文章目录
-
- 强化学习(第三课第三周)
-
- 一、以火星探测器为例说明强化学习的形式化表示
- 二、强化学习中的回报
- 三、强化学习算法的目标
- 三、连续状态空间的应用示例(以月球着陆器为示例)
- [四、Deep Q-Learning Algorithm with Experience Replay(代码版)](#四、Deep Q-Learning Algorithm with Experience Replay(代码版))
强化学习(第三课第三周)
强化学习:找到当前状态s到动作y的映射函数。强化学习的关键输入是奖励或者奖励函数,让模型多做一些有奖励的行为,少做一些有惩罚的行为,这样以后算法会自动找出如何选择好的行动。
一、以火星探测器为例说明强化学习的形式化表示
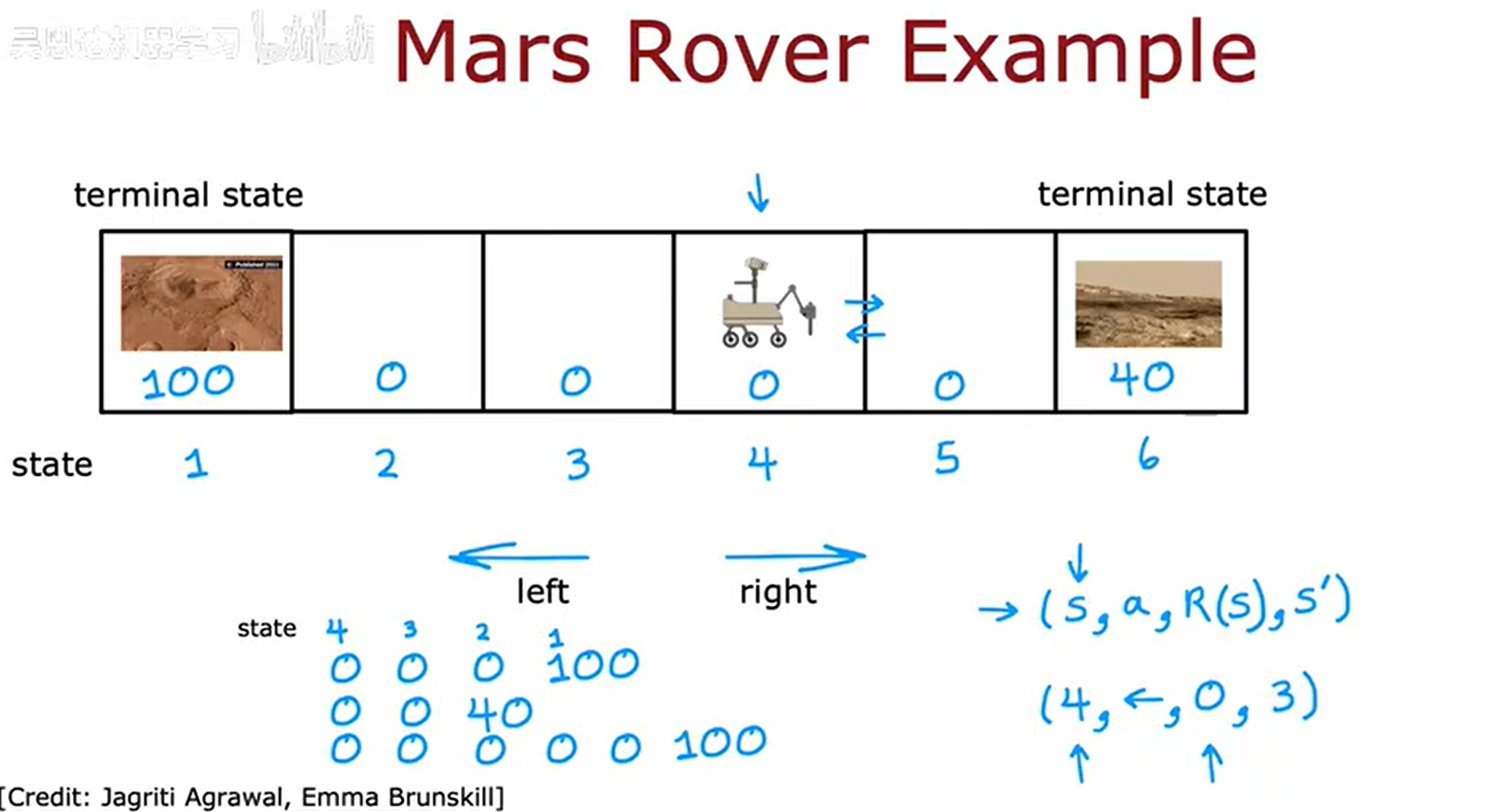
如上图所示,强化学习包含了四个要素,分别是当前状态、动作、奖励(与当前状态相关)、下一状态。强化学习如何运行停止呢,一般是有一个终止状态。
二、强化学习中的回报
在上面的奖励里面,我们会为每一个奖励添加折现因子(一个接近1的数),它的作用是让强化学习变得急功近利,即越早得到奖励,总回报值越高。示例如下;
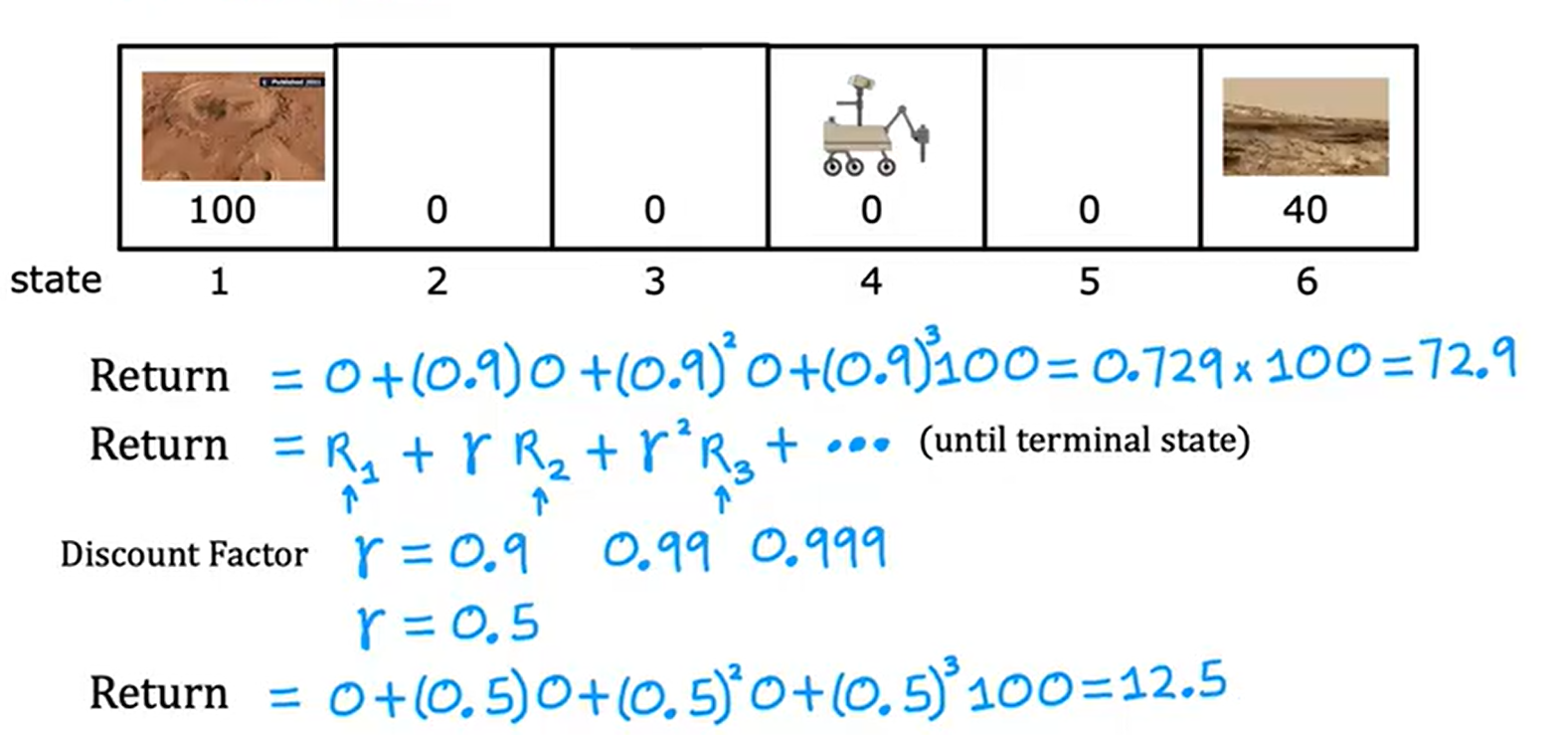
总之,我们的回报与动作息息相关,采取不同的动作,回报也会有所差别,回报是系统获得奖励的总和,示例如下: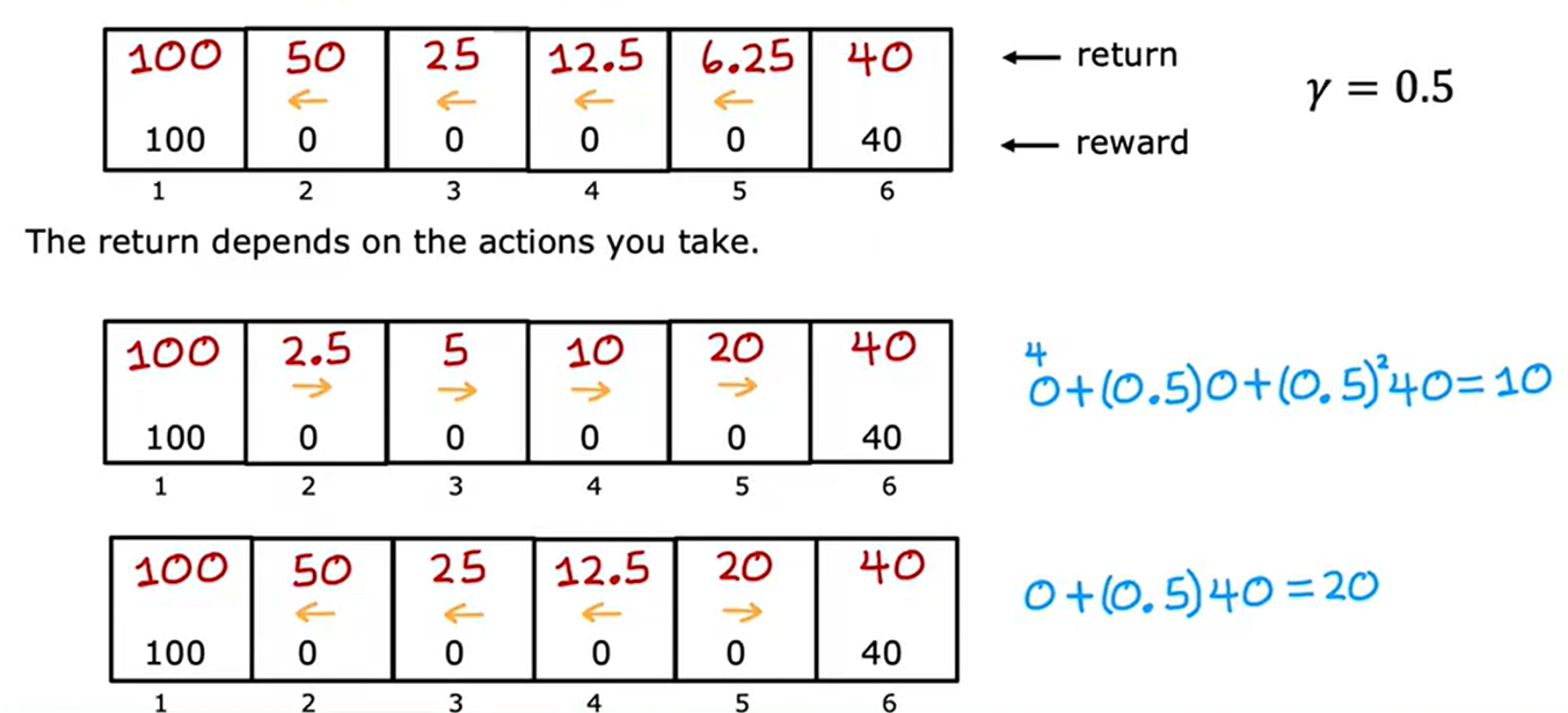
对于负奖励而言,算法更偏向于将负奖励推向未来,这样会尽量小幅度减少我们的回报值。
三、强化学习算法的目标
下面的讲解都是根据火星探测器(离散状态)的示例进行的。
(一)马尔可夫决策过程
我们的目标是提出一个称为pi的函数:它是将任何状态作为输入并映射到它想让我们采取的的行动a上面。这个函数会应用于状态s,并且告诉我们在那个状态我们需要采取什么行动,以便最大化回报。
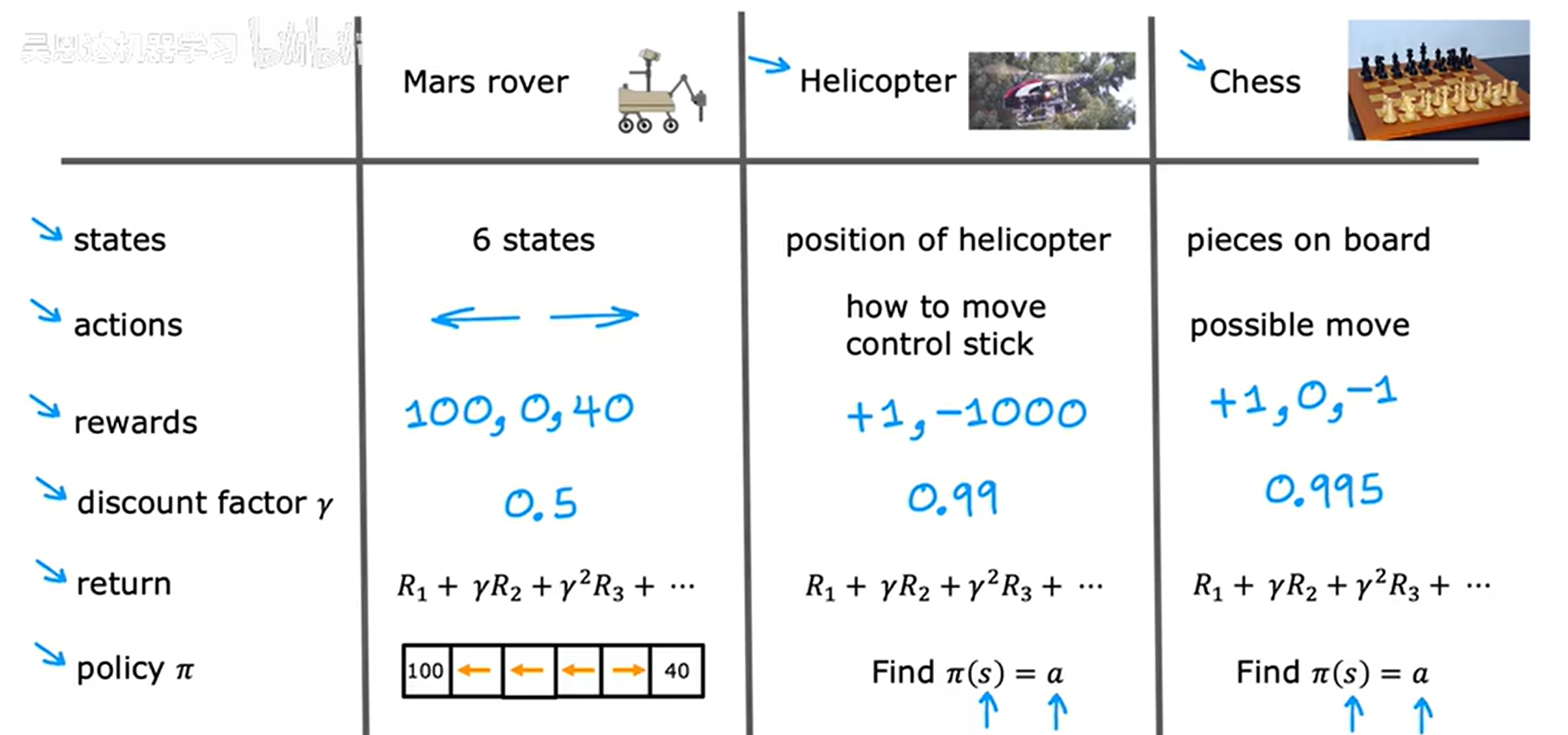
强化学习可以在很多方面进行应用:马尔可夫决策过程(MDP)。
(二)状态动作价值函数
状态动作价值函数(Q),报告了如果你在状态s采取动作a然后表现最优的回报。计算示例如下:
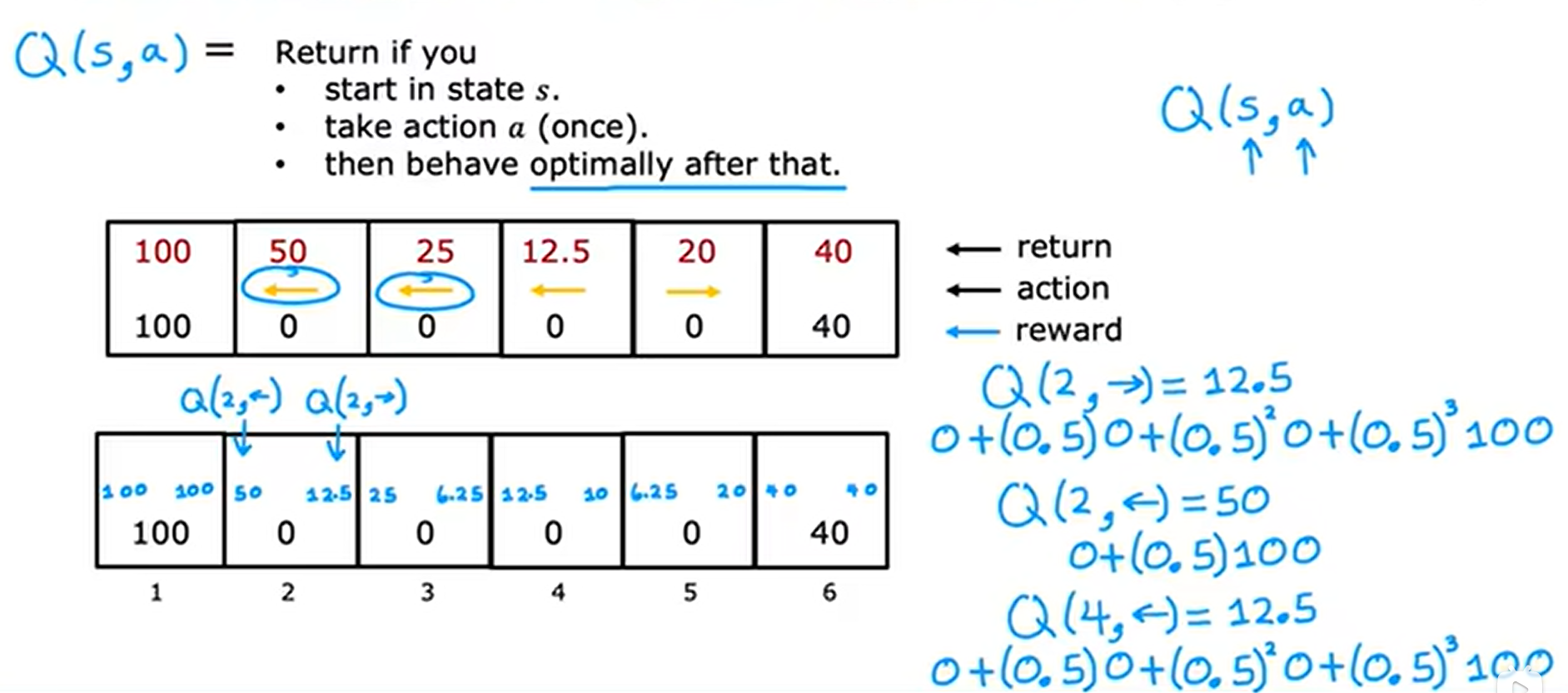
如果我们能够计算出每个状态和每个行动的状态动作价值函数值Q(s,a),那么这就给了我们一种计算最优策略pi(s)的好方法。
我们只需要计算出每个状态动作的Q值,选择该状态Q值最大的那个动作,就是我们的最优动作;示例如下:
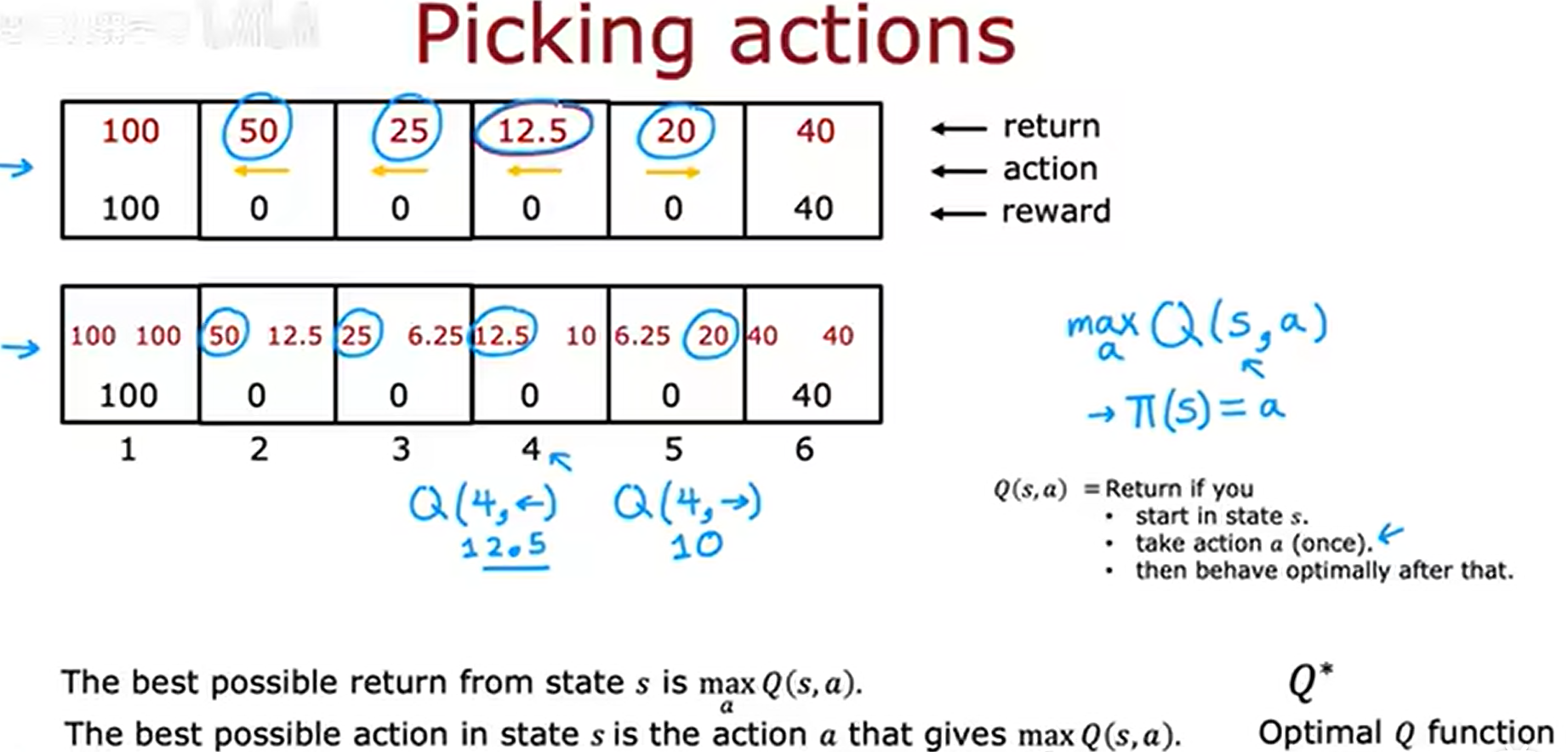
(四)使用Bellman方程帮助我们计算状态动作价值函数
贝尔曼方程如下:通过示例证明贝尔曼方程确实可以正确计算出状态动作价值函数

注意:当状态s为终端状态时,贝尔曼方程没有第二项,因为没有下一个状态了。
Q(s,a)的定义假设我们之后会最优地行动。所以贝尔曼方程地第二项是下一个状态的最优回报。
由于强化学习的过程具有很多随机性,受环境的影响,最终机器的动作路径可能不是按照最优路径进行的,所以我们感兴趣的是最大化折扣奖励总和的平均值。所以强化学习的任务就是选择一个策略pi以最大化平均值或期望的总和。
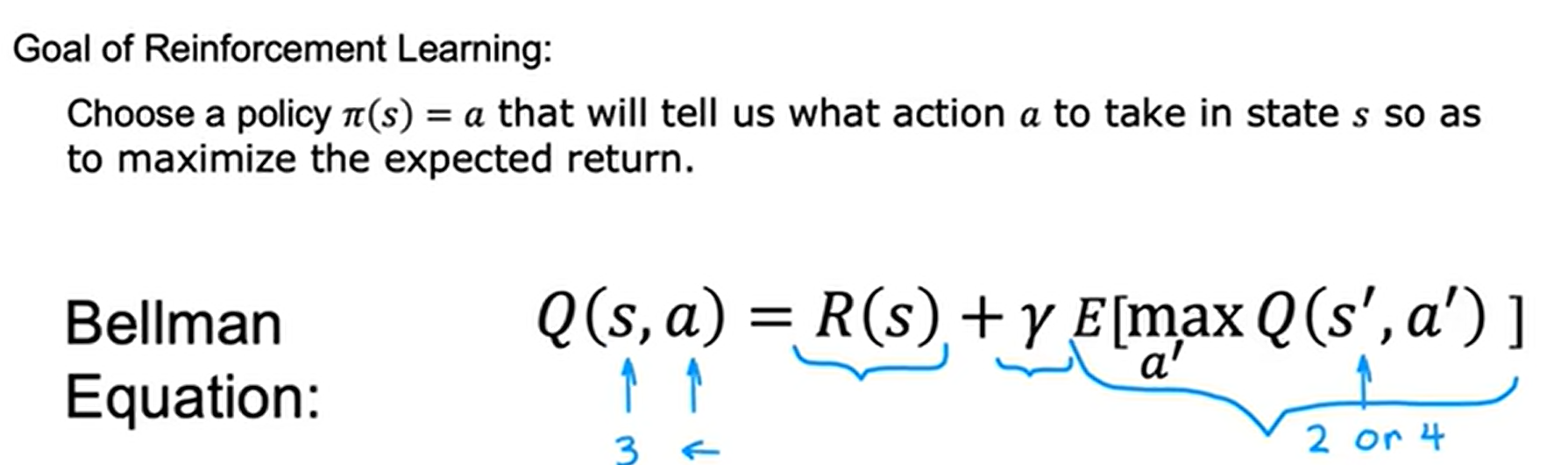
这里我理解的平均值就是:多次进行最优策略,相同的策略,但由于受到外界环境的影响,机器最终的动作路径会有所不同,那么回报也会不同,我们需要做的是最优化这个回报的平均值。
三、连续状态空间的应用示例(以月球着陆器为示例)
(一)月球着陆器的前提信息
在强化学习的应用中,也存在很多状态是连续的,可能是一个状态向量,向量里面的每一个数值都有一个范围,这个数值就在这个范围里面进行变化。
月球着陆器的状态是一个向量,包含了很多信息,示例如下:
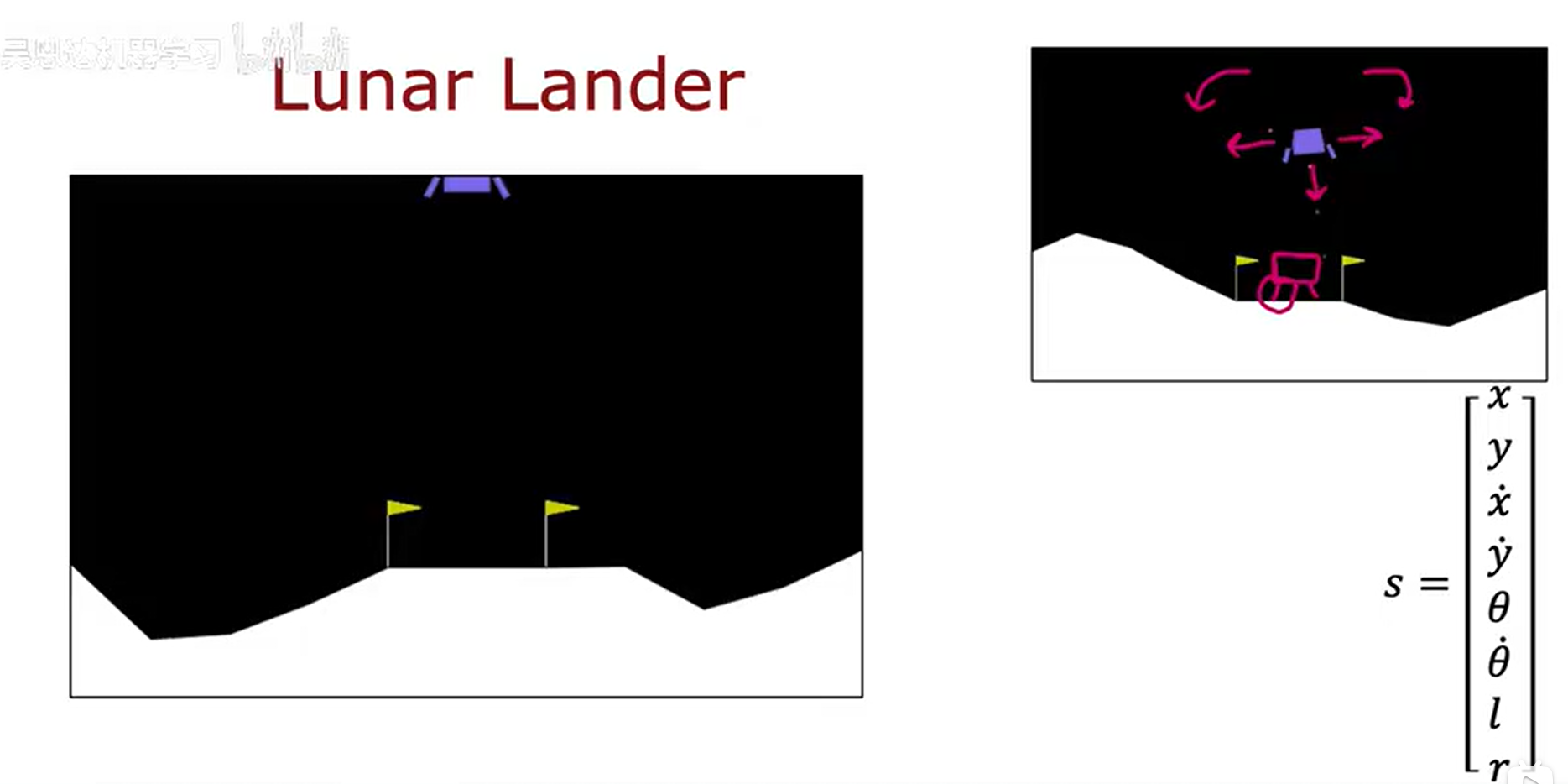
根据不同的状态信息有不同的奖励措施:

月球着陆器的折扣因子如下:
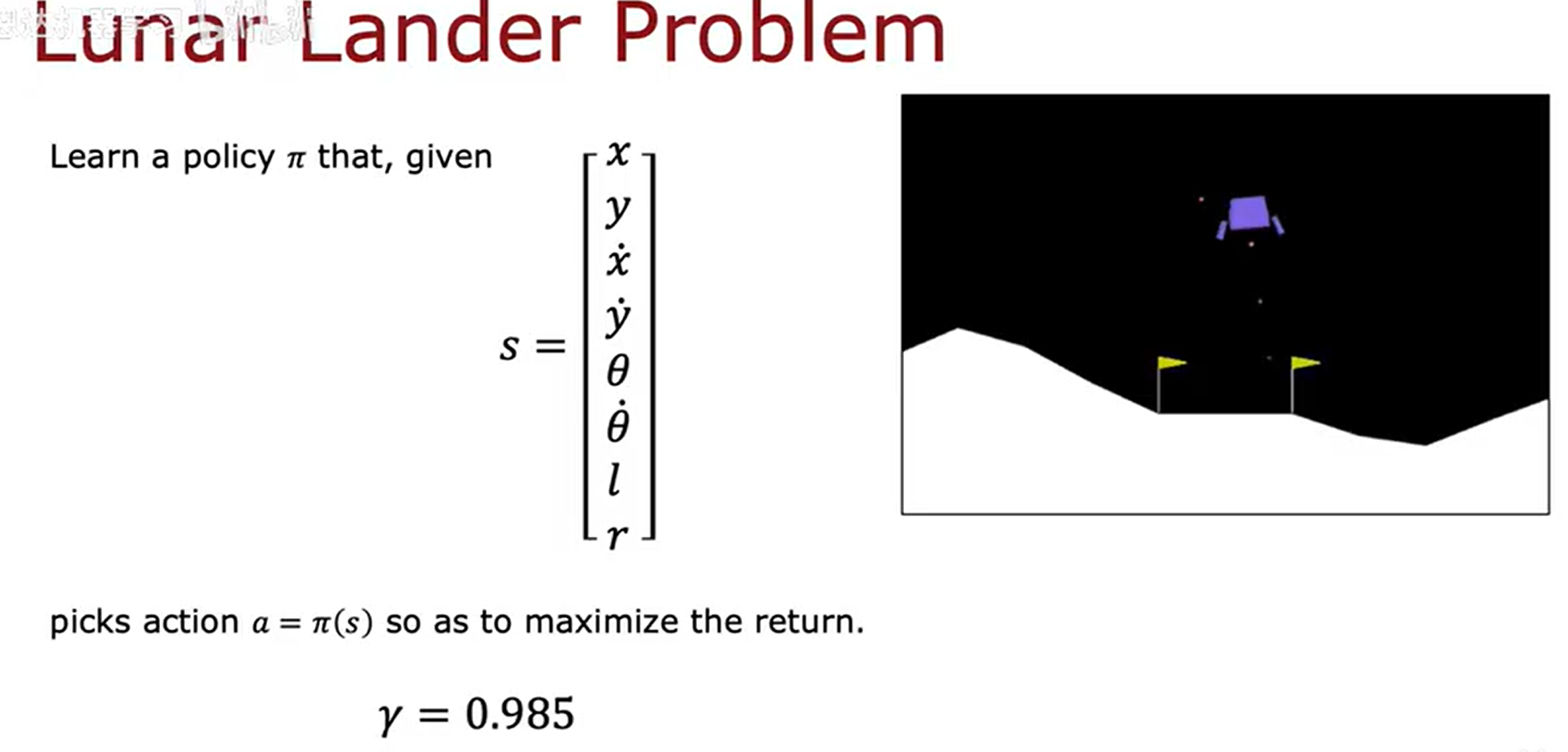
根据上面的前提,我们需要设计一个强化学习算法,来使得月球着陆器在不同的状态执行正确的动作,实现更好的着陆。
(二)训练一个神经网络来计算或者近似状态动作价值函数
提供给神经网络的输入则是与月球着陆器的状态和动作:状态是一个包含了8个数值的列表,动作是进行独热编码的4个数值,一共是12个数值。经过神经网咯,最终输出的是该状态动作的价值函数Q。这就叫做深度强化学习,我们将监督学习融入到了强化学习中去。具体如下:
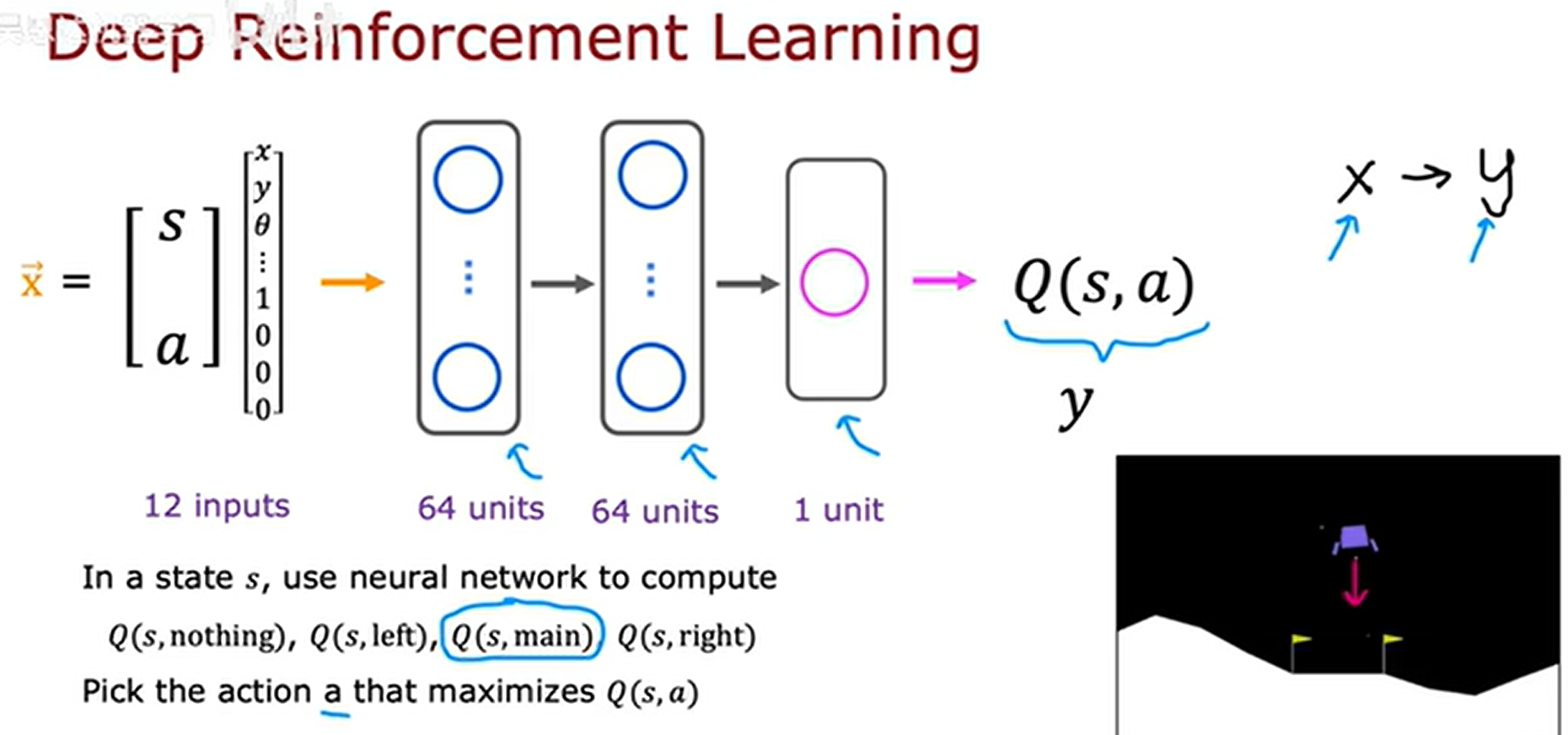
我们如何构造出关于输入和输出的训练集供神经网络学习呢?月球着陆模拟器,我们尝试不同的状态执行不同的动作,来得到训练集。
示例如下: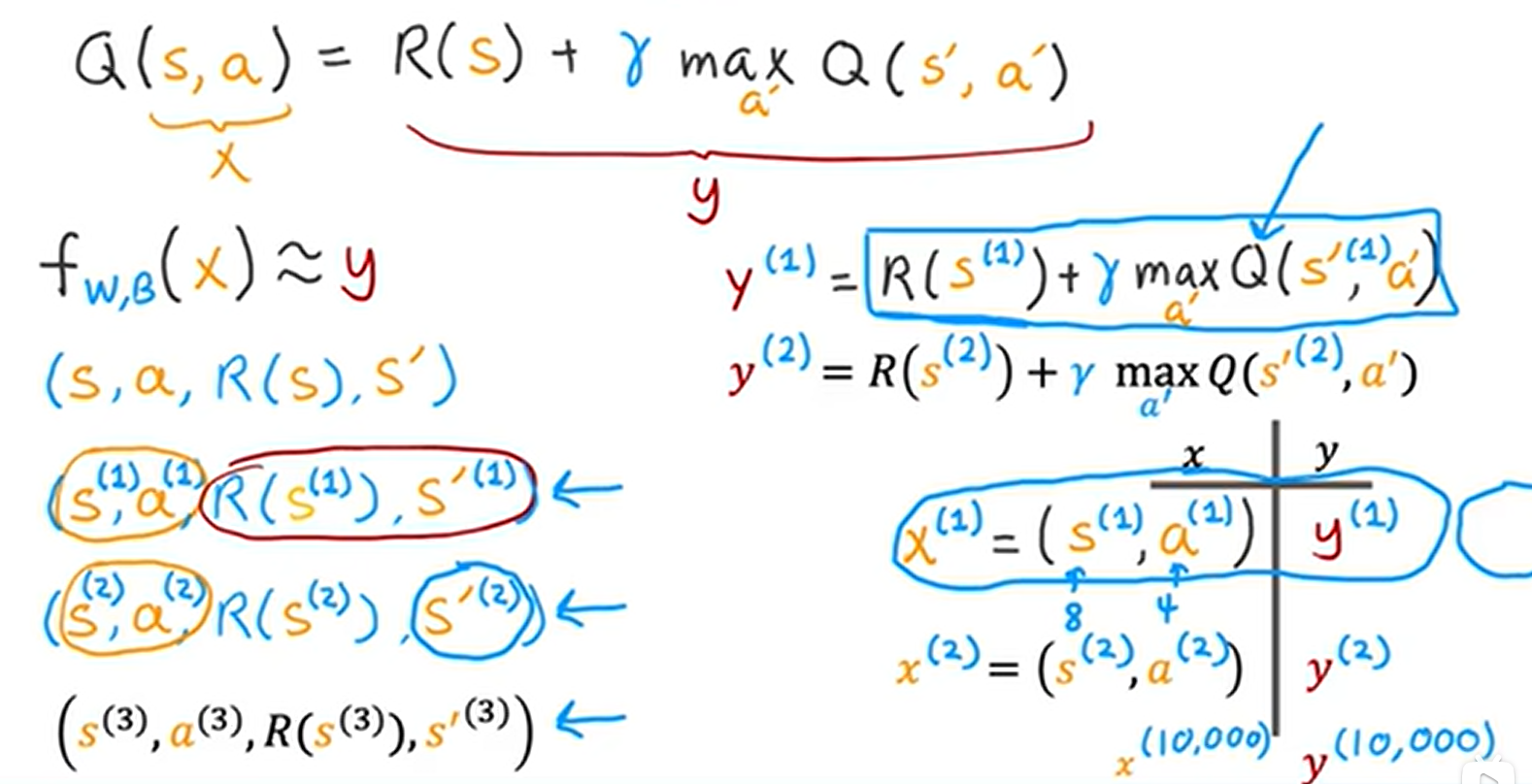
深度Q网络算法(DQN)的执行过程:

中间特别需要注意的是,每一次训练出来的新的Q,我们会把它将原来的Q替换掉,替换之后的数据集再次进行神经网络训练,这样不断迭代之后,Q函数会是一个很好的状态动作价值估计。
(三)优化DQN算法
1、优化神经网络结构
上面的模型训练结束之后,我们想要得到Q值最大的那个动作作为最优策略,我们需要对当前状态进行四次推理,才能得到。对上述算法的一个改进措施就是:训练一个神经网络来输出当前状态的四个Q值更为高效。示例如下: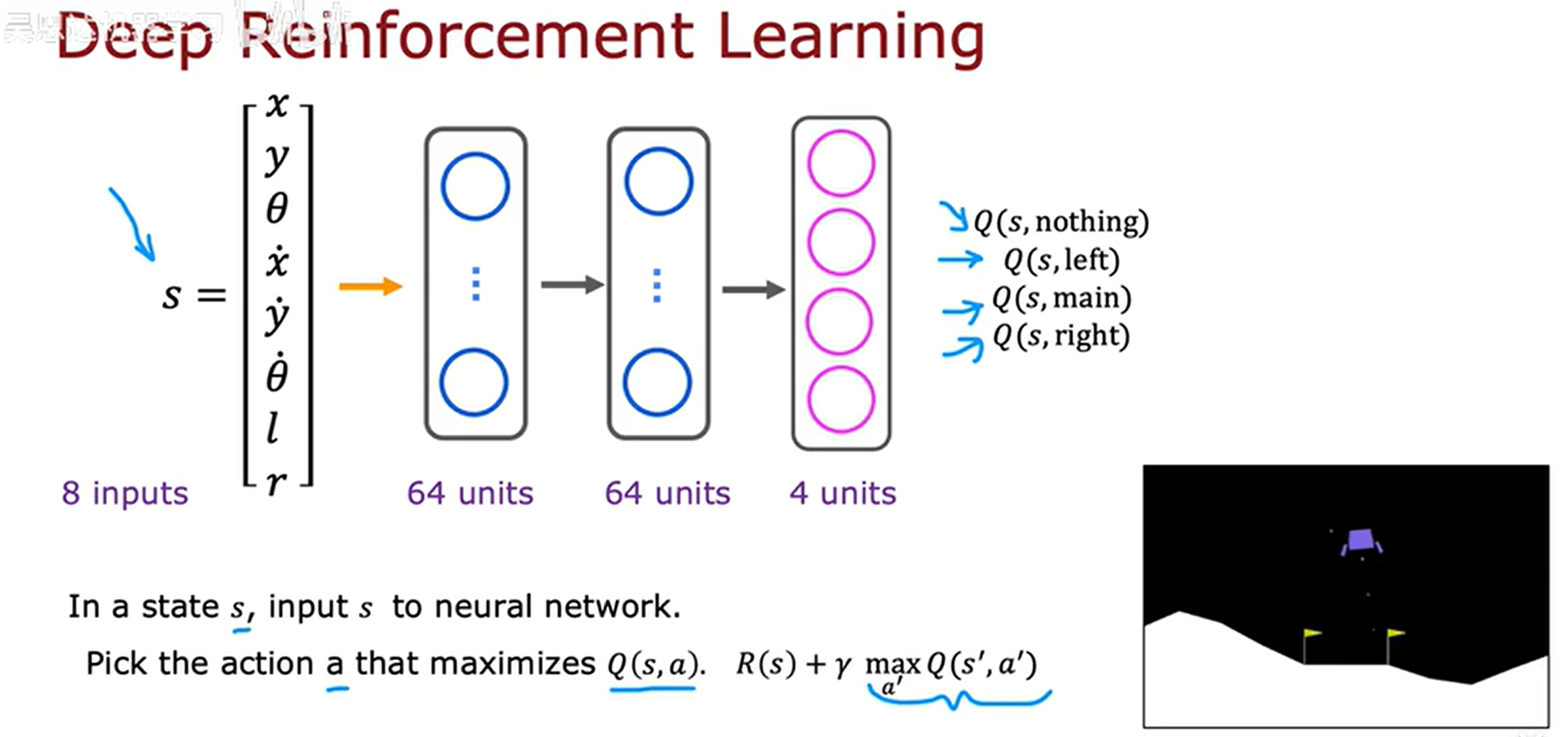
2、epsilon贪婪策略
在我们完成算法学习之前,也就是在过程中,我们不知道某一个状态的最佳动作是什么,算法还没有对Q有一个很好的估计。
在我们获取训练集时,我们会随机采取一些行动,但是为了使算法更好的学习,我们不能随意地采取一些行动,因为那通常是一个糟糕的行动,所以我们在采取行动时,采取的是最大化Q(当前的Q)的一个动作,即使它可能现在还不是一个很好的估计,这是一个方式之一;
那么另外一种方式(贪婪策略)就是:大多数时候,我们尝试使用当前的Q模型来估算选择一个好的行动(贪婪),小部分时间随机采取一个行动(探索)。
为什么要有一小部分随机选择呢,原因是神经网络在学习时,由于什么奇怪的原因,可能一直都没有选择过某一个行动,尽管那个行动可能会表现得好,随机值用来填补这一缺漏。贪婪策略指的是有epsilon*100%的数据是来自于随机采取的行动。
随着模型训练的深入,我们可以逐渐减少随机行动的比率,而更多地采取模型训练之后的Q来进行行动的选择。

3、小批量处理及软更新
在监督学习中,当样本数量巨大时,我们每执行一次梯度下降,就会计算一次数亿数据的一个平均值,这样太过耗费时间和资源。小批量梯度下降的理念是每次迭代不适用全部数据样本,我们可以取较少的样本数。
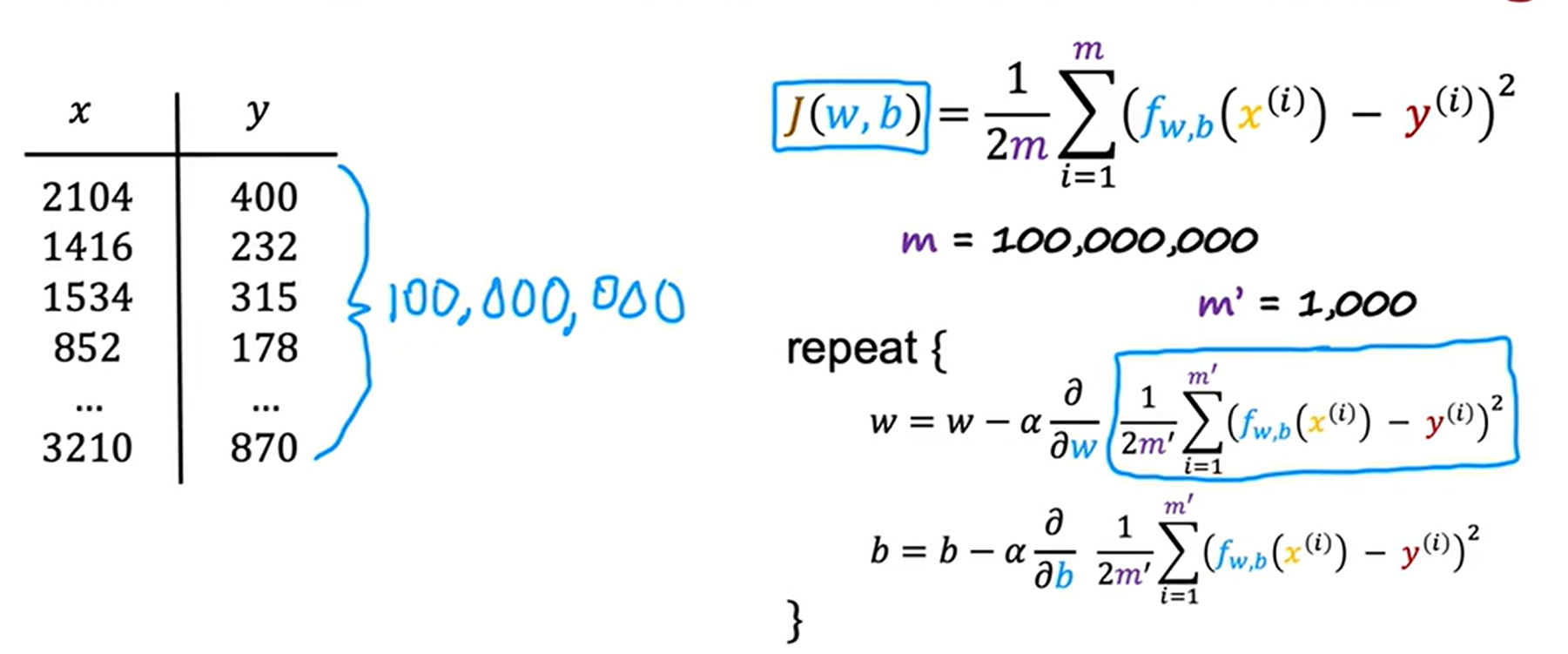
我们将原本的数据集划分成若干个小的数据集,依次对这些小的数据集进行梯度下降,在梯度下降的过程中,参数逐渐拟合小数据集,直到拟合完所有的子数据集。虽然小样本数据集在进行梯度下降是没有大数据集那样顺滑,变得很曲折,但是计算资源却会小很多。
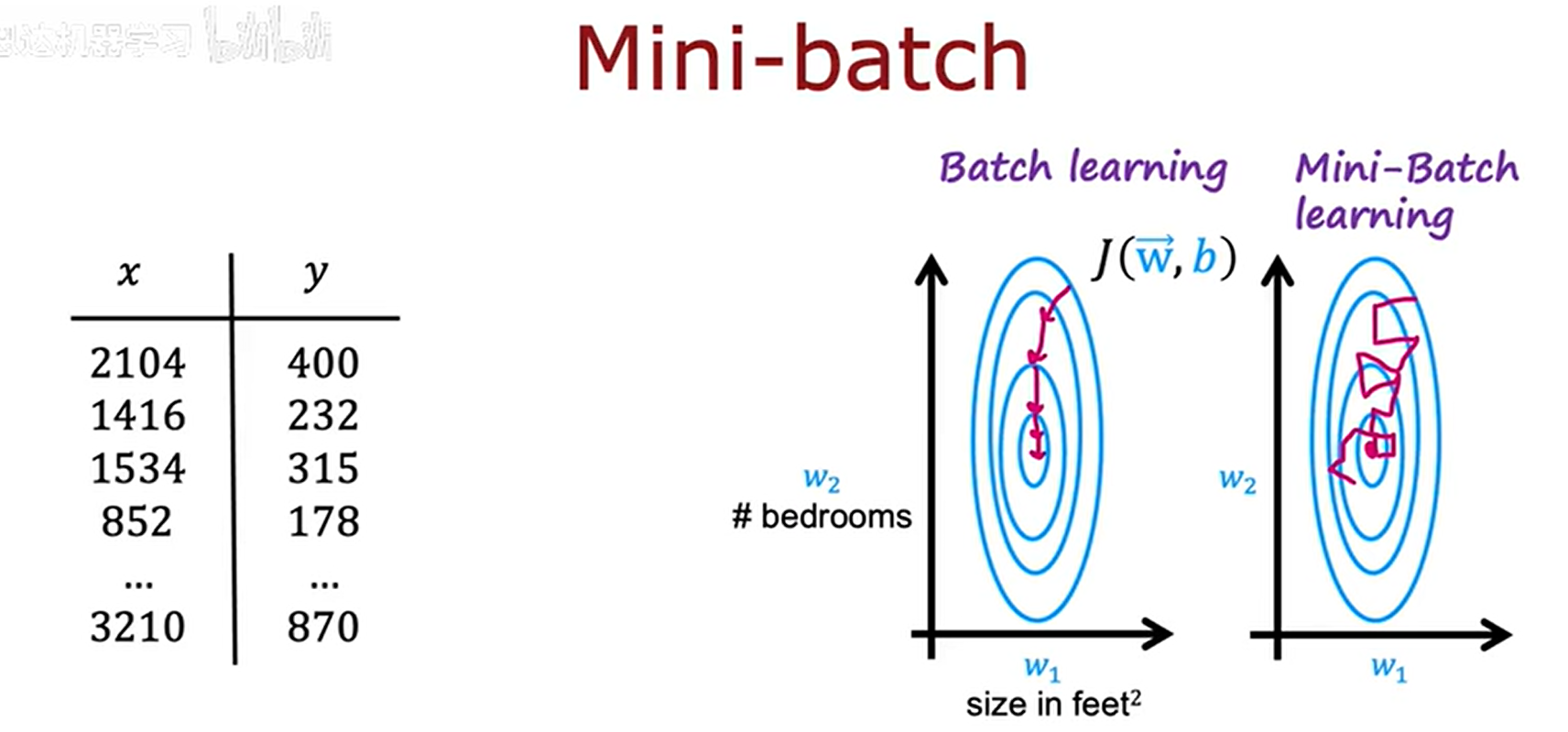
在强化学习中,同样也可以如此:

另外一种改进就是软更新,它所解决的问题是:在用新的模型Q覆盖旧的Q时,可能新的还没有旧的好,我们该怎么办呢?
我们可以控制旧Q向新Q更新的激进速度,来实现自我更新,使得强化学习算法能够更快地收敛,使得强化学习算法不太可能出现动荡、发散或者其他不良情况。通过使用软更新,我们可以确保目标值 缓慢变化,这大大提高了我们学习算法的稳定性。

四、Deep Q-Learning Algorithm with Experience Replay(代码版)
构建网络:
# UNQ_C1
# GRADED CELL
# 创建主 Q 网络,用于估计 Q(s, a) 值
q_network = Sequential([
### START CODE HERE ###
Input(shape=state_size), # 输入层:维度等于状态向量长度
Dense(units=64, activation="relu"), # 隐藏层 1:64 个 ReLU 神经元
Dense(units=64, activation="relu"), # 隐藏层 2:64 个 ReLU 神经元
Dense(units=num_actions, activation="linear"), # 输出层:每个动作对应一个 Q 值,线性激活
### END CODE HERE ###
])
# 创建目标 Q^- 网络,用于计算目标 y 值(参数更新较主网络慢)
target_q_network = Sequential([
### START CODE HERE ###
Input(shape=state_size), # 输入层:维度同上
Dense(units=64, activation="relu"), # 隐藏层 1:64 个 ReLU 神经元
Dense(units=64, activation="relu"), # 隐藏层 2:64 个 ReLU 神经元
Dense(units=num_actions, activation="linear"), # 输出层:每个动作对应一个 Q 值,线性激活
### END CODE HERE ###
])
# 创建优化器:使用 Adam,学习率由 ALPHA 指定
### START CODE HERE ###
optimizer = Adam(learning_rate=ALPHA) # 优化器将用于最小化 TD-error 损失
### END CODE HERE ###经验回放元组:
# 使用 collections.namedtuple 创建一个轻量级、不可变的数据结构
experience = namedtuple(
"Experience", # 新数据类型的名字,叫 Experience
field_names=[ # 指定每个实例里包含的字段名
"state", # 当前观测/状态 s_t
"action", # 在该状态下采取的动作 a_t
"reward", # 环境返回的即时奖励 r_t
"next_state", # 执行动作后进入的下一状态 s_{t+1}
"done" # 布尔标志:True 表示回合结束,False 表示未结束
]
)构造损失函数:
def compute_loss(experiences, gamma, q_network, target_q_network):
"""
Calculates the loss.
Args:
experiences: (tuple) tuple of ["state", "action", "reward", "next_state", "done"] namedtuples
gamma: (float) The discount factor.
q_network: (tf.keras.Sequential) Keras model for predicting the q_values
target_q_network: (tf.keras.Sequential) Karas model for predicting the targets
Returns:
loss: (TensorFlow Tensor(shape=(0,), dtype=int32)) the Mean-Squared Error between
the y targets and the Q(s,a) values.
"""
# 1. 把 experiences 这个批次的数据拆成五个张量
states, actions, rewards, next_states, done_vals = experiences
# 2. 用"目标网络"计算下一状态 s' 的最大 Q 值:max_a' Q̂(s', a')
# axis=-1 表示在动作维度上取最大值
max_qsa = tf.reduce_max(target_q_network(next_states), axis=-1)
# 3. 计算 y 目标值:
# 如果 done=1(回合结束),y = r
# 否则 y = r + γ * max_a' Q̂(s', a')
y_targets = rewards + (gamma * max_qsa * (1 - done_vals))
# 4. 用"主网络"计算当前状态-动作对应的 Q(s, a)
q_values = q_network(states) # 形状: [batch_size, num_actions]
# 5. 从 Q(s,·) 里挑出实际被执行动作 a 对应的 Q(s,a)
# 利用 gather_nd 按 (batch_index, action_index) 取值
q_values = tf.gather_nd(
q_values,
tf.stack([tf.range(q_values.shape[0]), # 每个样本的 batch 索引
tf.cast(actions, tf.int32)], # 每个样本的动作索引
axis=1)
)
# 6. 计算 MSE 损失: (y_targets - Q(s,a))^2 的均值
loss = MSE(y_targets, q_values)
# 7. 把标量损失返回给调用者
return loss更新网络权重:
# 用 @tf.function 装饰器将函数编译为静态图,加快训练速度并支持自动微分
@tf.function
def agent_learn(experiences, gamma):
"""
根据一批经验更新 Q 网络权重(主网络 + 目标网络)。
Args:
experiences: (tuple) 由 ["state", "action", "reward", "next_state", "done"] 五个字段组成的 namedtuple 批次
gamma: (float) 折扣因子 γ
"""
# 1. 在 GradientTape 的上下文里计算损失,便于后续求梯度
with tf.GradientTape() as tape:
loss = compute_loss(experiences, gamma, q_network, target_q_network)
# 2. 根据 loss 对主网络所有可训练变量求梯度
gradients = tape.gradient(loss, q_network.trainable_variables)
# 3. 将梯度应用到主网络权重,完成一次梯度下降更新
optimizer.apply_gradients(zip(gradients, q_network.trainable_variables))
# 4. 用软更新或硬更新策略,把主网络权重同步/平滑到目标网络
utils.update_target_network(q_network, target_q_network)训练模型:
# ---------------- 计时开始 ----------------
start = time.time()
# ---------------- 训练超参数 ----------------
num_episodes = 2000 # 总共训练多少回合(episode)
max_num_timesteps = 1000 # 每回合最多走多少步(超过也强制结束)
total_point_history = [] # 记录每回合得分的列表,用于计算滑动平均分
num_p_av = 100 # 计算最近多少回合的平均得分
epsilon = 1.0 # ε-贪婪策略的初始探索率(完全随机)
# 创建经验回放池(双端队列),容量 MEMORY_SIZE,满时自动弹出最旧经验
memory_buffer = deque(maxlen=MEMORY_SIZE)
# 把主网络(q_network)的权重一次性复制给目标网络(target_q_network),保证初始同步
target_q_network.set_weights(q_network.get_weights())
# ---------------- 主训练循环 ----------------
for i in range(num_episodes):
# 1. 重置环境,拿到初始状态
state = env.reset()
total_points = 0 # 本回合累计得分
# 2. 单回合内循环
for t in range(max_num_timesteps):
# 2-1 将状态扩展成 batch=1 的形状,喂给主网络
state_qn = np.expand_dims(state, axis=0)
# 2-2 主网络输出每个动作的 Q 值
q_values = q_network(state_qn)
# 2-3 根据 ε-贪婪策略选择动作
action = utils.get_action(q_values, epsilon)
# 2-4 在环境中执行动作,拿到下一步信息
next_state, reward, done, _ = env.step(action)
# 2-5 把五元组经验存进回放池
memory_buffer.append(experience(state, action, reward, next_state, done))
# 2-6 判断"是否到更新时机":时间步满足 + 回放池够大
update = utils.check_update_conditions(t, NUM_STEPS_FOR_UPDATE, memory_buffer)
if update:
# 2-6-1 从回放池随机采样一个 mini-batch 经验
experiences = utils.get_experiences(memory_buffer)
# 2-6-2 用 DQN 算法更新主网络权重
agent_learn(experiences, GAMMA)
# 2-7 状态转移,累加奖励
state = next_state.copy()
total_points += reward
# 2-8 如果回合结束,跳出内层循环
if done:
break
# 3. 记录本回合得分,计算最近 num_p_av 回合平均分
total_point_history.append(total_points)
av_latest_points = np.mean(total_point_history[-num_p_av:])
# 4. 每回合递减 ε(线性/指数衰减,函数内部实现)
epsilon = utils.get_new_eps(epsilon)
# 5. 实时打印进度(同一行覆盖)
print(f"\rEpisode {i+1} | Total point average of the last {num_p_av} episodes: {av_latest_points:.2f}", end="")
# 6. 每 num_p_av 回合换行打印一次
if (i+1) % num_p_av == 0:
print(f"\rEpisode {i+1} | Total point average of the last {num_p_av} episodes: {av_latest_points:.2f}")
# 7. 如果最近平均得分 ≥ 200,认为环境已解决
if av_latest_points >= 200.0:
print(f"\n\nEnvironment solved in {i+1} episodes!")
q_network.save('lunar_lander_model.h5') # 保存最终模型
break
# ---------------- 训练结束,输出总耗时 ----------------
tot_time = time.time() - start
print(f"\nTotal Runtime: {tot_time:.2f} s ({(tot_time/60):.2f} min)")在深度Q学习(DQN)中,神经网络训练所需的数据来源于智能体与环境的交互过程。具体来说,数据生成和使用的流程如下:
-
数据生成(交互过程):
-
智能体在环境中执行动作(基于当前策略,如ε-贪婪策略)。
-
环境返回执行动作后的结果:新的状态(next_state)、奖励(reward)以及是否终止(done)。
-
将每一步的交互结果存储为一个五元组(state, action, reward, next_state, done),称为一个经验(experience)。
-
-
数据存储(经验回放池):
- 这些经验被存储在一个固定大小的缓冲区中,称为经验回放池(experience replay buffer)。当缓冲区满时,旧的经验会被新的经验覆盖。
-
数据采样(训练数据来源):
-
在训练时,从经验回放池中随机采样一批(mini-batch)经验(例如,64个经验样本)。
-
这个随机采样的过程打破了数据之间的相关性(因为相邻的经验是相关的),使得训练更加稳定。
-
-
数据使用(训练网络):
- 对于每个采样的经验样本(s, a, r, s', done):
- 用主网络(q_network)计算当前状态s下所有动作的Q值,并选取执行动作a对应的Q值作为预测值(predicted Q)。
- 用目标网络(target_q_network)计算下一个状态s'的最大Q值:max_a' Q_target(s', a')。
- 如果done为真(即终止状态),则目标值(target)就是r;否则,目标值 = r + γ * max_a' Q_target(s', a')。
- 通过最小化预测值(predicted Q)与目标值(target)之间的均方误差来更新主网络的参数。
总结:训练数据来源于智能体在环境中探索得到的经验,这些经验被存储在经验回放池中,训练时从中随机采样一批数据用于神经网络的参数更新。这种机制使得数据可以被多次利用(提高样本效率),并且通过随机采样减少了数据间的相关性,从而稳定了训练过程。
结束!!!