'11111'})
CREATE (a4:Address {id:4, line1:'1 fourth ln', city:'Edison', state:'NJ', zip:'11111'})
CREATE (a5:Address {id:5, line1:'5 other ln', city:'Edison', state:'NJ', zip:'11111'})
CREATE (p)-[:HAS_ADDRESS {start:'2001-01-01', end:'2003-12-31'}]->(a1)
CREATE (p)-[:HAS_ADDRESS {start:'2004-01-01', end:'2008-12-31'}]->(a2)
CREATE (p)-[:HAS_ADDRESS {start:'2009-01-01', end:'2015-12-31'}]->(a3)
CREATE (p)-[:HAS_ADDRESS {start:'2016-01-01', end:'2020-12-31'}]->(a4)
CREATE (p)-[:HAS_ADDRESS {start:'2021-01-01'}]->(a5)数据加载完成后,在图数据库中将呈现如下结构。
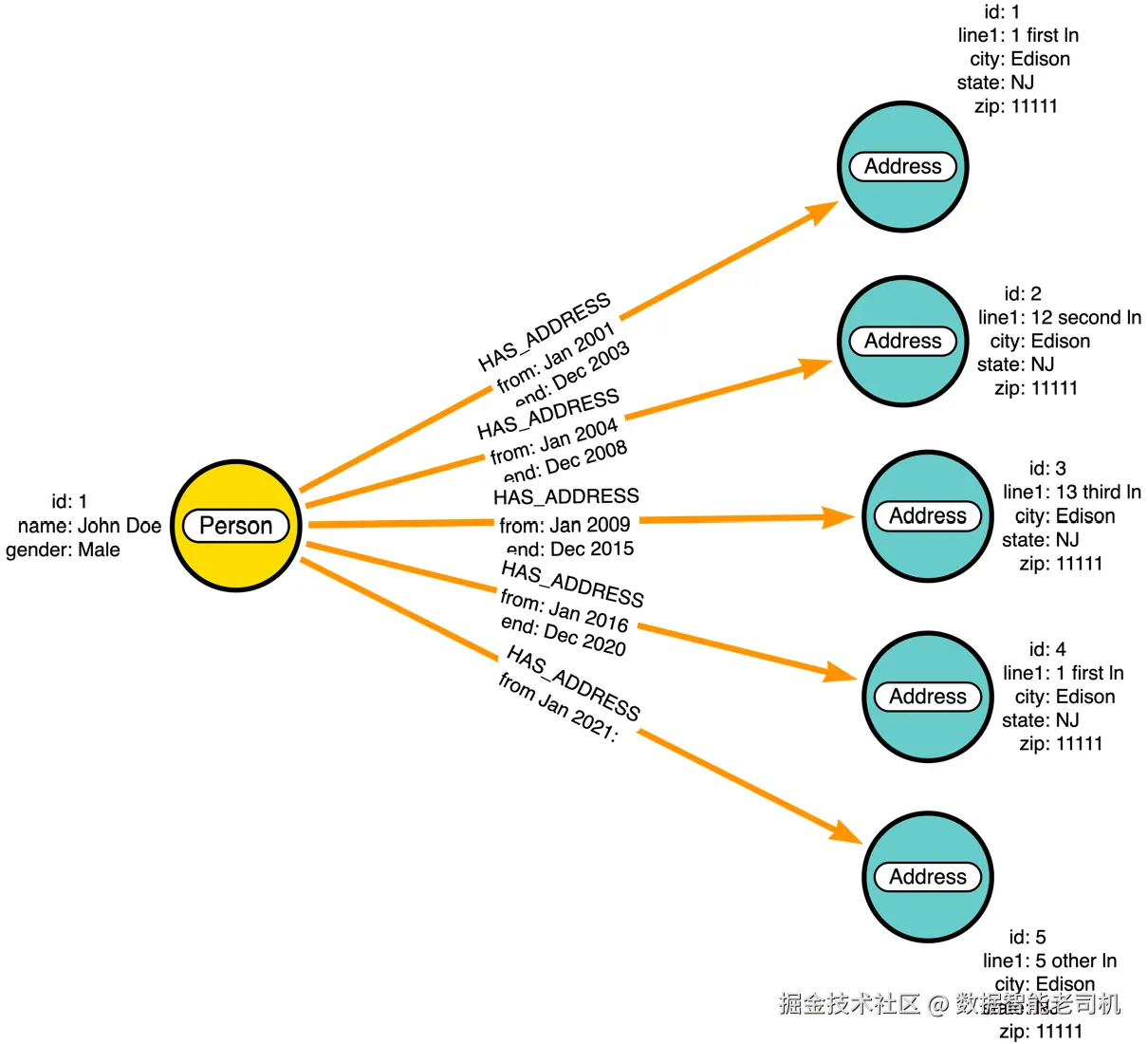
现在,我们将编写与上一节中RDBMS查询对应的Cypher查询:
查询1 --- 获取最新地址
以下Cypher查询获取John Doe的最新地址:
css
MATCH (p:Person {name:'John Doe'})-[r:HAS_ADDRESS]->(a)
WHERE r.end IS NULL
RETURN a可以看到,这条查询比之前的SQL查询更简洁。但结果仍依赖于我们如何标记最后一个地址,即关系上没有设置end属性。换句话说,确定最新地址的逻辑依然在查询中,就像SQL查询一样。
我们也注意到,SQL中对关联表的索引访问如下:
ini
AND pa.person_id = p.id
AND pa.address_id = a.id避免这些索引查找本身就能提升性能。
查询2 --- 获取第一个地址
下面的Cypher查询返回第一个地址:
css
MATCH (p:Person {name:'John Doe'})-[r:HAS_ADDRESS]->(a)
WITH r, a
ORDER BY r.start ASC
WITH r, a
RETURN a
LIMIT 1与SQL查询类似,这条查询使用"搜索-排序-过滤"的模式来定位所需数据。确定第一个地址的逻辑也包含在Cypher查询中。
查询3 --- 获取第三个地址
以下Cypher查询获取第三个地址:
css
MATCH (p:Person {name:'John Doe'})-[r:HAS_ADDRESS]->(a)
WITH r, a
ORDER BY r.start ASC
WITH r, a
RETURN a
SKIP 2
LIMIT 1与前一个查询类似,我们依然使用"搜索-排序-过滤"模式来获取目标数据。确定第三个地址的逻辑在Cypher查询中体现。
接下来,我们将深入探讨更细致的图数据建模方法。
图数据建模:高级方法
我们将以不同的视角来看待这些数据,并构建相应的数据模型。该模型受到我们对数据使用方式的影响。
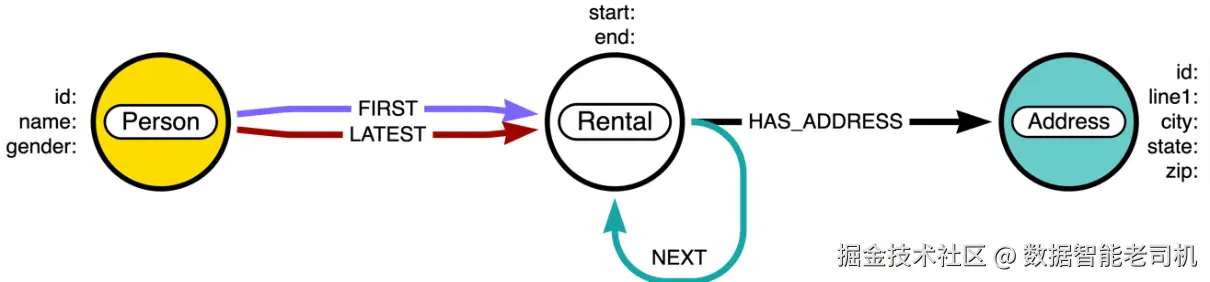
乍一看,这个模型看起来更接近于关系型数据库的实体-关系(ER)图。我们有Person、Address和Rental节点。但相似之处就到这里为止了。我们可以看到,Person通过FIRST或LATEST关系连接到Rental节点。Rental节点之间可能存在NEXT关系,表示租住顺序。Rental节点还连接到一个Address节点。这个模型看起来可能有些复杂,但当我们加载数据并观察它们的连接方式后,会更加清晰。
下面的Cypher脚本为加快数据加载和检索设置索引:
sql
CREATE CONSTRAINT person_id_idx FOR (n:Person) REQUIRE n.id IS UNIQUE;
CREATE CONSTRAINT address_id_idx FOR (n:Address) REQUIRE n.id IS UNIQUE;
CREATE INDEX person_name_idx FOR (n:Person) ON n.name;可以看到,这些索引与之前模型中相同。我们并没有为Rental节点添加任何索引或约束。
下面的Cypher脚本将数据加载到Neo4j中:
css
CREATE (p:Person {id:1, name:'John Doe', gender:'Male'})
CREATE (a1:Address {id:1, line1:'1 first ln', city:'Edison', state:'NJ', zip:'11111'})
CREATE (a2:Address {id:2, line1:'13 second ln', city:'Edison', state:'NJ', zip:'11111'})
CREATE (a3:Address {id:3, line1:'13 third ln', city:'Edison', state:'NJ', zip:'11111'})
CREATE (a4:Address {id:4, line1:'1 fourth ln', city:'Edison', state:'NJ', zip:'11111'})
CREATE (a5:Address {id:5, line1:'5 other ln', city:'Edison', state:'NJ', zip:'11111'})
CREATE (p)-[:FIRST]->(r1:Rental {start:'2001-01-01', end:'2003-12-31'})-[:HAS_ADDRESS]->(a1)
CREATE (r1)-[:NEXT]->(r2:Rental {start:'2004-01-01', end:'2008-12-31'})-[:HAS_ADDRESS]->(a2)
CREATE (r2)-[:NEXT]->(r3:Rental {start:'2009-01-01', end:'2015-12-31'})-[:HAS_ADDRESS]->(a3)
CREATE (r3)-[:NEXT]->(r4:Rental {start:'2016-01-01', end:'2020-12-31'})-[:HAS_ADDRESS]->(a4)
CREATE (r4)-[:NEXT]->(r5:Rental {start:'2021-01-01'})-[:HAS_ADDRESS]->(a5)
CREATE (p)-[:LATEST]->(r5)数据加载完成后,在图数据库中将呈现如下结构(见图3.7)。
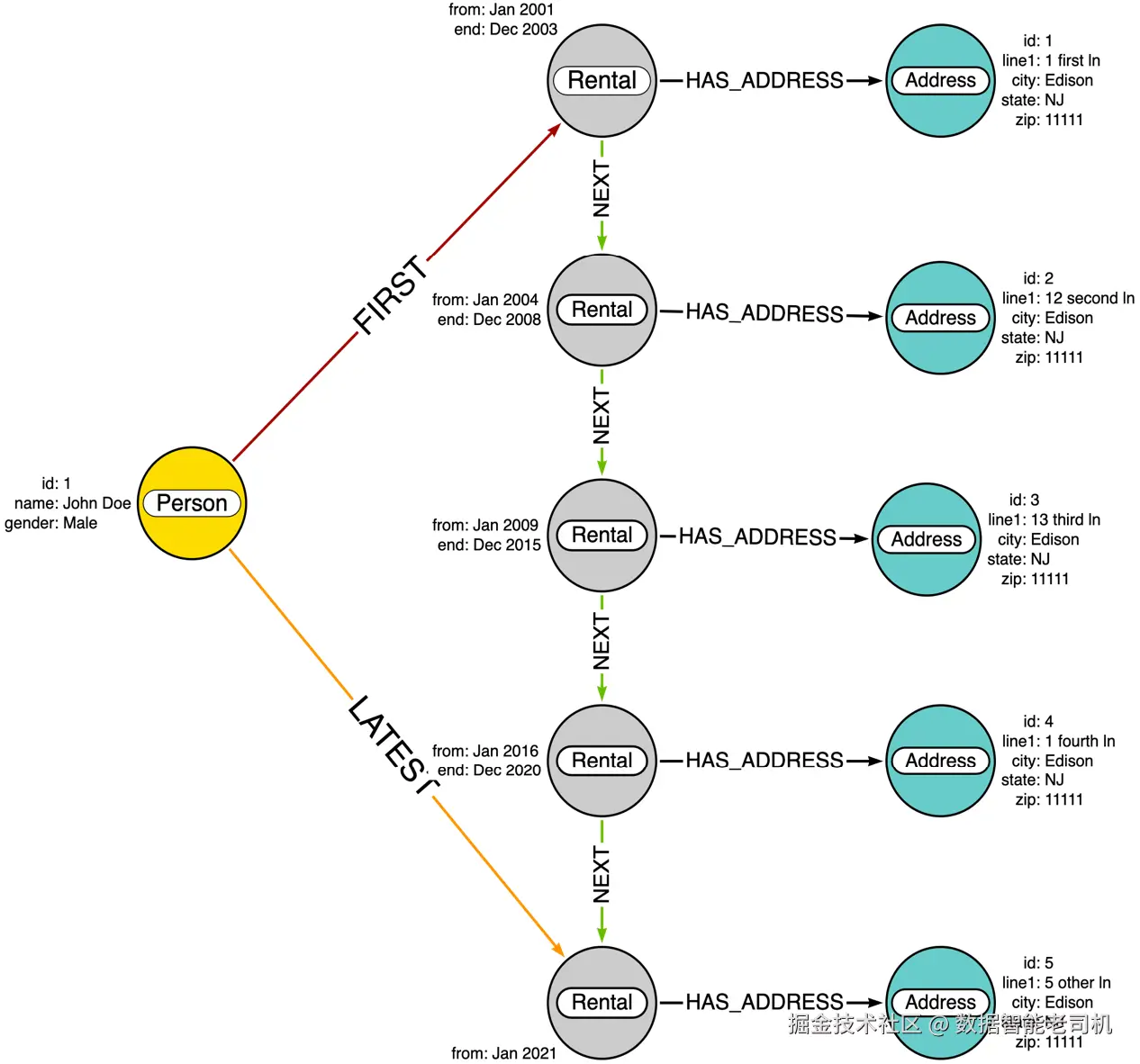
我们可以看到,图中存储的数据与之前大不相同。Person节点仅与第一个和最后一个租住节点相连,而这两个租住节点之间通过一系列的NEXT关系依次连接:
查询1 --- 获取最新地址
以下Cypher查询获取最新地址:
css
MATCH (p:Person {name:'John Doe'})-[:LATEST]->()-[:HAS_ADDRESS]->(a)
RETURN a可以看到,这条查询与之前的图模型和SQL查询有很大不同。在之前的图模型中,Cypher查询与SQL查询类似,都通过判断最后一个地址的逻辑来获取最新地址。而这里的查询更像英语句子"Person's latest address"(某人的最新地址)。
虽然这条查询对于大多数人来说更简单易懂,但以这种方式表示数据是否值得?在这种场景下,我们会使用更多存储空间来详细表达数据。接下来,让我们对比初始图数据模型与当前数据模型的查询性能,看看这种建模是否有优势。

从查询性能分析来看,初始的图数据模型执行该操作时,进行了18次数据库访问(db hits),占用了312字节内存;而当前的图数据模型执行同样操作时,只需12次数据库访问,内存占用仍为312字节。可以看出,新模型能更高效地执行该查询。随着数据规模增长,之前的图模型执行时间会增加,数据库访问次数会随着该人物的关系数量线性增长;而当前模型的访问次数则相对保持稳定。
接下来,我们来看查询2。
查询2 --- 获取第一个地址
以下Cypher查询获取第一个地址:
css
MATCH (p:Person {name:'John Doe'})-[:FIRST]->()-[:HAS_ADDRESS]->(a)
RETURN a这条查询与前一条几乎相同,只是遍历的关系不同。这里不再使用"搜索-排序-过滤"的模式,这是该数据模型的最大优势。该模型使得我们可以更方便地利用图结构来检索数据,同时也意味着确定目标数据的逻辑不必通过查询中的属性比较来实现。
让我们对比这两个查询的性能,看看是否能带来优势。
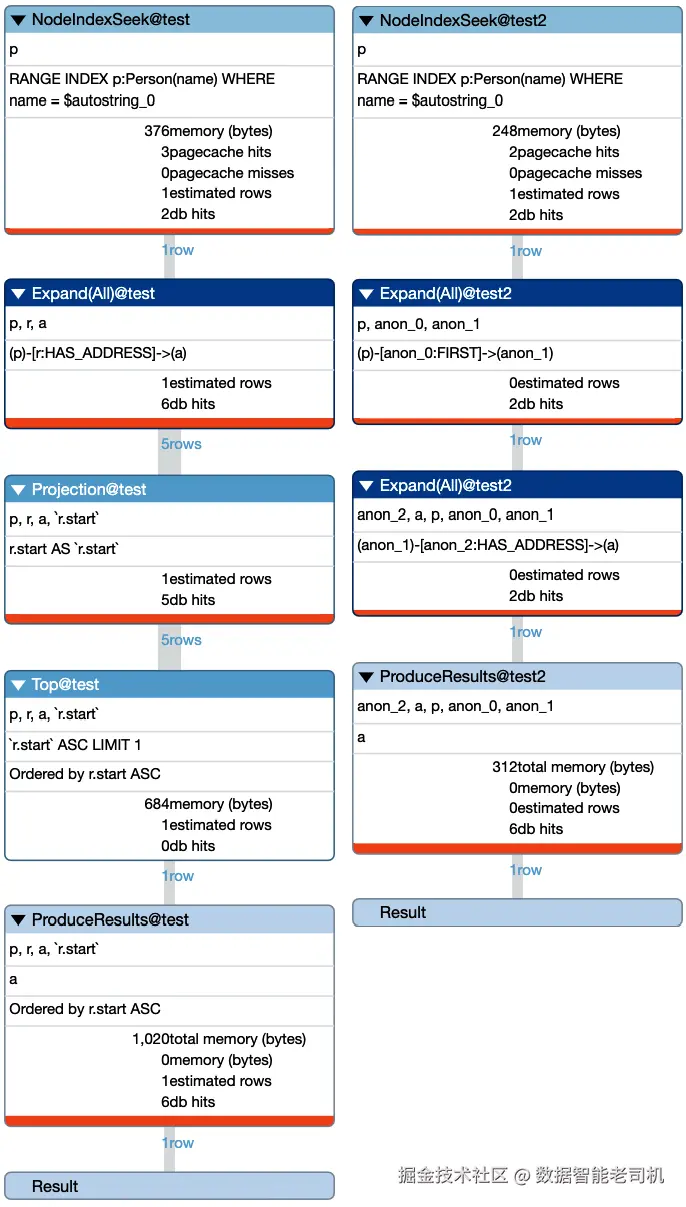
我们可以看到,初始图数据模型的查询执行计划比当前数据模型更大、更复杂。使用初始图数据模型执行该操作时,进行了19次数据库访问,消耗了1020字节内存。而当前数据模型的执行计划几乎与查询1相似,进行了12次数据库访问,消耗了312字节内存。由此可见,排序操作导致了更多内存使用和更高的CPU消耗。随着Person节点连接的地址增多,初始图数据模型的内存和数据库访问次数会增加,性能逐渐下降;而当前模型的性能则相对保持稳定。
查询3 --- 获取第三个地址
以下Cypher查询获取第三个地址:
css
MATCH (p:Person {name:'John Doe'})-[:FIRST]->()-[:NEXT*2..2]->()-[:HAS_ADDRESS]->(a)
RETURN a从查询中可以看到,它是先遍历到第一个租住节点,然后跳过接下来的一个租住节点,最终到达第三个租住节点。这种查询方式符合我们通常看待数据的习惯,表达方式也很自然。同样,这里没有依赖"搜索-排序-过滤"的模式。让我们对比这些查询的性能,看这种写法是否带来优势。
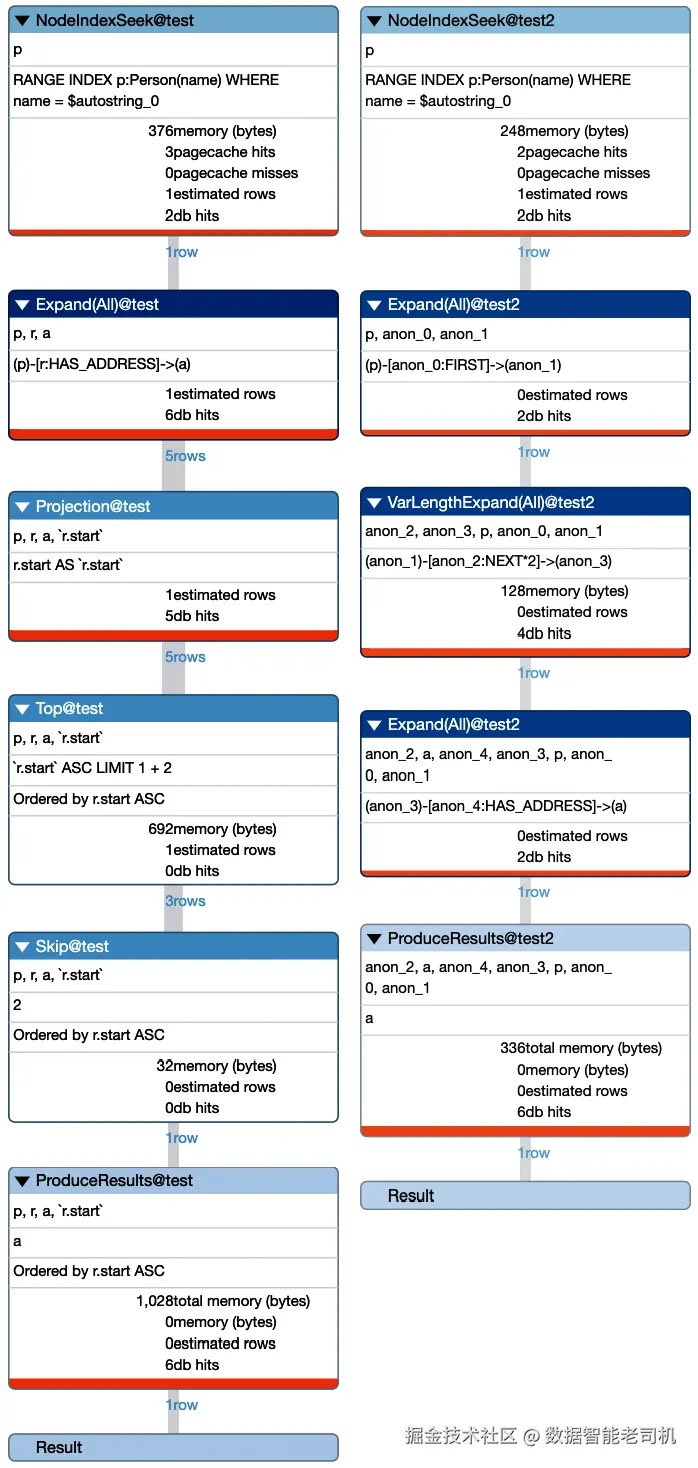
从这些性能分析来看,当前数据模型的查询相比之前的查询稍显复杂。初始图数据模型执行该操作时进行了19次数据库访问,消耗了1028字节内存;而当前图数据模型则进行了16次数据库访问,消耗336字节内存。
备注
查询性能分析是理解查询工作原理的最佳方式。如果对查询性能不满意,性能分析能帮助我们识别需要优化或调整的环节,从而提升性能。更多内容可参阅:neo4j.com/docs/cypher...。
通过分析查询和数据模型,我们可以看到,重新审视数据模型的定义方式,对性能和执行同样操作的成本有着巨大影响。
当前数据模型的另一个优势是,如果我们想从地址的角度追踪租赁情况,可以在同一地址的多个租赁节点间添加另一种关系,比如NEXT_RENTAL,以提供对同一数据的不同视角。在关系型数据库或其他数据持久化层中,实现这样的数据表达则相对困难。Neo4j凭借其灵活性------能够持久化关系以避免关联索引开销,以及可选的灵活模式设计,更适合构建知识图谱。
良好的图数据模型能提升RAG流程中检索器的效率,加快并简化相关数据的检索,正如我们在这里所探讨的。
接下来,我们将看看如何将知识图谱作为RAG流程的一部分加以利用。
结合RAG与Neo4j知识图谱的力量------GraphRAG
在上一章中,我们了解了检索器,它是RAG流程的核心。检索器利用数据存储来获取相关信息,提供给大型语言模型(LLMs),从而得到对我们问题的最佳回答。检索器可以根据需要连接各种数据存储,而数据存储的能力极大地决定了检索信息的有用性、速度和效果。这正是图数据库发挥重要作用的地方,也促成了GraphRAG的诞生。
备注
你可以在以下链接了解更多关于GraphRAG及其高效性的内容:www.microsoft.com/en-us/resea... 以及 microsoft.github.io/graphrag/ 。
若想全面理解GraphRAG,可以参考微软的研究论文《From Local to Global: A Graph RAG Approach to Query-Focused Summarization》(arxiv.org/abs/2404.16...)。此外,微软已在GitHub上开源GraphRAG项目(github.com/microsoft/g...),提供了实现该方法的资源和工具。
Neo4j图数据库擅长将数据以属性图的形式持久化,包含节点和关系,使得以直观方式存储和检索数据变得简单,成为RAG检索器的数据存储利器。这种方式能够支持更准确、具备上下文感知且可靠的AI驱动应用。
接下来,我们将构建一个结合RAG与知识图谱优势的GraphRAG流程,以提升大型语言模型的响应效果。
GraphRAG:用Neo4j增强RAG模型
在上一章中,我们讨论了基于RAG模型的聊天应用中的信息流(见图3.5)。
现在,我们将看到如何增强该工作流程,以为聊天应用生成更优质的响应。图3.11展示了GraphRAG的工作流程,其中用户的提示语通过LLM API处理,从Neo4j中检索相关信息,然后与提示语合并,最后发送给LLM API进行生成。
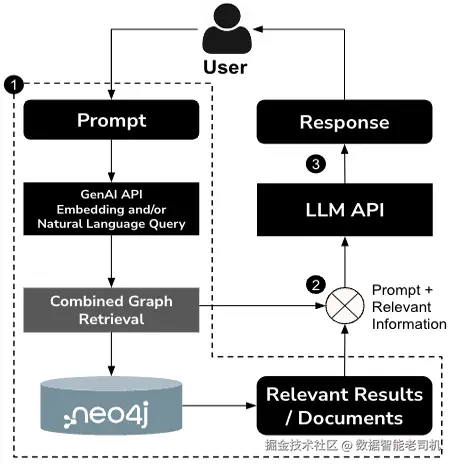
LLM API 会结合用户的提示语和来自 Neo4j 知识图谱的相关信息生成响应,为用户提供准确且具有上下文丰富性的结果。通过融合 Neo4j 和 RAG 模型的能力,GraphRAG 利用更多的领域上下文提升了响应的相关性。
接下来,我们将构建一个简单的图谱来演示 GraphRAG 流程。
为RAG集成构建知识图谱
本示例中,我们使用有限的数据进行演示,重点关注电影及其剧情。
Python示例代码:在Neo4j中设置知识图谱
通过以下代码示例,你将学习如何搭建Neo4j数据库,定义节点和关系,并使用Cypher执行基本查询:
-
准备Neo4j数据库
运行代码前,请确保你有可用的Neo4j数据库,可以选择以下方式:
- Neo4j Desktop:本地安装运行(下载地址:neo4j.com/download/)
- Neo4j AuraDB:云端托管方案(了解详情:neo4j.com/product/aur...) 启动数据库实例,并记录连接凭证(URI、用户名和密码)。
-
安装必要的Python库
需要以下Python库:
-
Neo4j Python Driver:用于与数据库交互
-
Pandas:用于数据结构处理与分析
安装命令:pip install neo4j pandas
-
-
连接数据库并建立知识图谱
在Neo4j数据库启动且Python库安装完毕后,可以使用下面的Python脚本搭建简单的知识图谱。本例中创建一个IMDb电影及其剧情的图谱,节点表示电影和剧情,关系表示剧情归属的电影。
备注
本示例不使用外部数据集,而采用硬编码数据以展示图模型和GraphRAG流程。完整的数据加载和GraphRAG流程将在第4章和第5章介绍。此示例仅演示GraphRAG流程的关键环节。
构建简单图谱展示Neo4j在GraphRAG流程中的作用
python
from neo4j import GraphDatabase
uri = "bolt://localhost:7687" # 替换为你的Neo4j URI
username = "neo4j" # 替换为你的Neo4j用户名
password = "password" # 替换为你的Neo4j密码
def create_graph(tx):
tx.run("CREATE (m:Movie {title: 'The Matrix', year: 1999})")
# ...
# 创建剧情节点
tx.run("CREATE (p:Plot {description: 'A computer hacker learns from mysterious rebels about the true nature of his reality and his role in the war against its controllers.'})")
# 创建关系
tx.run("""
MATCH (m:Movie {title: 'The Matrix'}),
(p:Plot {description: 'A computer hacker learns from mysterious rebels about the true nature of his reality and his role in the war against its controllers.'})
CREATE (m)-[:HAS_PLOT]->(p)
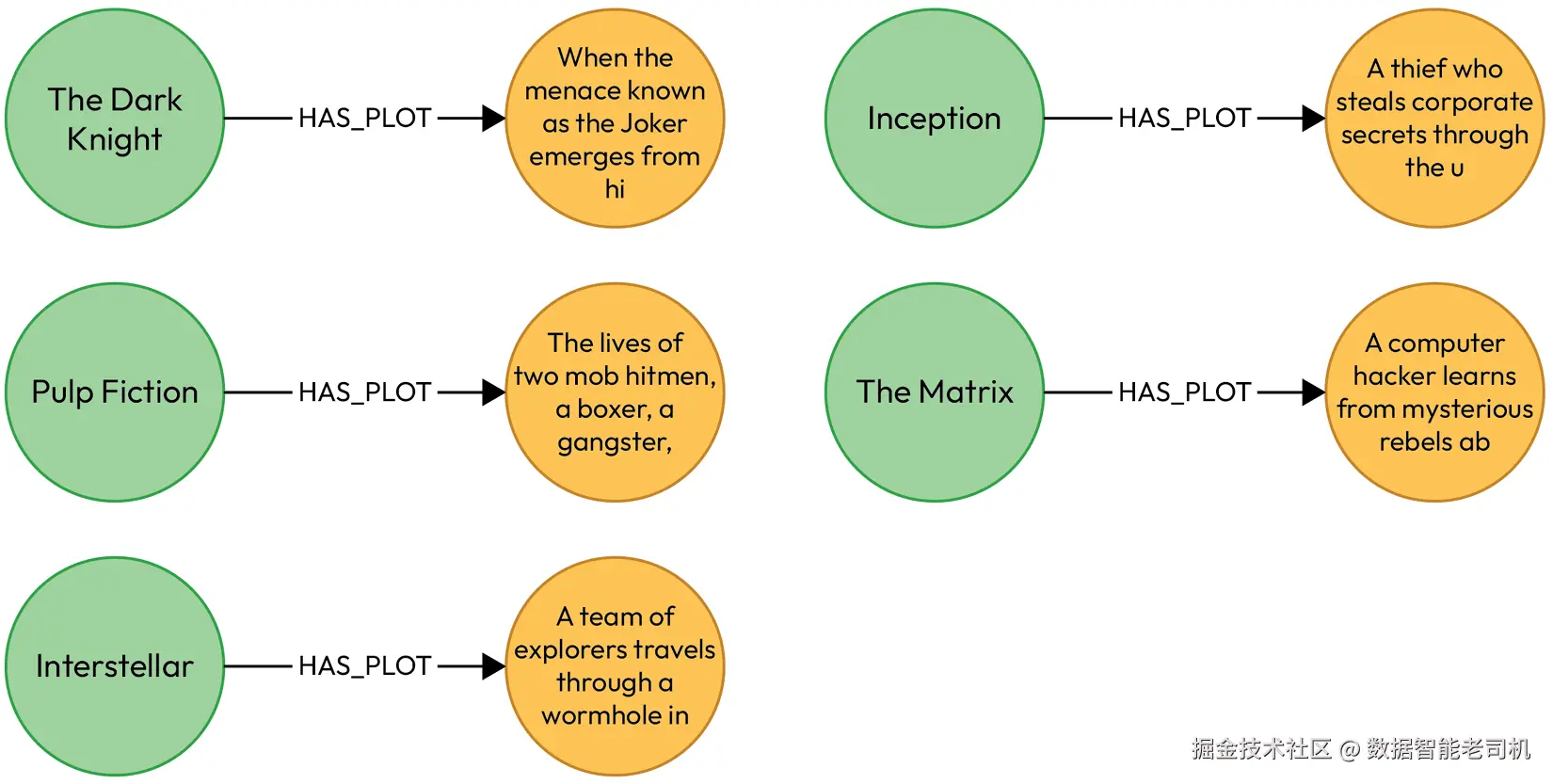
""")- 如果我们将创建的数据可视化,图形大致如图3.12所示:
less
MATCH p=(:Movie)-[:HAS_PLOT]->()
RETURN p
LIMIT 5通过这个简单示例,你可以理解Neo4j如何作为GraphRAG流程中的数据存储和检索核心。
- 现在,我们将使用Cypher查询来检索数据:
python
def query_graph(tx):
# 查询电影及其剧情
result = tx.run("""
MATCH (m:Movie)-[:HAS_PLOT]->(p:Plot)
RETURN m.title AS movie, m.year AS year, p.description AS plot
""")
# 打印查询结果
for record in result:
print(f"Movie: {record['movie']} ({record['year']}) - Plot: {record['plot']}")- 如果运行该代码,输出结果如下:
vbnet
Movie: The Matrix (1999) - Plot: A computer hacker learns from mysterious rebels about the true nature of his reality and his role in the war against its controllers.完整代码请访问:github.com/PacktPublis...。
现在,我们已经构建了基础图谱,接下来将其应用到GraphRAG流程中。
将RAG与Neo4j知识图谱集成
要将RAG模型与Neo4j集成,需要配置模型以查询图数据库。通常,这涉及搭建一个API或中间层,促进RAG模型与Neo4j之间的通信。
以下是一个示例集成流程:
用户输入:用户提供一个提示。在下面的代码示例中,提示在脚本中预定义为"The Matrix",用户可以修改以测试其他电影或提示:
ini
prompt = "The Matrix"查询生成:处理提示,生成Cypher查询,从Neo4j中检索相关信息。例如,查询电影剧情:
ini
query = f"""
MATCH (m:Movie)-[:HAS_PLOT]->(p:Plot)
WHERE m.title CONTAINS '{prompt}'
RETURN m.title AS title, m.year AS year, p.description AS plot
"""数据检索:执行Cypher查询,从知识图谱获取相关数据(如"The Matrix"的剧情):
python
with driver.session() as session:
result = session.run(query)
records = [
{
"title": record["title"],
"year": record["year"],
"plot": record["plot"],
}
for record in result if record["plot"] is not None
]
print(f"Retrieved Records: {records}") # 调试输出
return recordsRAG模型处理:将检索到的数据与原始提示结合,传入RAG模型继续处理,使模型生成更丰富、具备上下文的回答:
python
relevant_data = get_relevant_data(prompt)
if not relevant_data:
return "No relevant data found for the given prompt."
combined_input = (
f"Provide detailed information about: {prompt}. " +
" ".join([
f"{data['title']} ({data['year']}): {data['plot']}"
for data in relevant_data
])
)
print(f"Combined Input: {combined_input}")
if not combined_input.strip():
return "No relevant data to process for this prompt."
max_input_length = 512 - 50 # 留出输出空间
tokenized_input = tokenizer(combined_input, truncation=True,
max_length=max_input_length, return_tensors="pt")响应生成 :RAG模型基于丰富的提示生成回答,例如:"The plot of The Matrix is: 'A computer hacker learns from mysterious rebels about the true nature of his reality and his role in the war against its controllers.'":
ini
outputs = model.generate(
**tokenized_input,
max_length=150,
temperature=0.7,
top_k=50,
top_p=0.9,
num_beams=5,
no_repeat_ngram_size=3,
early_stopping=True
)
response = tokenizer.decode(outputs[0],
skip_special_tokens=True,
clean_up_tokenization_spaces=True)
return response示例输出:
vbnet
Prompt: The Matrix
Response: the matrix (1999): a computer hacker learns from mysterious rebels about the true nature of his reality and his role in the war against its controllers.本章完整代码请见:github.com/PacktPublis...。
注意
此代码片段仅适用于numpy版本低于2的环境。如果你使用numpy版本高于2,请在终端执行以下命令创建干净的虚拟环境,以避免兼容性问题:
bash
python3 -m venv my_env
source my_env/bin/activate
pip install numpy==1.26.4 neo4j transformers torch faiss-cpu datasets掌握了如何构建和查询基础知识图谱,以及如何将RAG模型与Neo4j集成后,你已经具备创建智能且具备上下文感知能力应用的基础技能。接下来,我们将介绍几种增强知识图谱的方法,这些概念将在后续章节中详细展开,助力智能应用的构建。
增强知识图谱
上一节我们学习了如何构建图谱及GraphRAG流程,所展示的是一个简单的图谱。为了使知识图谱更高效,我们可以采用以下几种方法。接下来,我们将介绍这些方法,并在后续章节中应用它们来增强我们的知识图谱:
- 本体构建(Ontology Development) :
本体可以定义图谱的结构和内容。将本体持久化到图中,可以让我们以更直观的方式解释数据及其关联关系,确保图谱遵循最佳实践并契合特定领域需求。本体还有助于不同数据集间保持一致性,并支持图谱的长期扩展。我们将在第5章中对本章创建的简单电影知识图谱进行增强。若想深入了解本体,可参考:neo4j.com/blog/ontolo...。 - 图数据科学(Graph Data Science,GDS) :
虽然图数据作为知识图谱本身已很有效,但还有一些方法能显著提升图的能力。例如,执行链路预测(link prediction)或社区检测(community detection),基于已有图数据推断节点间的新增关系,增强图中的智能信息,从而在查询时提供更精准的答案。我们将在第10章中使用KNN相似度和社区检测算法,提升图谱智能。
以上介绍了几种增强知识图谱的思路。现在,让我们总结一下对这些概念的理解。
总结
本章我们探讨了使用Neo4j构建知识图谱以集成RAG的基础内容。首先理解了Neo4j知识图谱的重要性及其在GraphRAG中的作用。随后,我们搭建了Neo4j数据库,创建了节点与关系,并执行查询以检索相关信息。
我们还介绍了RAG模型与Neo4j的集成工作流程。现在,你已经准备好进入第二部分------《将Haystack与Neo4j集成:构建AI驱动搜索的实用指南》。下一部分将在本章基础上展开,探索如何将Haystack与Neo4j结合,打造强大的AI搜索能力。这将自然延展你的知识和技能,助力你开发利用Haystack与Neo4j优势的复杂搜索应用。