Summary
LLM 现在的发展是日异月新,但是目前还是有一个关键的问题:LLM 很擅长推理,也很擅长执行,但是没办法同时将两者结合起来。
ReAct framework 就是以一种交错的方式生成推理轨迹和特定任务的执行,大模型就是根据生成的推理轨迹来制定下一步的执行计划。ReAct framework 就可以使得 LLM 调用外部工具获取外部信息,这样就可以避免 LLM 幻觉,产生更加可靠,更加准确的响应。同时,ReAct 输出了推理过程和执行的操作,提高了对 LLM 可解释性和信任度
What is ReAct
下面这个是分离了推理和执行的过程
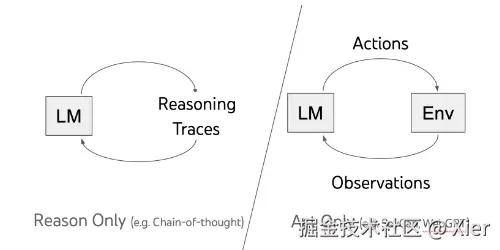
而 ReAct 就是将两者结合在了一起,这样就能够保证在执行操作时,有足够的真实信息,一定程度提升准确度:
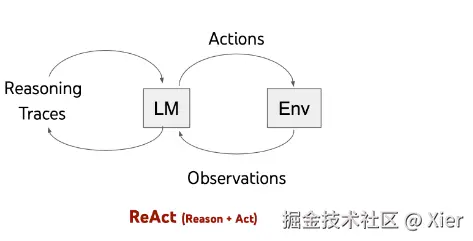
How ReAct
ReAct framework 就是可以使 LLM 采取额外的行为,比如:访问 Goole,运行计算等,获取得到额外的信息,告诉程序如何执行这些操作,并且将操作的结果再返回给 LLM,由 LLM 决定下一步的动作。下面是一个具体的例子:
具体的代码如下:
python
import openai
import re
import httpx
openai.api_key = "sk-..."
class ChatBot:
def __init__(self, system=""):
self.system = system
self.messages = []
if self.system:
self.messages.append({"role": "system", "content": system})
def __call__(self, message):
self.messages.append({"role": "user", "content": message})
result = self.execute()
self.messages.append({"role": "assistant", "content": result})
return result
def execute(self):
completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=self.messages)
# Uncomment this to print out token usage each time, e.g.
# {"completion_tokens": 86, "prompt_tokens": 26, "total_tokens": 112}
# print(completion.usage)
return completion.choices[0].message.content
prompt = """
You run in a loop of Thought, Action, PAUSE, Observation.
At the end of the loop you output an Answer
Use Thought to describe your thoughts about the question you have been asked.
Use Action to run one of the actions available to you - then return PAUSE.
Observation will be the result of running those actions.
Your available actions are:
calculate:
e.g. calculate: 4 * 7 / 3
Runs a calculation and returns the number - uses Python so be sure to use floating point syntax if necessary
wikipedia:
e.g. wikipedia: Django
Returns a summary from searching Wikipedia
simon_blog_search:
e.g. simon_blog_search: Django
Search Simon's blog for that term
Always look things up on Wikipedia if you have the opportunity to do so.
Example session:
Question: What is the capital of France?
Thought: I should look up France on Wikipedia
Action: wikipedia: France
PAUSE
You will be called again with this:
Observation: France is a country. The capital is Paris.
You then output:
Answer: The capital of France is Paris
""".strip()
action_re = re.compile('^Action: (\w+): (.*)$')
def query(question, max_turns=5):
i = 0
bot = ChatBot(prompt)
next_prompt = question
while i < max_turns:
i += 1
result = bot(next_prompt)
print(result)
actions = [action_re.match(a) for a in result.split('\n') if action_re.match(a)]
if actions:
# There is an action to run
action, action_input = actions[0].groups()
if action not in known_actions:
raise Exception("Unknown action: {}: {}".format(action, action_input))
print(" -- running {} {}".format(action, action_input))
observation = known_actions[action](action_input)
print("Observation:", observation)
next_prompt = "Observation: {}".format(observation)
else:
return
def wikipedia(q):
return httpx.get("<https://en.wikipedia.org/w/api.php>", params={
"action": "query",
"list": "search",
"srsearch": q,
"format": "json"
}).json()["query"]["search"][0]["snippet"]
def simon_blog_search(q):
results = httpx.get("<https://datasette.simonwillison.net/simonwillisonblog.json>", params={
"sql": """
select
blog_entry.title || ': ' || substr(html_strip_tags(blog_entry.body), 0, 1000) as text,
blog_entry.created
from
blog_entry join blog_entry_fts on blog_entry.rowid = blog_entry_fts.rowid
where
blog_entry_fts match escape_fts(:q)
order by
blog_entry_fts.rank
limit
1""".strip(),
"_shape": "array",
"q": q,
}).json()
return results[0]["text"]
def calculate(what):
return eval(what)
known_actions = {
"wikipedia": wikipedia,
"calculate": calculate,
"simon_blog_search": simon_blog_search
}
## 执行:
query("Fifteen * twenty five")
Thought: The action required is a calculation
Action: calculate: 15 * 25
PAUSE
-- running calculate 15 * 25
Observation: 375
Answer: Fifteen times twenty five equals 375.
query("What does England share borders with?")
Thought: I should list down the neighboring countries of England
Action: wikipedia: England
PAUSE
-- running wikipedia England
Observation: <span class="searchmatch">England</span> is a country that is part of the United Kingdom. It shares land borders with Wales to its west and Scotland to its north. The Irish Sea lies northwest
Answer: England shares borders with Wales and Scotland.Ending
ReAct 是一个反复调用 LLM 进行推断,执行,观察的过程,相比较于 Function Calling,ReAct 能通过多次迭代收集足够的外部真实信息,以此来减少 LLM 的幻觉,提高响应的准确度。但是, ReAct 也很有可能陷入到循环当中,最好是在循环中设置一个 MAX_Iteration_Step,防止出现过度的迭代。