文章目录
- 参考资料
- [一 AI Agent](#一 AI Agent)
- [二 ReAct](#二 ReAct)
- [三 LangGraph实现ReAct代理](#三 LangGraph实现ReAct代理)
-
- [3.1 SerperAPI实时联网搜索](#3.1 SerperAPI实时联网搜索)
- [3.2 ReAct实现](#3.2 ReAct实现)
参考资料
一 AI Agent
- AI Agent 整个过程是一个动态循环。Agent不断从环境中学习,通过其行动影响环境,然后根据环境的反馈继续调整其行动和策略。这种模式特别适用于那些需要理解和生成自然语言的应用场景,如聊天机器人、自动翻译系统或其他形式的自动化客户支持。
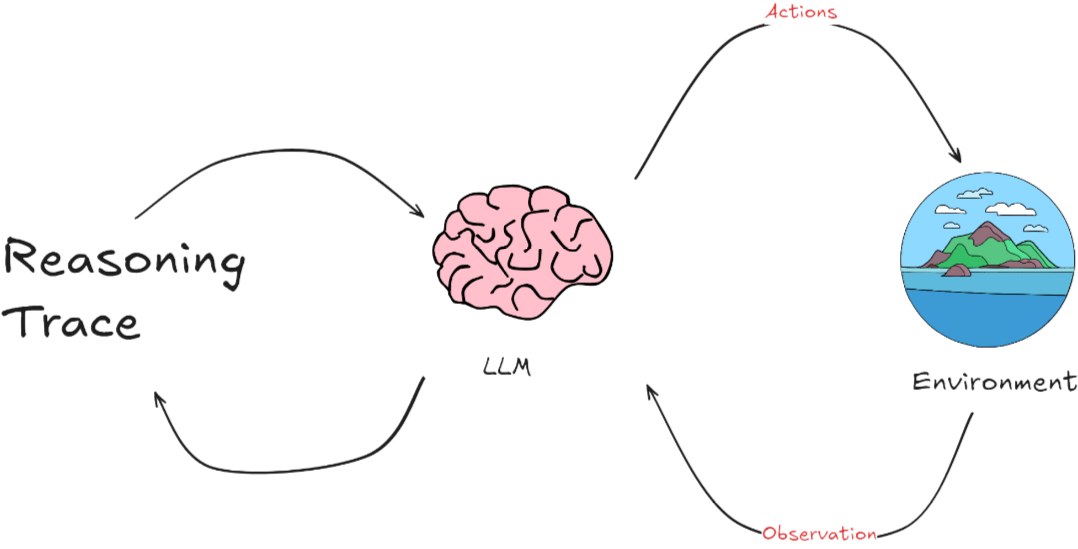
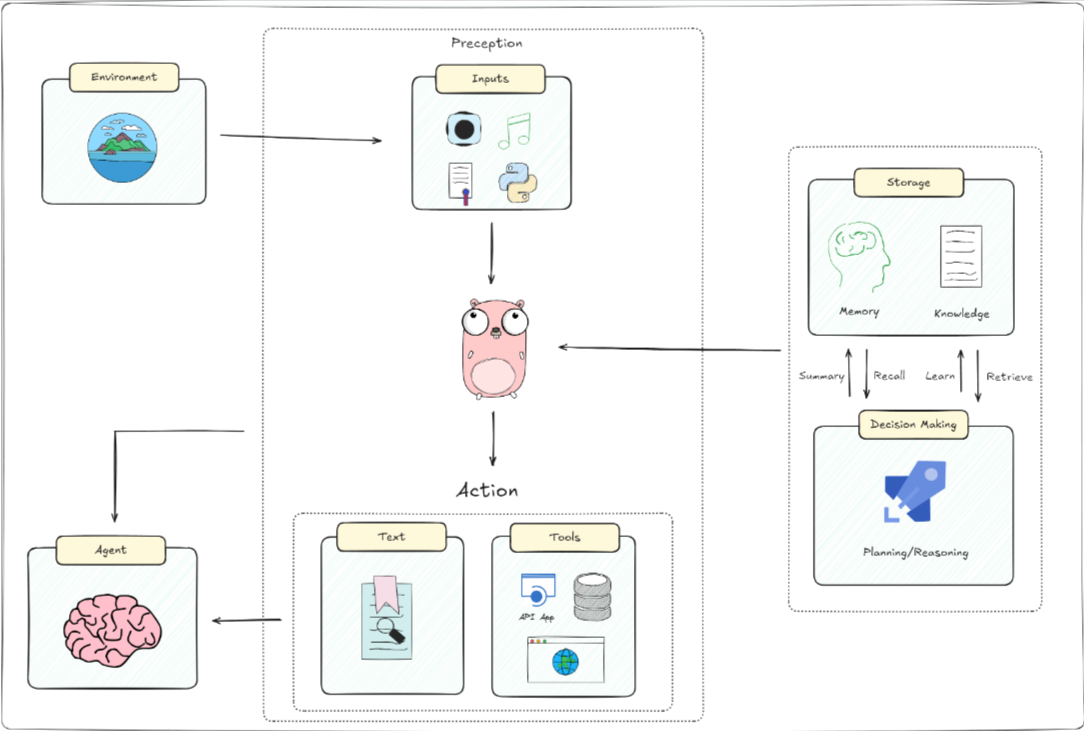
一个人工智能代理的基本架构,包括它与环境的互动、感知输入、大脑处理及其决策过程。具体来说:
- 环境(Environment): AI代理接收来自其周围环境的信息。环境可以是一个网站、数据库或任何其他类型的系统。
- 感知(Perception): 即输入。AI代理通过多种方式感知环境,如视觉(图像)、听觉(声音)、文本(文字信息)和其他传感器输入(如位置、温度等)。这些输入帮助代理理解当前的环境状态。
- 大脑(Brain):
- 存储(Storage) :
- 记忆(Memory):存储先前的经验和数据,类似于人类的记忆。
- 知识(Knowledge):包括事实、信息和代理用于决策的程序。
- 决策制定(Decision Making) :总结(Summary)、回忆(Recall)、学习(Learn)、检索(Retrieve):这些功能帮助AI在需要时回顾和利用存储的知识。
- 规划/推理(Planning/Reasoning):基于当前输入和存储的知识,制定行动计划。
- 行动(Action):代理基于其感知和决策过程产生响应或行动。这可以是物理动作、发送API请求、生成文本或其他形式的输出。
二 ReAct
- ReAct 代理可以处理顺序的多部分查询,同时通过将路由、查询规划和工具使用组合到单个实体中来维护状态(在内存中)。通过交叉推理和行动,ReAct 使智能体能够动态地在产生想法和特定于任务的行动之间交替。
- ReAct:Synergizing Reasoning and Acting in Language Models
- ReAct 框架有两个过程,由 Reason 和 Act 结合而来。从本质上讲,这种方法的灵感来自于人类如何通过和谐地结合思维和行动来执行任务。
- Reason基于一种推理技术------思想链(CoT)。 CoT是一种提示工程,通过将输入分解为多个逻辑思维步骤,帮助大语言模型执行推理并解决复杂问题。这使得大模型能够按顺序规划和解决任务的每个部分,从而更准确地获得最终结果。
- 分解问题:当面对复杂的任务时,CoT 方法不是通过单个步骤解决它,而是将任务分解为更小的步骤,每个步骤解决不同方面的问题。
- 顺序思维:思维链中的每一步都建立在上一步的结果之上。这样,模型就能从头到尾构造出一条逻辑推理链。
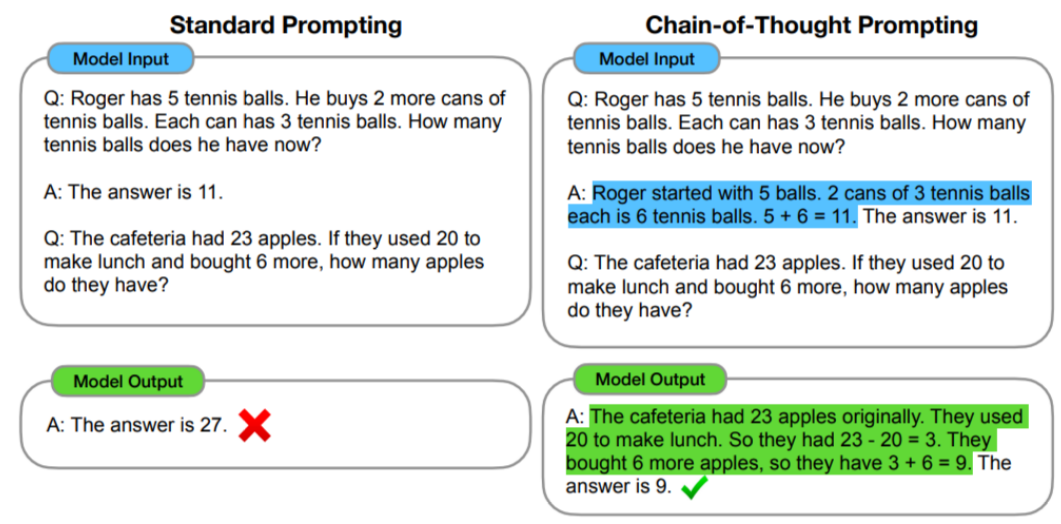
- 在 CoT 提示工程的限定下,大模型仍然会产生幻觉。因为经过长期的使用,大家发现在推理的中间阶段会产生不正确的答案或上下游的传播错误,所以,Google DeepMind 团队开发了ReAct的技术来弥补这一点。
- ReAct 采用的是 思想-行动-观察循环的思路,其中代理根据先前的观察进行推理以决定行动。这个迭代过程使其能够根据其行动的结果来调整和完善其方法。
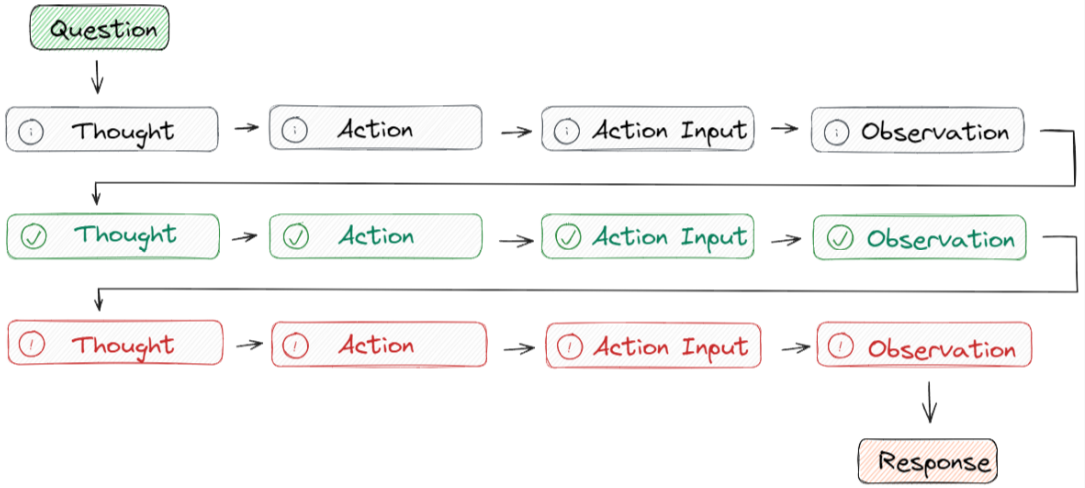
- Question指的是用户请求的任务或需要解决的问题。
- Thought用来确定要采取的行动并向大模型展示如何创建/维护/调整行动计划。
- Action Input是用来让大模型与外部环境(例如搜索引擎、维基百科)的实时交互,包括具有预定义范围的API。
- Observation是会观察执行操作结果的输出,重复此过程直至任务完成。
三 LangGraph实现ReAct代理
3.1 SerperAPI实时联网搜索
- Serper一个高性能的Google搜索APl,提供快速且成本效益高的方式访问Google搜索结果。在目前的应用落地产品中广泛被用于增强聊天机器人、进行搜索引擎优化(SEO)分析和简化金融科技项目等多种场景。该API具备:执行实时搜索、自定义查询位置、快速访问Google的搜索引擎结果等优势。
- 新用户注册具有2500次免费搜索额度,可以在Playground中自定义搜索配置。
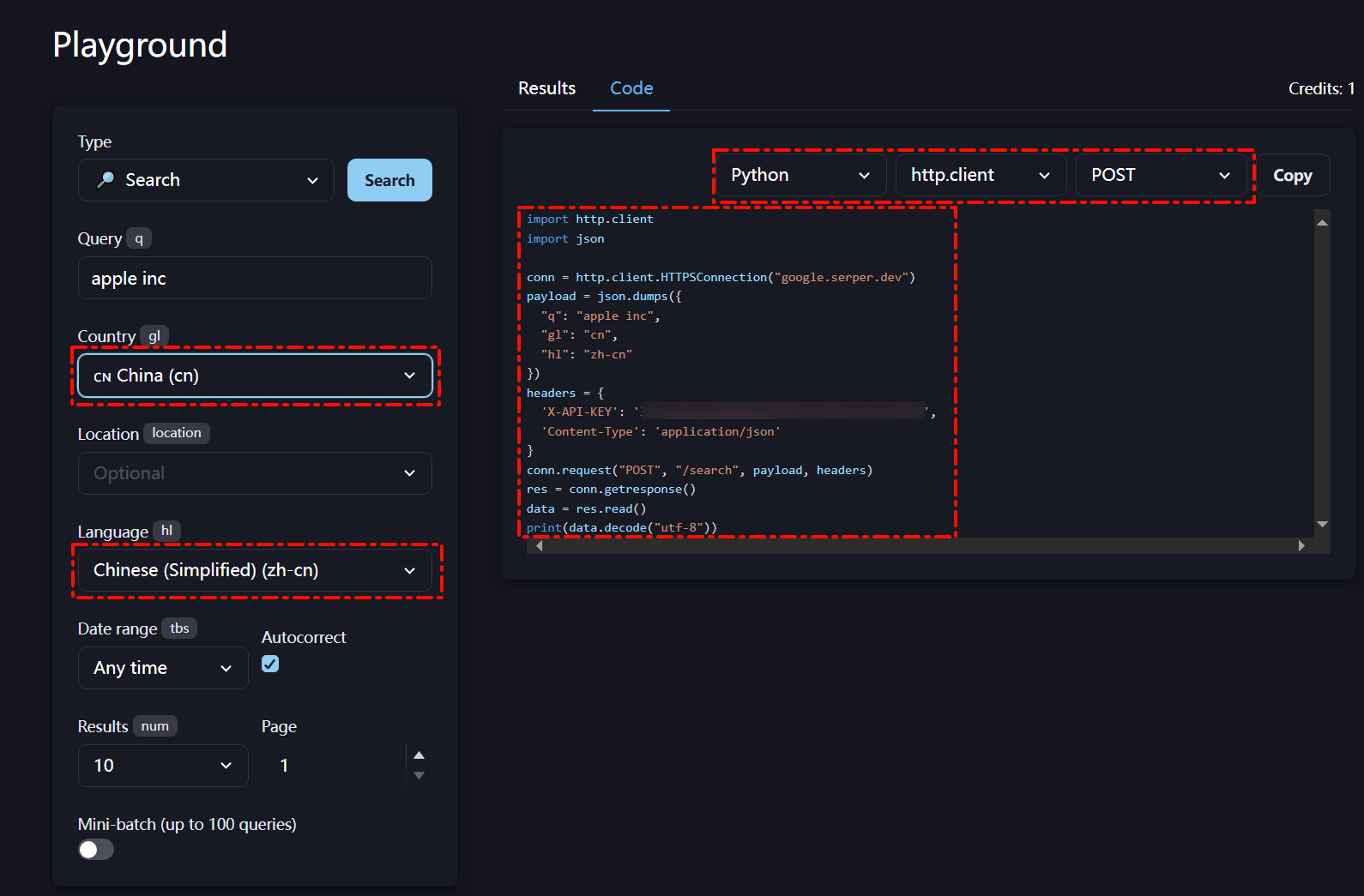
- 简单测试用例
python
import http.client
import json
conn = http.client.HTTPSConnection("google.serper.dev")
payload = json.dumps({
"q": "通义千问最新模型",
"gl": "cn",
"hl": "ny"
})
headers = {
'X-API-KEY': 'xxx',
'Content-Type': 'application/json'
}
conn.request("POST", "/search", payload, headers)
res = conn.getresponse()
data = res.read()
#print(data.decode("utf-8"))
data=json.loads(data.decode("utf-8"))# 将返回的JSON字符串转换为字典3.2 ReAct实现
- OpenAI 中转API key平台
- LLM Model使用gpt-4o
python
from typing import (Annotated,Sequence,TypedDict)
from langchain_core.messages import BaseMessage
from langgraph.graph.message import add_messages
from langchain_core.tools import tool
from typing import Union, Optional
from pydantic import BaseModel, Field
import json
import http.client
class AgentState(TypedDict):
"""代理状态"""
messages: Annotated[Sequence[BaseMessage], add_messages]
class SearchQuery(BaseModel):
"""SearchQuery 数据模型"""
query: str = Field(description="Questions for networking queries")
# 参数 args_schema=SearchQuery 表示使用 SearchQuery 模型来验证函数的输入参数
@tool(args_schema = SearchQuery)
def fetch_real_time_info(query):
"""获取互联网实时信息工具函数"""
conn = http.client.HTTPSConnection("google.serper.dev")
payload = json.dumps({
"q": query,
"gl": "cn",
"hl": "ny"
})
headers = {
'X-API-KEY': 'xxx',
'Content-Type': 'application/json'
}
conn.request("POST", "/search", payload, headers)
res = conn.getresponse()
data = res.read()
#print(data.decode("utf-8"))
data=json.loads(data.decode("utf-8"))# 将返回的JSON字符串转换为字典
if 'organic' in data:
return json.dumps(data['organic'], ensure_ascii=False) # 返回'organic'部分的JSON字符串
else:
return json.dumps({"error": "No organic results found"}, ensure_ascii=False) # 如果没有'organic'键,返回错误信息
#fetch_real_time_info.invoke({"query": "通义千问最新模型"})
#----------------------------
import os
from langchain_openai import ChatOpenAI
api_key="hk-xxx"
base_url="https://api.openai-hk.com/v1"
# 临时设置环境变量
os.environ["OPENAI_API_KEY"] = api_key
os.environ["OPENAI_BASE_URL"] = base_url
# 实例化模型
llm = ChatOpenAI(
api_key=api_key,
base_url=base_url,
model="gpt-4o"
)
# 绑定工具
tools = [fetch_real_time_info]
model = llm.bind_tools(tools)
# ----------------------------
import json
from langchain_core.messages import ToolMessage, SystemMessage, HumanMessage
from langchain_core.runnables import RunnableConfig
tools_by_name = {tool.name: tool for tool in tools}
# 定义工具节点
def tool_node(state: AgentState):
outputs = []
for tool_call in state["messages"][-1].tool_calls:
tool_result = tools_by_name[tool_call["name"]].invoke(tool_call["args"])
outputs.append(
ToolMessage(
content=json.dumps(tool_result),
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
)
return {"messages": outputs}
# 定义问答模型
def call_model(state: AgentState,):
system_prompt = SystemMessage(
"你是一个智能助手,请尽全力回答用户的问题"
)
response = model.invoke([system_prompt] + state["messages"])
return {"messages": [response]}
# 定义路由节点
def should_continue(state: AgentState):
messages = state["messages"]
last_message = messages[-1]
if not last_message.tool_calls:
return "end"
else:
return "continue"
# -----------------------------------
from langgraph.graph import StateGraph, END
from IPython.display import Image, display
# 定义一个图结构
workflow = StateGraph(AgentState)
# 在图结构中添加节点
workflow.add_node("agent", call_model)
workflow.add_node("tools", tool_node)
# 设置启动点是 agent
workflow.set_entry_point("agent")
# 添加路由边
workflow.add_conditional_edges(
"agent",
should_continue,
{
"continue": "tools",
"end": END,
},
)
# 添加返回边
workflow.add_edge("tools", "agent")
# 编译图
graph = workflow.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
# 打印问答的流
def print_stream(stream):
"""
打印消息流的工具函数,支持两种消息格式:
1. 元组(tuple)形式的原始消息
2. 具有 pretty_print() 方法的对象
参数:
stream: 可迭代的消息流,每个元素应包含 "messages" 列表
"""
for s in stream: # 遍历消息流中的每个元素
message = s["messages"][-1] # 获取当前元素中 messages 列表的最后一个消息
if isinstance(message, tuple): # 如果消息是元组类型
print(message) # 直接打印原始元组
else: # 其他情况
message.pretty_print() # 调用对象的格式化打印方法
inputs = {"messages": [("user", "如何看待通义千问最新模型?")]}
print_stream(graph.stream(inputs, stream_mode="values"))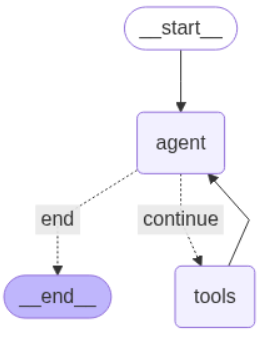
================================ Human Message =================================
如何看待通义千问最新模型?
================================== Ai Message ==================================
Tool Calls:
fetch_real_time_info (call_b85QNErx5VwN3KXtaDTQQbbe)
Call ID: call_b85QNErx5VwN3KXtaDTQQbbe
Args:
query: 通义千问最新模型 发布
================================= Tool Message =================================
Name: fetch_real_time_info
"{xxx}"
================================== Ai Message ==================================
对于阿里巴巴云最新发布的通义千问模型(Qwen3),这次更新带来了许多重要的变化和提升。以下是一些关键点:
-
版本升级: 通义千问的Qwen3版本及其子系列已经得到了显著提升。最新的Qwen3-Coder系列具有卓越的代码生成能力,被认为在开源模型中达到SOTA(State Of The Art)效果。
-
强化的核心: Qwen3系列核心的235B旗舰版本进行了同步重磅升级,其模型的通用能力显著领先于之前的版本。这表明模型在处理复杂任务时能够更高效地应对并提供更精确的结果。
-
多模态支持: 在不同应用场合的适应能力上,Qwen3还推出了加强互动环境的能力,使其在工具调优和环境交互中表现优异,使用户能够实现更加自主的任务操作。
更多详细信息可以访问阿里云官网。