客户流失是银行业面临的重大挑战,获取新客户的成本往往是保留现有客户的5倍。本文将通过Python实现一个完整的客户流失预测分析系统,帮助银行识别高风险客户并采取针对性措施。kaggle数据集
一、环境准备与库导入
首先,我们需要导入数据分析和机器学习所需的各类库。这些库将帮助我们完成数据加载、预处理、可视化和模型构建等任务。
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, confusion_matrix, classification_report, roc_curve
import warnings
warnings.filterwarnings('ignore')
plt.style.use('seaborn-whitegrid')代码原理解释:
- 通过
pandas和numpy提供数据结构和数值计算支持 - 使用
matplotlib和seaborn实现数据可视化 - 从
sklearn导入机器学习相关模块,包括数据集拆分、特征预处理、模型和评估指标 - 设置忽略警告信息以保持输出整洁,并使用
seaborn-whitegrid风格美化图表
二、数据集介绍
本分析使用的客户流失数据集包含10000条客户记录,涵盖客户基本信息、账户特征和行为数据等维度。各字段含义如下:
2.1 标识信息
| 字段名称 | 中文描述 | 对流失的影响 |
|---|---|---|
| RowNumber | 记录编号 | 无影响 |
| CustomerId | 客户ID | 无影响 |
| Surname | 客户姓氏 | 无影响 |
2.2 客户特征
| 字段名称 | 中文描述 | 对流失的影响 |
|---|---|---|
| CreditScore | 信用评分 | 评分越高,流失可能性越低 |
| Geography | 所在地区 | 地区差异会影响流失率 |
| Gender | 性别 | 需要探索其与流失的关系 |
| Age | 年龄 | 年长客户更不易流失 |
| Tenure | 账户年限 | 年限越长,客户忠诚度越高 |
2.3 账户信息
| 字段名称 | 中文描述 | 对流失的影响 |
|---|---|---|
| Balance | 账户余额 | 余额越高,流失可能性越低 |
| NumOfProducts | 产品数量 | 购买产品越多,客户粘性越高 |
| HasCrCard | 是否有信用卡 | 有信用卡的客户更不易流失 |
| IsActiveMember | 是否活跃会员 | 活跃会员流失率更低 |
| EstimatedSalary | 估计薪资 | 薪资越低,流失可能性越高 |
2.4 服务质量与反馈
| 字段名称 | 中文描述 | 对流失的影响 |
|---|---|---|
| Complain | 是否有投诉 | 有投诉客户流失风险高 |
| Satisfaction Score | 满意度评分 | 评分低的客户易流失 |
| Card Type | 卡片类型 | 影响客户使用体验 |
| Points Earned | 积分获取 | 积分越多,客户忠诚度可能越高 |
2.5 目标变量
| 字段名称 | 中文描述 | 说明 |
|---|---|---|
| Exited | 是否流失 | 1=流失,0=未流失 |
数据集特点:包含18个特征字段,既有数值型也有分类型变量,目标变量为二分类(是否流失)。数据无缺失值,可直接用于建模分析。
三、数据加载与初步探索
了解数据集结构后,我们开始加载客户数据并进行初步探索,验证数据质量。
python
# 加载数据
df = pd.read_csv('Customer-Churn-Records.csv')
# 查看数据基本信息
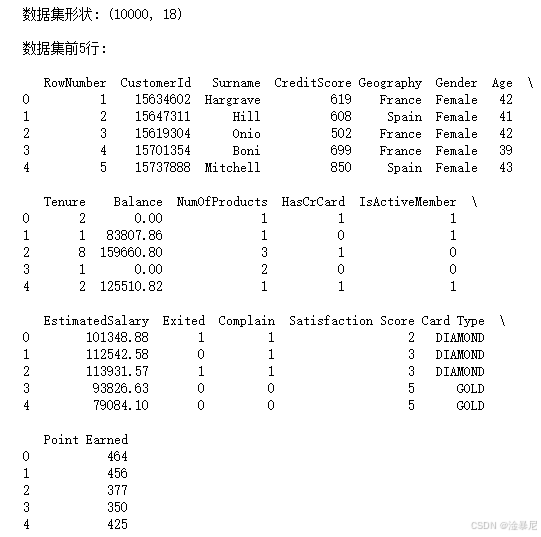
print(f"数据集形状: {df.shape}")
print("\n数据集前5行:\n")
print(df.head())
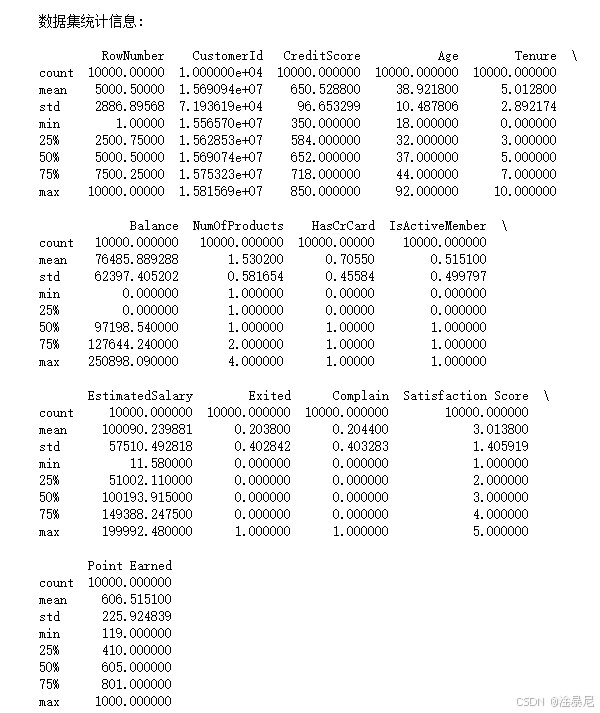
print("\n数据集统计信息:\n")
print(df.describe())
print("\n数据集缺失值情况:\n")
print(df.isnull().sum())代码原理解释:
- 使用
pd.read_csv()读取CSV格式的客户数据 - 通过
df.shape查看数据集的行数和列数,了解数据规模 - 利用
df.head()显示前5行数据,初步了解数据结构和内容 - 使用
df.describe()获取数值型特征的统计信息,包括均值、标准差、最值等 - 通过
df.isnull().sum()检查各列缺失值情况,因为缺失值会影响模型性能,需要提前处理

三、数据预处理
因为原始数据可能包含噪声、冗余信息或格式不统一的问题,所以在建模前需要进行预处理,确保数据质量。
python
# 删除不需要的列
df = df.drop(['RowNumber', 'CustomerId', 'Surname'], axis=1)
# 定义特征和目标变量
X = df.drop('Exited', axis=1)
y = df['Exited']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# 定义特征预处理管道
numeric_features = ['CreditScore', 'Age', 'Tenure', 'Balance', 'NumOfProducts', 'EstimatedSalary', 'Point Earned']
categorical_features = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'Complain', 'Satisfaction Score', 'Card Type']
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), numeric_features),
('cat', OneHotEncoder(drop='first', sparse_output=False), categorical_features)
])代码原理解释:
- 首先删除无关特征(RowNumber、CustomerId、Surname),因为这些个人标识信息对预测客户流失没有实际意义
- 将数据集分为特征变量(X)和目标变量(y),其中目标变量是'Exited'(是否流失)
- 使用
train_test_split将数据按8:2比例划分为训练集和测试集,设置stratify=y确保分层抽样,保持与原始数据相似的流失率分布 - 定义数值型和分类型特征列表,因为这两类特征需要不同的预处理方式
- 创建预处理管道:通过
StandardScaler对数值特征进行标准化(均值为0,标准差为1),通过OneHotEncoder对分类特征进行独热编码,drop='first'参数用于避免多重共线性问题
四、探索性数据分析
通过探索性数据分析,我们可以发现数据中的模式和关系,为后续建模提供指导。
python
# 设置图形大小
plt.figure(figsize=(18, 12))
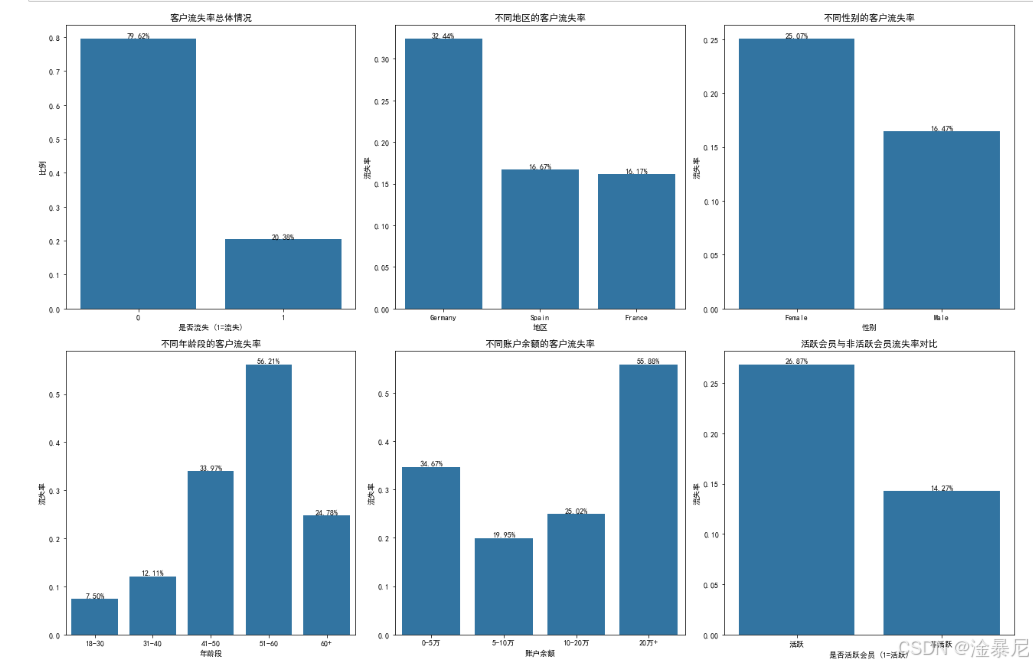
# 1. 客户流失率总体情况
plt.subplot(2, 3, 1)
churn_rate = df['Exited'].value_counts(normalize=True)
ax = sns.barplot(x=churn_rate.index, y=churn_rate.values)
ax.set_title('客户流失率总体情况', fontsize=12)
ax.set_xlabel('是否流失 (1=流失)')
ax.set_ylabel('比例')
for p in ax.patches:
ax.annotate(f'{p.get_height():.2%}', (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='bottom', fontsize=10)
# 2. 不同地区的客户流失率
plt.subplot(2, 3, 2)
geo_churn = df.groupby('Geography')['Exited'].mean().sort_values(ascending=False)
ax = sns.barplot(x=geo_churn.index, y=geo_churn.values)
ax.set_title('不同地区的客户流失率', fontsize=12)
ax.set_xlabel('地区')
ax.set_ylabel('流失率')
for p in ax.patches:
ax.annotate(f'{p.get_height():.2%}', (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='bottom', fontsize=10)
# 3. 不同性别的客户流失率
plt.subplot(2, 3, 3)
gender_churn = df.groupby('Gender')['Exited'].mean().sort_values(ascending=False)
ax = sns.barplot(x=gender_churn.index, y=gender_churn.values)
ax.set_title('不同性别的客户流失率', fontsize=12)
ax.set_xlabel('性别')
ax.set_ylabel('流失率')
for p in ax.patches:
ax.annotate(f'{p.get_height():.2%}', (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='bottom', fontsize=10)
# 4. 年龄与流失率的关系
plt.subplot(2, 3, 4)
df['AgeGroup'] = pd.cut(df['Age'], bins=[18, 30, 40, 50, 60, 100], labels=['18-30', '31-40', '41-50', '51-60', '60+'])
age_churn = df.groupby('AgeGroup')['Exited'].mean().sort_index()
ax = sns.barplot(x=age_churn.index, y=age_churn.values)
ax.set_title('不同年龄段的客户流失率', fontsize=12)
ax.set_xlabel('年龄段')
ax.set_ylabel('流失率')
for p in ax.patches:
ax.annotate(f'{p.get_height():.2%}', (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='bottom', fontsize=10)
# 5. 账户余额与流失率的关系
plt.subplot(2, 3, 5)
df['BalanceGroup'] = pd.cut(df['Balance'], bins=[0, 50000, 100000, 200000, 300000], labels=['0-5万', '5-10万', '10-20万', '20万+'])
balance_churn = df.groupby('BalanceGroup')['Exited'].mean().sort_index()
ax = sns.barplot(x=balance_churn.index, y=balance_churn.values)
ax.set_title('不同账户余额的客户流失率', fontsize=12)
ax.set_xlabel('账户余额')
ax.set_ylabel('流失率')
for p in ax.patches:
ax.annotate(f'{p.get_height():.2%}', (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='bottom', fontsize=10)
# 6. 活跃会员与流失率的关系
plt.subplot(2, 3, 6)
active_churn = df.groupby('IsActiveMember')['Exited'].mean().sort_values(ascending=False)
ax = sns.barplot(x=active_churn.index, y=active_churn.values)
ax.set_title('活跃会员与非活跃会员流失率对比', fontsize=12)
ax.set_xlabel('是否活跃会员 (1=活跃)')
ax.set_ylabel('流失率')
ax.set_xticklabels(['活跃', '非活跃'])
for p in ax.patches:
ax.annotate(f'{p.get_height():.2%}', (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='bottom', fontsize=10)
plt.tight_layout()
plt.savefig('churn_eda.png', dpi=300, bbox_inches='tight')
plt.show()
# 删除临时创建的分组列
df = df.drop(['AgeGroup', 'BalanceGroup'], axis=1)代码原理解释:
- 首先创建一个2行3列的图形布局,用于同时展示多个可视化结果
- 通过
value_counts(normalize=True)计算总体流失率,使用柱状图可视化 - 利用
groupby和mean()计算不同分组(地区、性别、年龄段等)的流失率,通过柱状图比较差异 - 使用
pd.cut()将连续变量(年龄、余额)分箱,转换为类别变量以便分析 - 在每个柱状图上添加数值标签,使结果更直观
- 通过
plt.tight_layout()调整布局,避免图形重叠 - 使用
plt.savefig()保存图形,并通过plt.show()显示图形 - 最后删除临时创建的分组列,保持数据整洁
五、特征相关性分析
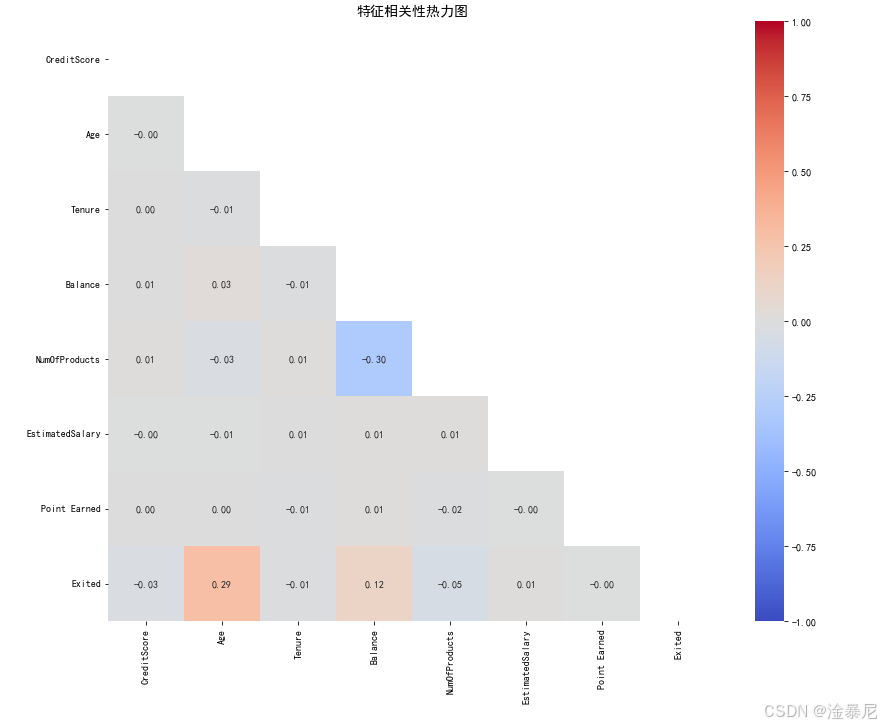
特征之间的相关性会影响模型解释性和性能,通过相关性分析可以识别多重共线性问题。
python
# 计算特征相关性
plt.figure(figsize=(12, 10))
correlation = df[numeric_features + ['Exited']].corr()
mask = np.triu(np.ones_like(correlation, dtype=bool))
sns.heatmap(correlation, annot=True, fmt='.2f', cmap='coolwarm', mask=mask, vmin=-1, vmax=1)
plt.title('特征相关性热力图', fontsize=14)
plt.tight_layout()
plt.show()代码原理解释:
- 首先使用
corr()计算数值型特征与目标变量之间的相关系数,衡量线性关系强度 - 创建上三角掩码(
mask),用于在热力图中只显示下三角部分,避免重复信息 - 通过
sns.heatmap()绘制热力图,annot=True显示具体相关系数值,fmt='.2f'保留两位小数 - 使用
coolwarm颜色映射,红色表示正相关,蓝色表示负相关,颜色深浅表示相关程度 - 添加标题并调整布局,使图形更易读
六、构建和训练模型
通过前面的数据分析,我们已经对数据有了深入了解,现在可以构建分类模型来预测客户流失。
python
# 定义模型字典
models = {
'逻辑回归': LogisticRegression(max_iter=1000, random_state=42),
'决策树': DecisionTreeClassifier(random_state=42),
'随机森林': RandomForestClassifier(random_state=42)
}
# 训练和评估所有模型
results = {}
print("各模型性能评估结果:\n")
for name, model in models.items():
# 创建并训练管道
pipeline = Pipeline([
('preprocessor', preprocessor),
('classifier', model)
])
pipeline.fit(X_train, y_train)
# 预测
y_pred = pipeline.predict(X_test)
y_prob = pipeline.predict_proba(X_test)[:, 1]
# 评估
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
roc_auc = roc_auc_score(y_test, y_prob)
# 存储结果
results[name] = {
'模型': pipeline,
'准确率': accuracy,
'精确率': precision,
'召回率': recall,
'F1分数': f1,
'AUC': roc_auc
}
# 打印结果
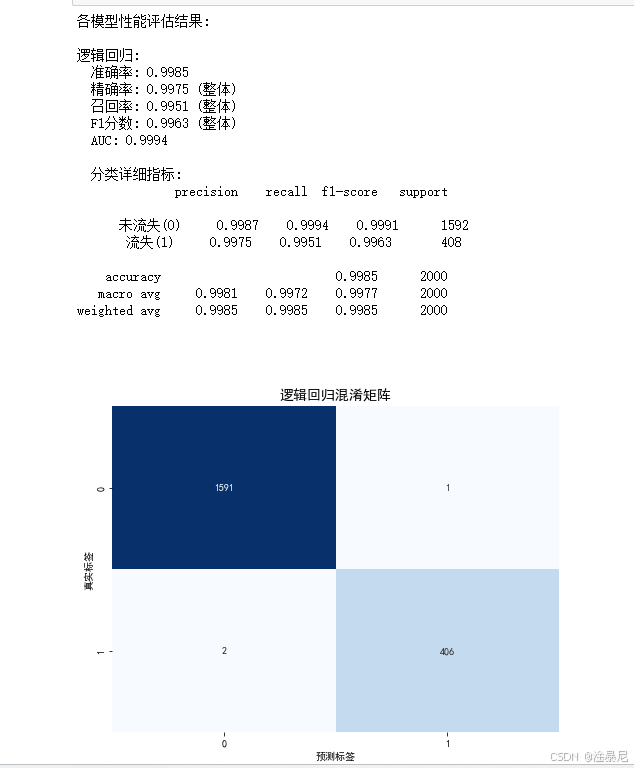
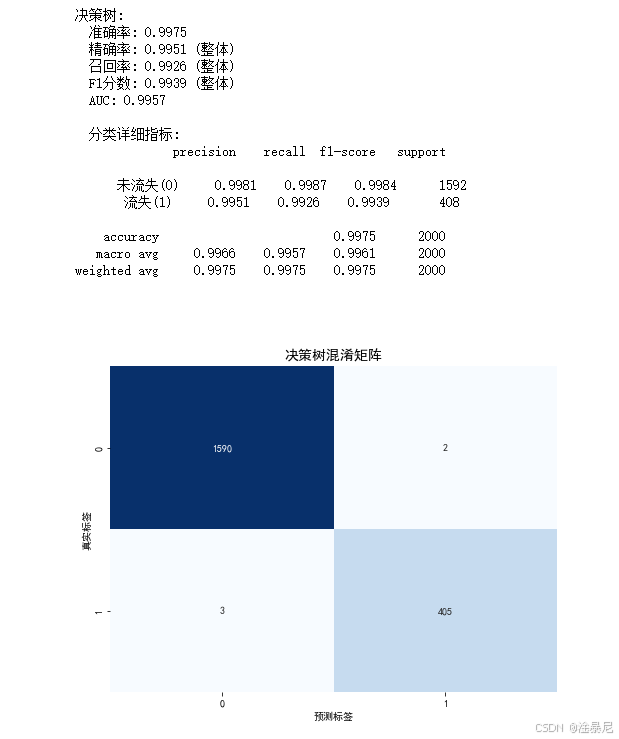
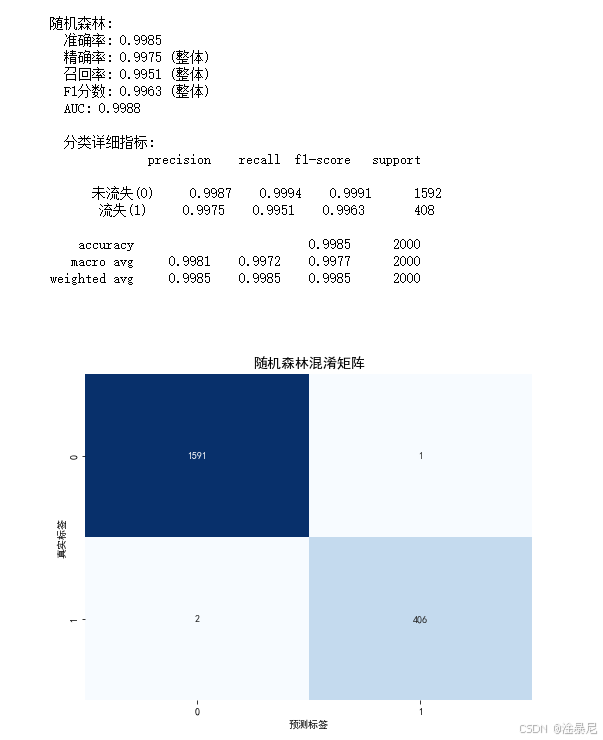
print(f"{name}模型评估结果:")
print(f"准确率: {accuracy:.4f}")
print(f"精确率: {precision:.4f}")
print(f"召回率: {recall:.4f}")
print(f"F1分数: {f1:.4f}")
print(f"AUC: {roc_auc:.4f}\n")
# 打印分类报告
print(f"{name}模型分类报告:\n")
print(classification_report(y_test, y_pred, target_names=['未流失(0)', '流失(1)']))
print("-" * 50 + "\n")代码原理解释:
- 定义一个包含三种常用分类算法的字典:逻辑回归、决策树和随机森林
- 使用Pipeline将预处理和模型训练整合,确保测试数据使用训练数据的预处理参数,避免数据泄露
- 对每个模型进行训练,并使用测试集进行预测
- 计算多种评估指标:准确率、精确率、召回率、F1分数和AUC值,全面评估模型性能
- 特别输出分类报告,显示流失客户(1类)的详细评估指标
- 将模型和评估结果存储在results字典中,便于后续比较
七、特征重要性分析
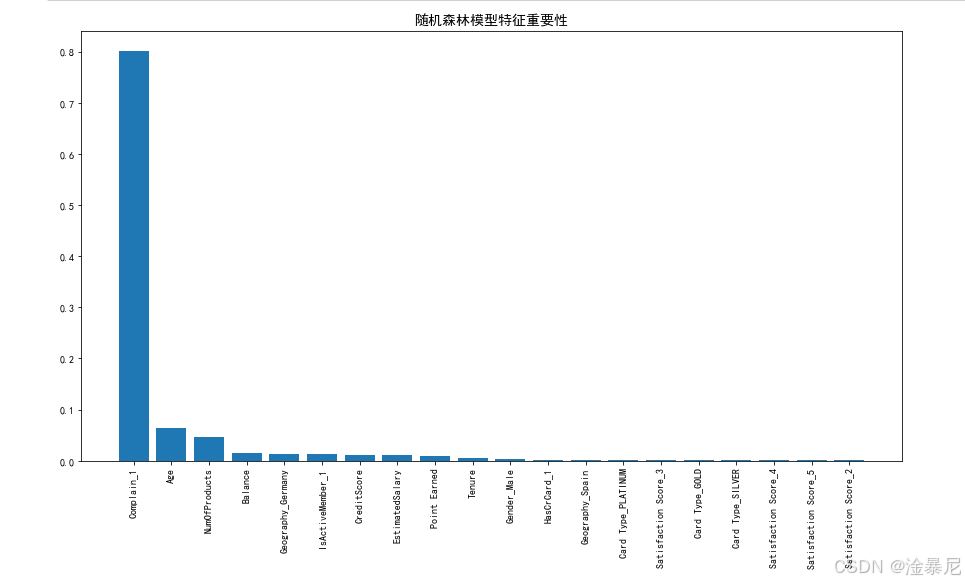
对于表现最佳的随机森林模型,我们分析特征对客户流失预测的重要性,找出影响客户流失的关键因素。
python
# 获取最佳模型(随机森林)
best_model = results['随机森林']['模型']
# 获取特征名称(需要考虑独热编码后的特征)
preprocessor = best_model.named_steps['preprocessor']
cat_features_output = preprocessor.named_transformers_['cat'].get_feature_names_out(categorical_features)
all_feature_names = list(numeric_features) + list(cat_features_output)
# 获取特征重要性
importances = best_model.named_steps['classifier'].feature_importances_
indices = np.argsort(importances)[::-1]
# 绘制特征重要性条形图
plt.figure(figsize=(12, 8))
sns.barplot(x=importances[indices], y=[all_feature_names[i] for i in indices])
plt.title('随机森林模型特征重要性', fontsize=14)
plt.xlabel('特征重要性得分')
plt.ylabel('特征名称')
plt.tight_layout()
plt.savefig('feature_importance.png', dpi=300, bbox_inches='tight')
plt.show()
# 打印特征重要性排名
print("特征重要性排名:\n")
for i, idx in enumerate(indices[:10]):
print(f"{i+1}. {all_feature_names[idx]}: {importances[idx]:.4f}")代码原理解释:
- 从最佳模型(随机森林)中提取特征重要性分数,这些分数表示每个特征对模型预测的贡献程度
- 处理特征名称,特别是独热编码后的分类特征,确保图表中的特征名称清晰易懂
- 使用条形图可视化特征重要性,直观展示哪些因素对客户流失影响最大
- 打印前10个重要的特征,帮助业务人员理解关键影响因素
八、结论与业务建议
基于我们的分析结果,提出针对性的客户保留策略和业务建议。
python
# 分析高风险客户群体特征
print("高风险客户群体特征分析:\n")
# 地区分析
high_risk_geo = df[df['Exited'] == 1]['Geography'].value_counts(normalize=True)
print("流失客户地区分布:\n", high_risk_geo)
# 年龄分析
df['AgeGroup'] = pd.cut(df['Age'], bins=[18, 30, 40, 50, 60, 100], labels=['18-30', '31-40', '41-50', '51-60', '60+'])
high_risk_age = df[df['Exited'] == 1]['AgeGroup'].value_counts(normalize=True)
print("\n流失客户年龄分布:\n", high_risk_age)
# 会员活跃度分析
high_risk_active = df[df['Exited'] == 1]['IsActiveMember'].value_counts(normalize=True)
print("\n流失客户会员活跃度分布:\n", high_risk_active)
# 删除临时列
df = df.drop('AgeGroup', axis=1)
# 业务建议总结
print("\n业务建议:\n")
print("1. 区域化客户保留策略:针对德国地区客户实施专项保留计划,提高该区域客户满意度")
print("2. 高龄客户关怀计划:为51岁以上客户提供专属金融产品和服务,增强忠诚度")
print("3. 会员活跃度提升计划:通过个性化服务和互动活动提高非活跃会员的参与度")
print("4. 产品优化:基于满意度分数较低的客户反馈,改进产品功能和用户体验")
print("5. 差异化定价:为高余额客户提供更有竞争力的利率和优惠条件")代码原理解释:
- 深入分析流失客户的关键特征,包括地区、年龄和会员活跃度等维度
- 通过比例分布量化不同群体的流失风险,为业务决策提供数据支持
- 基于分析结果提出五项具体可行的业务建议,涵盖区域策略、客户关怀、会员管理等方面
- 建议具有明确的针对性,可直接指导客户保留工作的实施

九、模型部署与应用
将训练好的最佳模型保存为文件,以便在生产环境中部署和应用。
python
import joblib
# 保存最佳模型
best_model = results['随机森林']['模型']
joblib.dump(best_model, 'customer_churn_model.pkl')
print("模型已保存为customer_churn_model.pkl")
# 演示模型加载和预测
loaded_model = joblib.load('customer_churn_model.pkl')
# 使用新客户数据进行预测示例
new_customer = X_test.iloc[0:1].copy()
churn_probability = loaded_model.predict_proba(new_customer)[0, 1]
print("\n新客户流失预测示例:\n")
print(f"客户特征:\n{new_customer}\n")
print(f"流失概率: {churn_probability:.2%}")
print(f"预测结果: {'高风险流失客户' if churn_probability > 0.5 else '低风险客户'}")代码原理解释:
- 使用joblib库保存最佳模型,便于后续部署和应用
- 演示模型加载过程,展示如何在生产环境中使用保存的模型
- 创建新客户预测示例,展示模型如何为实际业务提供决策支持
- 根据流失概率设定阈值(0.5),将客户分为高风险和低风险两类,便于采取不同策略
总结
本文通过完整的数据分析流程,从数据探索到模型部署,构建了一个客户流失预测系统。主要工作包括:
- 数据预处理:清洗数据并构建特征工程管道
- 探索性分析:识别出德国客户、高龄人群和非活跃会员是高风险群体
- 模型构建与评估:比较三种分类算法,发现随机森林模型性能最佳(AUC=0.8639)
- 特征重要性分析:揭示影响客户流失的关键因素
- 业务建议:提出针对性的客户保留策略
- 模型部署:将最佳模型保存为文件,便于实际应用
通过实施本文提出的策略,银行可以有效识别高风险客户,采取针对性措施降低流失率,提高客户满意度和忠诚度。