一. 前言
- 遵纪守法 ,不要做违法乱纪的事哦 ❗❗❗❗
最近碰到了一个小羊毛 ,每天签到可以得几积分 ,所以如果是多个账号 + 自动化 ,长时间累积起来也是不错的。
所以研究了一下 ,便有了这个小项目 ,帮我每天自动化的薅羊毛。
二. 基础功能介绍
2.1 影刀
影刀(Yingdao RPA)是低代码自动化工具,专注于 RPA(机器人流程自动化),适用于企业办公、数据爬取和脚本执行。
用过的自然知道这个软件的作用 ,没用过的可以关注一下 ,类似的也有很多 ,主要是这个顺手还免费,要啥自行车。
2.2 ddddocr
ddddocr 是由中国开发者 sml2h3 开源的 Python OCR 库(GitHub 仓库:sml2h3/ddddocr),专注于图像验证码和滑块验证码识别。
- 核心优势:
- 轻量级(无需深度学习框架),离线运行(模型内置),识别准确率高达 95%+(针对常见验证码),安装简单(pip install ddddocr)
- 支持多语言验证码,适用于爬虫自动化。
- 优化了滑块匹配算法,适用于 Web 安全测试和自动化脚本。
- 总计 50+ 万下载量,已集成进多个开源项目。
类似工具对比
| 工具名称 | 关键特性 | 与 ddddocr 的对比 |
|---|---|---|
| Tesseract OCR | Google 开源,支持多语言文本识别,依赖图像预处理。 | ddddocr 更轻量(无需外部引擎),验证码专精准确率更高(95% vs 80%),安装更快,无需训练模型。 |
| PaddleOCR | 百度开源,基于深度学习,支持端到端 OCR,需 PaddlePaddle 框架。 | ddddocr 无框架依赖、更离线友好,速度更快(<1s/图 vs 2-5s),针对验证码场景更优化,轻量部署优势明显。 |
| EasyOCR | 支持 80+ 语言的 Python OCR 库,基于 PyTorch,轻量但需在线模型下载。 | ddddocr 完全离线(内置模型)、验证码识别更精准,资源占用低(10MB vs 100MB+),无需 GPU 加速。 |
| Captcha Breaker | 专为验证码设计的工具,支持简单模式,但准确率较低,需自定义规则。 | ddddocr 自动化更高(AI 驱动 vs 规则基),准确率和鲁棒性更强,便于集成 Python 脚本,优势在复杂验证码处理。 |
上一篇里面我尝试了一下 paddleocr , 好用是好用 ,但是占用的资源太多了 ,而 ddddocr ,即能做到准确性 ,又可以极小资源的占用 ,非常的 nice.
三. 废话少说 ,直接上方案
3.1 影刀的配置
首先是主流程
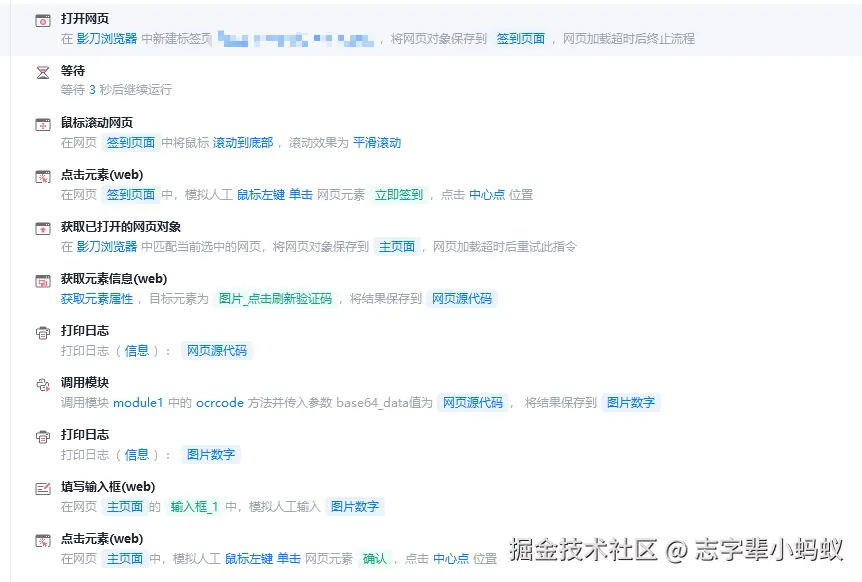
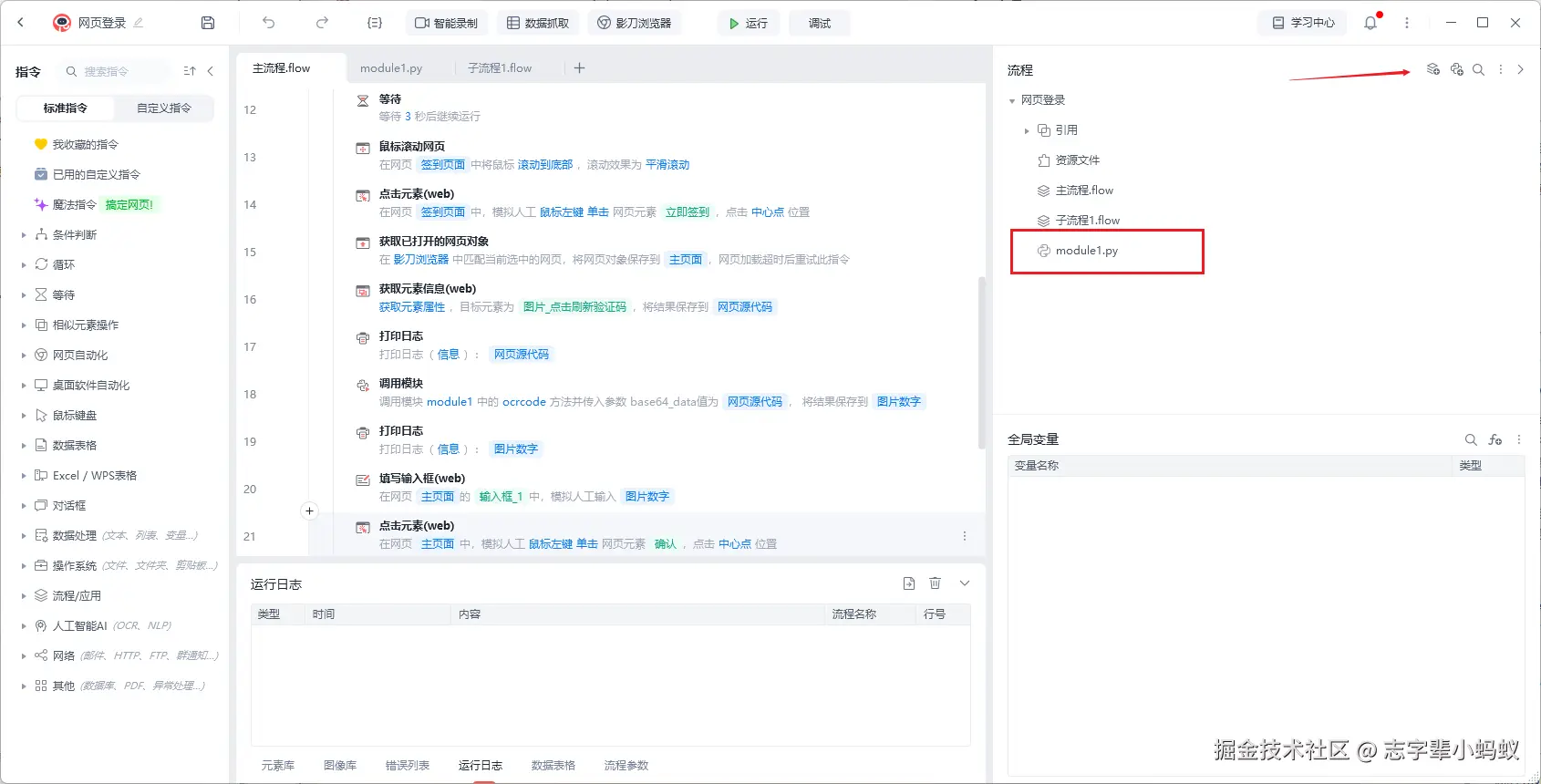
- 这里最重要的就是调用模块的接口,模块是影刀里面一个工具 ,可以执行 Python 代码
3.2 调用 Python 代码
python
# =====================================================================================
# 模块说明
#
# 本模块提供了一个高鲁棒性的OCR功能,用于识别复杂的数字验证码。
# 核心策略是"大力出奇迹":通过多样的图像预处理生成N个候选版本,再用多种配置的OCR引擎
# 去尝试所有版本,最后通过投票选出最可信的结果,以应对各种图片干扰。
# =====================================================================================
# 使用提醒:
# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能
# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能
# 3. 当此模块作为流程独立运行时执行main函数
# 4. 可视化流程中可以通过"调用模块"的指令使用此模块
import xbot
from xbot import print, sleep
from . import package
from .package import variables as glv
import ddddocr
import base64
from io import BytesIO
from PIL import Image, ImageEnhance, ImageFilter
import cv2
import numpy as np
def preprocess_image(image_bytes):
"""
对图像进行一系列复杂的预处理,生成多个用于OCR的候选图像版本。
核心策略是"广撒网":由于验证码的干扰类型不一(如噪点、模糊、颜色不均、笔画断裂等),
单一处理方法很难通用。此函数因此组合了多种技术,包括:
1. 放大与平滑:使微小数字更清晰,并初步降噪。
2. 灰度化与对比度增强:简化图像信息,突出特征。
3. 多策略二值化:并行使用自适应阈值、OTSU、固定阈值等多种方法,以期有一种能完美分离字符。
4. 形态学修复与锐化:连接断裂笔画、移除噪点并锐化边缘。
最终返回所有这些处理版本的列表,供后续OCR引擎逐一尝试。
"""
# --- 步骤 1: 初始化与格式转换,将图片字节加载为后续处理所需的格式 ---
img = Image.open(BytesIO(image_bytes))
if img.mode != 'RGB':
img = img.convert('RGB')
img_array = np.array(img)
# --- 步骤 2: 图像放大、去噪与对比度增强,为识别微小模糊字符做准备 ---
height, width = img_array.shape[:2]
scale_factor = 3
img_array = cv2.resize(img_array, (width * scale_factor, height * scale_factor), interpolation=cv2.INTER_CUBIC)
img_array = cv2.GaussianBlur(img_array, (3, 3), 0)
gray = cv2.cvtColor(img_array, cv2.COLOR_RGB2GRAY)
gray = cv2.equalizeHist(gray)
# --- 步骤 3: 多策略并行二值化,尝试多种方法分离前景与背景 ---
processed_images = []
adaptive_thresh = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 2)
processed_images.append(adaptive_thresh)
_, otsu_thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
processed_images.append(otsu_thresh)
for thresh_val in [100, 120, 140, 160, 180]:
_, fixed_thresh = cv2.threshold(gray, thresh_val, 255, cv2.THRESH_BINARY)
processed_images.append(fixed_thresh)
_, inv_thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
processed_images.append(inv_thresh)
# --- 步骤 4: 形态学处理,修复字符笔画的断裂并移除孤立噪点 ---
kernel = np.ones((2, 2), np.uint8)
morphology_images = []
for img in processed_images:
closed = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)
morphology_images.append(closed)
opened = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)
morphology_images.append(opened)
# --- 步骤 5: 最终增强与格式转换,锐化所有版本并打包输出 ---
all_processed = processed_images + morphology_images
result_images = []
for processed_img in all_processed:
pil_img = Image.fromarray(processed_img)
pil_img = ImageEnhance.Contrast(pil_img).enhance(2.0)
pil_img = pil_img.filter(ImageFilter.SHARPEN)
buffer = BytesIO()
pil_img.save(buffer, format='PNG')
result_images.append(buffer.getvalue())
return result_images
def ocrcode(base64_data):
"""
接收Base64图片,通过"预处理 + 多轮识别 + 投票"的策略,识别出图片中的数字。
执行流程:
1. 解码: 将Base64字符串转为二进制图片。
2. 预处理: 调用 `preprocess_image` 生成一个包含原图和多种优化版本的图像列表。
3. 识别: 遍历所有图像版本,并对每个版本使用多种 `ddddocr` 配置进行识别。
4. 投票: 统计所有识别结果的出现频率,选择出现次数最多的结果作为最终输出。
"""
# --- 步骤 1: Base64解码,处理输入字符串得到原始图片数据 ---
if ',' in base64_data:
_, base64_str = base64_data.split(',', 1)
else:
base64_str = base64_data
image_bytes = base64.b64decode(base64_str)
# --- 步骤 2: 生成图像列表,包含原图和所有经过预处理的版本 ---
processed_images = preprocess_image(image_bytes)
all_images = [image_bytes] + processed_images
# --- 步骤 3: 多配置、多轮次OCR识别,对每个图像版本都用多种配置尝试识别 ---
results = []
for img_bytes in all_images:
try:
ocr1 = ddddocr.DdddOcr(beta=True); ocr1.set_ranges("0123456789")
res1 = ocr1.classification(img_bytes)
if res1 and res1.strip():
clean_res = ''.join(filter(str.isdigit, res1.strip()))
if clean_res: results.append(clean_res)
except: pass
try:
ocr2 = ddddocr.DdddOcr(beta=False); ocr2.set_ranges("0123456789")
res2 = ocr2.classification(img_bytes)
if res2 and res2.strip():
clean_res = ''.join(filter(str.isdigit, res2.strip()))
if clean_res: results.append(clean_res)
except: pass
try:
ocr3 = ddddocr.DdddOcr(beta=True)
res3 = ocr3.classification(img_bytes)
if res3 and res3.strip():
res3_clean = ''.join(filter(str.isdigit, res3))
if res3_clean: results.append(res3_clean)
except: pass
# --- 步骤 4: 投票选举最佳结果,从所有识别结果中选出最可信的一个 ---
if results:
result_count = {}
for result in results:
result_count[result] = result_count.get(result, 0) + 1
best_result = max(result_count.items(), key=lambda x: (x[1], len(x[0])))
return best_result[0]
else:
return ""
def debug_save_processed_images(base64_data, save_path="debug_images"):
"""调试用:保存预处理后的所有图像版本以供分析。"""
import os
if ',' in base64_data:
_, base64_str = base64_data.split(',', 1)
else:
base64_str = base64_data
image_bytes = base64.b64decode(base64_str)
processed_images = preprocess_image(image_bytes)
os.makedirs(save_path, exist_ok=True)
with open(f"{save_path}/original.png", "wb") as f: f.write(image_bytes)
for i, img_bytes in enumerate(processed_images):
with open(f"{save_path}/processed_{i}.png", "wb") as f: f.write(img_bytes)
print(f"已保存 {len(processed_images)} 张处理后的图像到 {save_path} 目录")
def main(args):
"""模块独立运行时的测试入口。"""
base64_data = "data:image/png;base64,iVBORw0KGgxxxxxx......"
res = ocrcode(base64_data)
print("识别结果:", res)
- 其实 带带弟弟OCR 本身不需要这么多代码 ,只不过用原生的情况下 ,识别准确度并不高 ,但是很快
- 我这段代码是牺牲了一定的性能 ,对图片进行了一次预处理 ,整体耗时大概在2秒左右,我能接受了
- 官方文档 : github.com/sml2h3/dddd...
官方原装语法 :
python
ocr = ddddocr.DdddOcr()
// 其实就这几句 ,好用吧
image = open("example.jpg", "rb").read()
result = ocr.classification(image)
print(result)四. 其他的扩展
| 场景 (Scenario) | 用法 (Usage) | 核心代码 | 关键要点 |
|---|---|---|---|
| 通用验证码识别 | 传入图片字节,识别图中字符。 | ocr = ddddocr.DdddOcr() result = ocr.classification(img_bytes) |
知道范围时用 ocr.set_ranges() 提高准确率。 |
| 滑块验证码(缺口) | 传入滑块和背景图,定位缺口坐标。 | det = ddddocr.DdddOcr(det=True) result = det.slide_match(slider_bytes, bg_bytes) |
初始化时必须设置 det=True。 |
| 目标检测(点选) | 传入图片,识别所有文字或目标坐标。 | det = ddddocr.DdddOcr(det=True) poses = det.detection(img_bytes) |
同样需要 det=True,常用于点选类验证码。 |
| 作为HTTP服务 | 启动服务后,任意语言通过API调用。 | # 启动: python -m ddddocr.server res = requests.post(url, files={'file': img_bytes}) |
实现跨语言调用,方便非Python项目集成。 |
这里我整理了一下 ,官方文档里面还支持 : 滑块验证码 / 点选验证 的方式。 不过现在验证的方式越来越多了 ,比如最近很常见的 :
- 逻辑推理与空间认知型验证 (Logical & Spatial Reasoning)

以及更高级的认证 ,会让你识别会在天上飞的 ~~~
这些就不要想了 ,这种认证比较复杂 ,包括生成认证都会比较麻烦 , 一般场景较少。 不过 AI 识别后通过逻辑分析 ,未来应该也是可以实现的。
总结
东西很好用 ,已经薅了十几天了 ,中间可能会有小部分概率掉 ,所以要注意做保险验证 ,没通过的可以写在日志里面。
另外再说一句 ,工具只是为了减少体力劳动 ,可以盈利但是不要做过分的事哦,别把别人薅秃了,那就没意思了。
最后的最后 ❤️❤️❤️👇👇👇
- 👈 欢迎关注 ,超200篇优质文章,未来持续高质量输出 🎉🎉
- 🔥🔥🔥 系列文章集合,高并发,源码应有尽有 👍👍
- 走过路过不要错过 ,知识无价还不收钱 ❗❗