Hello 大家好, 这里是 Anyin
前言
最近 AI Agent 如火如荼,自己也想着接触这块内容,所以选择了 Spring AI Alibaba 这个项目进行学习。
在下载了 Spring AI Alibaba 代码之后,本地编译通过,并且也能跑了几个相关的 Demo。为了再深入点学习,最终选择了 deepresearch 这个项目,在看了相关代码之后,发现还是一知半解。
所以为了能够更加直观的感受整个项目的流程,就把前端代码也跑起来,结果发现前端跑了之后,也是没办法完整体验到整个流程,因为前端功能还是缺失很多。 而且观察了几天,发现并没有新的前端 PR 提交。
刚好手上有 Trae PRO 的账号,而且前几天还拿到了 SOLO 的内测码(虽然这个过程中并没有用到 SOLO 的功能)。所以突然想着自己用 AI,上手把这个前端干了!
前端框架
在阅读了 Deep Research 现有的代码,发现其用到了 2 个前端 UI 框架: Ant Design Vue 和 Ant Design X Vue
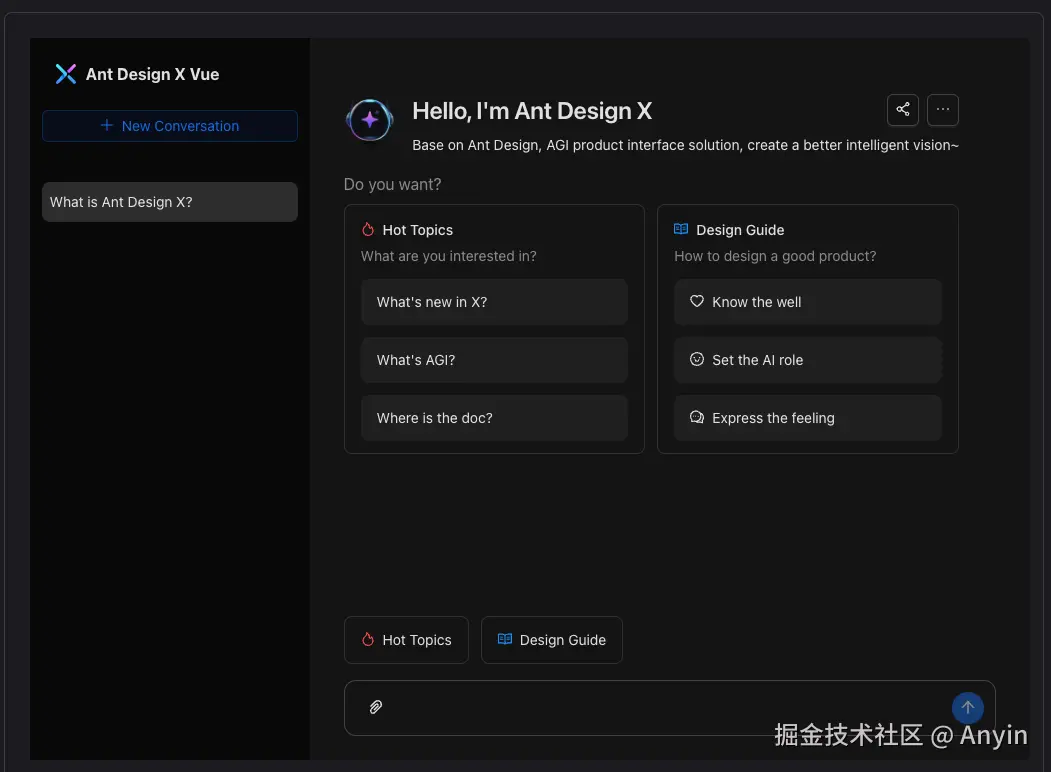
其中 Ant Design X Vue 是一个 AI界面的一个组件框架,包含基本的对话气泡组件、管理对话组件、输入框组件、思维链组件、流式请求组件、模型调度、数据管理等。
基于以上的组件,能够快速、方便的构建一个 AI 聊天界面。如下:
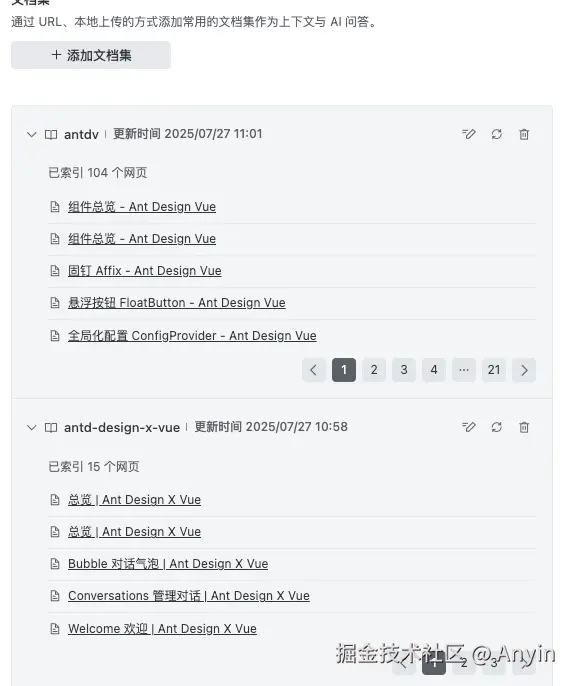
为了让 Trae 能够理解这 2 个框架,不以至于给我瞎写代码,我把这 2 个框架的相关信息放在 Trae 的文档集中,使得其能够知道这 2 个框架的使用。
梳理需求
OK ,在了解了现有的代码、使用的框架、并且和现有的开发者沟通了下,就可以开始梳理需求。
Deep Research 的前后端流程大概如下:
js
用户输入问题 -> 后端给出执行计划 -> 用户点击开始 -> 后端给出思考流程 -> 后端给出最终的报告前端需要做的内容是:
js
1. 根据后端给的消息列表,渲染对话气泡组件
2. 根据后端给的思考流程,渲染思维链组件
3. 根据后端给的最终报告结果,提供报告下载、在线预览功能对话气泡组件
对话气泡组件就是整个聊天窗口的主体,展示 AI 和 人类的对话历史记录。
对话组件的数据是一个 消息列表,这个列表的数据应该交由 数据管理组件进行管理(useXChat)。
useXChat 组件会依赖 模型调度组件(useXAgent),useXAgent 提供了和后端交互,抽象数据流。
所以基本流程为:
- 使用 useXAgent 和后端交互,拿到数据
- 把 useXAgent 拿到的数据交给 useXChat进行数据管理
- 从 useXChat 拿到 对话气泡组件需要的消息列表
- 最终根据 消息列表渲染 对话气泡组件
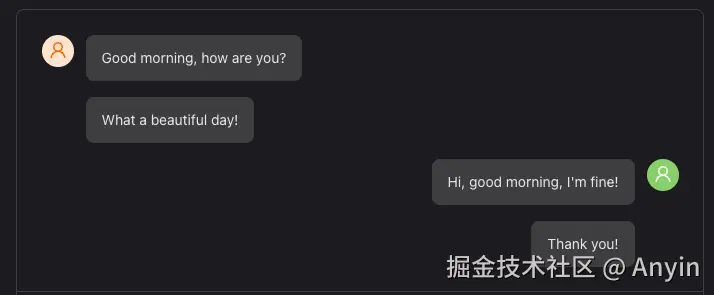
对话气泡组件效果如下:
思维链组件
思维链组件的数据来源也应该是从 useXChat 中获取(其实也是消息列表)
思维链组件需要处理的数据有以下几个问题:
- 对于后端返回的普通节点数据,一个普通节点就会渲染一个思维链的节点
- 对于后端返回的流式节点数据,流式节点数据是多次返回,只有全部返回之后才能正常渲染思维链节点,并且流式节点可能是并行返回,即同时返回多个 流式节点数据
- 思维链的 loading 节点渲染,在普通节点返回之后下一个节点未返回之前,需要渲染一个 loading 的节点;在返回的流式节点过程中,需要一直渲染 loading 节点
思维链组件效果如下:

报告展示组件
对于一个用户问题最终后端会返回基于这个问题的一个报告,这个报告可以下载为 PDF,也可以在线预览。
下载 PDF 的接口后端提供即可。
在线预览就比较特殊,它是一个交由大模型写一个前端页面的代码,并且流式返回给前端,前端拿到这些数据拼接成一个完整的 html 页面最终渲染在页面上。
在线预览有以下注意点:
- 后端必须保证大模型最终返回的内容是一个标准的 html 代码,否则会导致页面渲染错误
- 前端页面渲染需要加载外部资源,例如外部的:JS 、CSS 文件;同样需要加载内部 CSS 和 JS 脚本
- 前端页面渲染不能影响到外层的主体页面,因为大模型返回的内容不能保证是否会污染外层主体页面的样式等,这里可以使用 iframe 解决
代码实现
对话气泡列表
js
const bubbleList = computed(() => {
const len = messages.value.length
messageStore.history[convId] = messages.value
// 当状态是loading的时候,是每个chunk,然后succes,把之前所有的chunk 全部返回
return messages.value.map(({ id, message, status }, idx) => ({
key: id,
role: status === 'local' ? 'local' : 'ai',
content: parseMessage(status, message, idx === len - 1),
footer: parseFooter(status, idx === len - 1),
}))
})bubbleList 就是对话气泡列表需要的数据,它是由历史消息记录 messages 转换过来的
messages 的数据由是从 useXChat 中获取的
js
const { onRequest, messages } = useXChat({
agent: agent.value,
requestPlaceholder: 'Waiting...',
requestFallback: 'Failed return. Please try again later.',
})useXChat 组件依赖 useXAgent 组件,它的数据来源都是useXAgent 提供的。
js
const [agent] = useXAgent({
request: async ({ message }, { onSuccess, onUpdate, onError }) => {
let content = ''
switch (current.aiType) {
case 'normal':
case 'startDS': {
content = await sendChatStream(message, onUpdate, onError)
break
}
case 'onDS': {
current.deepResearchDetail = true
content = await (configStore.chatConfig.auto_accepted_plan ? sendChatStream(message, onUpdate, onError) : sendResumeStream(message, onUpdate, onError))
break
}
}
// 最后会返回本次stream的所有内容
onSuccess(content)
},
})以上为请求后端的核心代码。
message 就是用户发送的消息内容
onUpdate 在后端使用流式返回的时候,每一个 chunk 都可以通过 onUpdate方法传递给 messages。
举例:
js
用户消息:草莓蛋糕怎么做?
后端返回第一个 chunk: 这是第一个 chunk
后端返回第二个 chunk: 这是第二个 chunk这个时候调用了 onUpdate 方法的时候,messages 的值变更如下:
json
第一个 chunk 返回的时候:{ status: 'loading', messages: [ { role: '用户', msg: '草莓蛋糕怎么做?'}, { role: 'AI': msg: '这是第一个 chunk' } ]}
第二个 chunk 返回的时候:{ status: 'loading', messages: [ { role: '用户', msg: '草莓蛋糕怎么做?'}, { role: 'AI': msg: '这是第二个 chunk' } ]}onSuccess 在后端使用流式返回的时候,可以通过 onSuccess 方法把所有 chunk 拼接好的内容一次性变更到 messages 的值
举例:
js
用户消息:草莓蛋糕怎么做?
后端返回第一个 chunk: 这是第一个 chunk
后端返回第二个 chunk: 这是第二个 chunk在所有 chunk 返回之后,这个时候调用了 onSuccess方法,messges 的值变更如下:
js
{ status: 'success', messages: [ { role: '用户', msg: '草莓蛋糕怎么做?'}, { role: 'AI': msg: '这是第二个 chunk 这是第二个 chunk' } ]}可以看到,在调用 onUpdate的时候返回的状态是 loading,而调用 success 返回的状态是 success
思维链组件
思维链组件的处理就会比较复杂:
- 已经完成对话的历史消息列表的思维链渲染
- 当前正在对话中的消息列表的思维链渲染
2.1 普通节点的渲染
2.2 流式节点的渲染
2.3 Pending 状态节点渲染
js
messages.forEach(msg => {
// 单个chunk
// xchat组件的第一个chunk是 Waiting... 所以需要跳过
if(msg.status === 'loading' && msg.message != 'Waiting...') {
isLoading = true
const node = JSON.parse(msg.message)
if(node.nodeName) {
processJsonNodeLogic(node)
}else{
processLlmStreamNodeLogic(node)
}
}
// 完整的text, 历史记录的渲染
// 当stream完成,xchat还会返回一次success,为避免思维链重复渲染,如果是loading状态,则不在重复增加节点
if(msg.status === 'success' && !isLoading) {
isLoading = false
const jsonArray = parseJsonTextStrict(msg.message)
jsonArray.forEach(node => {
if(node.nodeName) {
processJsonNodeLogic(node)
}else{
processLlmStreamNodeLogic(node)
}
})
}
})对于已经完成对话的历史消息的渲染,需要使用 parseJsonTextStrict 方法对消息进行格式化下,转为消息数组。因为后端对于每个 chunk 返回其实都是一个标准 JSON 字符串,一个流式完整返回的时候,所有的 chunk 拼接就会变成类似以下状态:
js
{ nodeName: 'node1', content: '这是第一个节点的内容'} { nodeName: 'node2', content: '这是第二个节点的内容'}对于普通节点,既有 nodeName 属性使用 processJsonNodeLogic 方法进行渲染
对于流式节点,没有 nodeName 属性使用 processLlmStreamNodeLogic 方法进行渲染
processJsonNodeLogic 方法代码如下:
js
const processJsonNodeLogic = (node: any) => {
// 普通节点:完成之前的流式节点,然后处理当前节点
finalizePreviousStreamNodes('')
// 渲染普通节点
processJsonNode(node)
// 普通节点处理完后,添加pending节点
appendPendingNode()
// information 或者 end 节点 说明等待用户反馈 或者 结束
if(node.nodeName === 'planner' || node.nodeName === '__END__'){
removeLastPendingNode()
}
}processLlmStreamNodeLogic 方法代码如下:
js
// 处理llm_stream节点
const processLlmStreamNodeLogic = (node: any) => {
if(!node.visible) {
return
}
let item: ThoughtChainItem | undefined
// llm_stream 形式的节点,需要流式渲染
// 动态遍历node对象的key,只要包含'llm_stream'就执行相应处理
const llmStreamKeys = Object.keys(node).filter(key => key.includes('llm_stream'))
for (const key of llmStreamKeys) {
// 流式节点:移除pending节点,完成之前的流式节点
removeLastPendingNode()
finalizePreviousStreamNodes(key)
item = processLlmStreamNode(node, key)
}
if(item) {
// 检查是否已经存在相同的item(针对llm_stream节点)
const existingIndex = arrayTemp.findIndex(existingItem => existingItem === item)
if(existingIndex === -1) {
arrayTemp.push(item)
}
}
}对于流式节点返回的处理代码还不够完善,因为当流式节点是多个一起返回的时候,就会造成返回的流式节点都是 success 状态,但是期望是 loading 状态。
这是是因为目前流式节点返回的内容并没有一个 stop 标示这个流式节点完全返回,所以这里临时做法是 移除 loading 状态的节点 和 success之前的流式节点,这样子就会造成并行情况下,所有的流式节点都会变成 success 状态。
目前后端已经增加 stop 标识,等着我补充代码
报告展示组件
报告展示组件主要是渲染后端返回的 Html 页面。 这里的逻辑就比较简单了,使用 iframe 标签包裹,然后把后端返回的 html chunk 拼接即可。
JS 代码
js
// iframe内容(用于预览视图)
const iframeContent = computed(() => {
if (!accumulatedHtml.value) return ''
// 确保HTML内容包含完整的文档结构
let htmlContent = accumulatedHtml.value.trim()
return htmlContent
})页面代码
html
<iframe
ref="htmlIframe"
class="html-content"
:srcdoc="iframeContent"
sandbox="allow-scripts allow-same-origin allow-forms allow-popups"
></iframe> 整个报告展示组件,都是使用 Trae 代码生成的,一行代码没有写。 AI 写前端代码,是真的香啊
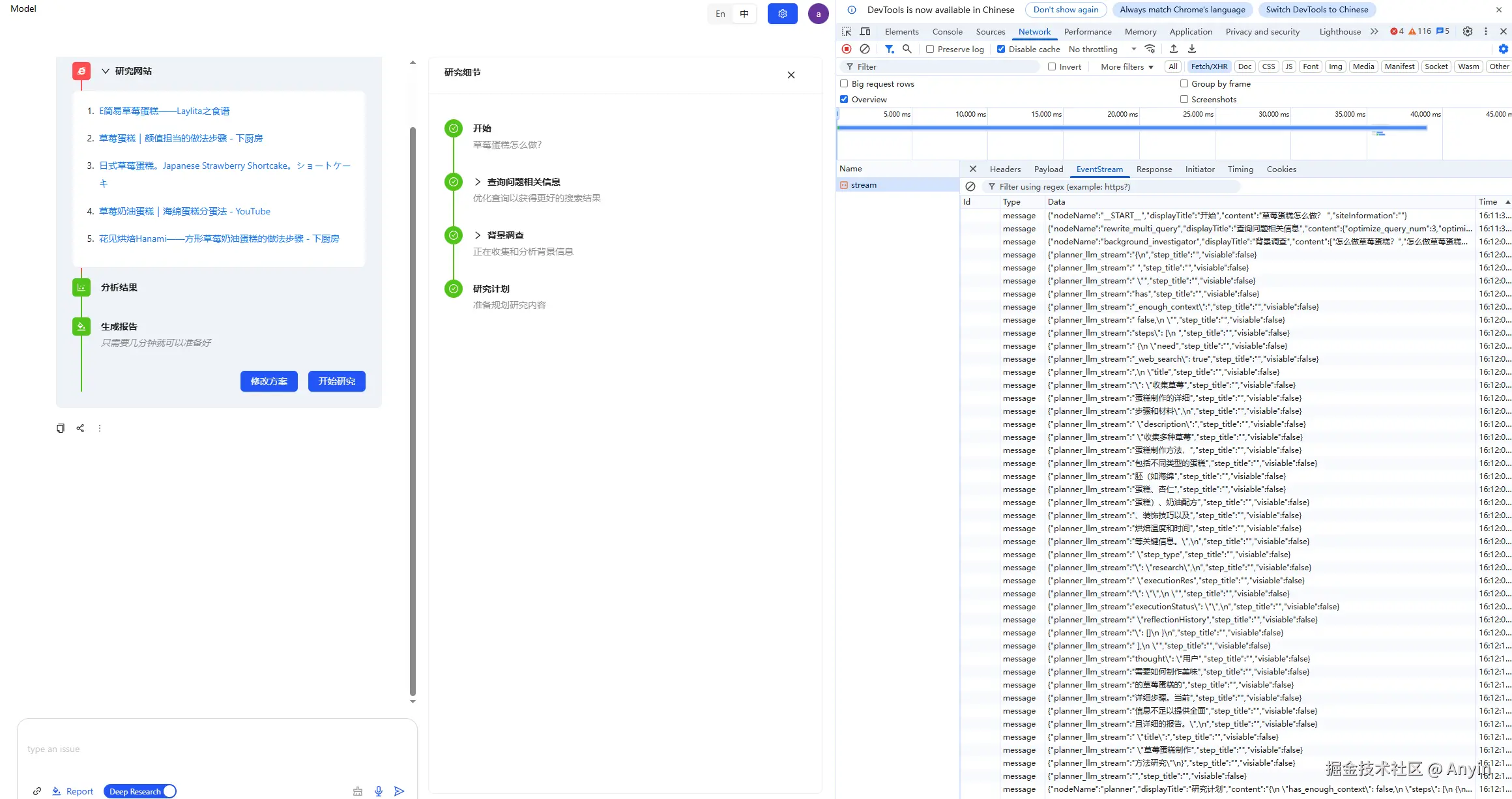
相关截图
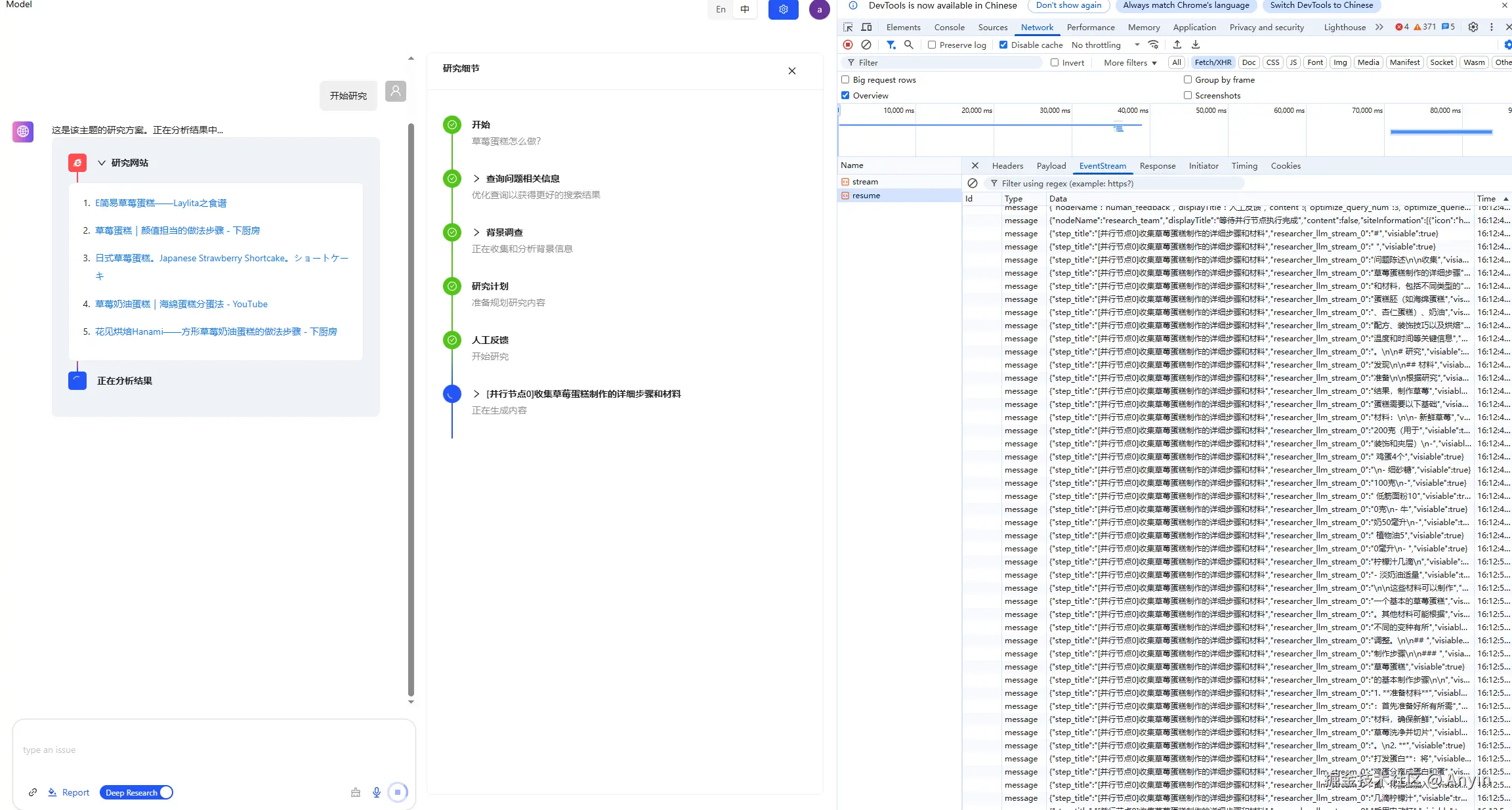
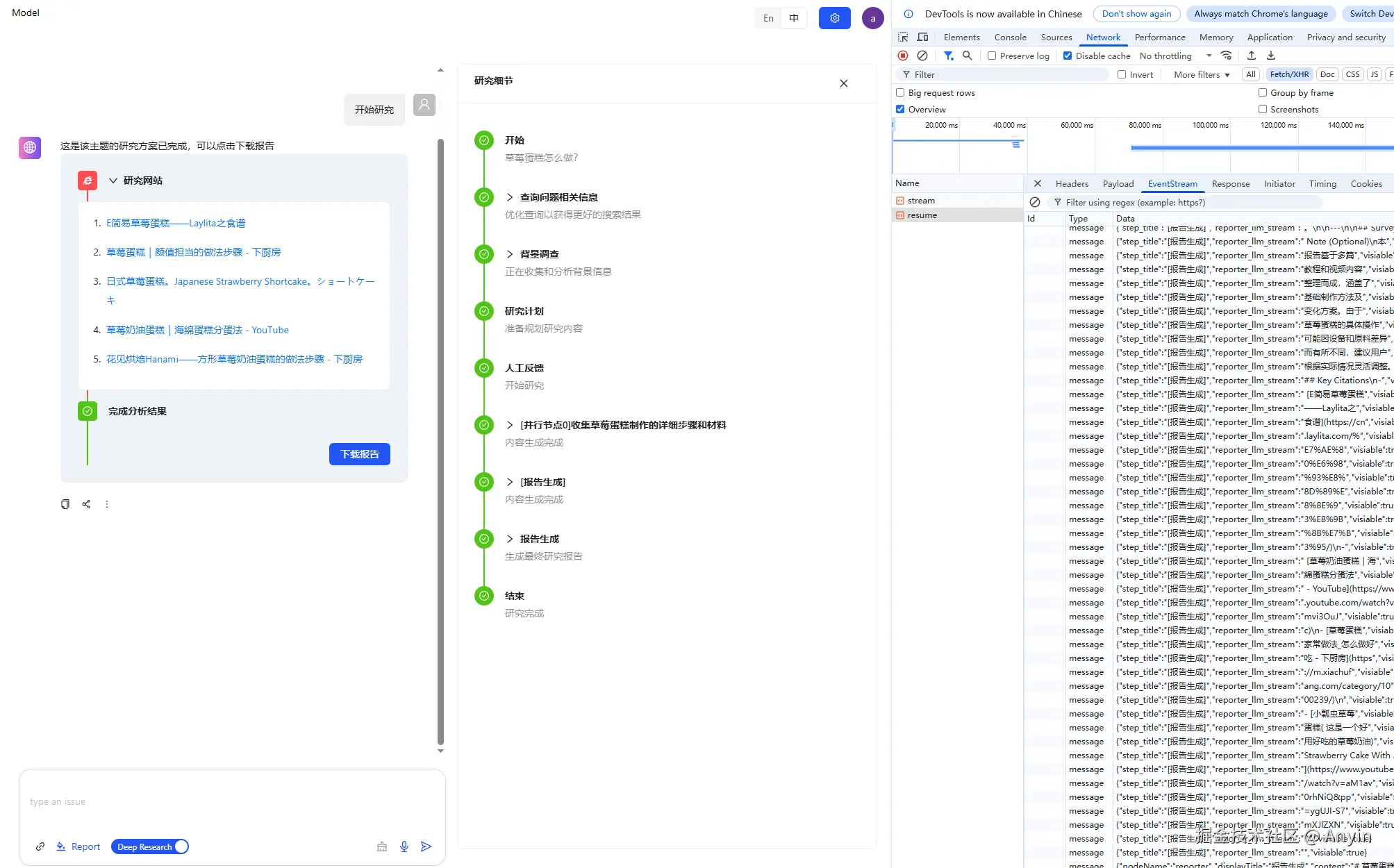
总结
首先,不得再说下 使用 AI 写代码是真的香,很多重复性工作、确定性的内容、CSS 样式等都是可以使用 AI 写的,例如: parseJsonTextStrict 方法、报告展示组件的样式、各种类型定义等
其次,在这个过程通过多次Debug、梳理相关逻辑,明白前后端交互逻辑,也熟悉后端代码的工作流程,后面应该还会再写一个后端代码相关总结
最后,以上如果有哪里不对欢迎指正 和 讨论。
本次前端主体 UI 构建完整的代码地址: github.com/alibaba/spr...