备注 :为了方便理解记忆,在此总结归纳(注:笔者水平有限,若有描述不当之处,欢迎大家留言)。
阐述的思维逻辑:会给出大的结构类型,后续会继续整理对应的代表方法。
LLM结构类型: 自回归模型(AR) 扩散语言模型(DLMs)
|-encode-decoder; |-连续空间DLMs
|-dencoder-only; |-离散空间DLMs
|-decoder-only; |-混合AR-DLMs
一 基础理解
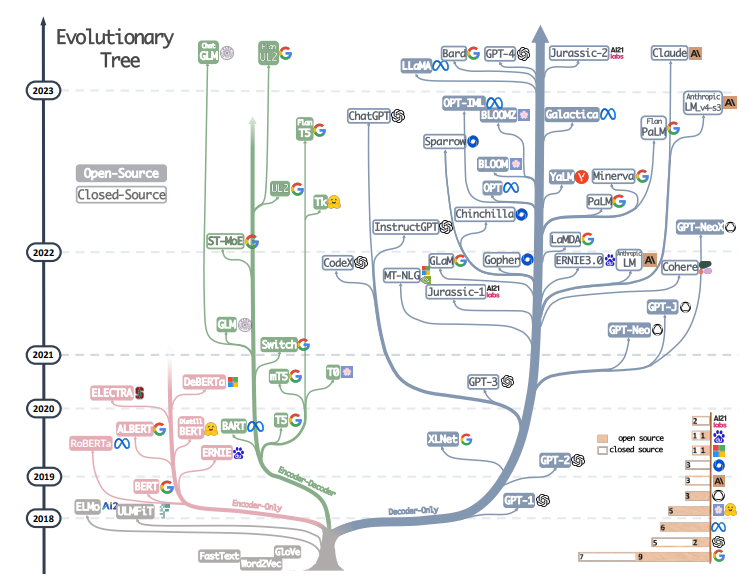
1.1 自回归模型(AR)
Encoder-only :拥有双向的注意力机制,即计算每一个词的特征时都看到完整上下文。专注于理解 和分析输入的信息,而不是创造新的内容。(阅读和理解一本书的内容)
优点:强大的理解能力 ;适应性广泛(多种分析型任务)
缺点:生成能力有限:不擅长自主生成文本和内容
Decoder-only : 拥有单向的注意力机制,即计算每一个词的特征时都只能看到上文,无法看到下文。更好的理解和预测语言模式,尤其适合处理开放式的,生成式性的任务。 (擅长写作或者生成文章)
优点:强大的生成能力:能够生成连贯,有创造性的文本
灵活性:各种生成型任务
缺点:有限的理解能力:不擅长理解复杂的输入数据
Encoder-decoder: Encoder部分使用双向的注意力,Decoder部分使用单向注意力(之所以能够在某些场最下表现更好,大概只是因为它多了一倍参数。)擅长处理需要理解输入 然后生成相关输出 的任务,(翻译和问答系统**)**。
优点: 灵活强大:能够理解复杂输入并生成相关输出
适用于复杂任务:机器翻译,文本摘要等。
缺点:架构复杂:相比单一的Encoder和Decoder,它更复杂
训练挑战:需要更多的训练数据和计算资源
1.2 扩散语言模型(DLMs)
连续空间DLMs:将离散的文本token映射到连续的嵌入空间(如通过预训练语言模型的Embedding层),在连续空间中完成「加噪-去噪」过程,最后通过「 nearest-neighbor搜索」或「解码器」将连续嵌入映射回离散token。
优点:继承图像扩散模型的成熟技术,例如可直接使用DDPM、Rectified Flow等经典扩散框架,且连续空间的数学性质更易优化
缺点:嵌入-映射 过程会损失部分语言语义,且生成的token可能存在语义偏差(如生成与目标语义相近但不匹配的词)
离散空间DLMs:无需转换到连续空间,直接在「token词汇表」上定义扩散过程------通过「结构化转移矩阵」将干净token逐步替换为特殊的MASK(加噪),再训练模型从MASK中恢复原始token(去噪)。
优点:无语义损失,扩散过程完全在离散语言空间进行,生成的token更符合语言习惯,且无需额外的「映射步骤」,推理流程更简洁。
离散空间DLMs还在长序列处理上取得突破
缺点:
混合AR-DLMs:结合AR模型的「长程依赖建模能力」与DLM的「并行生成能力」,典型方案是「块级AR+块内DLM」------将文本分为多个块,块与块之间采用AR生成(保证全局连贯),块内部采用DLM并行生成(提升速度)。
优点:「兼顾质量与效率」------既避免了纯DLM「并行解码诅咒」(并行生成导致token间依赖丢失),又解决了纯AR「速度慢」的问题。
缺点:
二 进阶理解
2.1 为何现在的LLM大都是Decoder only的架构
1 总述:Encoder-only专注于理解和分析输入的信息,不擅长生成任务。Decoder-only: 更好的理解和预测语言模式,适合处理开放式的,生成式性的任务。在各种下游任务(zero-shot和few-shot)上泛华性都很好。
2 展开论述的思路:现状-->泛化性-->效率-->生态-->展望
现状:基于现在新出的模型结构和研究的经验来说,decoder-only 的泛化性能更好:
新出的模型:llama,PaLM等
研究经验:What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization在最⼤ 5B 参数量、170B token 数据量的规模下做了一些列实验,发现用 next token prediction 预测训练的 decoder-only 模型在各种下游任务之zero-shot 泛化性能最好;另外,许多工作表明 decoder-only 模型的few-shot(也就是上下文学习,in-context learning)泛化能力更强。
泛化性能更好的潜在原因:1. @苏剑林 苏神提出的注意力稀疏的问题,双向 attention 的注意力矩阵容易收敛为低秩状态,而 causal attention* 的注意力矩阵是下三⻆矩阵,必然是稠密的,建模能力更强;
2. @yili ⼤佬强调的预测任务难度问题,纯粹的 decoder-only 架构 + next token prediction 训练,每个 token 任务都依赖全部上文信息,任务定义的预测难度更⾼,当模型足够⼤、采样更充⾜的时侯,decoder-only 模型学习到通用模式的上限更⾼;
3. @mimimum ⼤佬强调,上下文学习为 decoder-only 架构带来的更好的 few-shot 能⼒:
prompt 和 demonstration 的信息可以视为对模型参数的隐式微调,decoder-only 的架构相比 encoder-decoder 在 in-context learning 上会具有优势,因为 prompt 可以更直接地作用于 decoder 每一层的参数,微调的信号更强;
4. 多位⼤佬强调了一个很容易被忽视的属性,causal attention(就是 decoder-only 的单向 attention)具有隐式的位置信息映射,
打破了 transformer 的位置信不变性,而带有双向attention的模型,如果不显式加 position embedding,双向 attention 的部分 token 可以掉换也不改变表示,对语言的序列区分能力弱。
效率: decoder-only 支持一直复⽤ KV-Cache*,对多 token 语境更友好,因为每个 token 任务只和它之前的信息有关,而 encoder-decoder 就难以做到。
生态 :在OpenAI 作为开拓者使用decoder-only在结果上大放异彩,目前很多厂商都在decoder-only上发力。OpenAI 作为开拓者肯定要⼲最纯粹的事,以 decoder-only 架构的 simplicity 为优雅和可扩展的训练方法和 Scaling Law,尽管当时 KV-Cache 还没引⼊时计算成本⼤,⾃然不太能做⼤参数的⼤⽹络,继续采⽤ decoder-only 架构。在工程生态上,decoder-only 架构也形成了先发优势,Megatron* 和 flash attention* 等重要⼯具对 causal attention 的⽀持更好。
展望 :目前decoder-only在使用过程中也遇到效率和扩展等问题**,现在已经有一些工作在探索DLMs等架构,** 还没有特别系统的实验证据能说明 decoder-only 一定更好,
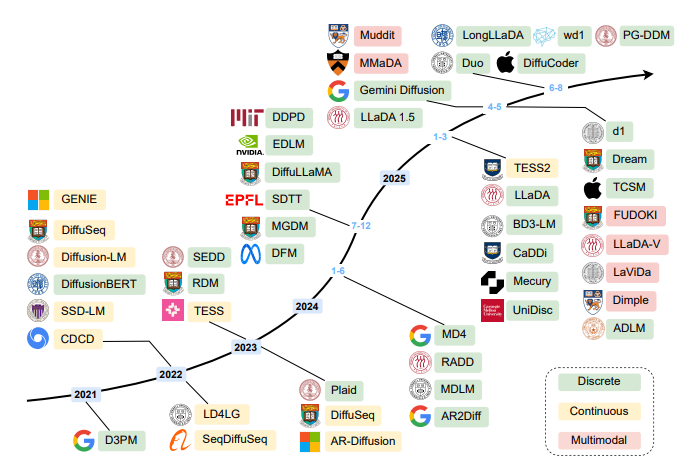
2.2 DLMS
todo.......
四 参考文献
1 Survey of different Large Language Model Architectures: Trends, Benchmarks, and Challenges(https://arxiv.org/pdf/2412.03220)
2 Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond(https://arxiv.org/pdf/2304.13712)
3 A Survey of Large Language Models(https://arxiv.org/pdf/2303.18223)
4 为何现在的LLM都是Decoder-only的架构: https://kexue.fm/archives/9529
5 A Survey on Diffusion Language Models(https://arxiv.org/pdf/2508.10875)
6 The Big LLM Architecture Comparison(https://sebastianraschka.com/blog/2025/the-big-llm-architecture-comparison.html)
7 What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?(https://arxiv.org/pdf/2204.05832)
8 LLaMA: Open and Efficient Foundation Language Models
9 PaLM: Scaling Language Modeling with Pathways
10 why can gpt learn in-context language models implicitly perform gradient descent as meta-optimizers